

Windows上基于Tesseract OCR5.0官方语言库的LSTM字库训练-CSDN博客
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
系列文章目录
文章目录
前言
TesseractOCR官方提供了训练好的标准语言包traineddata文件涵盖多国语言每个语言一个库文件。某些特定文字(LED灯的数字等)在官方语言库识别效果不好的情况下还可以自己训练语言库。本文讲述基于官方语言库的LSTM字库训练方法和步骤。
一、LSTM字库训练是什么
LSTM字库训练是指使用长短期记忆LSTM神经网络模型对特定文本或字符集进行训练以识别和分类其中的字符或单词。通过训练LSTM模型可以学习到文本的内在特征和模式从而在给定的文本数据集上提高OCR识别的准确率。
在训练过程中LSTM模型将文本数据作为输入通过反向传播算法不断调整模型的参数以最小化预测错误。训练的目标是使得模型能够正确识别并输出给定文本中的每个字符或单词。一旦训练完成就可以将训练好的模型应用于新的文本数据实现高效的OCR识别。
总之LSTM字库训练是指使用LSTM模型对特定文本集进行训练以提高OCR识别的准确率。
二、使用步骤
1. 环境准备
1.1下载Tesseract 程序并安装
官方没有最新的window安装程序。不过官网上有提供第三方的下载渠道。
有64位和32位的版本根据需要下载最新的版本并安装。
安装完成需把安装目录添加到环境变量。默认安装目录(C:\Program Files (x86)\Tesseract-OCR)
官方下载文档https://tesseract-ocr.github.io/tessdoc/Downloads.html
官方推荐下载渠道https://digi.bib.uni-mannheim.de/tesseract/
1.2下载Tesseract 训练字库
用LSTM训练字库的话一定要用 tessdata_best 字库。需要哪个语言下载哪个语言库。
比如中文简体是chi_sim.traineddata英语是eng.traineddata
官方下载地址
1.3下载工具jTessBoxEditor
网址https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/
下载后将之解压缩到C盘某个目录这个工具是用来训练样本用的(错误标注并更正)。
该工具是用Java开发的需要安装jdk环境
网址https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
2. LSTM训练
2.1 将要训练的图片(jpg/tif)合并成一个文件
打开jTessBoxEditor解压缩的目录双击执行jTessBoxEditorFX.jar或者train.bat
窗口打开后工具栏上依次Tools->Merge Tiff 选中需要训练的图片指定目录和命名合成后的文件。合成后会弹出如下Msg提示合并成功。然后检查指定目录下是否生成了合并好的tif文件(保存多种图片的信息)。
目录C:\Users\shen_pengfei.pfu\Desktop\LSTMTrain
合成文件eng.normal.exp1.list.tif
2.2 生成box文件
2.2.1 通过命令生成box文件
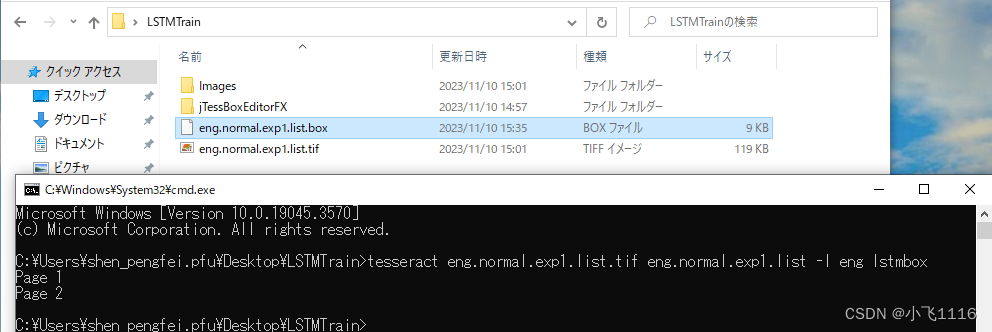
在合并后的tif文件所在目录启动cmd输入以下命令生成box文件eng.normal.exp1.list.box(保存图像中文字的位置信息比如坐标、宽、高等)。
box 文件名和tif 文件名需要一致且位于同一目录
tesseract eng.normal.exp1.list.tif eng.normal.exp1.list -l eng lstmbox
命令格式tesseract tif filename.tif box filenam -l lang lstmbox
2.3 字符校正
打开jTessBoxEditor工具然后依次Box Editor->Open选择eng.normal.exp1.list.tif文件右边显示原稿识别的区域以行位单位坐边对应识别的结果以字符位单位。在左边区域依次对识别错误的每个字符进行校正同时如果有减少或增加的字符也要在左边区域进行相应的增加或删除。
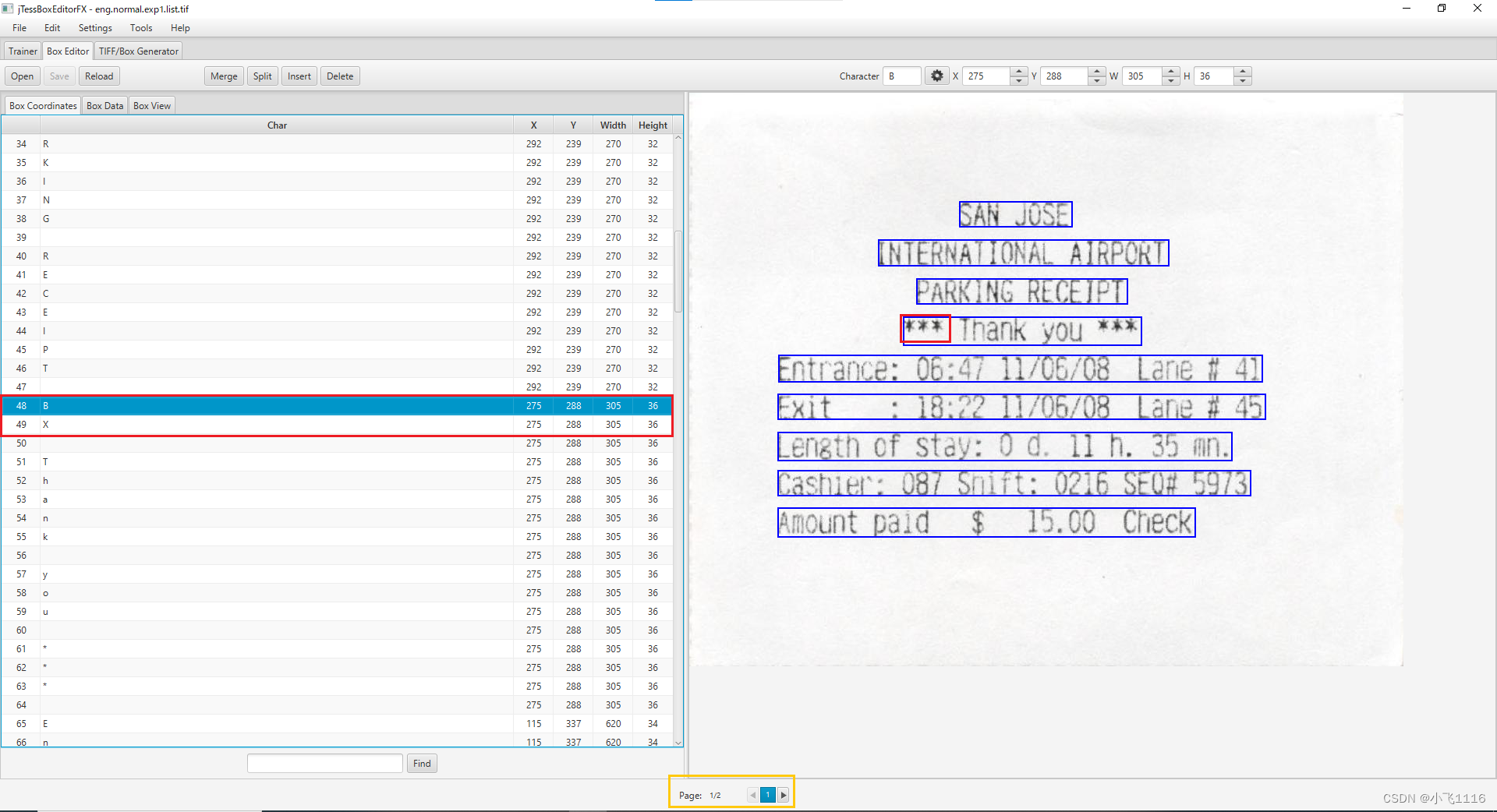
比如红色框选的地方***识别成了BX既识别错误也减少了一个字符。校正后首先更改位正确字符同时追加一个字符。
注意追加字符的时候相应的坐标也要更改

一页的内容都校正完后保存本页更改。然后点击下一页(黄色框选)继续校正。
2.3 生成.lstmf文件
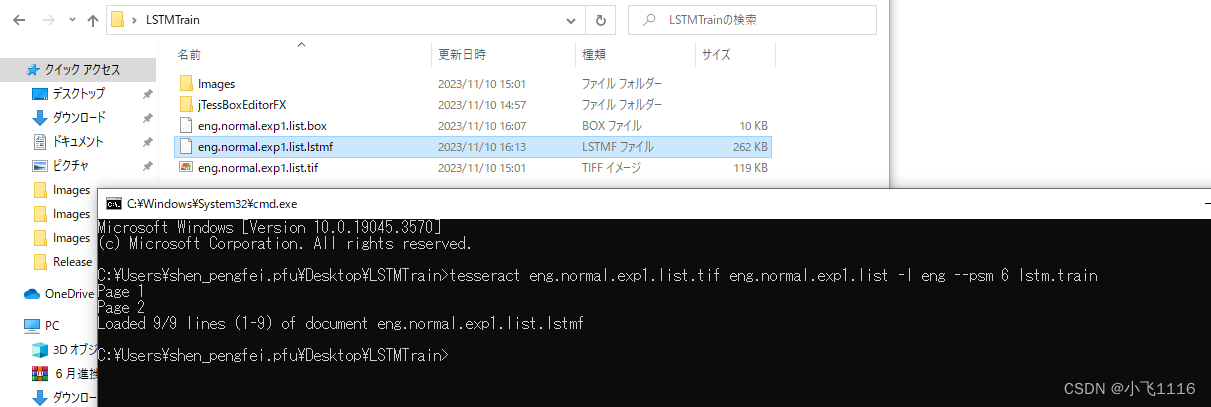
在合并后的tif文件和box文件所在目录启动cmd输入以下命令生成eng.normal.exp1.list.lstmf文件用于训练。
tesseract eng.normal.exp1.list.tif eng.normal.exp1.list -l eng --psm 6 lstm.train
命令格式 tesseract ‘tif filename’.tif lstmf filename -l lang –分割模式 lstm.train
分割模式汇总尝试不同分割模式精度有差异。
0 Orientation and script detection (OSD) only.
1 Automatic page segmentation with OSD.
2 Automatic page segmentation, but no OSD, or OCR.
3 Fully automatic page segmentation, but no OSD. (Default)
4 Assume a single column of text of variable sizes.
5 Assume a single uniform block of vertically aligned text.
6 Assume a single uniform block of text.
7 Treat the image as a single text line.
8 Treat the image as a single word.
9 Treat the image as a single word in a circle.
10 Treat the image as a single character.
11 Sparse text. Find as much text as possible in no particular order.
12 Sparse text with OSD.
13 Raw line. Treat the image as a single text line,
2.4 根据官方的.traineddata中提取.lstm文件
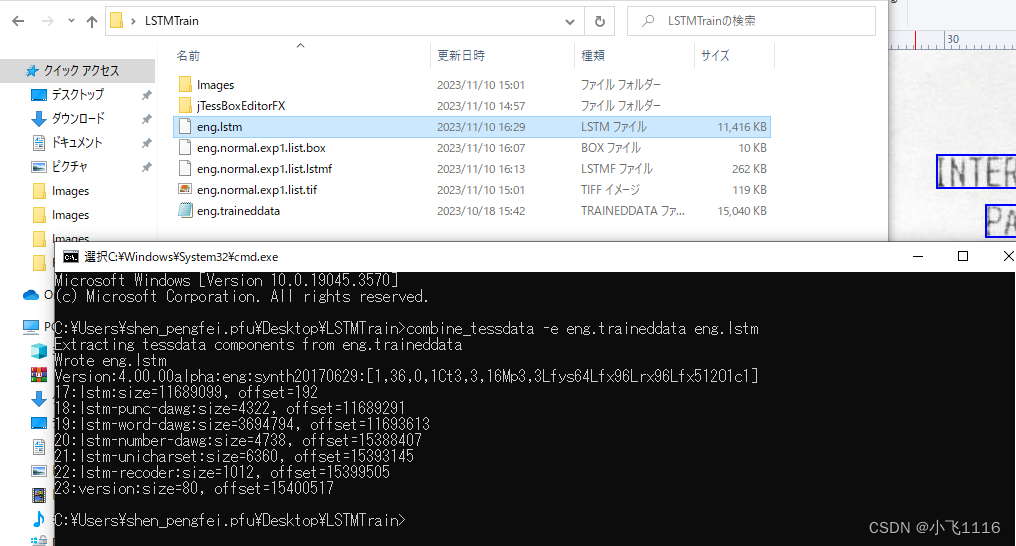
将官方的traineddata文件复制到tif同目录在该目录启动cmd输入以下命令生成.lstmf文件。我这里是用eng.traineddata生成eng.lstmf。
combine_tessdata -e eng.traineddata eng.lstm
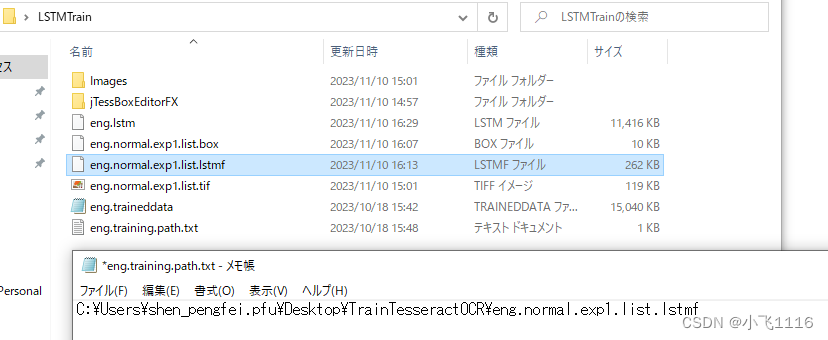
2.5 创建训练用的.txt文件
在tif同目录下创建eng.training.path.txt文件里面内容是.lstmf文件的完整路径。
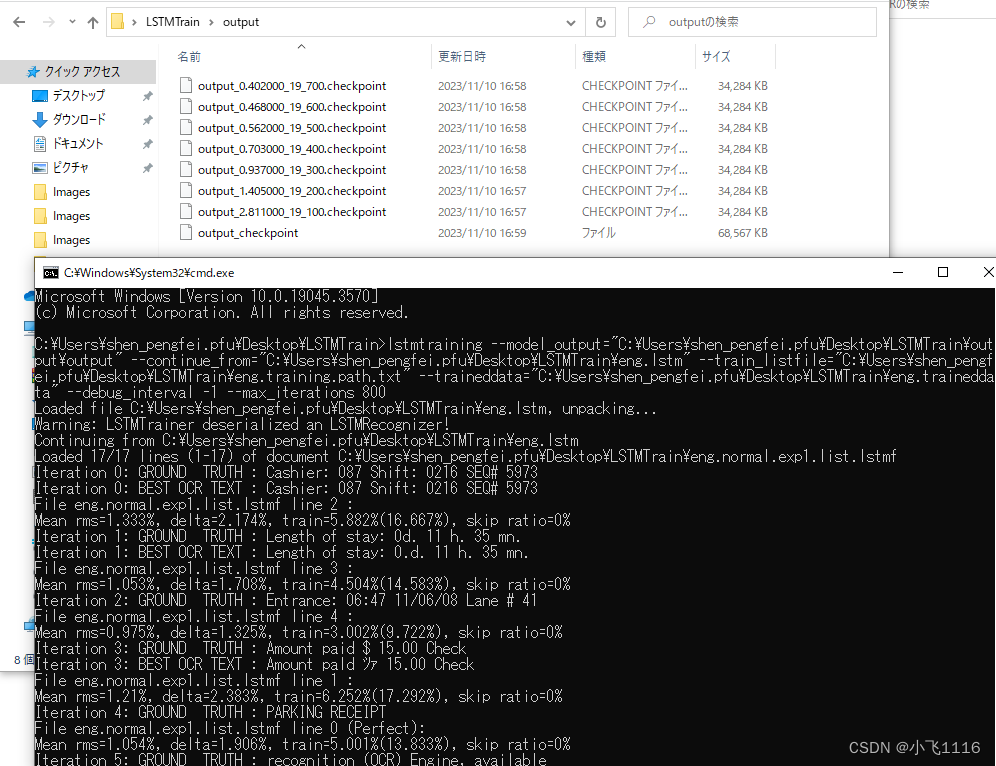
2.6 训练
在tif同目录下创建output子目录。然后该目录cmd输入以下命令进行训练。此步比较耗时耐心等待。最好会在output文件夹下生成一堆checkpoint文件。
lstmtraining --model_output=“C:\Users\xxxx\Desktop\LSTMTrain\output”
–continue_from=“C:\Users\xxxx\Desktop\LSTMTrain\eng.lstm” --train_listfile=“C:\Users\xxxx\Desktop\LSTMTrain\eng.training.path.txt”
–traineddata=“C:\Users\xxxx\Desktop\LSTMTrain\eng.traineddata” --debug_interval -1 --max_iterations 800
参数含义
–model_output 指定训练输出路径
–continue_from 训练base这里指定 eng.lstm文件
–train_listfile 指定上一步创建的文件的路径
–traineddata 指定.traineddata文件的路径
–debug_interval 当值为-1时训练结束会显示训练的一些结果参数
–max_iterations 指定训练遍历次数
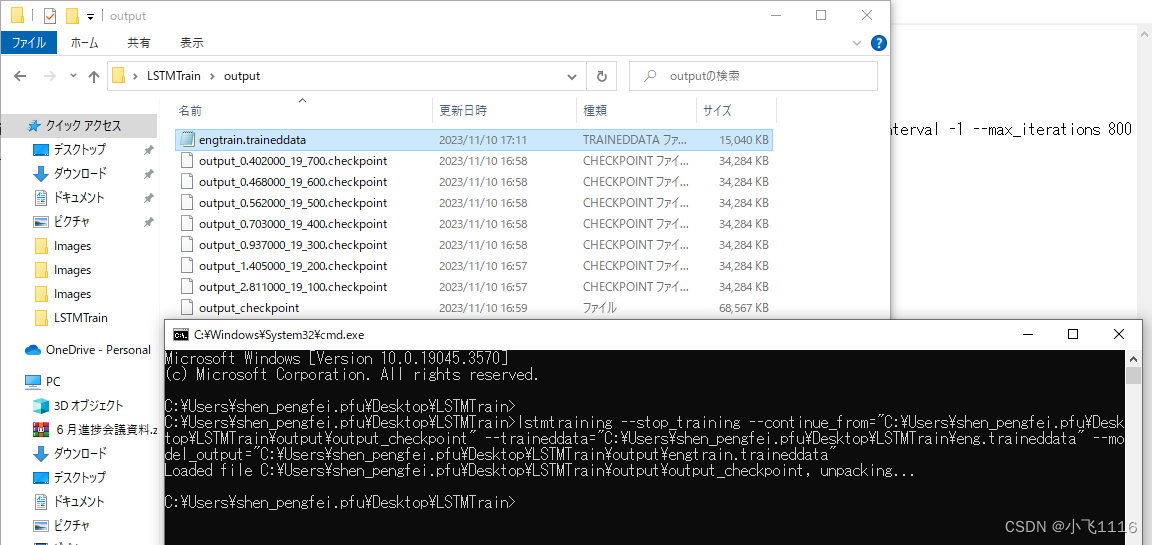
2.7 生成新的语言库
输入以下命令将checkpoint文件和.traineddata文件合并成新的.traineddata文件
eddata=“C:\Users\xxxx\Desktop\LSTMTrain\eng.traineddata”
–model_output=“C:\Users\xxxx\Desktop\LSTMTrain\output\engtrain.traineddata”
参数含义
–stop_training 默认要有的
–continue_from output_checkpoint文件路径
–traineddata 官方的.traineddata文件的路径
–model_output 新的.traineddata 输出的路径
2.8 检验
用新生成的engtrain.traineddata文件识别原来的图像看是否改善。
实测下来虽然校正的图像再识别的时候得到了改善但是如果训练的原稿不够多的话对没有训练的图像有较大劣化效果。所以一般不建议自己训练字库官方的字库基本足够用
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |