

MySQL事务四大特性ACID
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
事务:一组操作要么全部成功,要么全部失败,目的是保证数据的一致性。
一、事务四大特性ACID
(一)原子性(Atomicity)
当前事务的操作要么同时成功,要么同时失败。原子性由undo log 日志来实现。
undo log实现方式
当数据库insert一个id=21的数据时,undo log 会同时生成一个delete id=21 的sql,当数据需要回滚时,就会运行delete sql 语句。
(二)一致性(Consistency)
一致性是使用事务的最终目的,由其它三个特性以及业务代码正确逻辑来实现。
(三)隔离性(Isolation)
在事务并发执行时,他们内部的操作不能互相干扰,隔离性由MySQL的各种锁以及MVCC机制来实现。
事务隔离级别
级别越高事务隔离性越好性能越低,隔离级别越低性能越高。
(1)read uncommit(读未提交)
通俗来讲是可以读到未提交事务的数据;
#设置级别为读未提交;
SET SESSION tx_isolation = 'READ-UNCOMMITTED';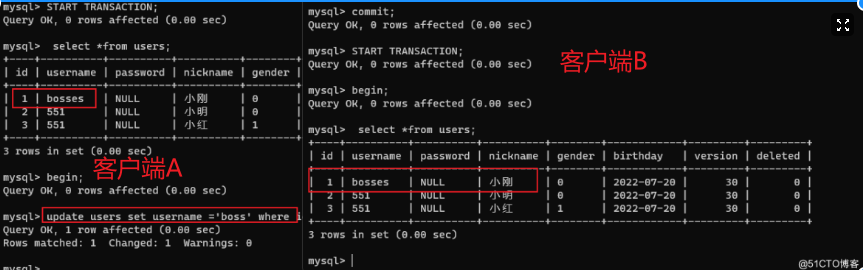
引起的问题:脏读;
- A事务对 id=1 的数据进行了修改而没有提交;
- B事务查询 id=1 的数据是修改后的数据,这条修改后的数据被拿到代码中进行一系列的运算;
- 这个时候A事务中的代码出错需要回滚,提交后 id=1 的数据并没有进行改变,B事务中的代码却拿着错误的数据去返回结果。
(2)read commit(读已提交)
只能读到已经提交后的数据。
#设置级别为读已提交;
SET SESSION tx_isolation = 'READ-COMMITTED';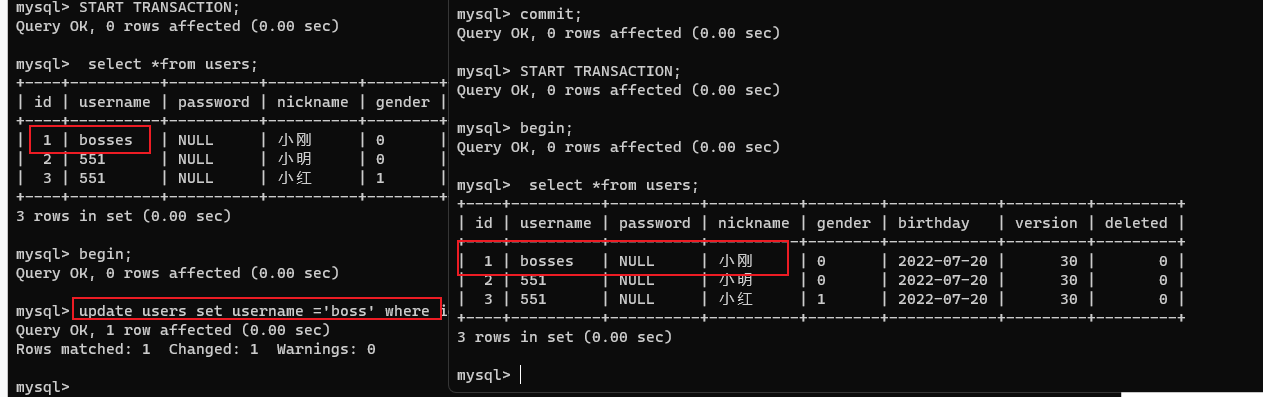
未提交的修改不会被读到;

解决了脏读问题,会引起不可重复读。
初始数据(id=1 ,age=10)
- A事务对 id=1 的数据修改后提交(id=1,age =12);
- B事务查询 id=1 的数据进行了第一次查询(id=1,age =12),没有提交事务;
- C事务也对 id=1 的数据修改并提交(id=1,age=16);
- B事务对 id=1 的数据进行了第二次查询(id =1,age=16);
- 问题就出现了:同一个事务对同一条数据查询结果却不一致!
(3)repeatable read(可重复读)
对不可重复读的优化,当开启事务A查询时,就像生成了一个快照,无论其他事务对数据进行什么修改,事务A中的数据不会发生任何变化。
#设置级别为可重复读;
SET SESSION tx_isolation = 'repeatable-read';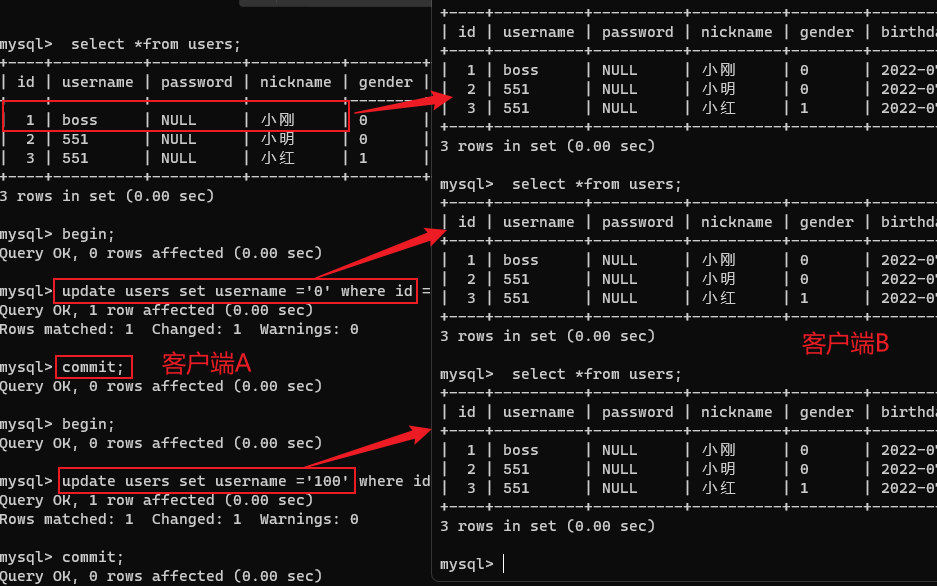
Ⅰ.这里会有一个小问题:(脏写)
数据(id=1 ,price=10)
- B事务对 id=1 的数据开启查询但未提交(id=1,price=10);
- A事务将 id=1 的数据进行了修改(id=1,price=20);
- B事务拿着查到的数据(id =1,price=10)去代码里 price+20 得到(id=1,price=30),然后update到了表中,这个时候数据就发生了冲突!
解决方法:将 price+20 的运算放入SQL中。
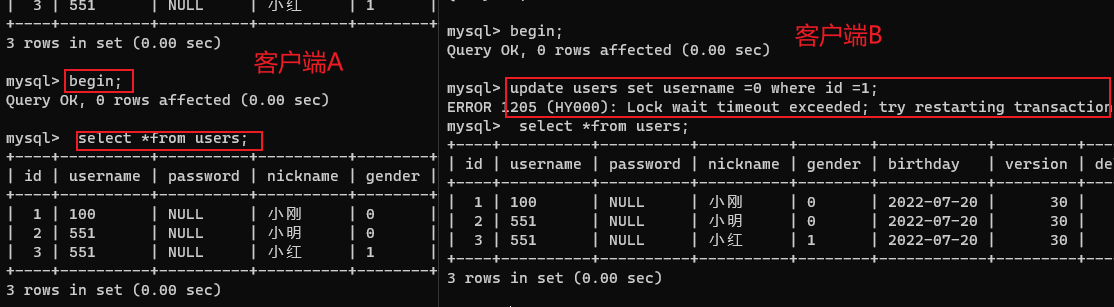
Ⅱ.幻读:事务B读到了事务A新增的数据,单纯可重复读严格意义上来说没有解决可重复读问题。
- 事务B先开始查询,
- 事务A新增一条数据,
- 事务B没有查到新增的数据;
- 但是事务B去修改这条数据时,是可以修改的!
- 事务B修改完毕后再去查询,可以查到新增的数据。
(4)serializable(串行化)
#设置级别为串行化;
SET SESSION tx_isolation = 'serializable';当一个事务A开启查询之后,只有事务A可以进行写操作,其他事务只能读操作。
当事务A开启更新操作未提交事务,其他事务不可以查询该数据。
解决上述所有问题,包括脏写;但会花费大量性能。
(四)持久性(Durability)
一旦提交了事务,对数据库的修改应该是持久性的。持久性由redo log日志来实现。
二、MVCC机制多版本并发控制实现方式:
MySQL会在每条数据后添加trx_id(事务版本id),roll_pointer(回滚指针),
回滚指针:当事务出现问题发生回滚时,回滚指针就会指向undo log中的sql,进行数据回滚。
事务版本id:数据开启事务生成的id。
三、查询操作方法是否需要开启事务?
MySQL默认隔离级别是RR,如果说是统计报表且多个查询时,如果不加事务不能保证级别是RR,在同一事务中,如果第一条查询之后,相隔一段时间再次查询第二条语句,第二条数据大小已经和第一条的数据不是同一时间段数据,造成一些误差。
四、大事务的影响
- 并发情况下,数据库连接池容易被撑爆
- 锁定太多的数据,造成大量的阻塞和锁超时
- 执行时间长,容易造成主从延迟
- 回滚所需要的时间比较长
- undo log膨胀
- 容易导致死锁
五、事务优化实践原则
- 将查询等数据准备操作放到事务外(RC级别下)
- 事务中避免远程调用,远程调用要设置超时,防止事务等待时间太久
- 事务中避免一次性处理太多数据,可以拆分成多个事务分次处理
- 更新等涉及加锁的操作尽可能放在事务靠后的位置
- 能异步处理的尽量异步处理
- 应用侧(业务代码)保证数据一致性,非事务执行
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |