

【Selenium】Selenium获取Network数据(高级版)
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
前言
为解决从Selenium中获取Network接口数据潜心研究了一小会儿遂有此文
基本看这篇文章的多多少少都跟spider 沾亲带故。所以直接进入正题。
只想要代码文章前边自取
想看长篇大论先看这篇 【Selenium】控制当前已经打开的 chrome浏览器窗口高级版
应用场景
Chrome浏览器 -> 开发者工具 -> Network 中所有的数据包我要全部拿下来。
举个例子🌰
网站通过XHR异步加载数据然后再渲染到网页上。而通过Selenium去获取渲染后的数据是同HTML打交道的
异步加载返回数据是json文件的有时渲染在网页上不一定是完整的json文件中的数据最重要的是json文件解析起来很方便
通过selenium去拿网页数据往往是两个途径
selenium.page_source通过解析HTML
通过中间人进行数据截获数据源是啥就是啥
这两种方法各有利弊但是这篇文章就可以将他们相结合起来了实在是妙啊
可能你会有疑惑👀直接使用requests去请求不就完事了
请你想一下我这都使用上selenium了你觉得我还会去使用requests再多请求一遍吗
完整代码
Selenium获取Network
这里指定9527端口打开浏览器也可以不指定看上一篇文章
代码讲解在下面
# -*- coding: utf-8 -*-# @Time : 2022-08-27 11:59# @Name : selenium_cdp.pyimport jsonfrom selenium import webdriverfrom selenium.common.exceptions import WebDriverExceptionfrom selenium.webdriver.chrome.options import Options
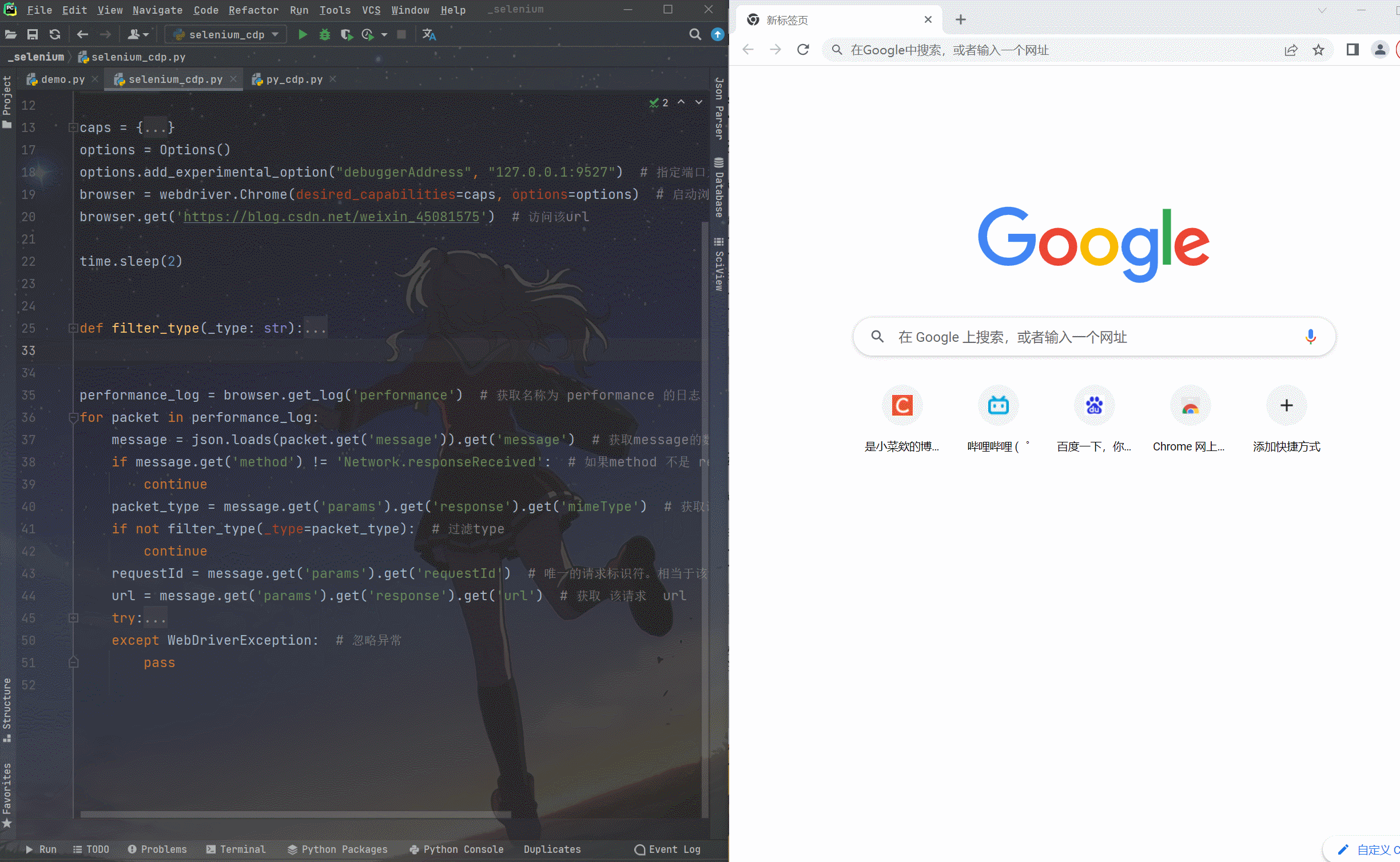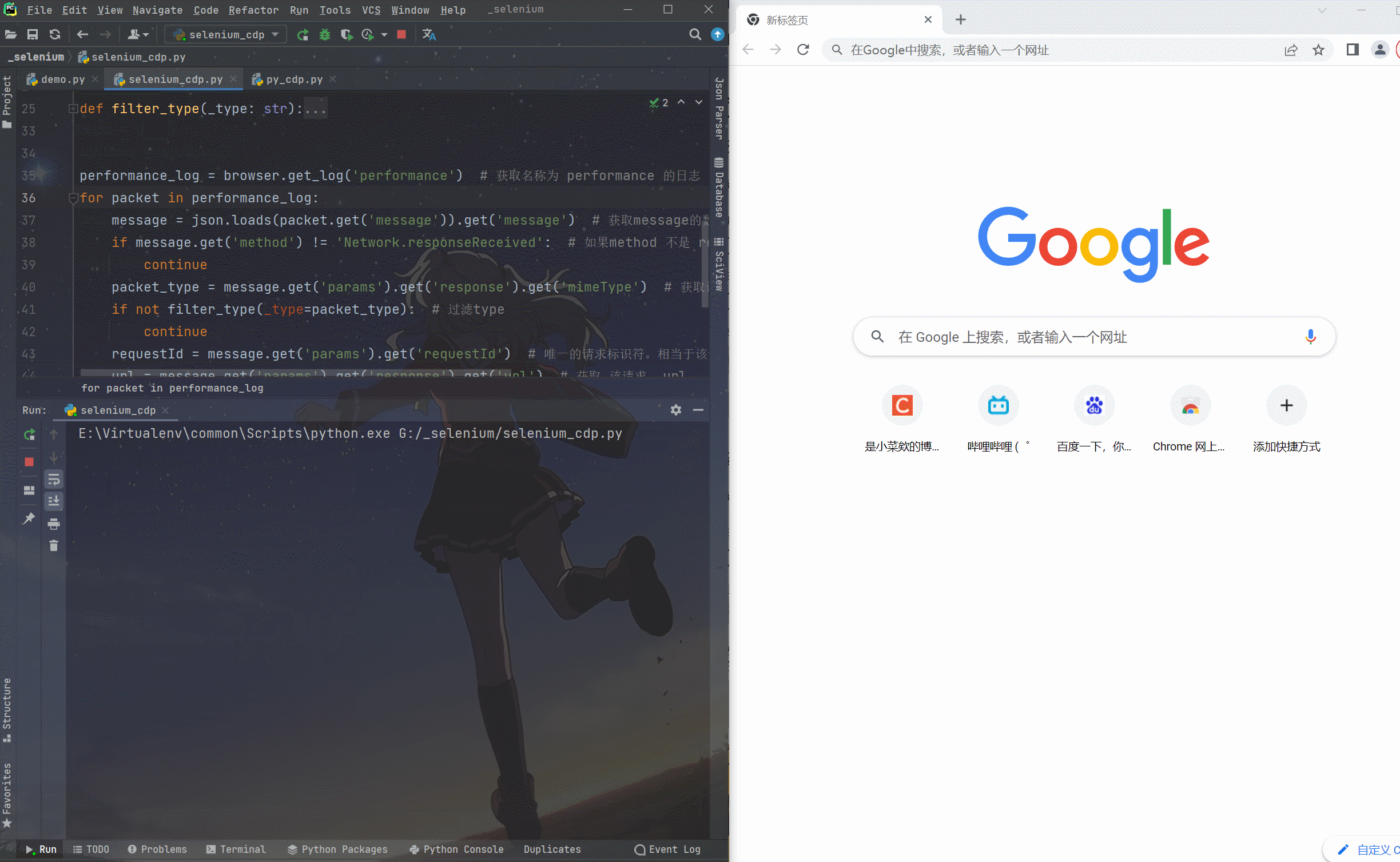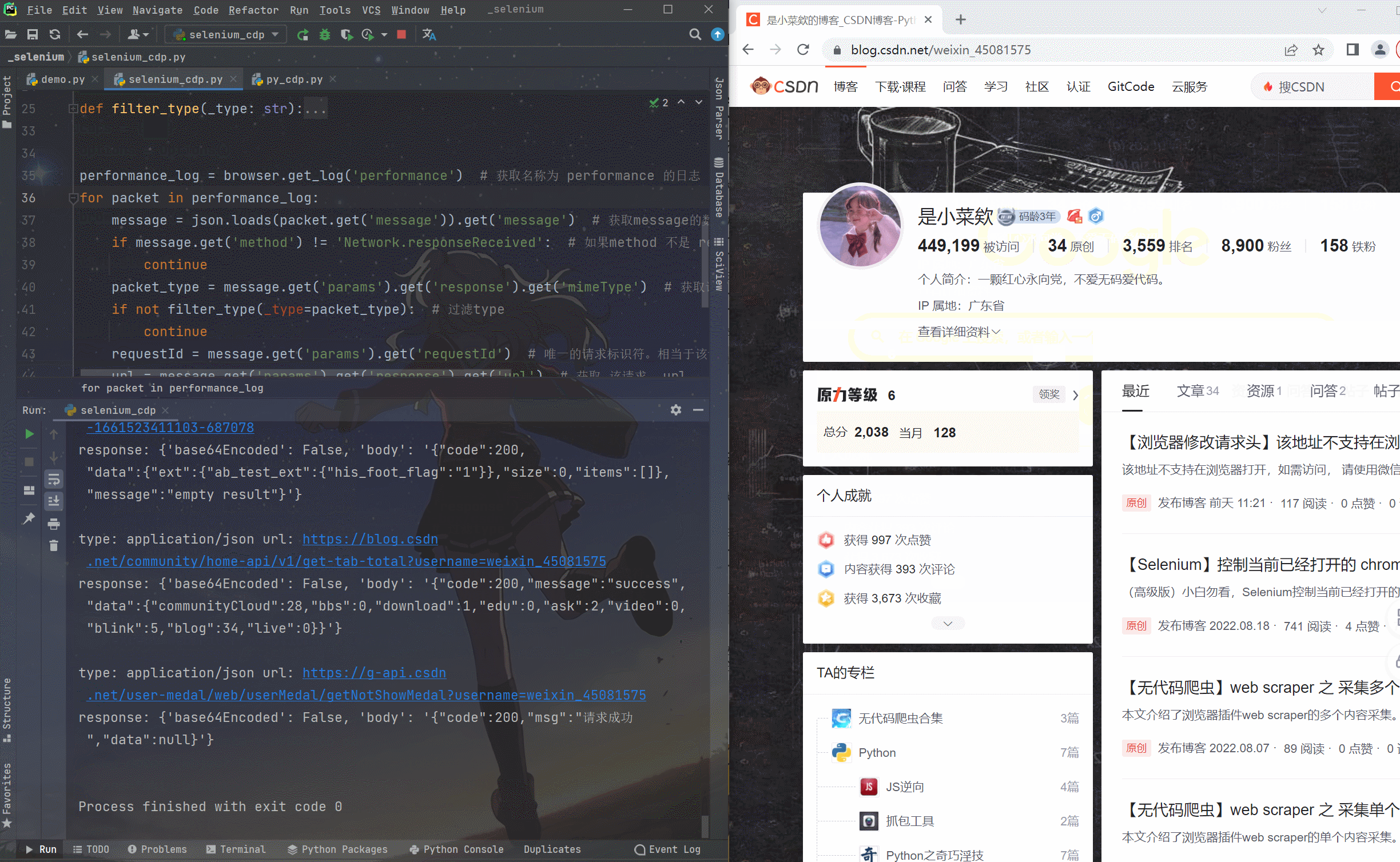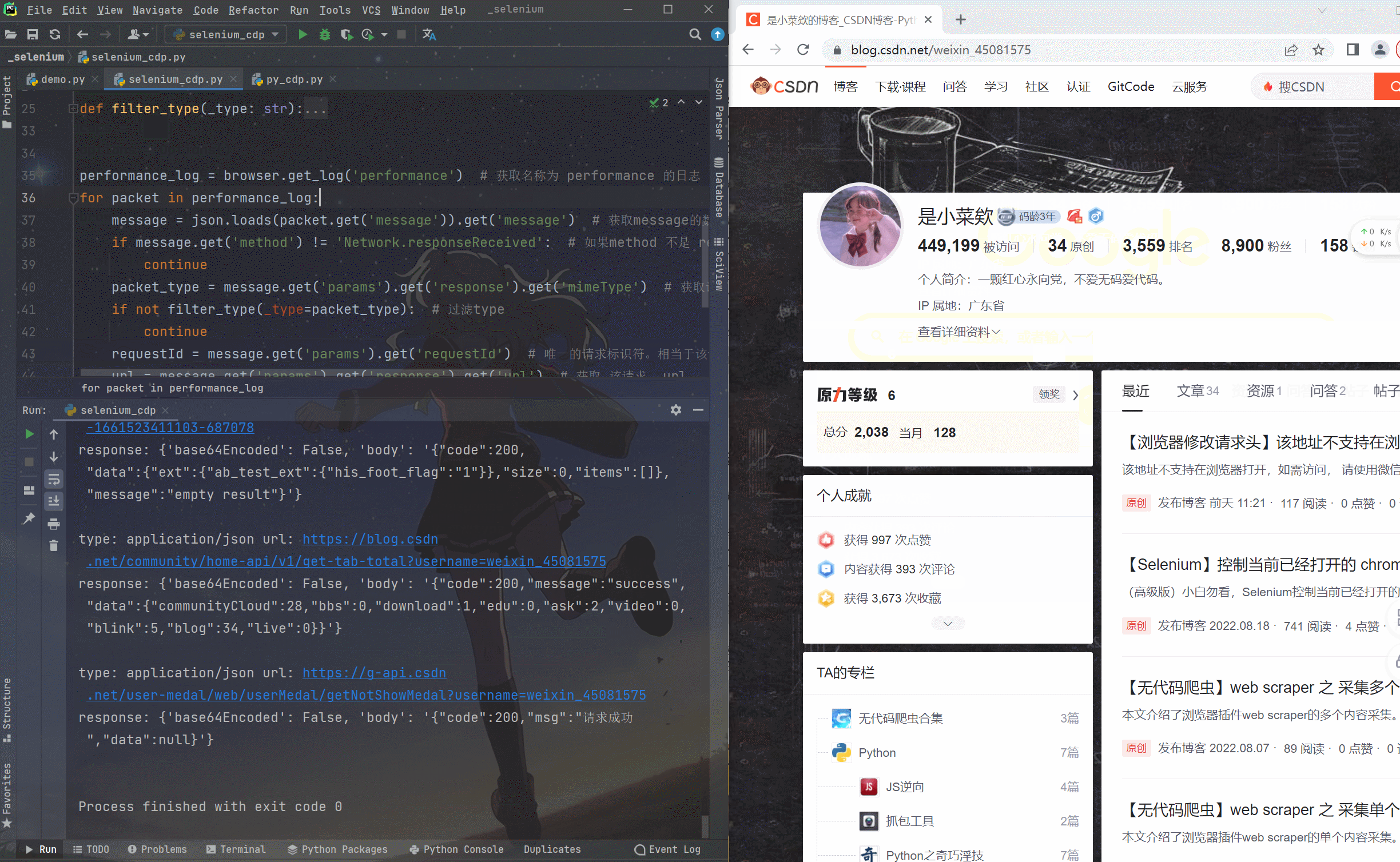
caps = {"browserName": "chrome",'goog:loggingPrefs': {'performance': 'ALL'} # 开启日志性能监听}options = Options()options.add_experimental_option("debuggerAddress", "127.0.0.1:9527") # 指定端口为9527browser = webdriver.Chrome(desired_capabilities=caps, options=options) # 启动浏览器browser.get('https://blog.csdn.net/weixin_45081575') # 访问该urldef filter_type(_type: str):types = ['application/javascript', 'application/x-javascript', 'text/css', 'webp', 'image/png', 'image/gif','image/jpeg', 'image/x-icon', 'application/octet-stream']if _type not in types:return Truereturn Falseperformance_log = browser.get_log('performance') # 获取名称为 performance 的日志for packet in performance_log:message = json.loads(packet.get('message')).get('message') # 获取message的数据if message.get('method') != 'Network.responseReceived': # 如果method 不是 responseReceived 类型就不往下执行continuepacket_type = message.get('params').get('response').get('mimeType') # 获取该请求返回的typeif not filter_type(_type=packet_type): # 过滤typecontinuerequestId = message.get('params').get('requestId') # 唯一的请求标识符。相当于该请求的身份证url = message.get('params').get('response').get('url') # 获取 该请求 urltry:resp = browser.execute_cdp_cmd('Network.getResponseBody', {'requestId': requestId}) # selenium调用 cdpprint(f'type: {packet_type} url: {url}')print(f'response: {resp}')print()except WebDriverException: # 忽略异常pass运行效果看下面动图轻松拿到该网页请求中的所有数据包~
知识点📖
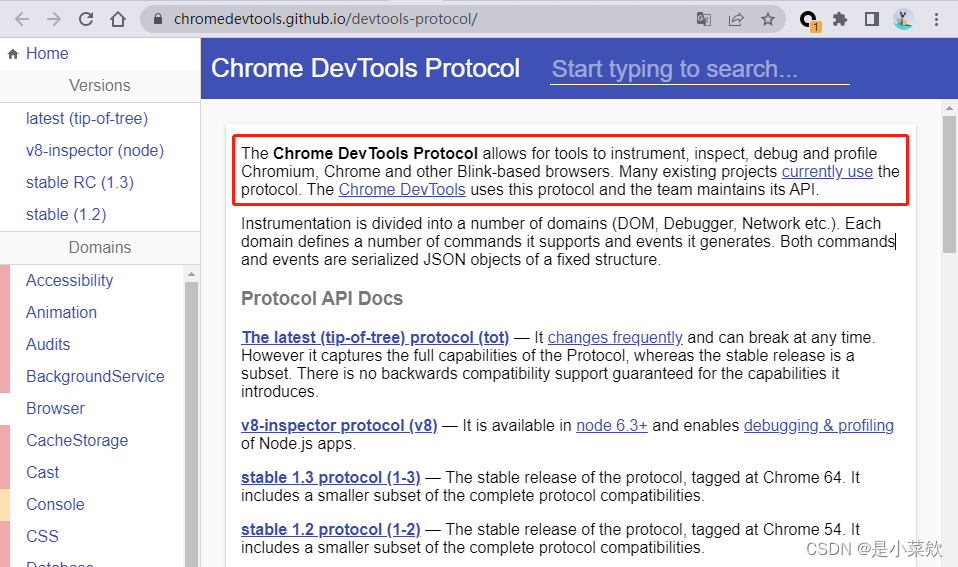
Chrome DevTools Protocol允许使用工具来检测、检查、调试和分析 Chromium、Chrome 和其他基于 Blink 的浏览器。
Chrome DevTools Protocol简称CDP
看以下 Chrome DevTools Protocol官方文档 感兴趣的可以深入去学习了解。这个将另起一篇文章来讲。
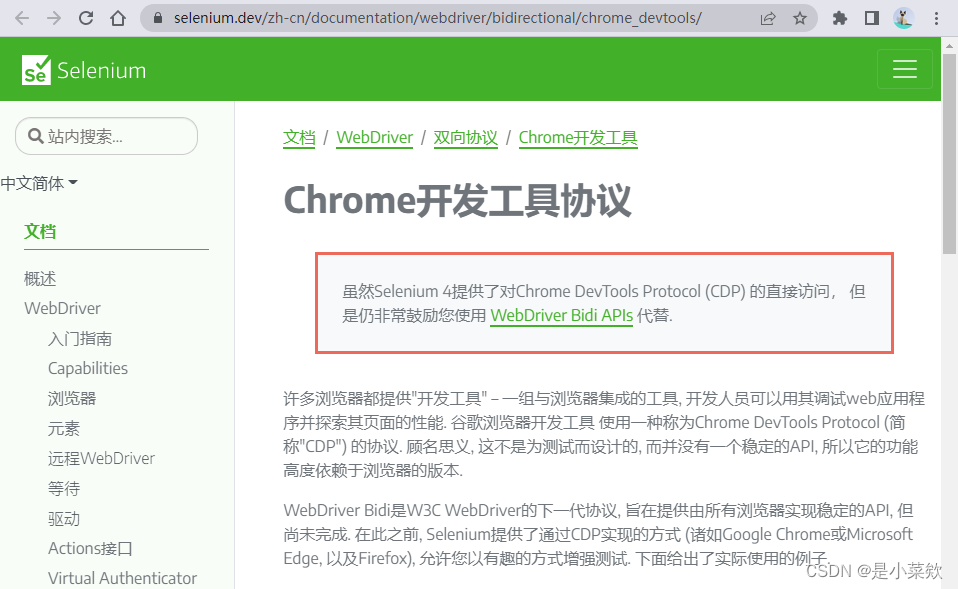
再看 Selenium官方文档所以是可以通过CDP协议去操作Selenium打开的Chrome浏览器的。
代码解析
在上一篇文章 【Selenium】控制当前已经打开的 chrome浏览器窗口高级版 中介绍了链接Chrome浏览器这里进一步介绍。
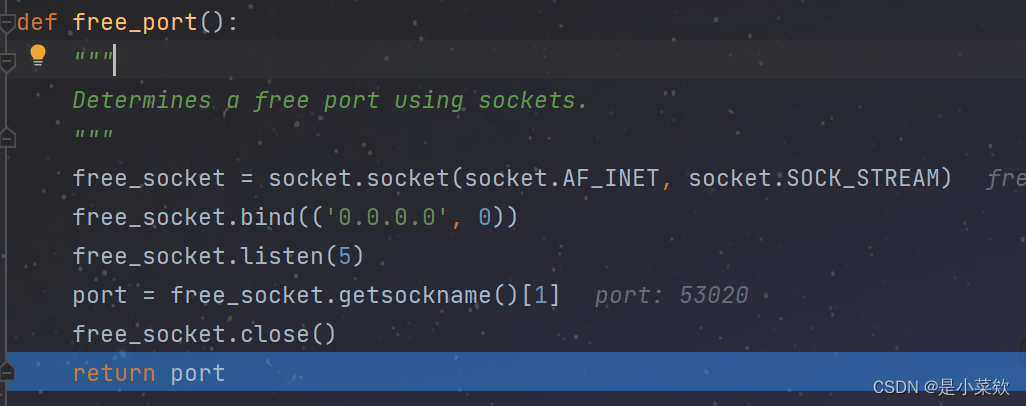
以调试模式启动Selenium打上断点跟一下源码。来到下面这里因为咱们指定了端口为9527否则这个port将是随机的至于为什么看源码
site-packages\selenium\webdriver\common\utils.py
回到上面的代码中
'goog:loggingPrefs': {'performance': 'ALL'}这段代码是开启浏览器的性能日志记录
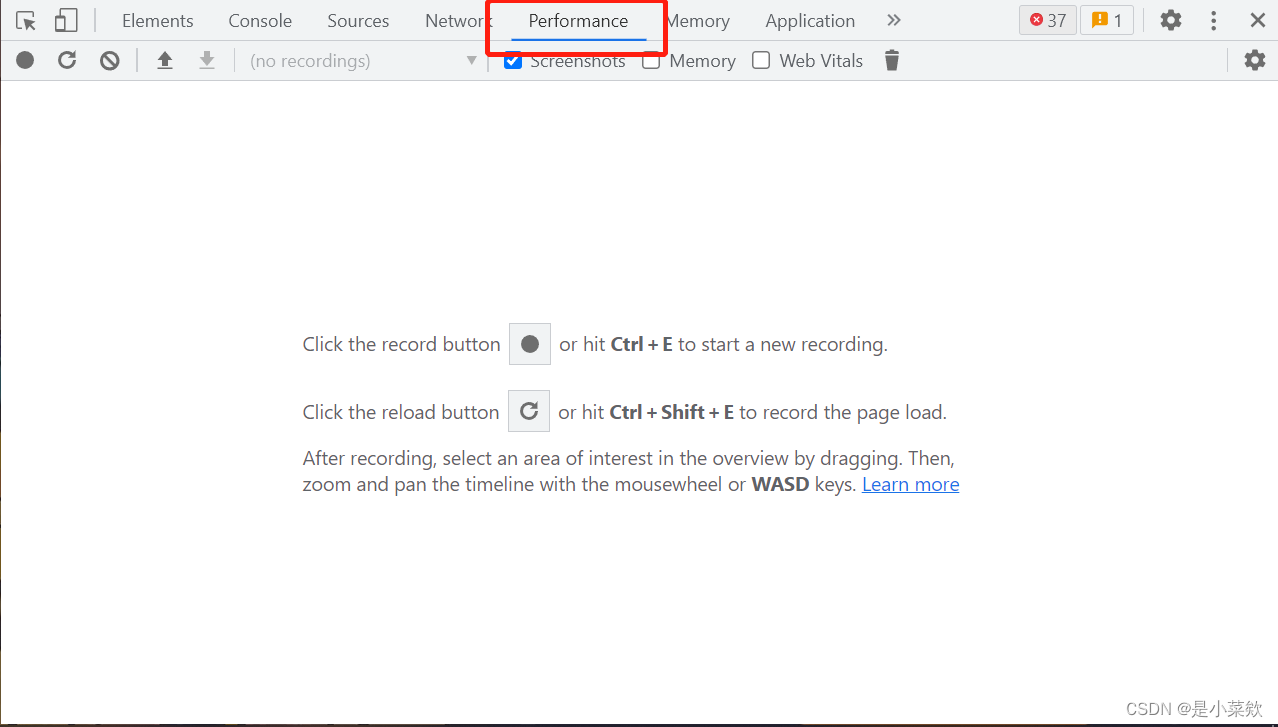
caps = {"browserName": "chrome",'goog:loggingPrefs': {'performance': 'ALL'} # 开启性能日志记录}简单理解为 开发者工具中的 performance看下图
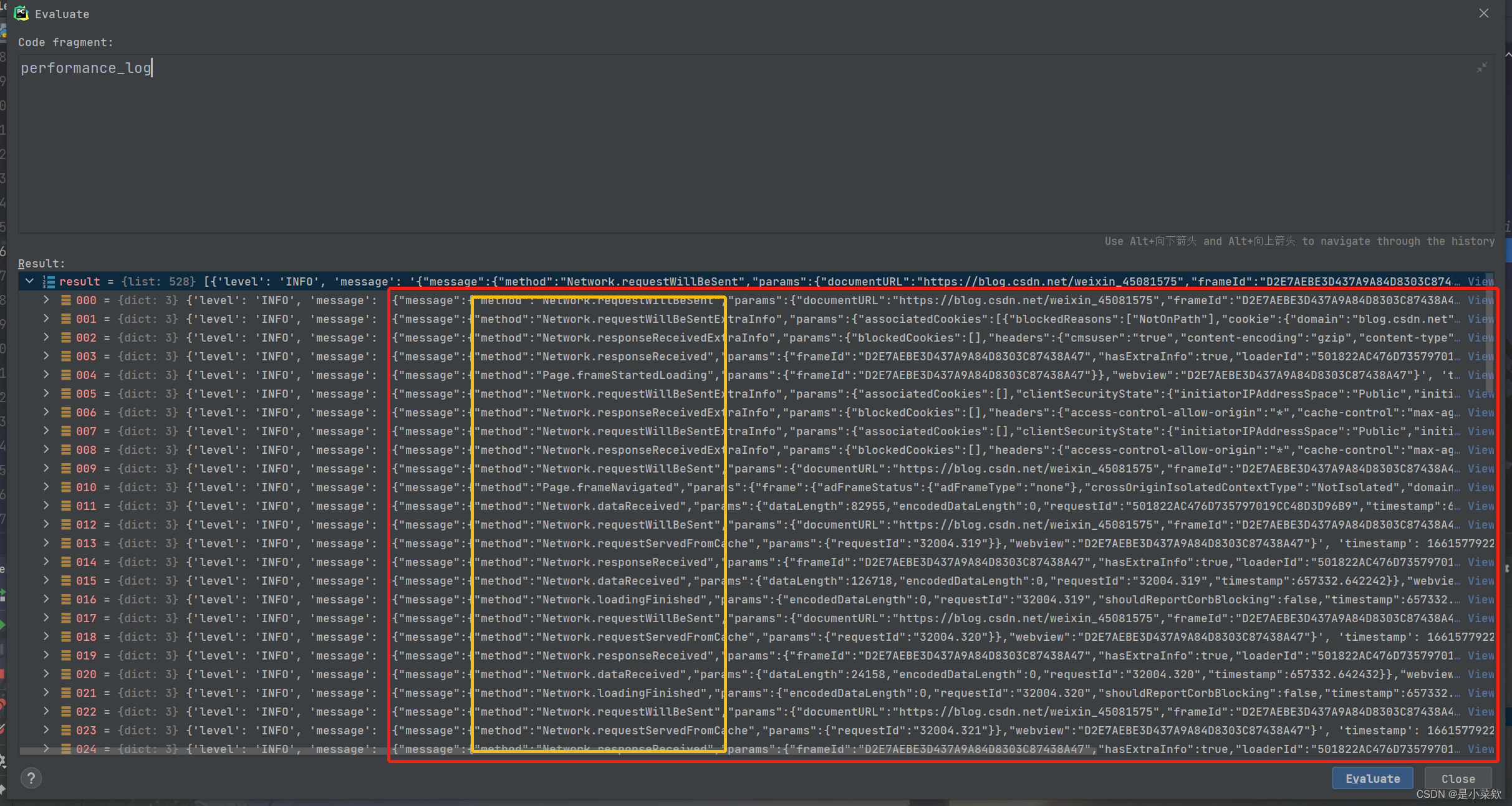
以下代码返回的是一个列表装着该网页请求中所有的数据包
performance_log = browser.get_log('performance')看下图
