

使用Python预处理机器学习需要的手写体数字图像文件数据集
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
封面图片:《Python程序设计实验指导书》,董付国,清华大学出版社
=============
问题描述:为演示机器学习算法对手写体数字识别与分类,需要准备大量数据,如果自己写的话需要很长时间,于是找很多同学帮忙,每位同学提供30张图片,每个图片包含一个数字的手写体,分别命名为0_1.png、0_2.png、0_3.png、1_1.png、1_2.png、1_3.png、...
一般来说,拿到的数据集都是无法直接使用的,这个数据集也不例外。真正作为机器学习数据集的话,需要对这些文件进行预处理,所有图片文件统一命名(虽然这并不是必须的)为0.jpg、1.jpg、2.jpg、3.jpg...同时应提供每个图片中数字对应的标签,也就是图片文件中实际包含的数字。
同学们提交的文件使用董付国老师开发的课堂管理系统统一收集(选用董付国老师系列Python教材的老师可以免费获取软件源码,既可以上课用,也可以作为教学案例),当然也可以通过其他途径收集,该软件教师端界面如下:

收集后文件夹结构如图所示:
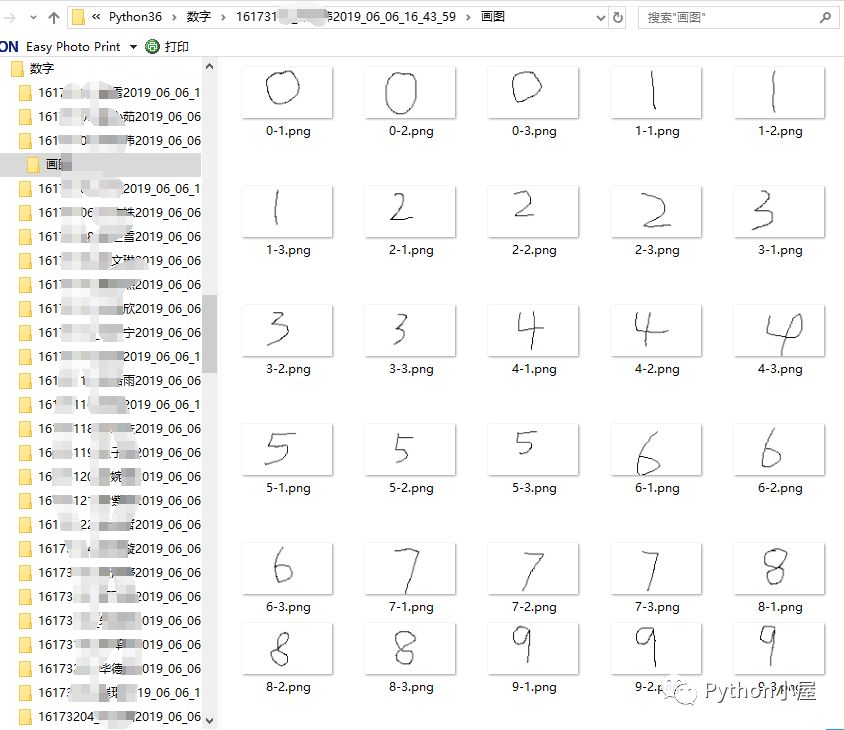
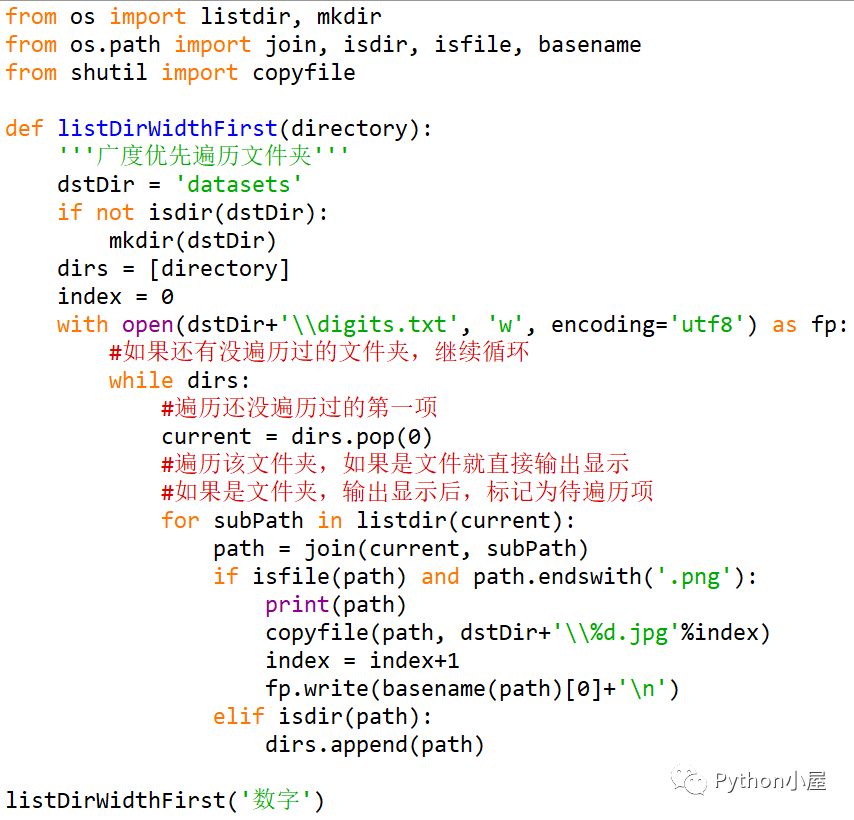
下面代码要解决的任务是:遍历所有png图片文件,将其按顺序编号复制到datasets文件夹并改名为jpg文件,同时根据文件名第一个字符获取该图片中实际包含的数字并写入文件digits.txt。
使用广度优先遍历目录树预处理数据集的参考代码:
代码运行后得到统一命名的图片文件,可以发现有同学故意捣乱啊,但这恰好反映了数据预处理的重要性:
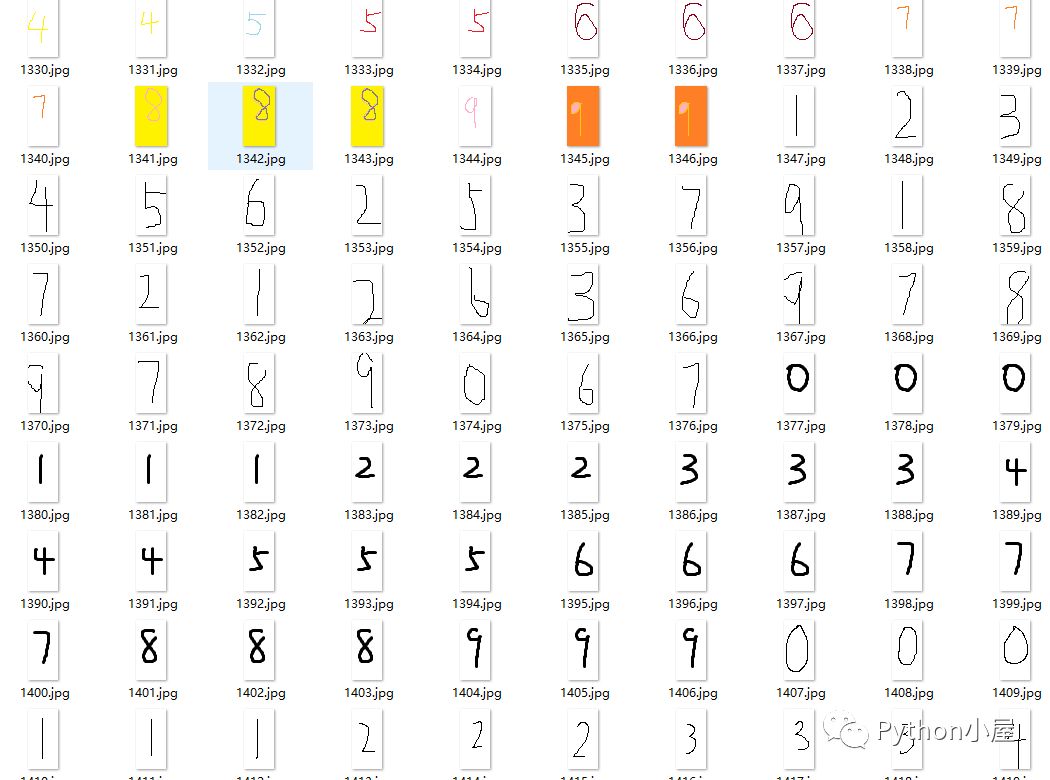
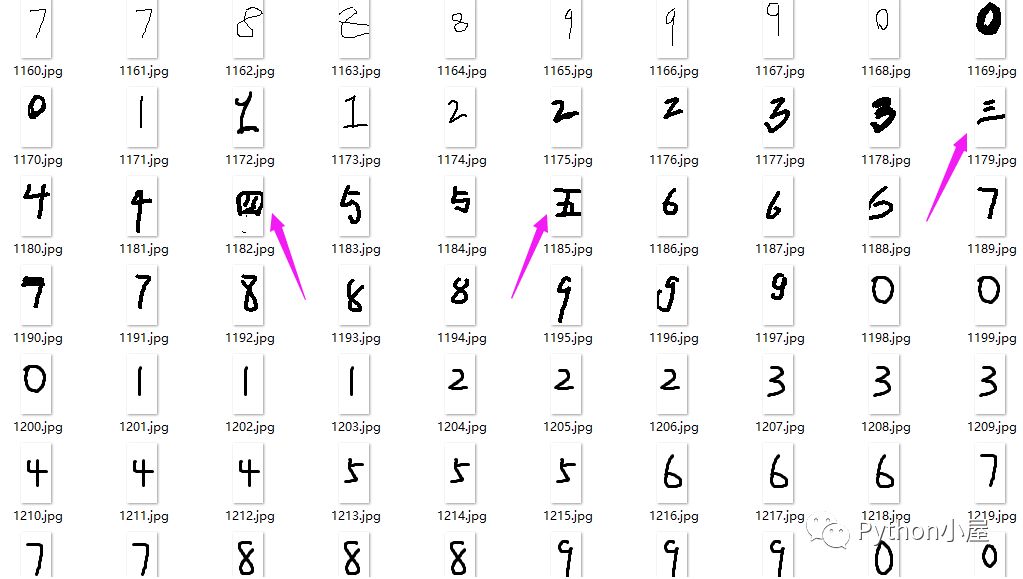
生成的标签文件digits.txt中部分内容:
公众号“Python小屋”
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |