

Python机器学习:认识机器学习
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
🌕 机器学习是什么
⭐️机器学习是一门涉及数学、统计学、计算机科学等的学科。
⭐️机器学习是从一个大量的已知数据中学习如何对未知的新数据进行预测并且可以随着学习内容的增加提高对未来数据预测的准确性的一个过程。着重强调过程就相当于是从已知去预测未知
⭐️例如在购物时机器学习算法自动根据浏览历史推荐用户感兴趣的商品。这点我相信大家在逛淘宝等等的时候都有所体会吧
机器学习算法可以分为三大类无监督学习、有监督学习和半监督学习。
那么接下来就简单介绍以下这三类是个什么意思。
无监督学习不需要提前知道数据集的类别标签可分为聚类和降维两个领域。
有监督学习使用有标签的训练数据建立模型用来预测新的未知标签的数据可分为分类和回归两个领域。
半监督学习无监督学习和有监督学习的结合。
在这里我是用python来学习机器学习算法的如果没有python基础的朋友可以去看看我之前的python学习笔记里面讲解了一些python的基础知识。
🌕 三个机器学习中常用的第三方库
在开始之前我们还要先了解熟悉一下三个机器学习中常用到的第三方库分别是Numpy、Pandas、Matplotlib。
🌗 Numpy库
Numpy库在矩阵运算等方面提供了很多高效的函数。
🌑 数组生成
- 用array()函数生成一个数组
import numpy as np
a = np.array([1,2,3,4]) # 用array()函数生成一个数组
print(a)
# [1 2 3 4]
b = np.array([[1,2,3],[4,5,6]])
print(b)
# [[1 2 3]
# [4 5 6]]
print(a.shape) # 用shape查看数组的形状例如3×5的数组形状就是(3,5)
# (4,) # 这里因为a是一维数组没有行和列的概念
print(b.shape)
# (2, 3)
print(a.ndim) # 用ndim查看数组的维度
# 1 # 表示一维
print(b.ndim)
# 2 # 表示二维
- 生成特定形状的矩阵
import numpy as np
print(np.zeros((2,4))) # 生成指定形状的全为0的数组
# [[0. 0. 0. 0.]
# [0. 0. 0. 0.]]
print(np.ones((2,4))) # 生成指定形状的全为1的数组
# [[1. 1. 1. 1.]
# [1. 1. 1. 1.]]
print(np.eye(3,3)) # 生成指定形状的单位矩阵对角线的元素为1
# [[1. 0. 0.]
# [0. 1. 0.]
# [0. 0. 1.]]
🌑 数组中的索引
数组中的元素可以利用切片索引来获取其中索引可以是获取一个元素也可以是获取多个元素的切片索引以及根据布尔值获取元素的布尔索引。
import numpy as np
a = np.arange(12).reshape(3,4) # arange(12)返回一个0~11的序列reshape(3,4)将这个序列组装成一个3行4列的数组
print(a)
# [[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]]
print(a[1,1]) # 获取数组中的某个元素
# 5
a[1,1] = 100 # 对数组中的某个元素重新赋值
print(a)
# [[ 0 1 2 3]
# [ 4 100 6 7]
# [ 8 9 10 11]]
print(a[:,:]) # 切片操作这里切片仍然是获取整个数组
# [[ 0 1 2 3]
# [ 4 100 6 7]
# [ 8 9 10 11]]
print(a[:,0]) # 获取数组中的第一列元素
# [0 4 8]
print(a[0,:]) # 获取数组中的第一行元素
# [0 1 2 3]
print(a[0:2,1:3]) # 获取数组中第一、第二行第二、第三列的元素
# [[ 1 2]
# [100 6]]
index = a % 2 == 1 # 用布尔值进行索引
print(index)
# [[False True False True]
# [False False False True]
# [False True False True]]
print(a[index])
# [ 1 3 7 9 11]
print(a[a % 2 == 1]) # 这行代码等于上面两行代码
# [ 1 3 7 9 11]
np.where可以找到符合条件的元素的位置或按条件作变化后的数组它有两种形式
# 1. np.where(condition) # 返回满足condition条件的元素的坐标将这些元素的行坐标放在一起列坐标放在一起然后按下标一一对应就类似于字典的键值对
print(np.where(a % 2 == 1))
# (array([0, 0, 1, 2, 2], dtype=int64), array([1, 3, 3, 1, 3], dtype=int64))
# 比如满足a % 2 == 1 的元素为[0,1]、[0,3]、[1,3]、[2,1]、[2,3]
# 2. np.where(condition,x,y) # 满足condition条件就输出x否则输出y
print(np.where(a % 2 == 1,a,a * 2))
# [[ 0 1 4 3]
# [ 8 200 12 7]
# [ 16 9 20 11]]
数组的转置
import numpy as np
a = np.arange(12).reshape(3,4)
print(a)
# [[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]]
print(a.T)
# [[ 0 4 8]
# [ 1 5 9]
# [ 2 6 10]
# [ 3 7 11]]
🌑 数组中的一些运算函数
- 数组的均值
import numpy as np
a = np.arange(12).reshape(3,4)
print(a)
# [[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]]
print(a.mean())
# 5.5
print(a.mean(axis=0)) # 每列的均值
# [4. 5. 6. 7.]
print(a.mean(axis=1)) # 每行的均值
# [1.5 5.5 9.5]
- 数组的和
import numpy as np
a = np.arange(12).reshape(3,4)
print(a)
# [[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]]
print(a.sum()) # 数组的和
# 66
print(a.sum(axis=0)) # 每列的和
# [12 15 18 21]
print(a.sum(axis=1)) # 每行的和
# [ 6 22 38]
- 数组的累加和
import numpy as np
a = np.arange(12).reshape(3,4)
print(a)
# [[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]]
print(a.cumsum()) # 数组的累加和
# [ 0 1 3 6 10 15 21 28 36 45 55 66]
print(a.cumsum(axis=0)) # 每列的累加和
# [[ 0 1 2 3]
# [ 4 6 8 10]
# [12 15 18 21]]
print(a.cumsum(axis=1)) # 每行的累加和
# [[ 0 1 3 6]
# [ 4 9 15 22]
# [ 8 17 27 38]]
- 数组的标准差(standard deviation和方差variance
import numpy as np
a = np.arange(12).reshape(3,4)
print(a)
# [[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]]
print(a.std()) # 数组的标准差
# 3.452052529534663
print(a.var()) # 数组的方差
# 11.916666666666666
🌗 Pandas库
pandas库在数据分析中是非常重要和常用的库。在数据预处理、缺失值填补、时间序列和可视化等方面都有应用。
🌑 序列和数据表
序列是一维标签数组能够容纳任何类型的数据。它类似于字典字典中的键就相当于序列中的索引字典中的值就相当于是数据键和值一一对应索引和数据也一一对应。
import pandas as pd
a = pd.Series(index=["a","b","c"],data=[1,2,3])
print(a)
# a 1
# b 2
# c 3
# dtype: int64
a = pd.Series(index=["a","b","c"],data=[1,2,3],name="var1") # 其中name是序列的名称是可选参数
print(a)
# a 1
# b 2
# c 3
# Name: var1, dtype: int64
可以通过切片和索引获取序列中的对应值也可以对获得的数值重新赋值。
import pandas as pd
a = pd.Series(index=["a","b","c"],data=[1,2,3],name="var1")
print(a[["a","c"]])
# a 1
# c 3
# Name: var1, dtype: int64
a[["a","c"]] = 100,200
print(a)
# a 100
# b 2
# c 200
# Name: var1, dtype: int64
前面说了序列跟字典非常像那么也可以用字典来生成序列
import pandas as pd
# 用字典生成序列
a = pd.Series({"A":100,"B":200,"C":300,"D":200})
print(a)
# A 100
# B 200
# C 300
# D 200
# dtype: int64
print(a.value_counts()) # 计算序列中每个取值出现的次数
# 200 2
# 100 1
# 300 1
# dtype: int64
数据表是一种二维数据结构数据按行和列的表格方式排列。数据表跟二维数组也非常的像它们之间不同的地方在于数据表的每行有一个标号每列也对应着一个名称。它的格式为
pd.DataFrame(index,data,columns)
其中index用于指定数据表的索引data就是索引对应的数据可以用字典、数组等内容columns用于指定数据表的列名。
用字典生成数据表时字典的键将会作为数据表格的列名值将会作为对应列的内容。
import pandas as pd
data = {"name":["Amy","Bob","Cindy","Tom"],"age":[20,19,21,18],"sex":["F","M","F","M"]}
a = pd.DataFrame(data = data)
print(a)
# name age sex
# 0 Amy 20 F
# 1 Bob 19 M
# 2 Cindy 21 F
# 3 Tom 18 M
# 添加新的列
a["height"] = [165,178,169,175]
print(a)
# name age sex height
# 0 Amy 20 F 165
# 1 Bob 19 M 178
# 2 Cindy 21 F 169
# 3 Tom 18 M 175
# 获取数据表的列名
print(a.columns)
# Index(['name', 'age', 'sex', 'height'], dtype='object')
# 通过列名获取数据表中的数据
print(a[["name","sex"]])
# name sex
# 0 Amy F
# 1 Bob M
# 2 Cindy F
# 3 Tom M
针对数据表格可以使用loc()函数获取指定的数据。它有两个参数第一个是索引行第二个就是列用来选择指定位置的数据。
print(a)
# name age sex height
# 0 Amy 20 F 165
# 1 Bob 19 M 178
# 2 Cindy 21 F 169
# 3 Tom 18 M 175
print(a.loc[2]) # 输出第二行的数据
# name Cindy
# age 21
# sex F
# height 169
# Name: 2, dtype: object
print(a.loc[0:2]) # 输出第0行到第2行的数据
# name age sex height
# 0 Amy 20 F 165
# 1 Bob 19 M 178
# 2 Cindy 21 F 169
print(a.loc[0:2,["name","sex"]]) # 输出第0到第2行的name和sex列注意关于列的参数不能像行那样切片
# name sex
# 0 Amy F
# 1 Bob M
# 2 Cindy F
print(a.loc[a.sex == "F",["name","sex"]]) # 输出name和sex列且sex为F的数据
# name sex
# 0 Amy F
# 2 Cindy F
iloc()函数是基于位置的索引来获取对应的内容也就是说用这个函数对于列的参数就可以切片了。
print(a)
# name age sex height
# 0 Amy 20 F 165
# 1 Bob 19 M 178
# 2 Cindy 21 F 169
# 3 Tom 18 M 175
print(a.iloc[0:2]) # 获取第0到第1行的数据注意这个切片是左闭右开“[)”
# name age sex height
# 0 Amy 20 F 165
# 1 Bob 19 M 178
print(a.iloc[0:2,0:2]) # 获取第0到1行第0到1列的数据
# name age
# 0 Amy 20
# 1 Bob 19
a.iloc[0:1,0:2] = ["Alan",25] # 将第0行第0列的数据改为“Alan”将第0行第1列的数据改为25
print(a)
# name age sex height
# 0 Alan 25 F 165
# 1 Bob 19 M 178
# 2 Cindy 21 F 169
# 3 Tom 18 M 175
🌑 数据聚合与分组运算
apply()函数可以将指定的函数作用于数据的行或列并将其应用于数据计算。
data = {"a":[23,40,39,11],"b":[1.3,0.9,1.5,1.1],"c":[103,122,119,108],"d":[89,91.2,88.9,90.5]}
a = pd.DataFrame(data = data)
print(a)
# a b c d
# 0 23 1.3 103 89.0
# 1 40 0.9 122 91.2
# 2 39 1.5 119 88.9
# 3 11 1.1 108 90.5
## 计算每列的均值
print(a.iloc[:,:].apply(func=np.mean,axis=0)) # func是将要应用于某行或某列的函数axis=0表示将要对每列进行操作
# a 28.25
# b 1.20
# c 113.00
# d 89.90
# dtype: float64
## 计算每列的最大值和最小值
print(a.iloc[:,:].apply(func=(np.min,np.max),axis=0))
# a b c d
# amin 11 0.9 103 88.9
# amax 40 1.5 122 91.2
## 计算每列的样本数量
print(a.iloc[:,:].apply(func=np.size,axis=0))
# a 4
# b 4
# c 4
# d 4
# dtype: int64
## 根据行进行计算
print(a.iloc[:,:].apply(func=(np.min,np.max,np.mean,np.std,np.var),axis=1))
# amin amax mean std var
# 0 1.3 103.0 54.075 49.545493 2454.755833
# 1 0.9 122.0 63.525 53.729407 2886.849167
# 2 1.5 119.0 62.100 52.159435 2720.606667
# 3 1.1 108.0 52.650 54.431517 2962.790000
groupby()函数可进行分组统计。
print(a)
# a b c d
# 0 23 1.3 103 89.0
# 1 40 0.9 122 91.2
# 2 39 1.5 119 88.9
# 3 11 1.1 108 90.5
print(a.groupby(by="a").mean())
# b c d
# a
# 11 1.1 108.0 90.5
# 23 1.3 103.0 89.0
# 39 1.5 119.0 88.9
# 40 0.9 122.0 91.2
print(a.groupby(by="c").mean())
# a b d
# c
# 103 23.0 1.3 89.0
# 108 11.0 1.1 90.5
# 119 39.0 1.5 88.9
# 122 40.0 0.9 91.2
🌗 Matplotlib库
Matplotlib是python的一个绘图库pyplot是其中的一个模块它提供了类似MATLAB的绘图接口能够绘制2D、3D等图像。
下面就来小试牛刀生成一个y=sin(x)的图像
🌑二维可视化图像
import matplotlib.pyplot as plt
import numpy as np
X = np.linspace(1,15) # linspace用于生成一个1~15的等差数列默认生成50个样本量
Y = np.sin(X) # 根据X的点绘制出Y的点
plt.figure(figsize=(10,6)) # 定义一个图像窗口宽10长6
plt.plot(X,Y,"r-") # 绘制X和Y的图像红色、直线
plt.xlabel("X轴") # X坐标轴的名称
plt.ylabel("Y轴") # Y坐标轴的名称
plt.title("y=sin(x)") # 图像的名称
plt.grid() # 图像中添加网格
plt.show() # 显示图像
显示如下
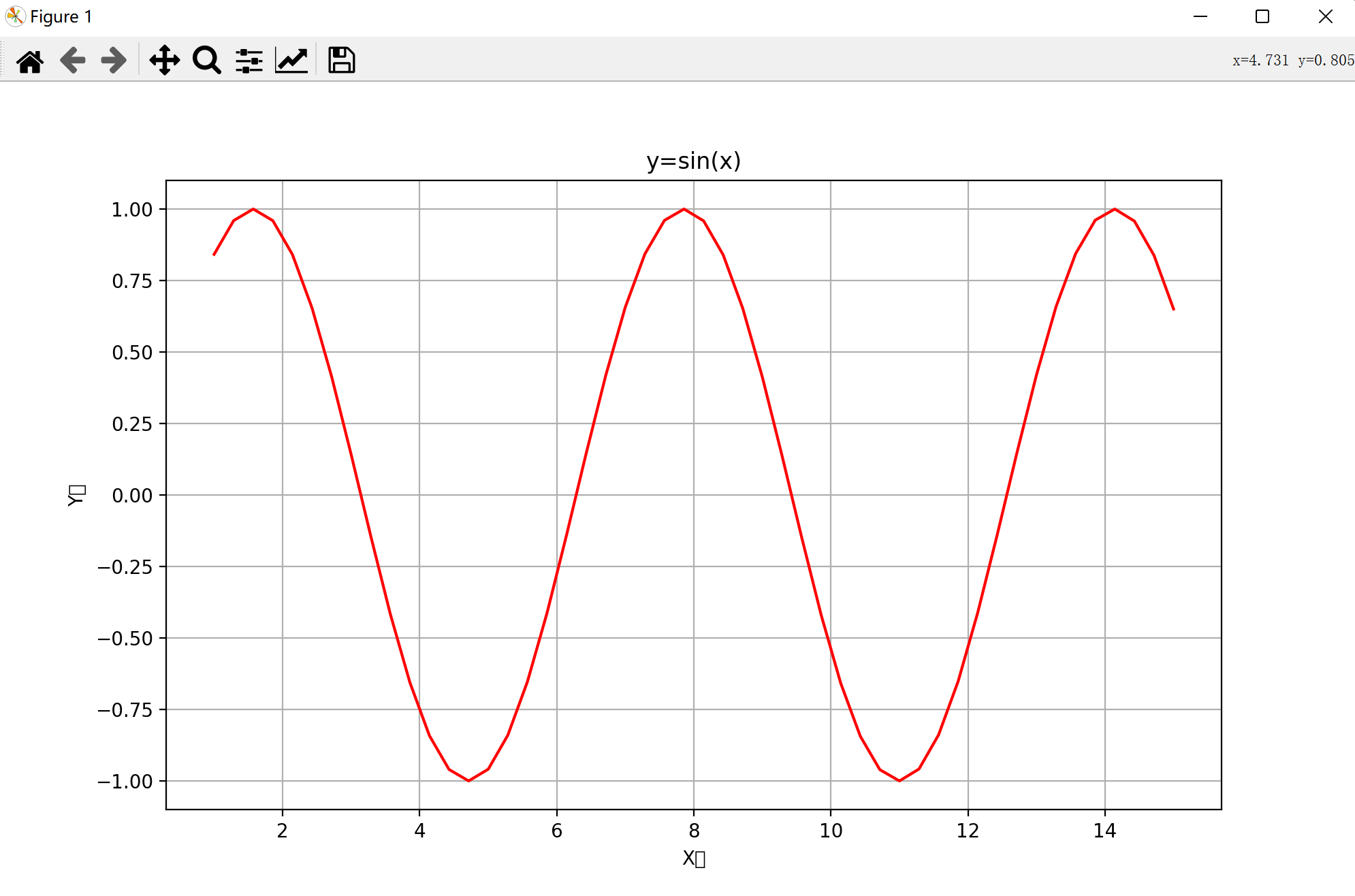
可以看到X和Y轴的名称中那个“轴”并没有显示出来这是因为Matplotlib库默认不支持中文文本在图像中的显示。为了解决这个问题我们可以添加以下代码
import matplotlib
matplotlib.rcParams['axes.unicode_minus']=False
import seaborn as sns
sns.set(font="Kaiti",style="ticks",font_scale=1.4)
其中seaborn是数据可视化库使用其set()方法可以设置可视化图像时的基础部分参数font指定图中文本使用的字体style设置坐标系的样式font_scale设置字体的显示比例等。
添加了这段代码后的显示如下

这样就可以正常显示中文啦
🌑三维可视化图像
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['axes.unicode_minus']=False
import seaborn as sns
sns.set(font="Kaiti",style="ticks",font_scale=1.4)
x = np.linspace(-4,4,num=50) # x的范围为-4~4上均匀分布的50个点
y = np.linspace(-4,4,num=50) # y的范围为-4~4上均匀分布的50个点
X,Y = np.meshgrid(x,y) # 根据输入的坐标向量生成对应的坐标矩阵
Z = np.sin(np.sqrt(X**2+Y**2))
fig = plt.figure(figsize=(10,6)) # 设置图像的大小
ax1 = fig.add_subplot(111,projection="3d") # 在图像中增加一个坐标轴也就是初始化一个3D坐标系ax1
ax1.plot_surface(X,Y,Z,rstride=1,cstride=2,alpha=0.5,cmap=plt.cm.coolwarm) # 绘制曲面图
cset = ax1.contour(X,Y,Z,zdir="z",offset=1,cmap=plt.cm.CMRmap) # 绘制Z轴方向的等高线投影位置在Z=1的平面
ax1.set_xlabel("X") # X轴的名称
ax1.set_xlim(-4,4) # 设置X轴的绘图范围
ax1.set_ylabel("Y") # Y轴的名称
ax1.set_ylim(-4,4) # 设置Y轴的绘图范围
ax1.set_zlabel("Z") # Z轴的名称
ax1.set_zlim(-1,1) # 设置Z轴的绘图范围
ax1.set_title("曲面图和等高曲线")
plt.show()
显示如下
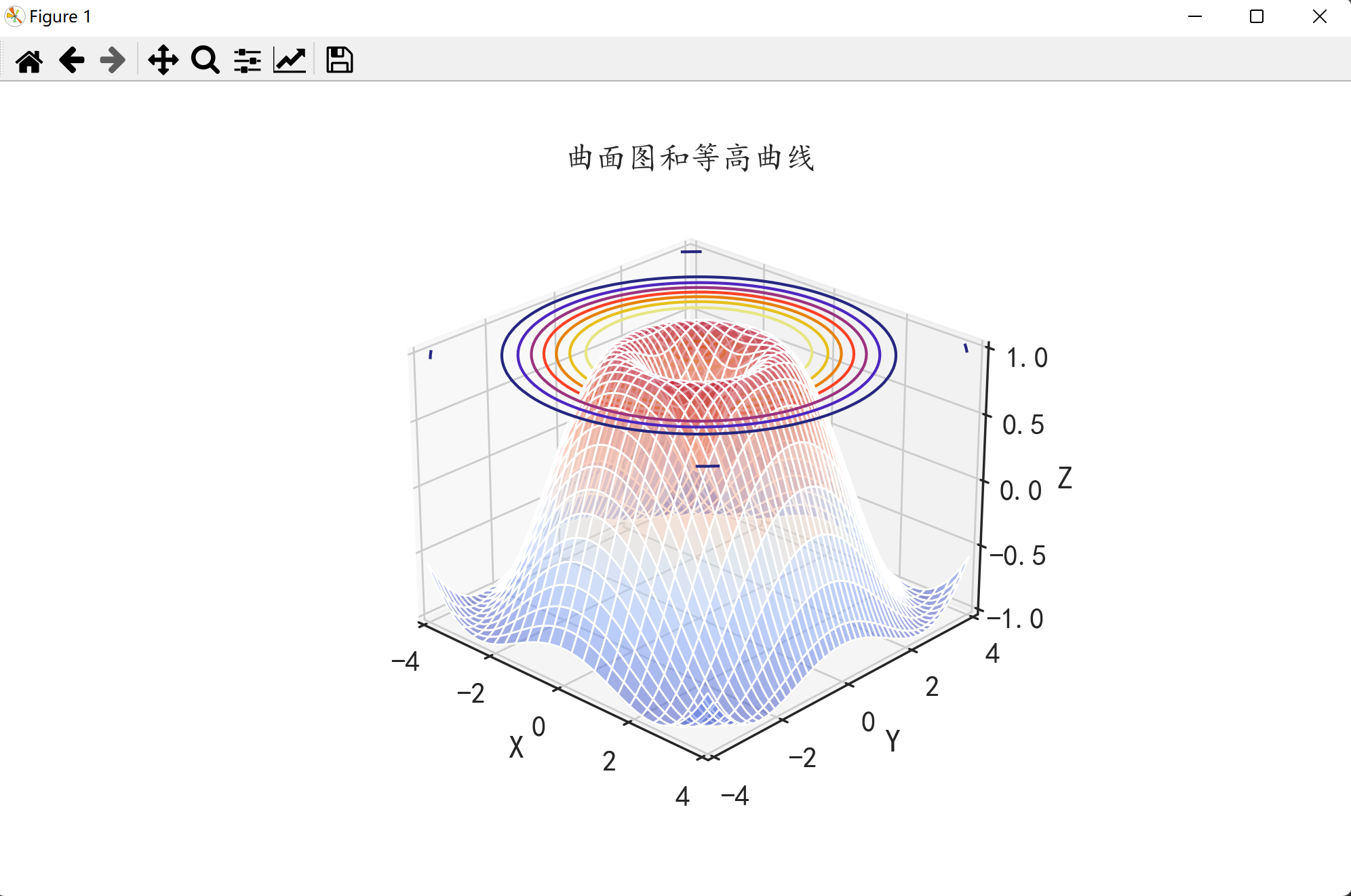
🌑可视化图片
import numpy as np
import matplotlib.pyplot as plt
# skimage库的全称是scikit-image
from skimage.io import imread # 从skimage库中引入读取图片的函数
from skimage.color import rgb2gray # 从skimage库中引入将RGB图片转化为灰度图像的函数
im = imread("02.jpg") # 读取图片
imgray = rgb2gray(im)
plt.figure(figsize=(10,6))
plt.subplot(1,2,1) # RGB图像
plt.imshow(im)
plt.axis("off") # 不显示坐标轴
plt.title("RGB Image")
plt.subplot(1,2,2) # 灰度图像
plt.imshow(imgray,cmap=plt.cm.gray)
plt.axis("off") # 不显示坐标轴
plt.title("Gray Image")
plt.show()
注subplot()函数是将多个图画到一个平面上例如subplot(m,n,p)表示的是将这些图画拍成m行n列p表示从左到右、从上到下的第一个位置那么subplot(1,2,1)表示的就是对这两块图中的第一块进行绘制。subplot(1,2,2)表示的就是对这两块图中的第二块进行绘制。
显示如下
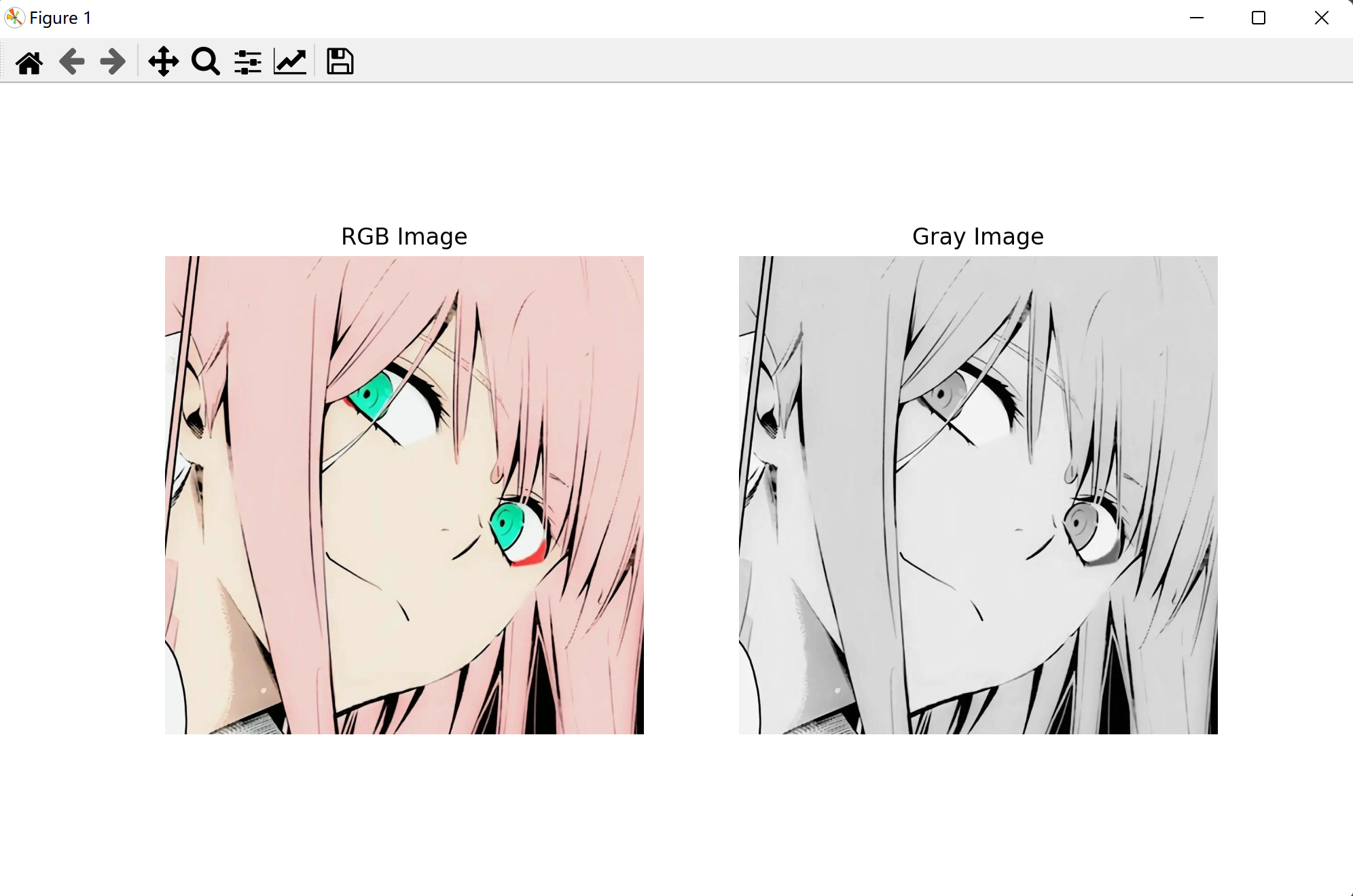
🌕 机器学习模型初探索
假设房子的价格只跟面积有关下表给出了一些房子的面积和价格之间的数据请计算出40 m 2 m^2 m2的房屋价格。
| 面积( m 2 m^2 m2) | 56 | 32 | 78 | 160 | 240 | 89 | 91 | 69 | 43 |
|---|---|---|---|---|---|---|---|---|---|
| 价格(万元) | 90 | 65 | 125 | 272 | 312 | 147 | 159 | 109 | 78 |
对于这样一个问题我们不知道房子的价格与面积满足怎样的一个数学关系我们可以先将面积看作x将价格看作y并将这些数据利用散点图进行可视化。
import matplotlib.pyplot as plt
import numpy as np
from sklearn.linear_model import LinearRegression
import matplotlib
matplotlib.rcParams['axes.unicode_minus']=False
import seaborn as sns
sns.set(font="Kaiti",style="ticks",font_scale=1.4)
x = np.array([56,32,78,160,240,89,91,69,43])
y = np.array([90,65,125,272,312,147,159,109,78])
X = x.reshape(-1,1)
Y = y.reshape(-1,1)
plt.figure(figsize=(10,6))
plt.scatter(X,Y,s=50)
plt.title("原始数据的图")
plt.show()
- np.arange(n).reshape(a,b)
依次生成n个自然数并且以a行b列的数组形式表示X=x.reshape(-1,1)是将x这个数组进行重组-1表示自动计算行数1表示列数行数=(a*b)/1。
print(x)
# [ 56 32 78 160 240 89 91 69 43]
print(X)
# [[ 56]
# [ 32]
# [ 78]
# [160]
# [240]
# [ 89]
# [ 91]
# [ 69]
# [ 43]]
- plt.scatter(X,Y,s)
XY表示的是形状为(n,)的数组也就是每个点对应的横纵坐标。s表示图中每个点的大小。
显示如下
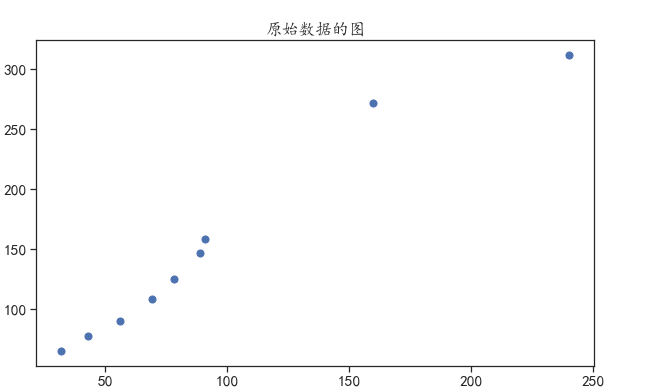
然后就是训练模型和预测。
model = LinearRegression()
model.fit(X,Y)
x1 = np.array([40,]).reshape(-1,1) # x1为我们去预测的条件
x1_pre = model.predict(np.array(x1)) # 预测面积为40平方米时的房价
print(x1_pre)
# 79.59645966
最后我们再将预测的点也打在图上
plt.figure(figsize = (10,6))
plt.scatter(X,Y) # 先打出原始数据的点
b = model.intercept_ # 训练好的模型的截距
a = model.coef_ # 训练好的模型的斜率
y = a * X + b # 原始数据按照训练好的模型画出的直线
plt.plot(X,y)
y1 = a * x1 + b # 预测的点房子面积为40平方米时的房价
plt.scatter(x1,y1,color='r') # 将预测的点以红色绘制在散点图上
plt.show()
显示如下
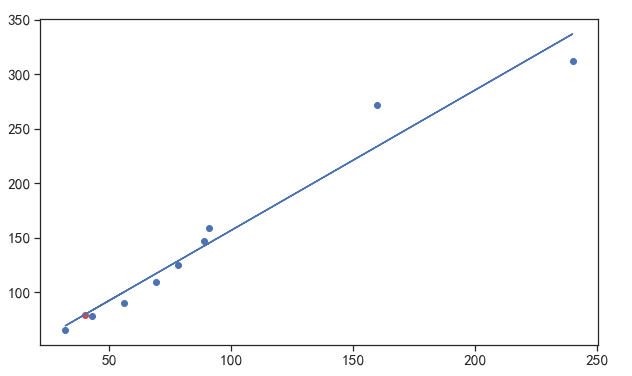
⭐️总结上面针对房屋价格预测的一元线性回归模型经过了以下5个步骤
- 数据预处理将数据处理为适合模型使用的数据格式
- 建立模型利用model=LinearRegression()建立线性回归模型
- 训练模型model.fit(x,y)
- 模型预测model.predict([[a]])
- 评价模型利用可视化方式直观地评价模型的预测效果