因为我们要获取的是 Network中的返回值所以只取
method =Network.responseReceived
知识补充
使用 browser.log_types 可以查看当前的可用日志类型的列表
下面两幅图分别是开启性能日志记录 和 不开启性能日志记录 的可用日志类型返回值~
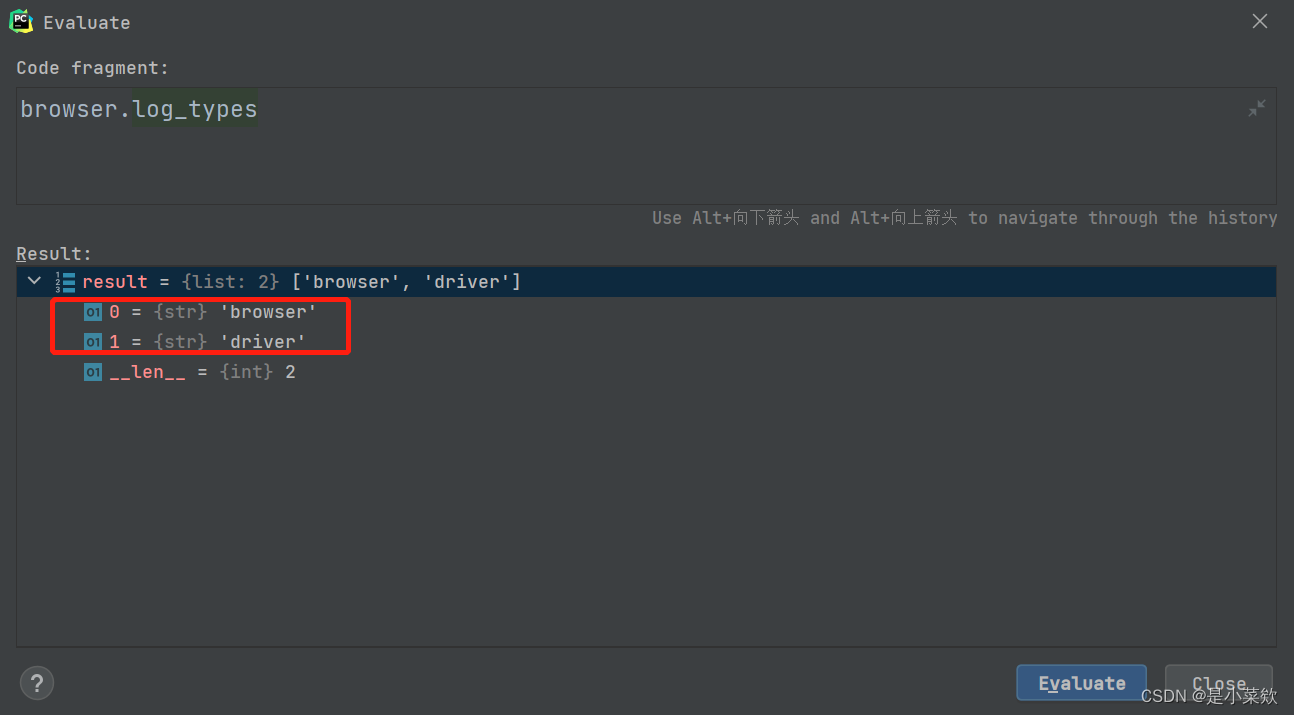
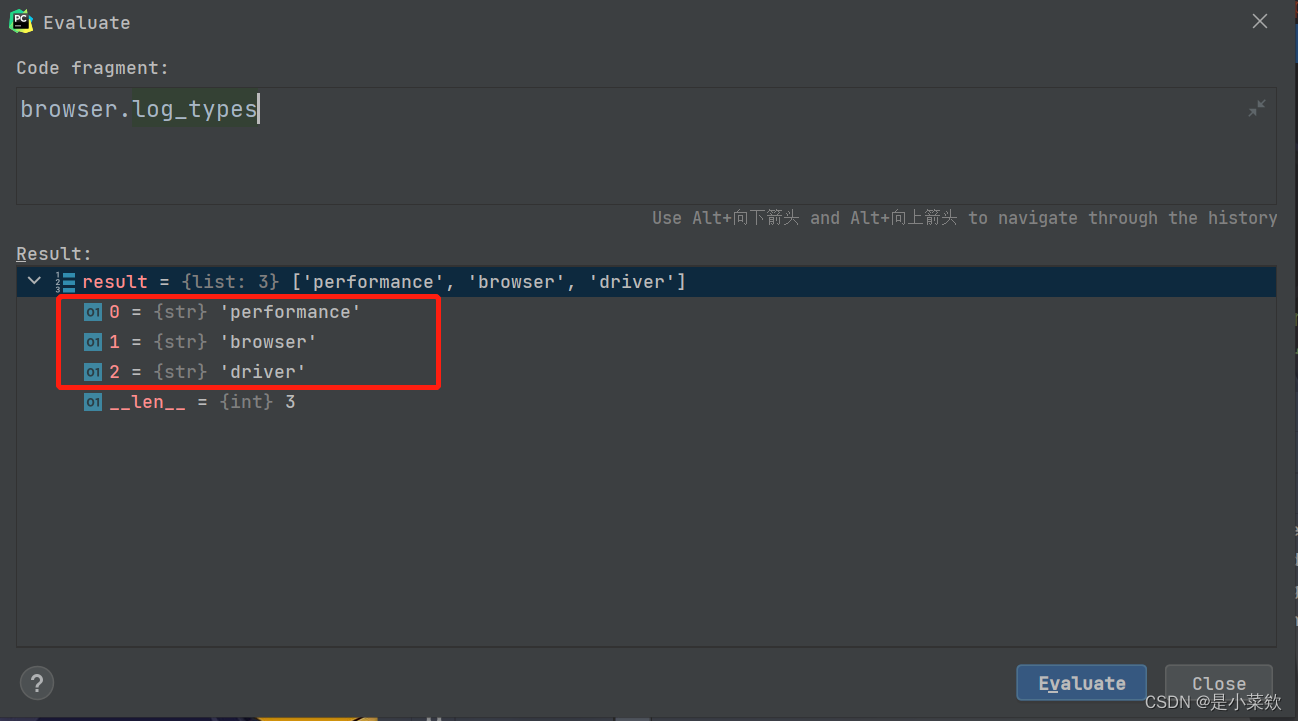
再接下来就是过滤请求包一般来说像图片、css&js文件等往往是不需要的所以可以对它们过滤~这一步可以根据自己的需求来过滤
def filter_type(_type: str):types = ['application/javascript', 'application/x-javascript', 'text/css', 'webp', 'image/png', 'image/gif','image/jpeg', 'image/x-icon', 'application/octet-stream']if _type not in types:return Truereturn False
最后是获取数据包的 requestId这个是调用 cdp 的关键它就好比每个网络数据包的身份证。
在Selenium中调用cdp时候需要传入 requestId浏览器会验证是否存在该 requestId
如果存在则响应并返回数据
如果不存在则会抛出
WebDriverException异常。
在这里的代码中我对这个异常进行了忽略的处理~
try:resp = browser.execute_cdp_cmd('Network.getResponseBody', {'requestId': '123123123'}) # selenium调用 cdpprint(f'type: {packet_type} url: {url}')print(f'response: {resp}')print()except WebDriverException: # 忽略异常pass后话
简单来说本文章所能实现的还算是有用的😎😎
远的不说起码本文章就帮助我解决了mitmproxy + Selenium 的组合拳现在只用Selenium就可以完成了~
See you.
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |