

【计算几何】沃罗诺伊图 | KNN 最邻近算法 | Voronoi 函数 | 利用 make
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
 猛戳跟哥们一起玩蛇啊 👉 《一起玩蛇》🐍
猛戳跟哥们一起玩蛇啊 👉 《一起玩蛇》🐍

 本篇博客全站热榜排名16
本篇博客全站热榜排名16
写在前面上一章我们介绍了介计算几何领域的德劳内三角剖分我们提到过关于点集的很多种几何图都与德劳内三角剖分密切相关其中最具代表的就是我们本章要介绍的 Voronoi 图 (即沃罗诺伊图) 。沃罗诺伊图有许多应用包括计算机图形学、地理信息系统、计算机视觉等领域。
Ⅰ. 前置知识Antecedent
0x00 引入什么是沃罗诺伊图

介绍沃罗诺伊图 (Voronoi Diagram) 又称 "狄利克雷镶嵌" (Dirichlettessellation) 又又称泰森多边形 (Thiessen polygon) 又又又称维诺图。是由俄国数学家 格奥尔基 · 沃洛诺伊 所建立的空间分割算法故命名为沃洛诺伊图。
其于1908年提出在《莫斯科数学学报》上发表了一篇题为《距离函数和近似问题》的论文在其中首次提出了沃罗诺伊图的概念沃罗诺伊图后来被广泛应用于许多领域并成为计算机图形学和地理信息系统等领域的重要工具。
性质沃洛诺伊图是一种可以把点转化成区域的图表这种图表中每个划分区域中的任何一点距离区域中心的距离都比距离其他区域中心点的距离更近。
- 沃罗诺伊图是按照与种子点 (seed point) 的距离分割平面的示意图
- 对于顶平面上的种子点
根据平面上的点与哪个
最接近来划分区域

定义用 表示一个距离函数为
的空间一个非空集合。令
为一个指数集合
为空间
的一个非空子集的有序元组。对应于
的
称沃罗诺伊原胞或称沃罗诺伊区域是空间
中所有到
的距离不大于到其他位置
(p!=k) 的点集。或者说如果定义
为点
和子集
的距离则
沃罗诺伊图即原胞 的元组。理论上有些位点能够交叉甚至重合但事实上它们往往被设定为不相交的。另外定义过程中允许位点数目无限然而通常情况下只考虑有限位点数。
对于某些特定情况如有限维度的欧几里得空间每一位点对应于一个点。这些点是有限且各异的则沃罗诺伊原胞表现为凸多胞形由它们的顶点、边、二维面等的组合方式加以描述。有时引入的组合结构被称为沃罗诺伊图。然而沃罗诺伊原胞不一定是凸形甚至不一定是连通的。
0x01 德劳内三角剖分与沃罗诺伊图的关系
德劳内三角剖分和沃罗诺伊图诺是双重关系 (dual) 只要知道一个就可以得到另一个。
德劳内 沃罗诺伊
用每个种子点将入口三角分割后连接被求出的三角形的外接园的中心就是博罗诺可以获得这个图像。
沃罗诺伊 德劳内
若将沃罗诺伊区域之间的种子点连接起来就可以获得这些种子点的德劳内三角剖分。

0x02 KNN 最邻近算法 (K-Nearest Neighbor)
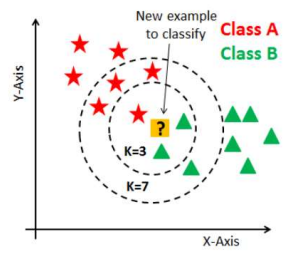 (K-Nearest Neighbor)
(K-Nearest Neighbor)
定义当输入新数据时通过将现有数据与新数据进行比较选出与新数据最接近的 个数据并根据
个数据的 category 对输入数据进行分类通常使用欧几里德距离。
欧几里得距离是两点在 维空间中的距离其公式如下

算法的工作流程如下
- 确定最近邻数量
。
- 计算待分类样本与训练数据集中每个样本的距离。
- 按照距离的大小对训练数据集中的样本进行排序。
- 选取距离最小的
- 确定
- 将待分类样本分类为出现次数最多的类别。
优点简单高效学习数据中的噪声影响不大训练速度可观。
缺点研究人员根据每个数据的特性任意设置最佳邻域数和要使用的距离尺度。测量新的观测值和每个学习数据之间的全部距离计算耗时较长对于给定的训练样本集需要对整个数据集进行扫描因此时间复杂度为
对于较大的数据集不太适用。
0x03 利用 make_classification 生成分类数据集
我们可以利用 sklearn.datasets 库中的 make_classification 去生成一些数据
import numpy as np
import matplotlib .pyplot as plt
import cv2
from sklearn.datasets import make_classification
# 使用 make_classification 创建数据
X, y = make_classification (
n_features = 2, # 设置特征数为2
n_samples = 200, # 设置样本数量为200
n_informative = 1, # 指定有用特征数量为1
n_redundant = 0, # 指定冗余特征0为无冗余特征
n_clusters_per_class = 1, # 指定每个类别簇数为1
random_state = 3 # 指定随机数种子为3
)
plt.scatter (
X[:, 0], X[:, 1],
marker = 'o', c = y, s = 100, edgecolor = "k", linewidth = 2
)
plt.xlim(-3,3)
plt.ylim(-3,3)
plt.show()🚩 运行结果

💡 代码分析上述代码中 make_classification 函数生成的数据储存在两个变量 和
中其中
是一个二维数组包含所有样本的两个特征而
是一个一维数组包含所有样本的类别。参数解释如下
n_features参数用于指定特征数我们设置为了 2 个。n_samples参数用于指定样本数量我们指定为 200 个。n_informative参数指定了有几个特征是有用的即可以用来帮助分类的这里设置为 1 表示只有一个特征是有用的。n_redundant参数指定了有几个特征是冗余的这里设置为 0 表示没有冗余特征。n_clusters_per_class参数指定了每个类别中有几个簇cluster这里设置为 1 表示每个类别只有一个簇。random_state参数指定了随机数生成器的种子可以用来确保生成的数据在不同的运行之间是相同的。
Ⅱ. 沃罗诺伊图Voronoi Diagram
0x00 通过 scipy.spatial 生成沃罗诺伊图
最简单的方法就是导入 scipy 库
from scipy.spatial import Voronoi, voronoi_plot_2d利用 scipy.spatial.Voronoi 函数生成并用 scipy.spatial.voronoi_plot_2d 绘制。
from scipy.spatial import Voronoi, voronoi_plot_2d
import matplotlib.pyplot as plt
points = np.random.rand(30, 2) # 生成随机点集
vor = Voronoi(points) # 使用Voronoi函数生成
voronoi_plot_2d(vor) # 绘制
plt.show()🚩 运行结果 (随机生成)

0x01 基于 make_classification 生成的数据生成沃罗诺伊图
在前置部分我们讲解了如何使用 make_classification 函数生成分类数据集。
现在我们利用刚才该函数生成的数据集通过 Voronoi 和 voronoi_plot_2d 生成沃罗诺伊图。
💬 代码演示基于 make_classification 创建的数据生成
import numpy as np
import cv2
import matplotlib .pyplot as plt
from sklearn.datasets import make_classification
from scipy.spatial import Voronoi, voronoi_plot_2d
X, y = make_classification (
n_features = 2,
n_samples = 200,
n_informative = 1,
n_redundant = 0,
n_clusters_per_class = 1,
random_state = 3
)
from scipy.spatial import Voronoi, voronoi_plot_2d
vor = Voronoi(X, qhull_options = 'Qc')
fig = voronoi_plot_2d(vor) # 使用 voronoi_plot_2d 生成图
plt.scatter (
X[:, 0], X[:, 1],
marker='o', c=y, s=45, edgecolor="k", linewidth=1 )
plt.show()🚩 运行结果

我们还可以尝试使用 annotate 函数给它们标上号
''' 标号 '''
for i in vor.point_region:
plt.annotate(str(i), (vor.points[i][0], vor.points[i][1]), size = 12)
0x02 沃罗诺伊图的应用
沃罗诺伊图最重要的条件是要利用垂直等分线将尽可能接近的两点分割成一定包含一个点的平面下面我介绍几种能够应用的场景
寻找最近的便利设施
地图 APP 大家一定使用过那种 "查看附近" 的功能就可以运用到沃罗诺伊图。
比如寻找离我所在地最近的医院、药店等便利设施以我在的地理上的位置为基准点每个点都可以认为是提供生活所需服务的场所的位置。
病毒传播

流行病学调查中可用于寻找密切接触者寻找第一个感染者和与他最近接触的人。
疾病感染地区分析
以饮用水泵为基准划分使用该饮用水泵的人的区域构成。如果某口井被污染了那么生活在那个领域的人很有可能都喝了被污染的水可利用这些原理追踪感染源。
……
Ⅲ. 实战练习Assignment
练习KNN & 沃罗诺伊图
![]() Google Colaboratory K80 GPUJupyter Notebookcolab
Google Colaboratory K80 GPUJupyter Notebookcolab
在 中保存整个 train set 时在创建沃罗诺伊图后编辑和推断近邻时请确保性能相同。
过程
- 创建由两个类组成的随机数据使用
sklearn库的make_classification函数 - 在
的
分类器中学习生成的数据 (Classifier1) 使用
sklearn库中的NeighborsClassifier函数。 - 使用数据生成全景图
- 对沃罗诺伊图执行 Nearest Neighbor editing
- 在
- 生成测试数据比较两个分类器的性能使用
sklearn库的accuratic_score函数

* 提供基础框架只需要在 TODO 位置填写代码即可完成第一部分和第二部分
💭 框架提供base code
- 第一部分
import numpy as np
import matplotlib .pyplot as plt
import cv2
from sklearn.datasets import make_classification
from scipy.spatial import Voronoi, voronoi_plot_2d
X, y = make_classification(
n_features=2, n_samples = 200, n_informative=1, n_redundant=0,
n_clusters_per_class=1, random_state=3)
vor = Voronoi(X, qhull_options = 'Qc')
# 检查图中的邻居如果只存在与当前类相同的类则删除当前节点
# 声明要标记是否丢弃的变量
mark = np.zeros(len(X))
# 收集与当前区域相邻的区域的索引信息
# voronoi.ridge_point存储相邻沃罗诺伊地区的索引。idx1idx2的形式
def get_neighbor_region_idx(curr_idx, voronoi):
'''
TODO 在此处添加代码
'''
neighbor_pair = []
for r in voronoi.ridge_points:
if curr_idx in r:
neighbor_pair.append(r)
return neighbor_pair
for i in range(len(X)):
# 收到与当前索引区域相邻的所有区域的信息
neighbor_pair = get_neighbor_region_idx(i, vor)
#
# print(neighbor_pair)
# Ex )
# [(0, 26), (0, 191), (0, 3), (0, 160), (0, 180), (0, 123), (0, 59)]
# [(1, 23), (1, 184), (1, 127), (1, 113), (1, 152), (1, 131)]
# [(2, 93), (2, 74), (2, 33), (2, 13), (2, 103)]
# ...
# 距离计算
shortest_dist = 99999999
shortest_idx = -1
# 检查所有相邻区域的类
isSame = True
for j in range(len(neighbor_pair)):
idx1 = neighbor_pair[j][0]
idx2 = neighbor_pair[j][1]
# 比较标签
if y[idx1]!=y[idx2]: # 如果标签不同
isSame = False
break
# 如果所有相邻地区都是同一类则标记。
# 标记完之后一次性扔掉
if isSame == True:
mark[i] = 1
# 新的点坐标数组
new_pt = np.where(mark<1) # 留下未标记的
## 绘图
pt_remain = X[new_pt]
labels_remain = y[new_pt]
plt.scatter(pt_remain[:, 0], pt_remain[:, 1], marker='o', c=labels_remain,
s=100, edgecolor="k", linewidth=2)
plt.xlim(-3,3)
plt.ylim(-3,3)
plt.show()
🚩 输出效果演示

- 第二部分
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
test_X, test_y = make_classification (
n_features=2, n_samples =30, n_informative=1,
n_redundant=0, n_clusters_per_class=1, random_state=3)
# 编辑前的数据学习
knn_classifier1 = KNeighborsClassifier(n_neighbors=1)
'''
TODO 在此处添加代码
'''
y_pred = knn_classifier1.predict(test_X)
print(f'Accuracy:', (accuracy_score(test_y, y_pred)))
# 编辑后的数据学习
knn_classifier2 = KNeighborsClassifier(n_neighbors=1)
'''
TODO 在此处添加代码
'''
print(f'Accuracy:', (accuracy_score(test_y, y_pred)))🚩 输出效果演示

参考答案
为了不影响练习如需查看答案请自行展开查看
- 第一部分
knn_classifier1.fit(test_X, test_y)- 第二部分
knn_classifier2.fit(test_X, test_y)
y_pred = knn_classifier2.predict(test_X)

📌 [ 笔者 ] 王亦优
📃 [ 更新 ] 2022.12.27
❌ [ 勘误 ] /* 暂无 */
📜 [ 声明 ] 由于作者水平有限本文有错误和不准确之处在所难免
本人也很想知道这些错误恳望读者批评指正| 📜 参考资料 Microsoft. MSDN(Microsoft Developer Network)[EB/OL]. []. . 百度百科[EB/OL]. []. https://baike.baidu.com/. |