

【音视频 | opus】opus编码的Ogg封装文件详解-CSDN博客
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
博客主页https://blog.csdn.net/wkd_007
博客内容嵌入式开发、Linux、C语言、C++、数据结构、音视频
本文内容介绍 opus 编码的 Ogg 封装文件
金句分享
本文未经允许不得转发
opus和Ogg相关系列文章
1、RFC3533 Ogg封装格式版本 0(The Ogg Encapsulation Format Version 0)
2、Ogg封装格式详解——包含Ogg封装过程、数据包(packet)、页(page)、段(segment)等
3、libogg库详解介绍以及使用——附带libogg库解析.opus文件的C源码
4、RFC7845Opus音频编解码器的Ogg封装(Ogg Encapsulation for the Opus Audio Codec)
5、opus编解码库(opus-1.4)详细介绍以及使用——附带解码示例代码
6、opus编码的Ogg封装文件详解
目录
![]()
一、概述
前面的文章 Ogg封装格式详解 介绍了Ogg格式的封装介绍了封装过程、Ogg的页结构、Ogg的段但没涉及到每个段的内容因为这跟编码有关系。本文就介绍 opus 编码在 Ogg 封装文件中是怎样存储的同样地从一个 opus 编码的Ogg文件去查看十六进制最终了解 opus 编码 Ogg 封装文件的整个结构这样就可以轻易将这类文件解码为PCM了。
opus 编码的Ogg文件结构如下图
- 逻辑Ogg比特流中的第一个数据包必须包含ID头部数据(ID Header)该头部数据将流唯一标识为Opus音频。
- 逻辑Ogg比特流中的第二个数据包必须包含注释头部数据(Comment Header)其中包含用户提供的元数据。
- 之后的所有页面(page)都是音频数据页面。

下文分析的Ogg封装文件为 48000Hz-s16le-1ch-ChengDu.opus下载链接https://download.csdn.net/download/wkd_007/88492683
![]()
二、ID头部数据(ID Header)
✨2.1、ID 头部数据的介绍
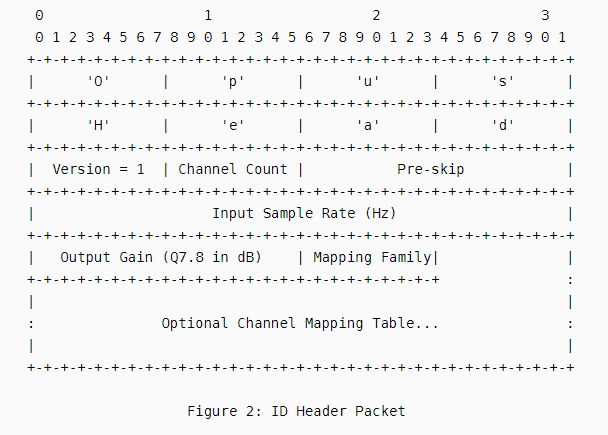
opus编码的逻辑Ogg比特流中第一页必须包含ID头部数据其结构如下图包括8个字段各个字段代表的含义如下
-
1、Magic Signature(8字节)
这是一个8位字节64位字段允许编解码器识别并且是人类可读的。它按顺序包含以下的字母
0x4F 'O' 0x70 'p' 0x75 'u' 0x73 's' 0x48 'H' 0x65 'e' 0x61 'a' 0x64 'd'从“Op”开始有助于将其与音频数据包区分开来因为这是一个无效的TOC序列。
-
2、Version (1字节, unsigned):
对于此版本的封装规范版本号必须始终为“1”。实现应该将版本号的前四位与已识别规范的版本号匹配的流视为与该规范向后兼容。也就是说版本号可以分为“主要”和“次要”版本子字段次要子字段的变化在较低的四位中表示兼容的变化。例如本规范的实现应该接受版本号为“15”或更低的任何流并且应该假设版本号为”16“或更高的任何流不兼容。选择初始版本“1”是为了防止实现依赖此八位字节作为“OpusHead”字符串的null终止符。 -
3、Output Channel Count ‘C’ (1字节, unsigned)
这是输出通道的数量。这可能与编码信道的数量不同编码信道的数目可以在逐包的基础上改变。此值不得为零。最大允许值取决于通道映射族可能大到255。详见[RFC7845]文档的第5.1.1节。 -
4、Pre-skip (2字节, unsigned, little endian):
这是开始播放时要从解码器输出中丢弃的采样数48 kHz也是要从页面的颗粒位置中减去以计算其PCM采样位置的数量。当裁剪现有Ogg Opus流的开头时建议预跳过至少3840个样本80ms以确保解码器完全收敛。
-
5、Input Sample Rate (4字节, unsigned, little endian):
这是原始输入编码前的采样率单位为Hz。该字段不是用于播放编码数据的采样率。
Opus可以在4、6、8、12和20kHz的内部音频带宽之间切换。流中的每个数据包可以具有不同的音频带宽。不管音频带宽如何参考解码器都支持以8、12、16、24或48kHz的采样率对任何流进行解码。传递到编码器的音频的原始采样率不被有损压缩所保留。
Ogg Opus播放器应根据以下程序选择播放采样率
1.如果硬件支持48 kHz播放则以48 kHz进行解码。
2.否则如果硬件的最高可用采样率是支持的速率则以该采样率进行解码。
3.否则如果硬件的最高可用采样率小于48kHz则以高于最高可用硬件速率的下一个更高的Opus支持速率进行解码并重新采样。
4.否则以48 kHz解码并重新采样。
然而“输入采样率”字段允许复用器将原始输入流的采样率作为元数据传递。当用户需要输出采样率来匹配输入采样率时这是有用的。例如当不播放输出时将PCM格式样本写入磁盘的实现可能会选择将音频重新采样回原始输入采样率以减少用户的意外因为用户可能会合理地期望以相同的采样率返回文件。
零值表示“未指定”。复用器应该写入实际输入采样率或零但使用该字段执行某些操作的实现应该注意如果给定疯狂的值例如如果请求不要实际将输出上采样到10MHz则行为要理智。实现应支持 8kHz 和 192kHz包括8kHz之间的输入采样率。此范围之外的速率可以通过回落到默认速率 48kHz 来忽略。
-
6、Output Gain (2字节, signed, little endian):
这是解码时要应用的增益。它是对解码器输出进行缩放以获得所需播放量的因子的20*log10存储在具有8个小数比特的16比特、带符号的2的补码定点值中即Q7.8[Q-NOTATION]。
为了应用增益实现可以使用以下内容
sample *= pow(10, output_gain/(20.0*256))其中“output_gain”是来自标头的原始16位值。
玩家和媒体框架应该默认应用它。如果播放器选择应用任何音量调整或增益修改如R128_TRACK_AIN见第5.2节则除了此输出增益外还必须应用该调整以实现标准化音量的播放。
复用器应该将该字段设置为零而不是在编码之前应用任何增益只要这是可能的并且不会与用户的愿望相冲突。非零输出增益表示在编码之后调整了增益或者用户希望在保持恢复原始信号幅度的能力的同时调整增益以进行回放。
尽管输出增益具有巨大的范围+/-128 dB足以将听不见的声音放大到身体疼痛的阈值但大多数应用程序只能合理地使用零附近这个范围的一小部分。大范围的部分作用是确保增益始终可以在OpusHead和R128增益标签之间无损传输见下文而不会饱和。
-
7、Channel Mapping Family (1字节, unsigned):
这个八位字节表示输出通道的顺序和语义。
该八位位组的每个当前指定值都指示一个映射族该映射族定义了一组允许的通道计数以及每个允许的通道数的有序通道名称集。详见
[RFC7845]文档的第5.1.1节。 -
8、Channel Mapping Table:
此表定义了从编码流到输出通道的映射。其内容见
[RFC7845]文档的第5.1.1节。ID标头中的所有字段都是必需的但“通道映射表”除外当通道映射族为0时必须省略该字段否则为必需字段。如果流包含的ID标头没有足够的数据用于这些字段即使它包含有效的“魔术签名”实现也应该将其视为无效。该规范的未来版本甚至是向后兼容的版本可能会在ID头中包含额外的字段。如果ID标头具有兼容的主版本但具有较大的次版本则实现不得将其视为无效因为它包含此处未指定的其他数据前提是它仍然在第一页上完成。
✨2.2、.opus 文件 ID头部数据 分析
现在按照上面的字段分析opus编码的Ogg文件用Notepad打开 48000Hz-s16le-1ch-ChengDu.opus 并查看十六进制模式
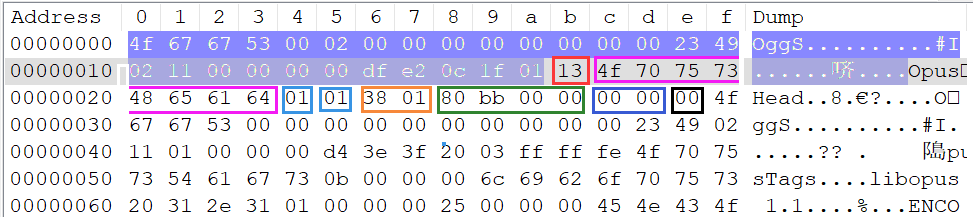
- 前面蓝色背景的部分(包括0x13)是Ogg页头部数据不清楚的看 上篇文章 的 4.2 节
- 紫色框开始是opus编码的ID头部数据内容是8个字符
OpusHead - 接下去的蓝色框是版本号目前的版本该值为
1 - 紧接着的蓝色框是声道数量这里值为
1表示单声道 - 后面的橙色框表示 “开始播放时要从解码器输出中丢弃的采样数”值为
0x0138 - 接着的绿色框表示 “原始输入编码前的采样率”值为
0xbb80对应十进制48000 - 后面的蓝色框表示 “解码时要应用的增益”
- 后面的黑色框表示 “表示输出通道的顺序和语义”值为
0代表使用映射族0允许的通道数1或2且省略通道映射表(Channel Mapping Table)
![]()
三、注释头部数据(Comment Header)
✨3.1、注释头部数据的介绍
opus编码的逻辑Ogg比特流中第二页必须包含注释头部数据。它可能跨越多个页面(page)从逻辑流的第二页开始。无论它跨越多少页注释头数据包都必须结束在一个完整的页面其结构如下图包括6个字段各个字段代表的含义如下

-
1、Magic Signature(8个字节)
这是一个8位字节64位字段允许编解码器识别并且是人类可读的。它按顺序包含以下神奇数字
0x4F 'O' 0x70 'p' 0x75 'u' 0x73 's' 0x54 'T' 0x61 'a' 0x67 'g' 0x73 's'从“Op”开始有助于将其与音频数据包区分开来因为这是一个无效的TOC序列。
-
2、Vendor String Length (4个字节, unsigned, little endian):
此字段给出下个字段
Vendor String的长度单位为八位字节。它不得指示供应商字符串比数据包的其余部分长。 -
3、Vendor String (variable length, UTF-8 vector):
这是一个用于供应商信息的简单可读标签编码为UTF-8字符串[RFC3629]。不需要终止空八位字节。
此标签旨在识别编解码器编码器和封装实现以跟踪技术行为的差异。面向用户的应用程序可以使用“ENCODER”用户注释标记来标识自己。
-
4、User Comment List Length (4个字节, unsigned, little endian):
此字段指示用户提供的注释个数。它可能表示用户提供的注释为零在这种情况下数据包中没有其他字段。它不能表明有太多的注释以至于注释字符串长度需要比数据包其余部分更多的数据。
-
5、User Comment #i String Length (4个字节, unsigned, little endian):
此字段给出下个字段
User Comment #i String的长度单位为八位字节。“用户评论列表长度”字段指示的每个用户评论都有一个。它不能指示字符串比数据包的其余部分长。 -
6、User Comment #i String (variable length, UTF-8 vector):
此字段包含编码为UTF-8字符串的单个用户注释[RFC3629]。“用户评论列表长度”字段指示的每个用户评论都有一个。
✨3.2、.opus 文件 注释头部数据 分析
下图是用Notepad打开 48000Hz-s16le-1ch-ChengDu.opus 并查看十六进制模式的截图这里分析的是第二页数据
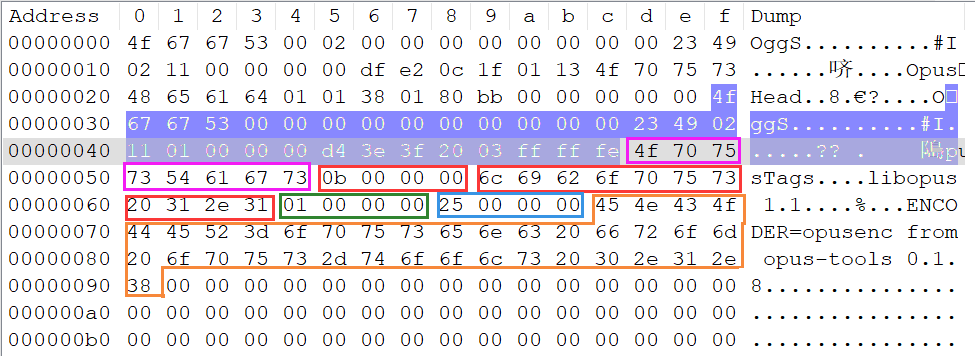
- 前面蓝色背景的部分是Ogg页头部数据不清楚的看 上篇文章 的 4.2 节第二页数据
- 紫色框开始是opus编码的注释头部数据内容是8个字符
OpusTags - 接下去的红色色框的4个字节是供应商字符串长度 此字段给出下个字段
Vendor String的长度这里是0x0b - 紧接着的红色框的11个字节就是供应商字符串内容是
libopus 1.1 - 后面的绿色框表示 “注释个数”值为
0x01表示只有一个注释 - 接着的蓝色框表示 “第一个注释字符串的长度”值为
0x25对应十进制37表示后面有37个字符的注释 - 后面的橙色框表示 “注释字符串”内容是
ENCODER=opusenc form opus-tools 0.1.8共37个字符
![]()
四、opus 编码数据包
在一个opus编码的Ogg格式文件中除了一个ID头部数据包和一个 注释头部数据包(有时可以跨多页)剩下的都是 opus编码音频数据包音频数据包也是存储在Ogg格式文件的各个段(Segment)中下面从一个实际的Ogg文件分析音频数据包。
下图是用Notepad打开 48000Hz-s16le-1ch-ChengDu.opus 并查看十六进制模式的截图这里分析的是第三页数据
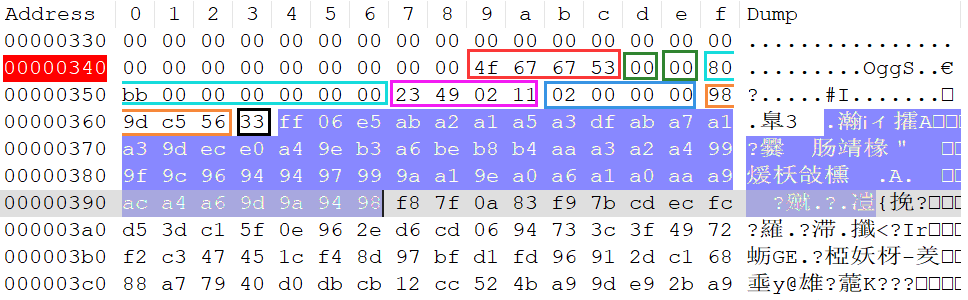
- 图中黑色框表示该Ogg页数据中有
0x33(十进制51)个段(Segment)但并不表示有51个opus音频数据包因为段的长度为0xff时表示该段存不下一个音频数据包下个段仍然是这个包的数据。 - 蓝色背景的
51个字节就是各个段的长度可以看到第一个段长度是0xff表示第一个音频包存储了2个段第一个音频包的实际长度应该是0xff+0x06后面49个段长度中都没有0xff说明每个都存储了一个音频数据包。所以这一页应该是50个音频数据包。每个数据包读取后都可以直接送到opus-1.4的库去解码成PCM音频数据。
![]()
五、opus编码的Ogg封装文件解码C语言源码
清楚了前面的知识就可以对opus编码的Ogg文件进行解码了你可以使用 libogg库加上 opus-1.4 的库进行解码那样会更简洁一点下面给出的源码只使用了opus-1.4去解码音频包有很大的参考价值
opusDec.h
/**
* @file opusDec.h
* @author wkd_007
* @date 2023-10-27 15:47:38
*/
#ifndef __OPUS_DEC_H__
#define __OPUS_DEC_H__
#include "opus/opus.h"
#define MAX_OPUS_DEC_FRAME 48000 // opus解码最大采样点个数如果个数时间小于120ms可能停止解码这里设置1000ms的个数
#define OPUS_DEC_CHANNELS 2
class COpusDec
{
public:
COpusDec();
~COpusDec();
int CreateOpusDecoder(int sampleRate, int channels);
int OpusDecode(unsigned char* in_data, int in_len, short *out_buf);
private:
OpusDecoder *decoder; // opus 解码器指针
int sample_rate; // 采样率
int channel_num; // 通道数
};
#endif// __OPUS_DEC_H__
opusDec.cpp
/**
* @file opusDec.cpp
* @author wkd_007
* @brief opus 解码
* @date 2023-10-27 15:38:43
*/
#include <stdio.h>
#include "opusDec.h"
COpusDec::COpusDec()
{
decoder = NULL;
sample_rate = 0;
channel_num = 0;
}
COpusDec::~COpusDec()
{
sample_rate = 0;
channel_num = 0;
if(decoder)
{
opus_decoder_destroy(decoder);
decoder = NULL;
}
}
int COpusDec::CreateOpusDecoder(int sampleRate, int channels)
{
int err = 0;
decoder = opus_decoder_create(sampleRate, channels, &err);
if(err != OPUS_OK || decoder == NULL)
{
printf("[%s %d]err=%d decoderIsNULL=%d\n",__FILE__,__LINE__,err, decoder == NULL);
return -1;
}
opus_decoder_ctl(decoder, OPUS_SET_LSB_DEPTH(16));
sample_rate = sampleRate;
channel_num = channels;
return err;
}
int COpusDec::OpusDecode(unsigned char* in_data, int in_len, short *out_buf)
{
if(decoder == NULL)
return -1;
int frame_size = opus_decode(decoder, in_data, in_len, out_buf, MAX_OPUS_DEC_FRAME, 0);
if (frame_size < 0)
{
printf("[%s %d] frame_size=%d in_len=%d\n",__FILE__,__LINE__, frame_size,in_len);
return frame_size;
}
return frame_size;
}
readOggFile.c
// g++ readOggFile.c opusDec.cpp ../../opus-1.4/result_gcc/lib/libopus.a -I ../../opus-1.4/result_gcc/include/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "opusDec.h"
COpusDec g_OpusDec;
// 8字节数组转成 unsigned long long
unsigned long long ToULL(unsigned char num[8], int len)
{
unsigned long long ret = 0;
if(len==8)
{
int i=0;
for(i=0; i<len; i++)
{
ret |= ((unsigned long long)num[i] << (i*8));
}
}
return ret;
}
// 4字节数组转成 unsigned int
unsigned int ToUInt(unsigned char num[4], int len)
{
unsigned int ret = 0;
if(len==4)
{
int i=0;
for(i=0; i<len; i++)
{
ret |= ((unsigned int)num[i] << (i*8));
}
}
return ret;
}
int readOggPage(char *oggFile)
{
typedef struct PAGE_HEADER{
char Oggs[4];
unsigned char ver;
unsigned char header_type_flag;
unsigned char granule_position[8];
unsigned char stream_serial_num[4];
unsigned char page_sequence_number[4];
unsigned char CRC_checksum[4];
unsigned char seg_num;
unsigned char segment_table[];
}PAGE_HEADER;
FILE *fp=fopen(oggFile,"rb");
FILE *fpout=fopen("opus_out.pcm","wb+");;
while(fp!=NULL && !feof(fp))
{
// 1、读取 page_header
PAGE_HEADER page_header;
if(1 != fread(&page_header,sizeof(page_header),1,fp))
break;
printf("page_num:%03u; ",ToUInt(page_header.page_sequence_number, 4));
printf("Oggs:%c %c %c %c; ",page_header.Oggs[0],page_header.Oggs[1],page_header.Oggs[2],page_header.Oggs[3]);
printf("type=%d, granule_position:%08llu; ", page_header.header_type_flag,ToULL(page_header.granule_position, 8));
//printf("seg_num:%d \n",page_header.seg_num);
// 2、读取 Segment_table
unsigned char *pSegment_table = (unsigned char *)malloc(page_header.seg_num);
fread(pSegment_table,sizeof(unsigned char),page_header.seg_num,fp);
// 3、计算段数据总大小
unsigned int TotalSegSize = 0;
int i=0;
for(i=0; i<page_header.seg_num; i++)
{
TotalSegSize += pSegment_table[i];
}
printf("TotalSegSize:%d \n",TotalSegSize);
// 4、读取段数据
unsigned char *pSegment_data = (unsigned char *)malloc(TotalSegSize);
fread(pSegment_data,sizeof(unsigned char),TotalSegSize,fp);
if(page_header.header_type_flag == 4)
printf("Last 4 Byte: %x %x %x %x\n",pSegment_data[TotalSegSize-4],pSegment_data[TotalSegSize-3], pSegment_data[TotalSegSize-2],pSegment_data[TotalSegSize-1]);
// 5、解码opus
unsigned sample_pos = ToULL(page_header.granule_position, 8);
if(sample_pos)
{
short out_buf[48000*2] = {0};
int decodedLen = 0; // 已经解码的长度
int preSegLen =0; // 前面分段的长度
for(i=0; i<page_header.seg_num; i++)
{
if(pSegment_table[i] == 255)// 这个包延续到后面把该段长度累加起来
{
preSegLen += pSegment_table[i];
continue;
}
int decFrames = g_OpusDec.OpusDecode((unsigned char*)pSegment_data+decodedLen, (int)preSegLen+pSegment_table[i], out_buf);
if(decFrames < 0)
{
printf("decodedLen=%d TotalSegSize=%d pSegment_table[i]=%d %d %d\n",decodedLen,
TotalSegSize,pSegment_table[i-1],pSegment_table[i],pSegment_table[i+1]);
}
else
{
fwrite(out_buf,decFrames * sizeof(unsigned short),1,fpout);
}
decodedLen += (preSegLen+pSegment_table[i]);
preSegLen = 0;
}
}
free(pSegment_data);
free(pSegment_table);
}
fclose(fp);
fclose(fpout);
return 0;
}
int main()
{
g_OpusDec.CreateOpusDecoder(48000, 1);
readOggPage((char *)"48000Hz-s16le-1ch-ChengDu.opus");
return 0;
}
![]()
六、总结
本文介绍了opus编码的Ogg文件的 ID数据头部、注释数据头部、opus编码数据包的结构和解析并用一个.opus文件的十六进行带着读者理解各个数据包最后给出了笔者的C语言代码将opus编码Ogg格式解析为PCM。看完一定大有所获别忘记点赞、收藏、支持一下。
如果文章有帮助的话点赞、收藏⭐支持一波谢谢
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |