

Mybatis——面试问题
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
摘要
主要介绍的是的Mybatis的面试问题

Mybatis的原理分为六个部分:
- 读取核心配置文件并返回
InputStream流对象。 - 根据
InputStream流对象解析出Configuration对象,然后创建SqlSessionFactory工厂对象 - 根据一系列属性从
SqlSessionFactory工厂中创建SqlSession - 从
SqlSession中调用Executor执行数据库操作&&生成具体SQL指令 - 对执行结果进行二次封装
- 提交与事务
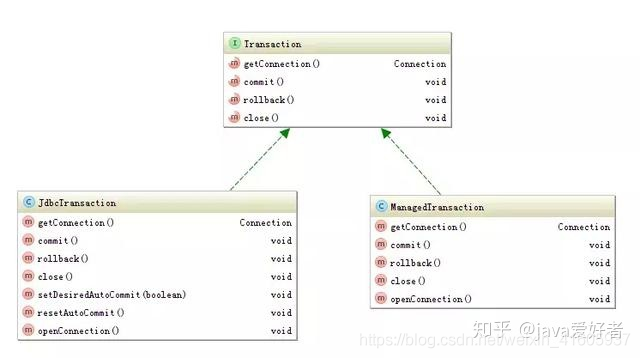
MyBatis的事务管理分为两种形式:
1、使用JDBC的事务管理机制:即利用java.sql.Connection对象完成对事务的提交(commit())、回滚(rollback())、关闭(close())等
2、使用MANAGED的事务管理机制:这种机制MyBatis自身不会去实现事务管理,而是让程序的容器如(JBOSS,Weblogic)来实现对事务的管理
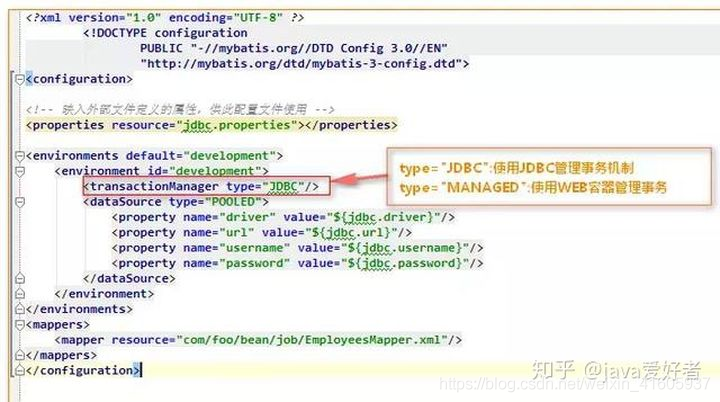
MyBatis事务的配置
在使用MyBatis时,一般会在MyBatisXML配置文件中定义类似如下的信息:
JdbcTransaction:JdbcTransaction直接使用JDBC的提交和回滚事务管理机制 。它依赖与从dataSource中取得的连接connection 来管理transaction 的作用域,connection对象的获取被延迟到调用getConnection()方法。如果autocommit设置为on,开启状态的话,它会忽略commit和rollback。直观地讲,就是JdbcTransaction是使用的java.sql.Connection 上的commit和rollback功能,JdbcTransaction只是相当于对java.sql.Connection事务处理进行了一次包装(wrapper),Transaction的事务管理都是通过java.sql.Connection实现的。
ManagedTransaction:ManagedTransaction让容器来管理事务Transaction的整个生命周期,意思就是说,使用ManagedTransaction的commit和rollback功能不会对事务有任何的影响,它什么都不会做,它将事务管理的权利移交给了容器来实现。
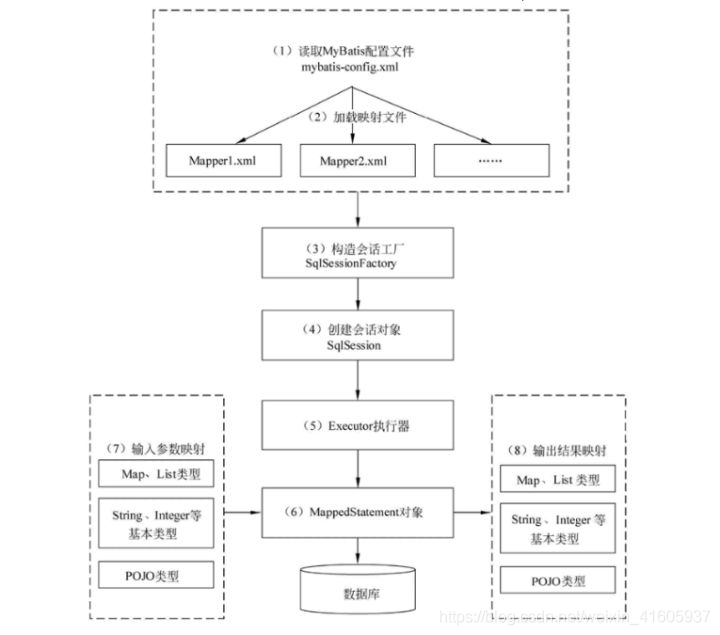
1)读取 MyBatis 配置文件:mybatis-config.xml 为 MyBatis 的全局配置文件,配置了 MyBatis 的运行环境等信息,例如数据库连接信息。
2)加载映射文件。映射文件即 SQL 映射文件,该文件中配置了操作数据库的 SQL 语句,需要在 MyBatis 配置文件 mybatis-config.xml 中加载。mybatis-config.xml 文件可以加载多个映射文件,每个文件对应数据库中的一张表。
3)构造会话工厂:通过 MyBatis 的环境等配置信息构建会话工厂 SqlSessionFactory。
4)创建会话对象:由会话工厂创建 SqlSession 对象,该对象中包含了执行 SQL 语句的所有方法。
5)Executor 执行器:MyBatis 底层定义了一个 Executor 接口来操作数据库,它将根据 SqlSession 传递的参数动态地生成需要执行的 SQL 语句,同时负责查询缓存的维护。
6)MappedStatement 对象:在 Executor 接口的执行方法中有一个 MappedStatement 类型的参数,该参数是对映射信息的封装,用于存储要映射的 SQL 语句的 id、参数等信息。
7)输入参数映射:输入参数类型可以是 Map、List 等集合类型,也可以是基本数据类型和 POJO 类型。输入参数映射过程类似于 JDBC 对 preparedStatement 对象设置参数的过程。
8)输出结果映射:输出结果类型可以是 Map、 List 等集合类型,也可以是基本数据类型和 POJO 类型。输出结果映射过程类似于 JDBC 对结果集的解析过程。
解释一下MyBatis中命名空间(namespace)的作用。
在大型项目中,可能存在大量的SQL语句,这时候为每个SQL语句起一个唯一的标识(ID)就变得并不容易了。为了解决这个问题,在MyBatis中,可以为每个映射文件起一个唯一的命名空间,这样定义在这个映射文件中的每个SQL语句就成了定义在这个命名空间中的一个ID。只要我们能够保证每个命名空间中这个ID是唯一的,即使在不同映射文件中的语句ID相同,也不会再产生冲突了。
阐述Session加载实体对象的过程?
- 1、Session在调用数据库查询功能之前,首先会在一级缓存中通过实体类型和主键进行查找,如果一级缓存查找命中且数据状态合法,则直接返回;
- 2、如果一级缓存没有命中,接下来Session会在当前NonExists记录(相当于一个查询黑名单,如果出现重复的无效查询可以迅速做出判断,从而提升性能)中进行查找,如果NonExists中存在同样的查询条件,则返回null;
- 3、如果一级缓存查询失败查询二级缓存,如果二级缓存命中直接返回;
- 4、如果之前的查询都未命中,则发出SQL语句,如果查询未发现对应记录则将此次查询添加到Session的NonExists中加以记录,并返回null;
- 5、根据映射配置和SQL语句得到ResultSet,并创建对应的实体对象;
- 6、将对象纳入Session(一级缓存)的管理;
- 7、如果有对应的拦截器,则执行拦截器的onLoad方法;
- 8、如果开启并设置了要使用二级缓存,则将数据对象纳入二级缓存;
- 9、返回数据对象。
Mybatis框架使用不当导致的SQL注入问题为例:
Mybatis的SQL注入:Mybatis的SQL语句可以基于注解的方式写在类方法上面,更多的是以xml的方式写到xml文件。Mybatis中SQL语句需要我们自己手动编写或者用generator自动生成。编写xml文件时,MyBatis支持两种参数符号,一种是#,另一种是$。比如:
<select id="queryAll" resultMap="resultMap">
SELECT * FROM NEWS WHERE ID = #{id}
</select>#使用预编译,$使用拼接SQL。Mybatis框架下易产生SQL注入漏洞的情况主要分为以下三种:
1、模糊查询
Select * from news where title like ‘%#{title}%’在这种情况下使用#程序会报错,新手程序员就把#号改成了$,这样如果java代码层面没有对用户输入的内容做处理势必会产生SQL注入漏洞。
正确写法:
select * from news where tile like concat(‘%’,#{title}, ‘%’)2、in 之后的多个参数
in之后多个id查询时使用# 同样会报错,
Select * from news where id in (#{ids})正确用法为使用foreach,而不是将#替换为$
id in
<foreach collection="ids" item="item" open="("separatosr="," close=")">
#{ids}
</foreach>3、order by 之后
这种场景应当在Java层面做映射,设置一个字段/表名数组,仅允许用户传入索引值。这样保证传入的字段或者表名都在白名单里面。需要注意的是在mybatis-generator自动生成的SQL语句中,order by使用的也是$,而like和in没有问题。以上就是mybatis的sql注入审计的基本方法,我们没有分析的几个点也有问题,新手可以尝试分析一下不同的注入点来实操一遍,相信会有更多的收获。当我们再遇到类似问题时可以考虑:
1、Mybatis框架下审计SQL注入,重点关注在三个方面like,in和order by
2、xml方式编写sql时,可以先筛选xml文件搜索$,逐个分析,要特别注意mybatis-generator的order by注入
3、Mybatis注解编写sql时方法类似
4、java层面应该做好参数检查,假定用户输入均为恶意输入,防范潜在的攻击
Mybatis是如何将sql执行结果封装为目标对象并返回的?都有哪些映射形式?
- 第一种是使用
<resultMap>标签,逐一定义列名和对象属性名之间的映射关系。 - 第二种是使用sql列的别名功能,将列别名书写为对象属性名,比如
T_NAME AS NAME,对象属性名一般是name,小写,但是列名不区分大小写,Mybatis会忽略列名大小写,智能找到与之对应对象属性名,你甚至可以写成T_NAME AS NaMe,Mybatis一样可以正常工作。
有了列名与属性名的映射关系后,Mybatis通过反射创建对象,同时使用反射给对象的属性逐一赋值并返回,那些找不到映射关系的属性,是无法完成赋值的。
通常一个Xml映射文件,都会写一个Dao接口与之对应,请问,这个Dao接口的工作原理是什么?Dao接口里的方法,参数不同时,方法能重载吗?
Dao接口,就是人们常说的Mapper接口,接口的全限名,就是映射文件中的namespace的值,接口的方法名,就是映射文件中MappedStatement的id值,接口方法内的参数,就是传递给sql的参数。Mapper接口是没有实现类的,当调用接口方法时,接口全限名+方法名拼接字符串作为key值,可唯一定位一个MappedStatement,举例:com.mybatis3.mappers.StudentDao.findStudentById,可以唯一找到namespace为com.mybatis3.mappers.StudentDao下面id = findStudentById的MappedStatement。
在Mybatis中,每一个<select>、<insert>、<update>、<delete>标签,都会被解析为一个MappedStatement对象。Dao接口里的方法,是不能重载的,因为是全限名+方法名的保存和寻找策略。Dao接口的工作原理是JDK动态代理,Mybatis运行时会使用JDK动态代理为Dao接口生成代理proxy对象,代理对象proxy会拦截接口方法,转而执行MappedStatement所代表的sql,然后将sql执行结果返回。
Mybatis是如何进行分页的?分页插件的原理是什么?
Mybatis使用RowBounds对象进行分页,它是针对ResultSet结果集执行的内存分页,而非物理分页,可以在sql内直接书写带有物理分页的参数来完成物理分页功能,也可以使用分页插件来完成物理分页。分页插件的基本原理是使用Mybatis提供的插件接口,实现自定义插件,在插件的拦截方法内拦截待执行的sql,然后重写sql,根据dialect方言,添加对应的物理分页语句和物理分页参数。
举例:select * from student,拦截sql后重写为:select t.* from (select * from student)t limit 0,10Xml映射文件中,除了常见的select|insert|update|delete标签之外,还有哪些标签?
还有很多其他的标签,加上动态sql的9个标签,trim(where|set)、foreach 、if、choose、when、otherwise、bind(动态SQL的语句)等,其中为sql片段标签,通过标签引入sql片段,为不支持自增的主键生成策略标签。
传统的JDBC的方法,在组合SQL语句的时候需要去拼接,稍微不注意就会少少了一个空格,标点符号,都会导致系统错误。Mybatis的动态SQL就是为了解决这种问题而产生的;Mybatis的动态SQL语句值基于OGNL表达式的,方便在SQL语句中实现某些逻辑;可以使用标签组合成灵活的sql语句,提供开发的效率。
Mybatis的动态SQL标签主要由以下几类: If语句(简单的条件判断) Choose(when/otherwise),相当于java语言中的switch,与jstl中choose类似 Trim(对包含的内容加上prefix,或者suffix) Where(主要是用来简化SQL语句中where条件判断,能智能的处理and/or 不用担心多余的语法导致的错误) Set(主要用于更新时候) Foreach(一般使用在mybatis in语句查询时特别有用)
<resultMap>、<parameterMap>、<sql>、<include>、<selectKey> ,加上动态sql的9个标签,其中 <sql> 为sql片段标签,通过 <include> 标签引入sql片段, <selectKey> 为不支持自增的主键生成策略标签
Mybatis映射文件中,如果A标签通过include引用了B标签的内容,请问,B标签能否定义在A标签的后面,还是说必须定义在A标签的前面?
虽然Mybatis解析Xml映射文件是按照顺序解析的,但是,被引用的B标签依然可以定义在任何地方,Mybatis都可以正确识别。原理是,Mybatis解析A标签,发现A标签引用了B标签,但是B标签尚未解析到,尚不存在,此时,Mybatis会将A标签标记为未解析状态,然后继续解析余下的标签,包含B标签,待所有标签解析完毕,Mybatis会重新解析那些被标记为未解析的标签,此时再解析A标签时,B标签已经存在,A标签也就可以正常解析完成了。
简述Mybatis的Xml映射文件和Mybatis内部数据结构之间的映射关系?
Mybatis将所有Xml配置信息都封装到All-In-One重量级对象Configuration内部。在Xml映射文件中,<parameterMap>标签会被解析为ParameterMap对象,其每个子元素会被解析为ParameterMapping对象。<resultMap>标签会被解析为ResultMap对象,其每个子元素会被解析为ResultMapping对象。每一个<select>、<insert>、<update>、<delete>标签均会被解析为MappedStatement对象,标签内的sql会被解析为BoundSql对象。
当实体类中的属性名和表中的字段名不一样,怎么办?
- 第1种: 通过在查询的sql语句中定义字段名的别名,让字段名的别名和实体类的属性名一致。
- 第2种: 通过 `` 来映射字段名和实体类属性名的一一对应的关系。
模糊查询like语句该怎么写?
- 第1种:在Java代码中添加sql通配符。
- 第2种:在sql语句中拼接通配符,会引起sql注入(就是使用了$这个符号)
Mybatis的Xml映射文件中,不同的Xml映射文件,id是否可以重复?
不同的Xml映射文件,如果配置了namespace,那么id可以重复;如果没有配置namespace,那么id不能重复; 原因就是namespace+id是作为Map <String,MapperStatement> 的key使用的,如果没有namespace,就剩下id,那么,id重复会导致数据互相覆盖。有了namespace,自然id就可以重复,namespace不同,namespace+id自然也就不同。
使用MyBatis的mapper接口调用时有哪些要求?
- Mapper接口方法名和mapper.xml中定义的每个sql的id相同;
- Mapper接口方法的输入参数类型和mapper.xml中定义的每个sql 的parameterType的类型相同;
- Mapper接口方法的输出参数类型和mapper.xml中定义的每个sql的resultType的类型相同;
- Mapper.xml文件中的namespace即是mapper接口的类路径。
package cn.itcast.mp.simple.mapper;
import cn.itcast.mp.simple.pojo.User;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import java.util.List;
public interface UserMapper extends BaseMapper<User> {
List<User> findAll();
}
----------------------------------------------------------------------------------------
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!-- 这里的namespace 就是的mapper接口的路径-->
<mapper namespace="cn.itcast.mp.simple.mapper.UserMapper">
<!--
id 这里就是的 UserMapper 中的方法
这里的resultType就是的mapper接口方法的返回的结果相同
-->
<select id="findAll" resultType="cn.itcast.mp.simple.pojo.User">
select * from tb_user
</select>
</mapper>Mybatis 缓存
Mybatis中有一级缓存和二级缓存,默认情况下一级缓存是开启的,而且是不能关闭的。
一级缓存是指 SqlSession 级别的缓存,当在同一个 SqlSession 中进行相同的 SQL 语句查询时,第二次以后的查询不会从数据库查询,而是直接从缓存中获取,一级缓存最多缓存 1024 条 SQL。
二级缓存是指可以跨 SqlSession 的缓存。是 mapper 级别的缓存,对于mapper 级别的缓存不同的sqlsession 是可以共享的。
Mybatis首先去缓存中查询结果集,如果没有则查询数据库,如果有则从缓存取出返回结果集就不走数据库。Mybatis内部存储缓存使用一个HashMap,key为hashCode+sqlId+Sql语句。value为从查询出来映射生成的java对象
Mybatis的二级缓存即查询缓存,它的作用域是一个mapper的namespace,即在同一个namespace中查询sql可以从缓存中获取数据。二级缓存是可以跨SqlSession的。
Mybatis是否支持延迟加载?如果支持,它的实现原理是什么?
Mybatis仅支持association关联对象和collection关联集合对象的延迟加载,association指的就是一对一,collection指的就是一对多查询。在Mybatis配置文件中,可以配置是否启用延迟加载lazyLoadingEnabled=true|false。
它的原理是,使用CGLIB创建目标对象的代理对象,当调用目标方法时,进入拦截器方法,比如调用a.getB().getName(),拦截器invoke()方法发现a.getB()是null值,那么就会单独发送事先保存好的查询关联B对象的sql,把B查询上来,然后调用a.setB(b),于是a的对象b属性就有值了,接着完成a.getB().getName()方法的调用。这就是延迟加载的基本原理。
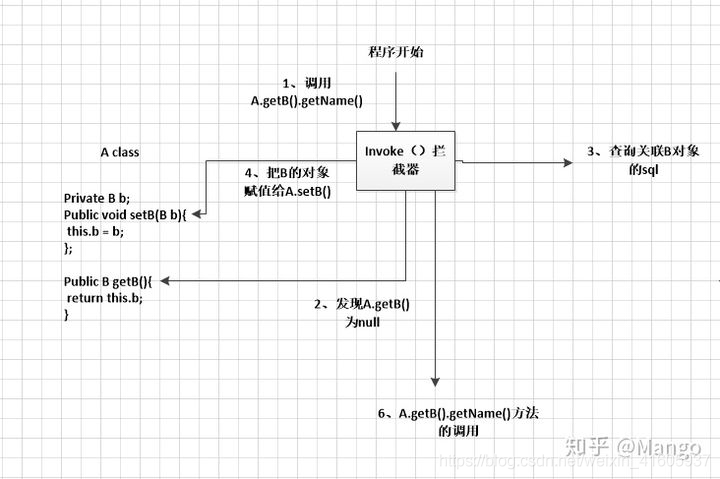
Mybatis仅支持association关联对象和collection关联集合对象的延迟加载,association指的就是一对一,collection指的就是一对多查询。在Mybatis配置文件中,可以配置是否启用延迟加载lazyLoadingEnabled=true|false。使用CGLIB创建目标对象的代理对象,当调用目标方法时,进入拦截器方法,比如调用A.getB().getName(),拦截器invoke()方法发现A.getB()是null值,那么就会单独发送事先保存好的查询关联B对象的sql,把B查询上来,然后调用A.setB(b),于是a的对象b属性就有值了,接着完成A.getB().getName()方法的调用。这就是延迟加载的基本原理。
好处:延迟加载就是在需要用到数据时才进行加载,不需要用到数据时就不加载数据。延迟加载也称懒加载. 好处: 先从单表查询,需要时再从关联表去关联查询,大大提高数据库性能,因为查询单表要比关联查询多张表速度要快。
坏处: 因为只有当需要用到数据时,才会进行数据库查询,这样在大批量数据查询时,因为查询工作也要消耗 时间,所以可能造成用户等待时间变长,造成用户体验下降。
MyBatis实现一对一有几种方式?具体怎么操作的?实现一对多有几种方式,怎么操作的?
有联合查询和嵌套查询
- 联合查询是几个表联合查询,只查询一次, 通过在resultMap里面配置association节点配置一对一的类就可以完成;
- 嵌套查询是先查一个表,根据这个表里面的结果的 外键id,去再另外一个表里面查询数据,也是通过association配置,但另外一个表的查询通过select属性配置。
- 联合查询是几个表联合查询,只查询一次,通过在resultMap里面的collection节点配置一对多的类就可以完成;
- 嵌套查询是先查一个表,根据这个表里面的 结果的外键id,去再另外一个表里面查询数据,也是通过配置collection,但另外一个表的查询通过select节点配置。
什么是MyBatis的接口绑定?有哪些实现方式?
接口绑定,就是在MyBatis中任意定义接口,然后把接口里面的方法和SQL语句绑定, 我们直接调用接口方法就可以,这样比起原来了SqlSession提供的方法我们可以有更加灵活的选择和设置。 接口绑定有两种实现方式:当Sql语句比较简单时候,用注解绑定, 当SQL语句比较复杂时候,用xml绑定,一般用xml绑定的比较多。
- 注解绑定,就是在接口的方法上面加上 @Select、@Update等注解,里面包含Sql语句来绑定;
- 外一种就是通过xml里面写SQL来绑定, 在这种情况下,要指定xml映射文件里面的namespace必须为接口的全路径名。
MyBatis 常用注解
这几年来注解开发越来越流行,MyBatis 也可以使用注解开发方式,这样我们就可以减少编写 Mapper 映射文件了。我们先围绕一些基本的 CRUD 来学习,再学习复杂映射多表操作。
@Insert:实现新增,代替了 <insert></insert>
@Delete:实现删除,代替了 <delete></delete>
@Update:实现更新,代替了 <update></update>
@Select:实现查询,代替了 <select></select>
@Result:实现结果集封装,代替了 <result></result>
@Results:可以与@Result 一起使用,封装多个结果集,代替了 <resultMap></resultMap>
@One:实现一对一结果集封装,代替了 <association></association>
@Many:实现一对多结果集封装,代替了 <collection></collection>Mybatis中如何执行批处理?
答:使用BatchExecutor完成批处理。
Mybatis都有哪些Executor执行器?它们之间的区别是什么?
答:Mybatis有三种基本的Executor执行器,SimpleExecutor、ReuseExecutor、BatchExecutor。
SimpleExecutor:每执行一次update或select,就开启一个Statement对象,用完立刻关闭Statement对象。
ReuseExecutor:执行update或select,以sql作为key查找Statement对象,存在就使用,不存在就创建,用完后,不关闭Statement对象,而是放置于Map<String, Statement>内,供下一次使用。简言之,就是重复使用Statement对象。
BatchExecutor:执行update(没有select,JDBC批处理不支持select),将所有sql都添加到批处理中(addBatch()),等待统一执行(executeBatch()),它缓存了多个Statement对象,每个Statement对象都是addBatch()完毕后,等待逐一执行executeBatch()批处理。与JDBC批处理相同。
RowBounds 是一次性查询全部结果吗?为什么?
RowBounds 表面是在“所有”数据中检索数据,其实并非是一次性查询出所有数据,因为 MyBatis 是对 jdbc 的封装,在 jdbc 驱动中有一个 Fetch Size 的配置,它规定了每次最多从数据库查询多少条数据,假如你要查询更多数据,它会在你执行 next()的时候,去查询更多的数据。就好比你去自动取款机取 10000 元,但取款机每次最多能取 2500 元,所以你要取 4 次才能把钱取完。只是对于 jdbc 来说,当你调用 next()的时候会自动帮你完成查询工作。这样做的好处可以有效的防止内存溢出。
Mybatis 逻辑分页和物理分页的区别是什么?
- 逻辑分页是一次性查询很多数据,然后再在结果中检索分页的数据。这样做弊端是需要消耗大量的内存、有内存溢出的风险、对数据库压力较大。
- 物理分页是从数据库查询指定条数的数据,弥补了一次性全部查出的所有数据的种种缺点,比如需要大量的内存,对数据库查询压力较大等问题。
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |