

ChatGPT背后的模型
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
文章目录
InstructGPT语言模型是一个比 GPT-3 更善于遵循用户意图同时使用通过我们的对齐研究开发的技术使它们更真实、毒性更小。InstructGPT 模型循环迭代的过程当中加入了人类反馈进行训练。
比如下面的例子几句话向6岁的孩子解析登月

可以看到GPT-3模型的回答需要分开多个句子进行解析这样的回答并不像人类。而InstructGPT模型的回答在逻辑和语义通顺上更加偏向于人类的回答。
实际上GPT-3 模型未接受过遵循用户说明的训练。InstructGPT 模型上面蓝色的字体生成更有用的输出以响应用户指令。
在GPT-3模型中可以使用精心设计好的文本提示词语引导该模型执行自然语言任务。但是这些模型在生成文本时会输出不真实、有毒或反映有害情绪的文本。这是因为在训练GPT-3模型的时候利用了大量的互联网文本数据来预测下一个单词而不是在安全情况下执行用户想要的语言文本。总结来说GPT-3模型与用户的需求不太一致。
为了让模型生成更安全有用对其用户需求的文本OpenAI使用了一个称为**RLHFReinforcement Learning from Human Feedback**的方法**它是一种根据人类反馈从而进行学习的强化学习方法。**在实际过程中用户提交文本提示词语标注者针对模型给出的几个回答进行排序这样就可以对GPT-3模型进行fine-tune这样就可以得到InstructGPT模型。
InstructGPT模型比GPT-3模型更擅长遵循用户的指令。这个模型很少会编造事实同时在有毒输出产生方面表现出小幅下降。InstructGPT模型参数量比GPT少100倍只达到了1.3B但其效果和GPT-3模型差不多。
1.RLHF方法
接下来详细讲一下InstructGPT中用到的RLHF方法。
构建一个安全的AI模型**首先需要的就是摆脱直接编写目标函数的需求。**因为如果对复杂的目标任务使用简单的函数进行表征或者使用错误的函数进行表征就可能导致模型学习到不良的甚至时危险的行为。简单来说就是让模型生成多种输出然后人工标注哪种输出更好来指导模型训练。
这里以“训练AI进行后空翻操作”为例子讲述RLHF的原理

在算法中仅仅需要900位人类的反馈就可以完成AI后空翻的训练效果。其包含了3个训练循环步骤

- 奖励预测根据人类的反馈
- RL算法训练
- agent理解目标行为
AI agent首先在环境中随机行动。定期将其行为的两个视频片段提供给人工审核标注者决定两个片段中的哪一个最接近实现其目标——在本例中为后空翻。人工智能通过找到最能解释人类判断的奖励函数逐步建立任务目标模型。然后它使用 RL 来学习如何实现该目标。随着其行为的改进它会继续询问人类对轨迹行为的反馈并进一步完善其对目标的理解。
后空翻视频需要不到 1000 位的人类反馈。它花费了人类评估者不到一个小时的时间。下面就是人工在看视频标注的过程

作为对比研究者重新编写了奖励函数也训练了一个模型。从实验上看使用RLHF方法要更优雅得多。左图为RLHF右图为正常利用奖励函数进行训练

OpenAI进一步把RLHF方法试验到多个领域中包括模拟机器人和 雅利达游戏上。在这些游戏中没有利用后台的分数作为奖励函数而仅仅利用标注进行奖励。
Agent可以从人类反馈中学习有时甚至是超人的表现。在下面的动画中可以看到训练好的智能体玩各种雅利达游戏。

2.ChatGPT中的RLHF方法
在实际应用上训练ChatGPT中其包含了几个以下的三个主要步骤
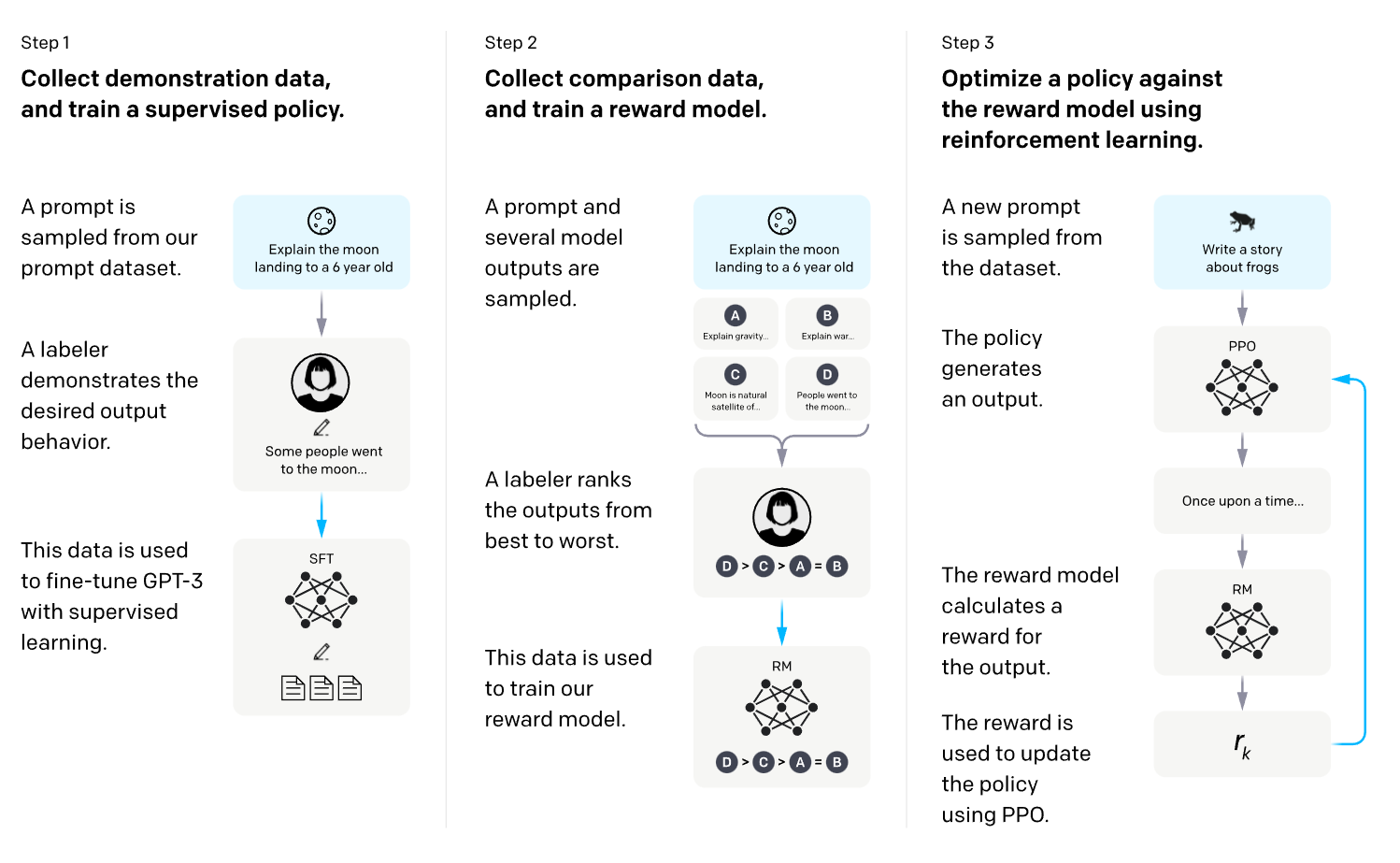
- 收集人工标记的数据用来微调预训练模型GPT-3
- 训练奖励模型
- 利用强化学习进一步微调语言模型
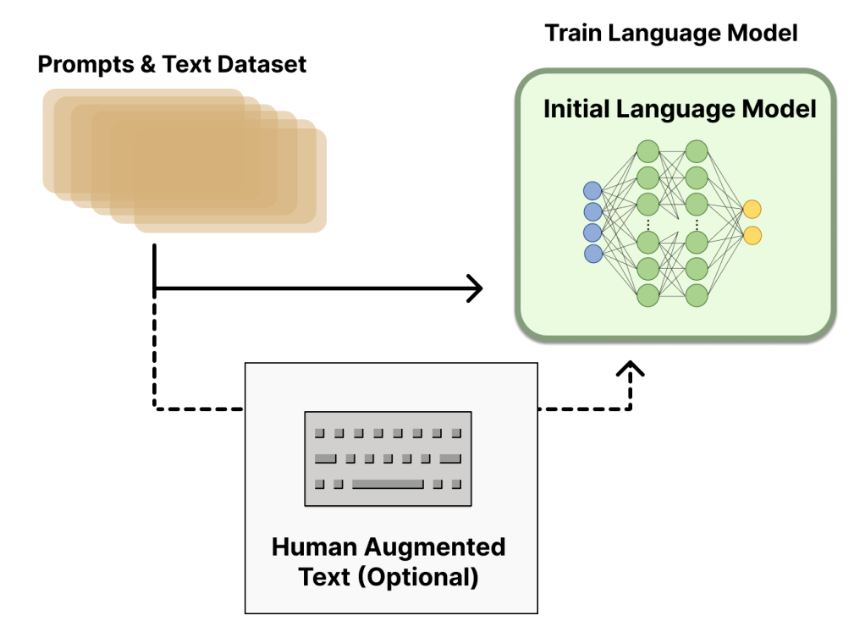
2.1 微调模型GPT-3
第一步比较简单ChatGPT直接使用GPT-3作为预训练模型。在人工标注的数据微调后可以得到一个初始化LM模型Initial Language Model。
2.2 训练奖励模型
从Prompts数据集中抽样出多个prompts然后输入到上面微调过的LM模型中这样会得到多个输出文本即[prompt, generated text]。
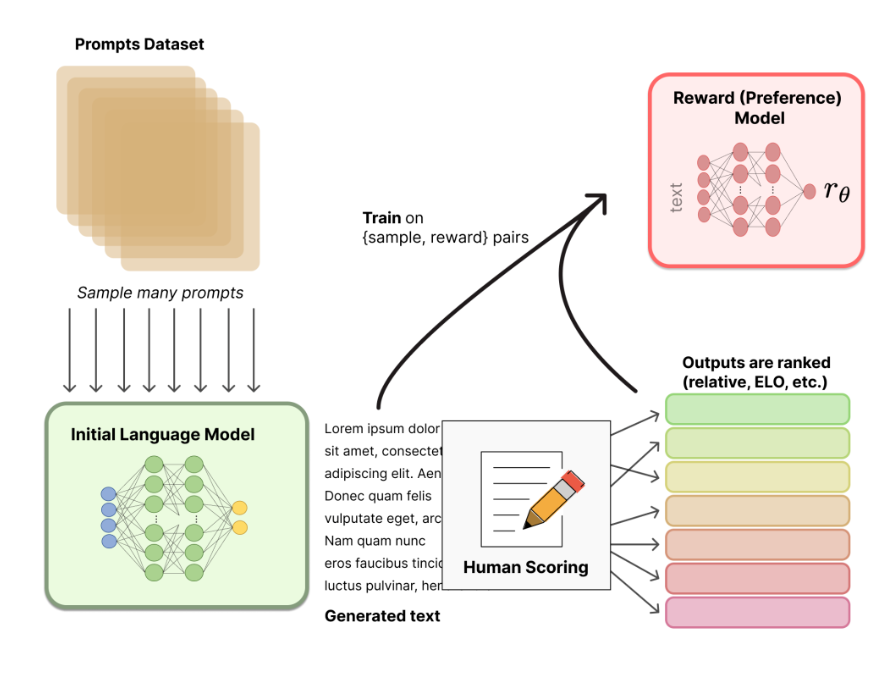
接下来利用人工方法对这些输出的文本进行排序人为确认哪些文本较为满意。
**为什么要使用排序方法而不是直接打分数呢**这是因为不同的研究人员对同一个句子可能有不一样的评分这样会导致大量的噪声出现如果改成排序则会大大降低噪声。
得到排序结果后就可以用来训练奖励模型。奖励模型可以利用预训练模型进行初始化或者也可以进行随机初始化。然后把人工标注的排序结果输入到奖励模型中。这里可以使用类似推荐系统中的“pair-wise”把两个句子输入进行奖励模型判别哪个句子较好。
最后我们就有了两个模型一个是第一步得到的LM模型另一个是现在得到的奖励模型RM。
2.3 利用强化学习进一步微调语言模型
利用强化学习方法不断强化Tuned Language Model。让这个模型生成的文本越来越符合人类的语言认知。这样最终得到的模型在文本生成上更加语义通顺和安全。
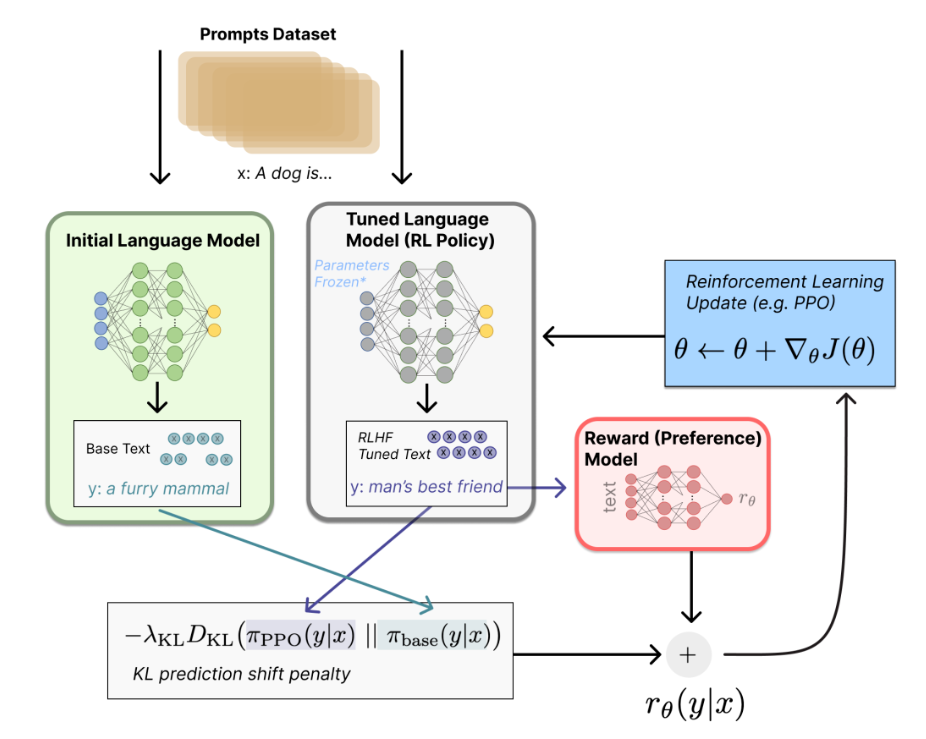
这其中用到的强化学习方法主要是PPO算法感兴趣的同学可以了解一下。
3.效果
为了衡量模型的安全性OpenAI主要在公开可用的数据集上进行验证。与 GPT-3 相比InstructGPT 产生的模仿性错误更少并且毒性更小。同时发现 InstructGPT 更少地编造事实“幻觉”并生成更合适的输出。

4.面临挑战
RLHF算法的性能最高只能达到与人类评估的行为因此如果人类没有很好地掌握任务他们不会提供很多有用的反馈这进一步限制了模型的效果。
同时AI系统的安全性不仅取决于底层模型的行为还取决于这些模型的部署方式。需要更多的过滤器来检测不安全行为的生成。
InstructGPT更多的还是偏向于英语的文化价值观针对少数群体的差异和分歧该模型很难对齐。这更需要加入人工知识来进一步平衡模型的价值观。
5.参考
1.[https://zhuanlan.zhihu.com/p/591474085](https://zhuanlan.zhihu.com/p/591474085)
2.[https://huggingface.co/blog/rlhf](https://huggingface.co/blog/rlhf)
3.[https://openai.com/blog/deep-reinforcement-learning-from-human-preferences/](https://openai.com/blog/deep-reinforcement-learning-from-human-preferences/)
4.[https://mp.weixin.qq.com/s?__biz=MzI4MDYzNzg4Mw==&mid=2247554744&idx=3&sn=58d27263f499a939cba817522840a9cb&chksm=ebb72e6cdcc0a77a135c55c297c3c8c5ee106780c92f072bbf821ea0f8a1e143a47034e69680&scene=27](https://mp.weixin.qq.com/s?__biz=MzI4MDYzNzg4Mw==&mid=2247554744&idx=3&sn=58d27263f499a939cba817522840a9cb&chksm=ebb72e6cdcc0a77a135c55c297c3c8c5ee106780c92f072bbf821ea0f8a1e143a47034e69680&scene=27)
5.[https://openai.com/blog/instruction-following/](https://openai.com/blog/instruction-following/)
好了以上就是本期的全部内容了我是leo欢迎关注我的公众号/知乎"算法一只狗"我们下期再见~