

Maven&Linux&Shell复习笔记(重点简略版)【一】
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
目录
Maven
1.为什么要使用Maven
1传统的以来jar包我们需要在网上进行下载然后复制粘贴然后进行使用。但是有了Maven的使用可以在相应的pom.xml文件之中填写自己想要的jar包依赖它就是可以进行自动下载添加。
2你只需要在你的项目中以坐标的方式依赖一个jar包Maven就会自动从中央仓库进行下载并同时下载这个jar包所依赖的其他jar包——规范、完整、准确
(3) 传统的jar包进行引入的时候需要进行注意的是jar包之间的依赖关系导入一个依赖还需要导入依赖所需的依赖但是Maven的使用使得这个导入依赖的过程变得简单。使用pom.xml文件配置好之后自动导入依赖所需的依赖无需人工参与。
4依赖冲突问题如下图所示
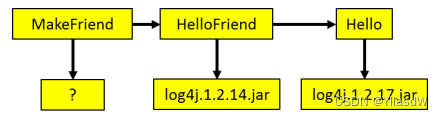
Maven遵循两个原则最短路径者优先和先声明者优先上述问题MakeFriend工程会自动使用log4j.1.2.14.jar。
5多个工程同时进行的时候可以得到上层依赖于下层的关系。

6项目分布式部署

2.Maven是什么
1首先我们要了解一个构建的概念。
针对于纯java代码.java扩展名的源文件需要编译成.class扩展名的字节码文件才能够执行这个过程称之为编译。
针对于Web而言我们需要将相应的代码搁置到对应的目录下执行这个搁置的过程称之为部署。
构建就是以我们编写的Java代码、框架配置文件、国际化等其他资源文件、JSP页面和图片等静态资源作为“原材料”去“生产”出一个可以运行的项目的过程。
2 构建环节
如下所示的构建环节是比较好理解的。

a.测试针对项目中的关键点进行测试确保项目在迭代开发过程中关键点的正确性。
b.报告在每一次测试后以标准的格式记录和展示测试结果。
c.安装在Maven环境下特指将打包的结果——jar包或war包安装到本地仓库中。
d.部署将打包的结果部署到远程仓库或将war包部署到服务器上运行。
3.Maven如何使用
1配置环境变量
a.Maven是java开发的因此是需要知道相应的java的JDK是否存在。进入cmd环境下检测相应的JDK的安装目录。
C:\Windows\System32>echo %JAVA_HOME%
D:\Java\jdk1.8.0_111b.解压Maven的jar包解压到相应的一个非中文目录下方记录路径。
D:\apache-maven-3.2.2c.配置环境变量
在系统变量里进行配置
变量M2_HOME
值D:\apache-maven-3.2.2在Path之中进行配置
变量Path
值%M2_HOME%\bin或D:\apache-maven-3.2.2\bind.检查是否安装成功
在相应的cmd环境下输入如下
C:\Users\Administrator>mvn -v2Maven的本地配置

我的理解就是国内是一般不能使用这个东西的一般是需要墙一下因此这个地方是需要相应的镜像过程国内才是可以使用的。
a.Maven默认的本地仓库~\.m2\repository目录。~表示当前用户的家目录。
b.Maven的核心配置文件位置
解压目录D:\apache-maven-3.2.2\conf\settings.xmlc.本地仓库地址更改到E:\LocalRepository默认在C:\Users\Administrator\.m2\repository
<localRepository>E:\LocalRepository</localRepository>d.配置阿里云镜像下载速度快
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>central</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror> 3在Idea中配置Maven
a.设置安装目录

解释
Maven home directory可以指定本地 Maven 的安装目录所在配置了系统变量因此是可以指定的。
User settings file / Local repository我们还可以指定 Maven 的 settings.xml 位置和本地仓库位置。
b.配置Maven自动导入依赖的jar包

- Import Maven projects automatically表示 IDEA 会实时监控项目的 pom.xml 文件进行项目变动设置勾选上。
- Automatically download在 Maven 导入依赖包的时候是否自动下载源码和文档。默认是没有勾选的也不建议勾选原因是这样可以加快项目从外网导入依赖包的速度如果我们需要源码和文档的时候我们到时候再针对某个依赖包进行联网下载即可。IDEA 支持直接从公网下载源码和文档的。
- VM options for importer可以设置导入的VM参数。一般这个都不需要主动改除非项目真的导入太慢了我们再增大此参数。
(4) Maven程序测试
a.project创建需要注意的是project创建过程之中出现的相应的名称和路径

b.创建module右键→new Module→Maven

注意下面是一个规范写东西要规范一些。否则的话后面用起来容易出现问题。

c.目录说明

- main目录用于存放主程序。
- java目录用于存放源代码文件。
- resources目录用于存放配置文件和资源文件。
- test目录用于存放测试程序。
d.一些什么清理测试什么的前面已经说明不过就是在进行测试的时候在相应的package文件之中产生相应的文件查看这些文件是如何进行使用即可。
4.Maven核心概念
Maven的核心概念包括POM、约定的目录结构、坐标、依赖、仓库、生命周期、插件和目标、继承、聚合。
1pom就是进行相应的pom.xml文件的配置。
2约定的目录结构上面已经进行了相应的说明。
3坐标坐标的使用就是将Maven仓库之中确定的jar进行提取的过程。
groupId公司或组织的域名倒序+当前项目名称
artifactId当前项目的模块名称
version当前模块的版本
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.atguigu.maven</groupId>
<artifactId>Hello</artifactId>
<version>1.0-SNAPSHOT</version>
</project>如何通过坐标到仓库中查找jar包
如上面所示写的相应的pom.xml文件可以知道首先是将上面的三个东西进行一个串联即com.atguigu.maven + Hello + 1.0-SNAPSHOT然后就是在相应的仓库目录下进行查找com/atguigu/maven/Hello/1.0-SNAPSHOT/Hello-1.0-SNAPSHOT.jar。
注意我们自己的Maven工程必须执行安装操作才会进入仓库。安装的命令是mvn install

依赖测试在相应的main/java之中进行主函数的填写在test/java中进行测试填写。
4依赖管理
a.依赖的传递性
| Maven工程 | 依赖范围 | 对A的可见性 | ||
| A | B | C | compile | √ |
| D | test | × | ||
| E | provided | × | ||
b.依赖范围

c.依赖原则
1路径最短者优先

2路径相同时先声明者优先

d.依赖排除
下面的这个例子就是进行了排除首先是排除了原始的commons-logging又使用了新的版本的commons-logging。
<dependency>
<groupId>com.atguigu.maven</groupId>
<artifactId>OurFriends</artifactId>
<version>1.0-SNAPSHOT</version>
<!--依赖排除-->
<exclusions>
<exclusion>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.1.2</version>
</dependency> e.统一管理目标Jar包的版本
在使用的过程之中可能是需要进行相应的版本的确定。有的时候是需要修改很多的但是为了避免一个一个的修改这里我们使用一个整体的修改方式。如下所示是很好进行相应的理解的。
控制模块
<!--统一管理当前模块的jar包的版本-->
<properties>
<spring.version>4.0.0.RELEASE</spring.version>
</properties>整体修改模块
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webmvc</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-orm</artifactId>
<version>${spring.version}</version>
</dependency>5仓库
a.本地仓库
b.远程仓库
a私服架设在当前局域网环境下为当前局域网范围内的所有Maven工程服务。

b中央仓库架设在Internet上为全世界所有Maven工程服务。
c中央仓库的镜像架设在各个大洲为中央仓库分担流量。减轻中央仓库的压力同时更快的响应用户请求。
6生命周期
这个地方我的理解就是在运行的过程之中是存在相应的顺序的关键的顺序是不能够省略的。
5.继承
1为什么要使用继承机制
拿下面的这一段代码进行相应的举例子。
| Hello | <dependency> |
| HelloFriend | <dependency> |
| MakeFriend | <dependency> |
进行依赖的时候我们不用一个一个修改相应的junit的版本只是需要修改父类的的junit的版本号就是可以进行相应的整体修改。
2创建父工程
注意其打包方式是pom
<groupId>com.atguigu.maven</groupId>
<artifactId>Parent</artifactId>
<packaging>pom</packaging>
<version>1.0-SNAPSHOT</version>3子工程之中引用父工程
<!--继承-->
<parent>
<groupId>com.atguigu.maven</groupId>
<artifactId>Parent</artifactId>
<version>1.0-SNAPSHOT</version>
<!--指定从当前pom.xml文件出发寻找父工程的pom.xml文件的相对路径-->
<relativePath>../Parent/pom.xml</relativePath>
</parent>4在父工程中管理依赖
将Parent项目中的dependencies标签用dependencyManagement标签括起来
<!--依赖管理-->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.0</version>
<scope>test</scope>
</dependency>
</dependencies>
</dependencyManagement>如果要是相应的子工程要用这些依赖的话需要重新指定否则就是在子工程之中是没有使用的。
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
</dependency>6.聚合
(1为什么要使用聚合
将多个工程拆分为模块后需要手动逐个安装到仓库后依赖才能够生效。这时候就是需要用到相应的聚合过程了。
2如何配置聚合
在总的聚合工程中使用modules/module标签组合指定模块工程的相对路径即可。
<!--聚合-->
<modules>
<module>../MakeFriend</module>
<module>../OurFriends</module>
<module>../HelloFriend</module>
<module>../Hello</module>
</modules>Maven可以根据各个模块的继承和依赖关系自动选择安装的顺序.
Linux
使用linux首先是要安装相应的VMWare和CentOS的具体的安装过程见我的博客资源存档部分已经上传。
1.Linux文件与目录
a.Linux之中一切皆文件。
b.Linux目录
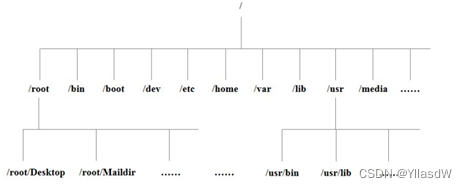
/bin是Binary的缩写存放最常使用的命令。
/sbins是Super User的意思用来存放管理员使用的系统管理程序。
/home普通用户的主目录一般是使用用户名进行定义的。
/root超级管理员目录。
/lib系统开机需要使用的动态库就是相当于windows系统使用的DLL文档库。
/lost+found非法关机时候存放的文档。
/etc系统管理存放的系统所需要的配置文件和子目录。
/usr用户的应用程序和文件都是存放到这个地方的。类似于windows之中program files目录。
/boot存放linux启动时候核心文件包括一些连接文件以及镜像文件。
/media用来存放一些U盘和光驱识别后Linux就是会将这些文件进行迁移到这个地方。CentOS7将这个部分进行了迁移到/run/media。
/mnt用户临时挂载的别的文件。
/opt给Linux用户额外摆放的安装软件目录。
/var将经常修改的目录放到这个地方当然也是有着各种日志文件的。
2.VI/VIM编辑器
1一般模式
当我们使用vim打开一个文件的时候首先进入的就是一个一般模式。
| 语法 | 功能描述 |
| yy | 复制光标当前一行 |
| y数字y | 复制一段从第几行到第几行 |
| p | 箭头移动到目的行粘贴 |
| u | 撤销上一步 |
| dd | 删除光标当前行 |
| d数字d | 删除光标含后多少行 |
| x | 剪切一个字母相当于del |
| X | 剪切一个字母相当于Backspace |
| yw | 复制一个词 |
| dw | 删除一个词 |
| shift+6^ | 移动到行头 |
| shift+4 $ | 移动到行尾 |
| 1+shift+g | 移动到页头数字 |
| shift+g | 移动到页尾 |
| 数字+shift+g | 移动到目标行 |
2编辑模式这个地方存在什么五个按键不用想那么多直接使用i就是可以的。
3指令模式按下【esc】
| 命令 | 功能 |
| :w | 保存 |
| :q | 退出 |
| :! | 强制执行 |
| /要查找的词 | n 查找下一个N 往上查找 |
| :noh | 取消高亮显示 |
| :set nu | 显示行号 |
| :set nonu | 关闭行号 |
| :%s/old/new/g | 替换内容 /g 替换匹配到的所有内容 |
4转换过程

3.网络配置和系统管理操作
1查看IP和网关
这个步骤是在虚拟机之中进行的。



2配置网络ip地址
a.配置网络接口 进入Linux之中输入ifconfig即可进行查看。
b.测试网络连通性在Linux之中输入ping www.baidu.com
c.修改IPvim /etc/sysconfig/network-scripts/ifcfg-ens33需要进行修改的值如下所示
执行service network restart 重启网络。
3配置主机名
a.查看当前服务器主机名称
[root@hadoop100 ]# hostnameb.如果感觉此主机名不合适我们可以进行修改。通过编辑/etc/hostname文件
[root@hadoop100 ]# vim /etc/hostname重启即可生效。
c.修改hosts映射文件
a修改linux的主机映射文件hosts文件后续在hadoop阶段虚拟机会比较多配置时通常会采用主机名的方式配置不用刻意记ip地址。
[root@hadoop100]# vim /etc/hosts192.168.2.100 hadoop100
192.168.2.101 hadoop101
192.168.2.102 hadoop102
192.168.2.103 hadoop103
192.168.2.104 hadoop104
192.168.2.105 hadoop105重启设备即可生效。
b修改window的主机映射文件hosts文件
进入C:\Windows\System32\drivers\etc路径添加如下内容。
192.168.2.100 hadoop100
192.168.2.101 hadoop101
192.168.2.102 hadoop102
192.168.2.103 hadoop103
192.168.2.104 hadoop104
192.168.2.105 hadoop1054关闭防火墙这里由于CentOS6已经过时了这里讲解的主要是以CentOS7为主
查看防火墙服务的状态
[root@hadoop100]# systemctl status firewalld停止防火墙服务
[root@hadoop100]# systemctl stop firewalld启动防火墙服务
[root@hadoop100]# systemctl start firewalld重启防火墙服务
[root@hadoop100]# systemctl restart firewalld5systemctl 设置后台服务的自启配置
开启/关闭iptables(防火墙)服务的自动启动
[root@hadoop100]# systemctl enable firewalld.service
[root@hadoop100]# systemctl disable firewalld.service 6关机重启命令
一般是迫不得已的时候必需使用关机操作。正确的关机流程为sync > shutdown > reboot > halt才能够使得数据不能够丢失保存相应的数据进行开机。
将数据由内存同步到硬盘中#sync
重启# reboot
关机#halt
计算机将在1分钟后关机并且会显示在登录用户的当前屏幕中#shutdown -h 1 ‘This server will shutdown after 1 mins’
我一般很少想那么多直接一个reboot重启。
4.常用基本命令
1帮助命令
在Linux之中使用的是man在Xshell之中查看帮助使用的内置命令是help。
2文件目录类
a.pwd 显示当前工作目录的绝对路径
[root@hadoop101 ~]# pwd
/rootb.ls 列出目录的内容每行列出的信息依次是 文件类型与权限 链接数 文件属主 文件属组 文件大小用byte来表示 建立或最近修改的时间 名字
[atguigu@hadoop101 ~]$ ls -al
总用量 44
drwx------. 5 atguigu atguigu 4096 5月 27 15:15 .
drwxr-xr-x. 3 root root 4096 5月 27 14:03 ..
drwxrwxrwx. 2 root root 4096 5月 27 14:14 hello
-rwxrw-r--. 1 atguigu atguigu 34 5月 27 14:20 test.txtc.cd 切换目录
| 参数 | 功能 |
| cd 绝对路径 | 切换路径 |
| cd相对路径 | 切换路径 |
| cd ~或者cd | 回到自己的家目录 |
| cd - | 回到上一次所在目录 |
| cd .. | 回到当前目录的上一级目录 |
| cd -P | 跳转到实际物理路径而非快捷方式路径 |
d.mkdir 创建一个新的目录这里的-p的使用是将
[root@hadoop101 ~]# mkdir -p xiyou/dssz/meihouwange.touch 创建空文件
[root@hadoop101 ~]# touch xiyou/dssz/sunwukong.txtf.cp 复制文件或目录注意复制一个目录的时候前面是要进行添加-r的进行递归复制过程。
[root@hadoop101 ~]# cp -r xiyou/dssz/ ./g.rm 删除文件或者目录
| 选项 | 功能 |
| -r | 递归删除目录中所有内容 |
| -f | 强制执行删除操作而不提示用于进行确认。 |
| -v | 显示指令的详细执行过程 |
[root@hadoop101 ~]# rm -rf dssz/h.mv 移动文件与目录或重命名
[root@hadoop101 ~]# mv xiyou/dssz/suwukong.txt xiyou/dssz/houge.txti.cat 查看文件内容后面加入一个-n是显示相应的行号。我一般是不使用这个命令的我一般就是直接使用vimvim多好用呀。
[atguigu@hadoop101 ~]$ cat -n houge.txt j.more 文件内容分屏查看器基本用不着
| 操作 | 功能说明 |
| 空白键 (space) | 代表向下翻一页 |
| Enter | 代表向下翻『一行』 |
| q | 代表立刻离开 more 不再显示该文件内容。 |
| Ctrl+F | 向下滚动一屏 |
| Ctrl+B | 返回上一屏 |
| = | 输出当前行的行号 |
| :f | 输出文件名和当前行的行号 |
[root@hadoop101 ~]# more smartd.confk.less 分屏显示文件内容与more类似这个功能用于看小说可以。
| 操作 | 功能说明 |
| 空白键 | 向下翻动一页 |
| [pagedown] | 向下翻动一页 |
| [pageup] | 向上翻动一页 |
| /字串 | 向下搜寻『字串』的功能n向下查找N向上查找 |
| ?字串 | 向上搜寻『字串』的功能n向上查找N向下查找 |
| q | 离开 less 这个程序 |
[root@hadoop101 ~]# less smartd.confl. echo
-e 支持反斜线控制的字符转换
| 控制字符 | 作用 |
| \\ | 输出\本身 |
| \n | 换行符 |
| \t | 制表符也就是Tab键 |
[atguigu@hadoop101 ~]$ echo “hello\tworld”
hello\tworld
[atguigu@hadoop101 ~]$ echo -e “hello\tworld”
hello worldm.head 显示文件头部内容默认是前十行
[root@hadoop101 ~]# head -n 2 smartd.confn.tail 输出文件尾部内容-f是实时最终文件的更新
| 选项 | 功能 |
| -n<行数> | 输出文件尾部n行内容 |
| -f | 显示文件最新追加的内容监视文件变化 |
[root@hadoop101 ~]# date "+%Y-%m-%d %H:%M:%S"
2017-06-19 20:54:58[root@hadoop101 ~]# tail -n 1 smartd.conf o.history 查看已经执行过历史命令
[root@hadoop101 test1]# history3时间日期类
a.date 显示当前时间
[root@hadoop101 ~]# date
2017年 06月 19日 星期一 20:53:30 CST[root@hadoop101 ~]# date +%Y%m%d
20170619b.date 显示非当前时间
显示前一天
[root@hadoop101 ~]# date -d '1 days ago'
2017年 06月 18日 星期日 21:07:22 CST显示后一天
[root@hadoop101 ~]#date -d '-1 days ago'
2017年 06月 20日 星期日 21:07:22 CSTc.date 设置系统时间这一个可能在相应的虚拟机同步的时候会用到
[root@hadoop101 ~]# date -s "2017-06-19 20:52:18"d.查看日历
查看当前月的日历
[root@hadoop101 ~]# cal查看当年的日历
[root@hadoop101 ~]# cal 20174用户管理命令
a.添加用户
[root@hadoop101 ~]# useradd tangseng
[root@hadoop101 ~]#ll /home/b.设置密码
[root@hadoop101 ~]# passwd tangsengc.查看用户
[root@hadoop101 ~]#id tangsengd.切换用户
[root@hadoop101 ~]#su tangsenge.删除用户
删除用户但保存用户主目录
[root@hadoop101 ~]#useradd zhubajie
[root@hadoop101 ~]#ll /home/
删除用户和用户主目录都删除
[root@hadoop101 ~]#userdel -r zhubajie
[root@hadoop101 ~]#ll /home/f.sudo设置普通用户拥有root权限
添加Yang用户并对其设置密码。
[root@hadoop101 ~]#useradd Yang
[root@hadoop101 ~]#passwd Yang修改配置文件
[root@hadoop101 ~]#vi /etc/sudoers修改 /etc/sudoers 文件找到下面一行(91行)在root下面添加一行如下所示
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
atguigu ALL=(ALL) ALL修改完毕现在可以用atguigu帐号登录然后用命令 sudo 即可获得root权限进行操作。
g.who 查看登录用户信息
显示自身用户名称
[root@hadoop101 opt]# whoami
显示登录用户的用户名与时间
[root@hadoop101 opt]# who am i5用户组这一部分感觉用不着就不写了懒得想了。
6文件权限类
a.文件属性

0首位表示类型在Linux中第一个字符代表这个文件是目录、文件或链接文件等等
- 代表文件 d 代表目录 l 链接文档(link file)
第1-3位确定属主该文件的所有者拥有该文件的权限。---User
第4-6位确定属组所有者的同组用户拥有该文件的权限---Group
第7-9位确定其他用户拥有该文件的权限 ---Other

如果查看到是文件链接数指的是硬链接个数。
如果查看的是文件夹链接数指的是子文件夹个数。
b.chmod 改变权限

u:所有者 g:所有组 o:其他人 a:所有人(u、g、o的总和)
r=4 w=2 x=1 rwx=4+2+1=7
修改案例如下所示
[root@hadoop101 ~]# cp xiyou/dssz/houge.txt ./
[root@hadoop101 ~]# chmod u+x houge.txt[root@hadoop101 ~]# chmod 777 houge.txt如果要是想要整个文件目录之中的东西都是可以进行相应的操作使用的命令是如下所示
[root@hadoop101 ~]# chmod -R 777 xiyou/c.chown 改变所有者
修改文件所有者
[root@hadoop101 ~]# chown atguigu houge.txt
[root@hadoop101 ~]# ls -al
-rwxrwxrwx. 1 atguigu root 551 5月 23 13:02 houge.txt递归改变文件所有者和所有组
[root@hadoop101 xiyou]# ll
drwxrwxrwx. 2 root root 4096 9月 3 21:20 xiyou
[root@hadoop101 xiyou]# chown -R atguigu:atguigu xiyou/
[root@hadoop101 xiyou]# ll
drwxrwxrwx. 2 atguigu atguigu 4096 9月 3 21:20 xiyoud.chgrp 改变所属组
[root@hadoop101 ~]# chgrp root houge.txt
[root@hadoop101 ~]# ls -al
-rwxrwxrwx. 1 atguigu root 551 5月 23 13:02 houge.txt7搜索查找类
a.find进行相应的搜索的过程使用注意这里的find是在知道在哪个文件夹之中的时候才是可以进行使用的。
按文件名根据名称查找/目录下的filename.txt文件。
[root@hadoop101 ~]# find xiyou/ -name *.txt
按拥有者查找/opt目录下用户名称为-user的文件
[root@hadoop101 ~]# find xiyou/ -user atguigu
按文件大小在/home目录下查找大于200m的文件+n 大于 -n小于 n等于
[root@hadoop101 ~]find /home -size +204800b.locate快速定位文件路径locate是直接进行使用的进行查询一个文件夹。
[root@hadoop101 ~]# updatedb
[root@hadoop101 ~]#locate tmpc.grep 过滤查找及“|”管道符
查找某文件在第几行
[root@hadoop101 ~]# ls | grep -n test8压缩和解压类
a.gzip/gunzip 压缩
gzip 文件 功能描述压缩文件只能将文件压缩为*.gz文件
gunzip 文件.gz 功能描述解压缩文件命令
注意这个地方
1只能压缩文件不能压缩目录
2不保留原来的文件
3同时多个文件会产生多个压缩包
b.zip/unzip 压缩
zip [选项] XXX.zip 将要压缩的内容 功能描述压缩文件和目录的命令
unzip [选项] XXX.zip 功能描述解压缩文件
| zip选项 | 功能 |
| -r | 压缩目录 |
| unzip选项 | 功能 |
| -d<目录> | 指定解压后文件的存放目录 |
c.tar 打包
| 选项 | 功能 |
| -c | 产生.tar打包文件 |
| -v | 显示详细信息 |
| -f | 指定压缩后的文件名 |
| -z | 打包同时压缩 |
| -x | 解包.tar文件 |
| -C | 解压到指定目录 |
这个命令就是经常使用的无论是压缩还是进行解压的过程都是tar -zxvf ****
压缩多个文件
[root@hadoop101 opt]# tar -zcvf houma.tar.gz houge.txt bailongma.txt
压缩目录
[root@hadoop101 ~]# tar -zcvf xiyou.tar.gz xiyou/
解压到当前目录
[root@hadoop101 ~]# tar -zxvf houma.tar.gz
解压到指定目录
[root@hadoop101 ~]# tar -zxvf xiyou.tar.gz -C /opt9磁盘分区类
a.df 查看磁盘空间使用情况-h的使用是在显示的时候使用M G等比较好看的方式显示。
[root@hadoop101 ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda2 15G 3.5G 11G 26% /
tmpfs 939M 224K 939M 1% /dev/shm
/dev/sda1 190M 39M 142M 22% /boot后面还有几个但是我感觉用不到等用到的时候再进行查询就是可以的。
10进程线程类
a.ps 查看当前系统进程状态
ps -aux | grep xxx 功能描述查看系统中所有进程
显示信息需要注意的地方
PID进程的ID号
%CPU该进程占用CPU资源的百分比占用越高进程越耗费资源
%MEM该进程占用物理内存的百分比占用越高进程越耗费资源 ps -ef | grep xxx 功能描述可以查看子父进程之间的关系
ps -ef | grep xxx 功能描述可以查看子父进程之间的关系
PID进程ID
PPID父进程ID
b.kill 终止进程:常用的kill -9 ****命令就是可以的。
c.pstree 查看进程树
显示进程pid
[root@hadoop101 datas]# pstree -p
显示进程所属用户
[root@hadoop101 datas]# pstree -ud.top 查看系统健康状态至今没有用到过就不看了
e.netstat 显示网络统计信息和端口占用情况
netstat -anp | grep 进程号 功能描述查看该进程网络信息
netstat –nlp | grep 端口号 功能描述查看网络端口号占用情况
11crontab 系统定时任务 【没有用到过】
5.软件包管理
1RPM
a.概述
RPMRedHat Package ManagerRedHat软件包管理工具类似windows里面的setup.exe是Linux这系列操作系统里面的打包安装工具它虽然是RedHat的标志但理念是通用的。
RPM包的名称格式Apache-1.3.23-11.i386.rpm
- “apache” 软件名称
- “1.3.23-11”软件的版本号主版本和此版本
- “i386”是软件所运行的硬件平台Intel 32位处理器的统称
- “rpm”文件扩展名代表RPM包
b.RPM查询命令rpm -qa
查询firefox软件安装情况
[root@hadoop101 Packages]# rpm -qa |grep firefox
firefox-45.0.1-1.el6.centos.x86_64c.RPM卸载命令rpm -e
| 选项 | 功能 |
| -e | 卸载软件包 |
| --nodeps | 卸载软件时不检查依赖。这样的话那些使用该软件包的软件在此之后可能就不能正常工作了。 |
卸载firefox软件
[root@hadoop101 Packages]# rpm -e firefoxd.RPM安装命令rpm -ivh
| 选项 | 功能 |
| -i | -i=install安装 |
| -v | -v=verbose显示详细信息 |
| -h | -h=hash进度条 |
| --nodeps | --nodeps不检测依赖进度 |
安装firefox软件
[root@hadoop101 Packages]# pwd
/run/media/root/CentOS 7 x86_64/Packages
[root@hadoop101 Packages]# rpm -ivh firefox-45.0.1-1.el6.centos.x86_64.rpm
warning: firefox-45.0.1-1.el6.centos.x86_64.rpm: Header V3 RSA/SHA1 Signature, key ID c105b9de: NOKEY
Preparing... ########################################### [100%]
1:firefox ########################################### [100%]2YUM仓库配置
a.概述
将其想成是Maven就可以可以自动处理依赖关系。基于RPM包管理能够从指定的服务器自动下载RPM包并且安装可以自动处理依赖性关系并且一次安装所有依赖的软件包无须繁琐地一次次下载、安装。

b.常用的命令
选项说明
| 选项 | 功能 |
| -y | 对所有提问都回答“yes” |
参数说明
| 参数 | 功能 |
| install | 安装rpm软件包 |
| update | 更新rpm软件包 |
| check-update | 检查是否有可用的更新rpm软件包 |
| remove | 删除指定的rpm软件包 |
| list | 显示软件包信息 |
| clean | 清理yum过期的缓存 |
| deplist | 显示yum软件包的所有依赖关系 |
使用yum的方式进行安装相应的firefox如下所示
[root@hadoop101 ~]#yum -y install firefox.x86_64c.修改网络YUM源
默认的系统YUM源需要连接国外apache网站网速比较慢可以修改关联的网络YUM源为国内镜像的网站比如网易163,aliyun等。
1安装wget, wget用来从指定的URL下载文件
[root@hadoop101 ~] yum install wget2在/etc/yum.repos.d/目录下备份默认的repos文件
[root@hadoop101 yum.repos.d] pwd
/etc/yum.repos.d
[root@hadoop101 yum.repos.d] cp CentOS-Base.repo CentOS-Base
.repo.backup3下载网易163或者是aliyun的repos文件,任选其一
[root@hadoop101 yum.repos.d] wget
http://mirrors.aliyun.com/repo/Centos-7.repo //阿里云
[root@hadoop101 yum.repos.d] wget
http://mirrors.163.com/.help/CentOS7-Base-163.repo //网易1634使用下载好的repos文件替换默认的repos文件。例如:用CentOS7-Base-163.repo替换CentOS-Base.repo
[root@hadoop101 yum.repos.d]# mv CentOS7-Base-163.repo CentOS-Base.repo5清理旧缓存数据缓存新数据
[root@hadoop101 yum.repos.d]#yum clean all
[root@hadoop101 yum.repos.d]#yum makecacheyum makecache就是把服务器的包信息下载到本地电脑缓存起来
6测试
[root@hadoop101 yum.repos.d]# yum list | grep firefox
[root@hadoop101 ~]#yum -y install firefox.x86_646.常见错误及解决方案
虚拟化支持异常情况这个情况我记得在上大三实习的时候遇到过如下几种情况


 问题原因宿主机BIOS设置中的硬件虚拟化被禁用了
问题原因宿主机BIOS设置中的硬件虚拟化被禁用了
解决办法需要打开笔记本BIOS中的IVT对虚拟化的支持
针对于不同版本的电脑进入BIOS的方式还是不一样的需要在网上进行查找可以使用的方式。
7.企业面试题
1百度&考满分
问题Linux常用命令
参考答案find、df、tar、ps、top、netstat等。尽量说一些高级命令
2瓜子二手车
问题Linux查看内存、磁盘存储、io 读写、端口占用、进程等命令
1、查看内存top在显示信息的第四第五行之中存在相应的内存信息。在本篇之中没有写到top是如何进行使用查了一下博客可以参考下面的这个博客
Linux运维之top命令解析_linux top命令_宗而研之的博客-CSDN博客
2、查看磁盘存储情况df -h
3、查 看磁盘IO读写情况iotop需要安装一下yum install iotop、iotop -o直接查看输出比较高的磁盘读写程序
4、查看端口占用情况netstat -tunlp | grep 端口号
5、查看进程ps -aux
Shell
1.Shell概述
Shell是一个命令行解析器用来接收外部程序命令进而调制Linux内核。

1Linux提供的Shell解析器有
[atguigu@hadoop101 ~]$ cat /etc/shells
/bin/sh
/bin/bash
/sbin/nologin
/bin/dash
/bin/tcsh
/bin/csh2bash和sh的关系
[atguigu@hadoop101 bin]$ ll | grep bash
-rwxr-xr-x. 1 root root 941880 5月 11 2016 bash
lrwxrwxrwx. 1 root root 4 5月 27 2017 sh -> bash3Centos默认的解析器是bash这个地方需要进行特别的注意因为其提供的解析器是bash这就解释了为什么我们在写shell脚本的时候使用的是#!/bin/bash开头了。脚本以#!/bin/bash开头指定解析器
[atguigu@hadoop102 bin]$ echo $SHELL
/bin/bash2.Shell脚本入门
1脚本格式
脚本以#!/bin/bash开头指定解析器
2创建第一个脚本
打印hello world
[atguigu@hadoop101 datas]$ touch helloworld.sh
[atguigu@hadoop101 datas]$ vi helloworld.sh#!/bin/bash
echo "helloworld"3脚本执行方式
第一种采用bash或sh+脚本的相对路径或绝对路径不用赋予脚本+x权限
[atguigu@hadoop101 datas]$ bash helloworld.sh 第二种采用输入脚本的绝对路径或相对路径执行脚本必须具有可执行权限+x
[atguigu@hadoop101 datas]$ chmod +x helloworld.sh[atguigu@hadoop101 datas]$ ./helloworld.sh 3.变量
1系统预定义变量$HOME、$PWD、$SHELL、$USER等
2自定义变量
a.基本语法
定义变量变量=值
撤销变量unset 变量
声明静态变量readonly变量注意不能unset
[atguigu@hadoop101 datas]$ readonly B=2
[atguigu@hadoop101 datas]$ echo $B
2
[atguigu@hadoop101 datas]$ B=9
-bash: B: readonly variableb.变量定义规则
变量名称可以由字母、数字和下划线组成但是不能以数字开头环境变量名建议大写。
等号两侧不能有空格.
在bash中变量默认类型都是字符串类型无法直接进行数值运算。
[atguigu@hadoop102 ~]$ C=1+2
[atguigu@hadoop102 ~]$ echo $C
1+2变量的值如果有空格需要使用双引号或单引号括起来。
[atguigu@hadoop102 ~]$ D=I love banzhang
-bash: world: command not found
[atguigu@hadoop102 ~]$ D="I love banzhang"
[atguigu@hadoop102 ~]$ echo $D
I love banzhang可把变量提升为全局环境变量可供其他Shell程序使用
export 变量名3特殊变量
a.$n
1基本语法
$n 功能描述n为数字$0代表该脚本名称$1-$9代表第一到第九个参数十以上的参数十以上的参数需要用大括号包含如${10}
2案例实操
[atguigu@hadoop101 datas]$ touch parameter.sh
[atguigu@hadoop101 datas]$ vim parameter.sh
#!/bin/bash
echo "$0 $1 $2"
[atguigu@hadoop101 datas]$ chmod 777 parameter.sh
[atguigu@hadoop101 datas]$ ./parameter.sh cls xz
./parameter.sh cls xzb.$#
1基本语法
$# 功能描述获取所有输入参数个数常用于循环。
2案例实操
[atguigu@hadoop101 datas]$ vim parameter.sh
#!/bin/bash
echo "$0 $1 $2"
echo $#
[atguigu@hadoop101 datas]$ chmod 777 parameter.sh
[atguigu@hadoop101 datas]$ ./parameter.sh cls xz
parameter.sh cls xz
2c.$*、$@
1基本语法
$* 功能描述这个变量代表命令行中所有的参数$*把所有的参数看成一个整体
$@ 功能描述这个变量也代表命令行中所有的参数不过$@把每个参数区分对待
注意如果想让$*和$@ 体现区别必须用双引号括起来才生效
2案例实操
[atguigu@hadoop101 datas]$ vim parameter.sh
#!/bin/bash
echo "$0 $1 $2"
echo $#
echo $*
echo $@
[atguigu@hadoop101 datas]$ bash parameter.sh 1 2 3
parameter.sh 1 2
3
1 2 3
1 2 3d.$
$ 功能描述最后一次执行的命令的返回状态。如果这个变量的值为0证明上一个命令正确执行如果这个变量的值为非0具体是哪个数由命令自己来决定则证明上一个命令执行不正确了。
如下所示判断helloworld.sh脚本是否正确执行
[atguigu@hadoop101 datas]$ ./helloworld.sh
hello world
[atguigu@hadoop101 datas]$ echo $?
04.运算符
“$((运算式))”或“$[运算式]”
[atguigu@hadoop101 datas]# S=$[(2+3)*4]
[atguigu@hadoop101 datas]# echo $S5.条件判断
1基本语法
test condition
[ condition ]注意condition前后要有空格
注意条件非空即为true[ atguigu ]返回true[] 返回false。
2常用判断条件
a.两个整数之间比较
== 字符串比较
-lt 小于less than -le 小于等于less equal
-eq 等于equal -gt 大于greater than
-ge 大于等于greater equal -ne 不等于Not equal
b.按照文件权限进行判断
-r 有读的权限read -w 有写的权限write-x 有执行的权限execute
c.按照文件类型进行判断
-f 文件存在并且是一个常规的文件file-e 文件存在existence -d 文件存在并是一个目录directory
d.实际操作
23是否大于等于22
[atguigu@hadoop101 datas]$ [ 23 -ge 22 ]
[atguigu@hadoop101 datas]$ echo $?
0helloworld.sh是否具有写权限
[atguigu@hadoop101 datas]$ [ -w helloworld.sh ]
[atguigu@hadoop101 datas]$ echo $?
0/home/atguigu/cls.txt目录中的文件是否存在
[atguigu@hadoop101 datas]$ [ -e /home/atguigu/cls.txt ]
[atguigu@hadoop101 datas]$ echo $?
1多条件判断&& 表示前一条命令执行成功时才执行后一条命令|| 表示上一条命令执行失败后才执行下一条命令
[atguigu@hadoop101 ~]$ [ condition ] && echo OK || echo notok
OK
[atguigu@hadoop101 datas]$ [ condition ] && [ ] || echo notok
notok6.流程控制重点
这部分的流程控制是比较重要的具体的格式是具体分析就是可以的。实际需要可能也是需要写一些脚本之类的。
1 if判断
1基本语法
if [ 条件判断式 ];then
程序
fi
或者
if [ 条件判断式 ]
then
程序
elif [ 条件判断式 ]
then
程序
else
程序
fi注意事项
a.[ 条件判断式 ]中括号和条件判断式之间必须有空格
b.if后要有空格
2案例实操
输入一个数字如果是1则输出banzhang zhen shuai如果是2则输出cls zhen mei如果是其它什么也不输出。
[atguigu@hadoop101 datas]$ touch if.sh
[atguigu@hadoop101 datas]$ vim if.sh
#!/bin/bash
if [ $1 -eq "1" ]
then
echo "banzhang zhen shuai"
elif [ $1 -eq "2" ]
then
echo "cls zhen mei"
fi
[atguigu@hadoop101 datas]$ chmod 777 if.sh
[atguigu@hadoop101 datas]$ ./if.sh 1
banzhang zhen shuai2 case语句
1基本语法
case $变量名 in
"值1"
如果变量的值等于值1则执行程序1
;;
"值2"
如果变量的值等于值2则执行程序2
;;
…省略其他分支…
*
如果变量的值都不是以上的值则执行此程序
;;
esac注意事项
a.case行尾必须为单词“in”每一个模式匹配必须以右括号“”结束。
b.双分号“;;”表示命令序列结束相当于java中的break。
c.最后的“*”表示默认模式相当于java中的default。
2案例实操
输入一个数字如果是1则输出banzhang如果是2则输出cls如果是其它输出renyao。
[atguigu@hadoop101 datas]$ touch case.sh
[atguigu@hadoop101 datas]$ vim case.sh
!/bin/bash
case $1 in
"1")
echo "banzhang"
;;
"2")
echo "cls"
;;
*)
echo "renyao"
;;
esac
[atguigu@hadoop101 datas]$ chmod 777 case.sh
[atguigu@hadoop101 datas]$ ./case.sh 1
13for循环
1基本语法1
for (( 初始值;循环控制条件;变量变化 ))
do
程序
done2案例实操
[atguigu@hadoop101 datas]$ touch for1.sh
[atguigu@hadoop101 datas]$ vim for1.sh
#!/bin/bash
s=0
for((i=0;i<=100;i++))
do
s=$[$s+$i]
done
echo $s
[atguigu@hadoop101 datas]$ chmod 777 for1.sh
[atguigu@hadoop101 datas]$ ./for1.sh
“5050”3基本语法2
for 变量 in 值1 值2 值3…
do
程序
done4案例实操
[atguigu@hadoop101 datas]$ touch for2.sh
[atguigu@hadoop101 datas]$ vim for2.sh
#!/bin/bash
#打印数字
for i in $*
do
echo "ban zhang love $i "
done
[atguigu@hadoop101 datas]$ chmod 777 for2.sh
[atguigu@hadoop101 datas]$ bash for2.sh cls xz bd
ban zhang love cls
ban zhang love xz
ban zhang love bd之前提到一个$@与$*的区别但是没有进行真正的比较。
$*和$@都表示传递给函数或脚本的所有参数不被双引号“”包含时都以$1 $2 …$n的形式输出所有参数。
[atguigu@hadoop101 datas]$ touch for.sh
[atguigu@hadoop101 datas]$ vim for.sh
#!/bin/bash
for i in $*
do
echo "ban zhang love $i "
done
for j in $@
do
echo "ban zhang love $j"
done
[atguigu@hadoop101 datas]$ bash for.sh cls xz bd
ban zhang love cls
ban zhang love xz
ban zhang love bd
ban zhang love cls
ban zhang love xz
ban zhang love bd当它们被双引号“”包含时“$*”会将所有的参数作为一个整体以“$1 $2 …$n”的形式输出所有参数“$@”会将各个参数分开以“$1” “$2”…”$n”的形式输出所有参数。
[atguigu@hadoop101 datas]$ vim for.sh
#!/bin/bash
for i in "$*"
#$*中的所有参数看成是一个整体所以这个for循环只会循环一次
do
echo "ban zhang love $i"
done
for j in "$@"
#$@中的每个参数都看成是独立的所以“$@”中有几个参数就会循环几次
do
echo "ban zhang love $j"
done
[atguigu@hadoop101 datas]$ chmod 777 for.sh
[atguigu@hadoop101 datas]$ bash for.sh cls xz bd
ban zhang love cls xz bd
ban zhang love cls
ban zhang love xz用自己的语言进行解释就是如果要是"$*"就是执行一次如果要是"$@"执行多次。
4while循环
1基本语法
while [ 条件判断式 ]
do
程序
done2案例实操
[atguigu@hadoop101 datas]$ touch while.sh
[atguigu@hadoop101 datas]$ vim while.sh
#!/bin/bash
s=0
i=1
while [ $i -le 100 ]
do
s=$[$s+$i]
i=$[$i+1]
done
echo $s
[atguigu@hadoop101 datas]$ chmod 777 while.sh
[atguigu@hadoop101 datas]$ ./while.sh
50507.read读取控制台输入
read(选项)(参数)
选项-p指定读取值时的提示符-t指定读取值时等待的时间秒。
参数变量指定读取值的变量名
案例提示7秒内读取控制台输入的名称
[atguigu@hadoop101 datas]$ touch read.sh
[atguigu@hadoop101 datas]$ vim read.sh
#!/bin/bash
read -t 7 -p "Enter your name in 7 seconds " NAME
echo $NAME
[atguigu@hadoop101 datas]$ ./read.sh
Enter your name in 7 seconds xiaoze
xiaoze8.函数
1系统函数
a. basename
basename [string / pathname] [suffix] 功能描述basename命令会删掉所有的前缀包括最后一个‘/’字符然后将字符串显示出来。
[atguigu@hadoop101 datas]$ basename /home/atguigu/banzhang.txt
banzhang.txt
[atguigu@hadoop101 datas]$ basename /home/atguigu/banzhang.txt .txt
banzhangb.dirname
dirname 文件绝对路径 功能描述从给定的包含绝对路径的文件名中去除文件名非目录的部分然后返回剩下的路径目录的部分
[atguigu@hadoop101 ~]$ dirname /home/atguigu/banzhang.txt
/home/atguigu2自定义函数
自定义函数的语法如下所示
#定义函数
[ function ] funname[()]
{
Action;
[return int;]
}
#调用函数
funname注意事项
①必须在调用函数地方之前先声明函数shell脚本是逐行运行。不会像其它语言一样先编译。
②函数返回值只能通过$?系统变量获得可以显示加return返回如果不加将以最后一条命令运行结果作为返回值。return后跟数值n(0-255)
[atguigu@hadoop101 datas]$ touch fun.sh
[atguigu@hadoop101 datas]$ vim fun.sh
#!/bin/bash
function sum()
{
s=0
s=$[ $1 + $2 ]
echo "$s"
}
read -p "Please input the number1: " n1;
read -p "Please input the number2: " n2;
sum $n1 $n2;
[atguigu@hadoop101 datas]$ chmod 777 fun.sh
[atguigu@hadoop101 datas]$ ./fun.sh
Please input the number1: 2
Please input the number2: 5
79.Shell工具
1cut
cut [选项参数] filename
| 选项参数 | 功能 |
| -f | 列号提取第几列 |
| -d | 分隔符按照指定分隔符分割列 |
| -c | 指定具体的字符 |
操作案例
a.准备数据
[atguigu@hadoop101 datas]$ touch cut.txt
[atguigu@hadoop101 datas]$ vim cut.txt
dong shen
guan zhen
wo wo
lai lai
le leb.切割cut.txt第一列
[atguigu@hadoop101 datas]$ cut -d " " -f 1 cut.txt
dong
guan
wo
lai
lec.切割cut.txt第二、三列
[atguigu@hadoop101 datas]$ cut -d " " -f 2,3 cut.txt
shen
zhen
wo
lai
led.在cut.txt文件中切割出guan
[atguigu@hadoop101 datas]$ cat cut.txt | grep "guan" | cut -d " " -f 1
guane.选取系统PATH变量值第2个“”开始后的所有路径
[atguigu@hadoop101 datas]$ echo $PATH
/usr/lib64/qt-3.3/bin:/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin:/home/atguigu/bin
[atguigu@hadoop102 datas]$ echo $PATH | cut -d: -f 2-
/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin:/home/atguigu/binf.切割ifconfig 后打印的IP地址
[atguigu@hadoop101 datas]$ ifconfig eth0 | grep "inet addr" | cut -d: -f 2 | cut -d" " -f1
192.168.1.1022awk
1基本用法
awk [选项参数] ‘pattern1{action1} pattern2{action2}...’ filename
pattern表示AWK在数据中查找的内容就是匹配模式
action在找到匹配内容时所执行的一系列命令
2选项参数说明
| 选项参数 | 功能 |
| -F | 指定输入文件折分隔符 |
| -v | 赋值一个用户定义变量 |
3案例
①只显示/etc/passwd的第一列和第七列以逗号分割且在所有行前面添加列名usershell在最后一行添加"dahaige/bin/zuishuai"
[atguigu@hadoop102 datas]$ awk -F : 'BEGIN{print "user, shell"} {print $1","$7} END{print "dahaige,/bin/zuishuai"}' passwd
user, shell
root,/bin/bash
bin,/sbin/nologin
。。。
atguigu,/bin/bash
dahaige,/bin/zuishuai注意BEGIN 在所有数据读取行之前执行END 在所有数据执行之后执行。
②将passwd文件中的用户id增加数值1并输出
[atguigu@hadoop102 datas]$ awk -v i=1 -F: '{print $3+i}' passwd
1
2
3
44内置变量
| 变量 | 说明 |
| FILENAME | 文件名 |
| NR | 已读的记录数行数 |
| NF | 浏览记录的域的个数切割后列的个数 |
统计passwd文件名每行的行号每行的列数
[atguigu@hadoop102 datas]$ awk -F: '{print "filename:" FILENAME ", linenumber:" NR ",columns:" NF}' passwd
filename:passwd, linenumber:1,columns:7
filename:passwd, linenumber:2,columns:7
filename:passwd, linenumber:3,columns:7切割IP
[atguigu@hadoop102 datas]$ ifconfig eth0 | grep "inet addr" | awk -F: '{print $2}' | awk -F " " '{print $1}'
192.168.1.102查询cut.txt中空行所在的行号
[atguigu@hadoop102 datas]$ awk '/^$/{print NR}' cut.txt
53sort
sort命令是在Linux里非常有用它将文件进行排序并将排序结果标准输出。
1基本语法
sort(选项)(参数)
| 选项 | 说明 |
| -n | 依照数值的大小排序 |
| -r | 以相反的顺序来排序 |
| -t | 设置排序时所用的分隔字符 |
| -k | 指定需要排序的列 |
2案例实操
数据准备
[atguigu@hadoop102 datas]$ touch sort.sh
[atguigu@hadoop102 datas]$ vim sort.sh
bb:40:5.4
bd:20:4.2
xz:50:2.3
cls:10:3.5
ss:30:1.6按照“”分割后的第三列倒序排序
[atguigu@hadoop102 datas]$ sort -t : -nrk 3 sort.sh
bb:40:5.4
bd:20:4.2
cls:10:3.5
xz:50:2.3
ss:30:1.610.正则表达式
1常规匹配
一串不包含特殊字符的正则表达式匹配它自己例如
[atguigu@hadoop102 datas]$ cat /etc/passwd | grep atguigu就会匹配所有包含atguigu的行
2常用特殊字符
1特殊字符^
^ 匹配一行的开头例如
[atguigu@hadoop102 datas]$ cat /etc/passwd | grep ^a会匹配出所有以a开头的行。
2特殊字符$
$ 匹配一行的结束例如
[atguigu@hadoop102 datas]$ cat /etc/passwd | grep t$会匹配出所有以t结尾的行
3特殊字符.
. 匹配一个任意的字符例如
[atguigu@hadoop102 datas]$ cat /etc/passwd | grep r..t会匹配包含rabt,rbbt,rxdt,root等的所有行
4特殊字符*
* 不单独使用他和左边第一个字符连用表示匹配上一个字符0次或多次例如
会匹配rt, rot, root, rooot, roooot等所有行
.* 匹配任何字符
5特殊字符[ ]
[ ] 表示匹配某个范围内的一个字符例如
[6,8]------匹配6或者8
[a-z]------匹配一个a-z之间的字符
[a-z]*-----匹配任意字母字符串
[a-c, e-f]-匹配a-c或者e-f之间的任意字符
[atguigu@hadoop102 datas]$ cat /etc/passwd | grep r[a,b,c]*t会匹配rat, rbt, rabt, rbact等等所有行
6特殊字符\
\ 表示转义并不会单独使用。由于所有特殊字符都有其特定匹配模式当我们想匹配某一特殊字符本身时例如我想找出所有包含 '$' 的行就会碰到困难。此时我们就要将转义字符和特殊字符连用来表示特殊字符本身例如
[atguigu@hadoop102 datas]$ cat /etc/passwd | grep a\$b注意直接匹配 $ 字符需要进行转义并且加上单引号
就会匹配所有包含 a$b 的行。