Pandas读取excel合并单元格的正确姿势(openpyxl合并单元格拆分并填充内容)
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
问题介绍(ffill填充存在的问题
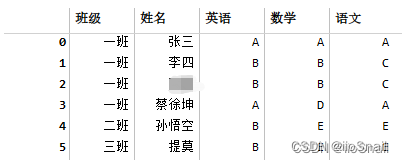
在pandas读取excel经常会遇到合并单元格的问题。例如
此时使用pandas读取到的内容为

如果去百度几乎所有人会说应该用如下代码
df['班级'] = df['班级'].ffill()

这样看起来没问题但是该解决方案并不能适用于所有场景甚至会造成数据错误。
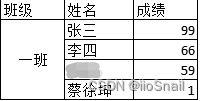
例如
 对班级和备注填充后
对班级和备注填充后 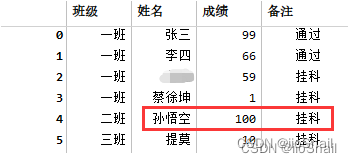
孙武空本来是数据缺失现在被错误的标记成了挂科数据。
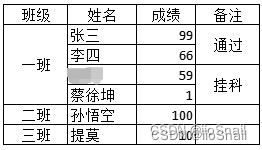
再例如
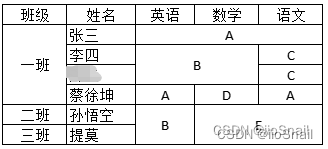 对所有列填充后
对所有列填充后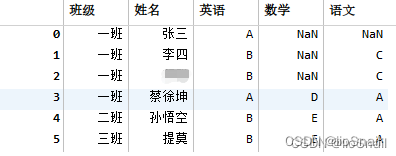
同样存在大量数据或错误数据。
正确填充方式
思路① 使用openpyxl将合并单元格拆分生成中间文件 ② 读取中间文件
第一步使用如下工具类生成拆分单元格并生成中间文件
import openpyxl
# 拆分所有的合并单元格并赋予合并之前的值。
# 由于openpyxl并没有提供拆分并填充的方法所以使用该方法进行完成
def unmerge_and_fill_cells(worksheet):
all_merged_cell_ranges = list(
worksheet.merged_cells.ranges
)
for merged_cell_range in all_merged_cell_ranges:
merged_cell = merged_cell_range.start_cell
worksheet.unmerge_cells(range_string=merged_cell_range.coord)
for row_index, col_index in merged_cell_range.cells:
cell = worksheet.cell(row=row_index, column=col_index)
cell.value = merged_cell.value
# 读取原始xlsx文件拆分并填充单元格然后生成中间临时文件。
def unmerge_cell(filename):
wb = openpyxl.load_workbook(filename)
for sheet_name in wb.sheetnames:
sheet = wb[sheet_name]
unmerge_and_fill_cells(sheet)
filename = filename.replace(".xls", "_temp.xls")
wb.save(filename)
wb.close()
# openpyxl保存之后再用pandas读取会存在公式无法读取到的情况使用下面方式就可以了
# 如果你的excel不涉及公式可以删除下面内容
# 原理为使用windows打开excel然后另存为一下
from win32com.client import Dispatch
xlApp = Dispatch("Excel.Application")
xlApp.Visible = False
xlBook = xlApp.Workbooks.Open(str(Path(".").absolute() / filename)) # 这里必须填绝对路径
xlBook.Save()
xlBook.Close()
return filename
if __name__ == '__main__':
unmerge_cell("test.xlsx")
拆分后的sheet页如图
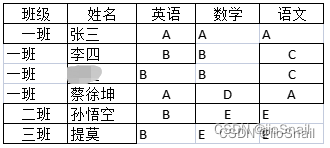
然后再使用pandas读取中间文件即可
import pandas as pd
df = pd.read_excel("test_temp.xlsx")
结果为