

Hudi(6):Hudi集成Spark之spark-shell 方式
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
目录
0. 相关文章链接
1. 启动 spark-shell
- 启动命令
#针对Spark 3.2
spark-shell \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'- 设置表名基本路径和数据生成器不需要单独的建表。如果表不存在第一批写表将创建该表
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
val tableName = "hudi_trips_cow"
val basePath = "file:///tmp/hudi_trips_cow"
val dataGen = new DataGenerator
2. 插入数据
新增数据生成一些数据将其加载到DataFrame中然后将DataFrame写入Hudi表。
val inserts = convertToStringList(dataGen.generateInserts(10))
val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Overwrite).
save(basePath)
Modeoverwrite将覆盖重新创建表如果已存在。可以检查/tmp/hudi_trps_cow 路径下是否有数据生成。
数据文件的命名规则源码如下

3. 查询数据
3.1. 转换成DF
val tripsSnapshotDF = spark.
read.
format("hudi").
load(basePath)
tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")
注意该表有三级分区区域/国家/城市在0.9.0版本以前的hudi在load中的路径需要按照分区目录拼接"*"如load(basePath + "/*/*/*/*")当前版本不需要。
3.2. 查询
spark.sql("select fare, begin_lon, begin_lat, ts from hudi_trips_snapshot where fare > 20.0").show()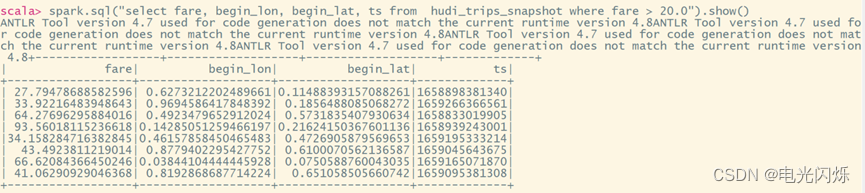
spark.sql("select _hoodie_commit_time, _hoodie_record_key, _hoodie_partition_path, rider, driver, fare from hudi_trips_snapshot").show()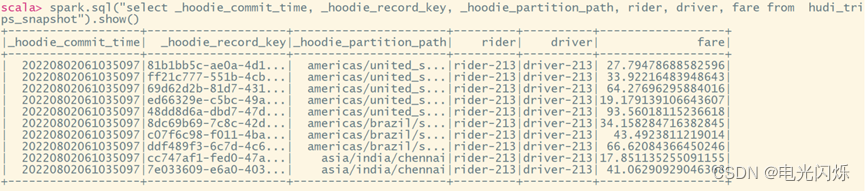
3.3. 时间旅行查询
Hudi从0.9.0开始就支持时间旅行查询。目前支持三种查询时间格式如下所示。
spark.read.
format("hudi").
option("as.of.instant", "20210728141108100").
load(basePath)
spark.read.
format("hudi").
option("as.of.instant", "2021-07-28 14:11:08.200").
load(basePath)
// 表示 "as.of.instant = 2021-07-28 00:00:00"
spark.read.
format("hudi").
option("as.of.instant", "2021-07-28").
load(basePath)
4. 更新数据
类似于插入新数据使用数据生成器生成新数据对历史数据进行更新。将数据加载到DataFrame中并将DataFrame写入Hudi表中。
val updates = convertToStringList(dataGen.generateUpdates(10))
val df = spark.read.json(spark.sparkContext.parallelize(updates, 2))
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Append).
save(basePath)
注意保存模式现在是Append。通常除非是第一次创建表否则请始终使用追加模式。现在再次查询数据将显示更新的行程数据。每个写操作都会生成一个用时间戳表示的新提交。查找以前提交中相同的_hoodie_record_keys在该表的_hoodie_commit_time、rider、driver字段中的变化。
查询更新后的数据要重新加载该hudi表
val tripsSnapshotDF = spark.
read.
format("hudi").
load(basePath)
tripsSnapshotDF1.createOrReplaceTempView("hudi_trips_snapshot")
spark.sql("select _hoodie_commit_time, _hoodie_record_key, _hoodie_partition_path, rider, driver, fare from hudi_trips_snapshot").show()
5. 增量查询
Hudi还提供了增量查询的方式可以获取从给定提交时间戳以来更改的数据流。需要指定增量查询的beginTime选择性指定endTime。如果我们希望在给定提交之后进行所有更改则不需要指定endTime这是常见的情况。
5.1. 重新加载数据
spark.
read.
format("hudi").
load(basePath).
createOrReplaceTempView("hudi_trips_snapshot")
5.2. 获取指定beginTime
val commits = spark.sql("select distinct(_hoodie_commit_time) as commitTime from hudi_trips_snapshot order by commitTime").map(k => k.getString(0)).take(50)
val beginTime = commits(commits.length - 2)
5.3. 创建增量查询的表
val tripsIncrementalDF = spark.read.format("hudi").
option(QUERY_TYPE_OPT_KEY, QUERY_TYPE_INCREMENTAL_OPT_VAL).
option(BEGIN_INSTANTTIME_OPT_KEY, beginTime).
load(basePath)
tripsIncrementalDF.createOrReplaceTempView("hudi_trips_incremental")
5.4. 查询增量表
spark.sql("select `_hoodie_commit_time`, fare, begin_lon, begin_lat, ts from hudi_trips_incremental where fare > 20.0").show()这将过滤出beginTime之后提交且fare>20的数据。
利用增量查询我们能在批处理数据上创建streaming pipelines。
6. 指定时间点查询
查询特定时间点的数据可以将endTime指向特定时间beginTime指向000表示最早提交时间
- 指定beginTime和endTime
val beginTime = "000"
val endTime = commits(commits.length - 2)
- 根据指定时间创建表
val tripsPointInTimeDF = spark.read.format("hudi").
option(QUERY_TYPE_OPT_KEY, QUERY_TYPE_INCREMENTAL_OPT_VAL).
option(BEGIN_INSTANTTIME_OPT_KEY, beginTime).
option(END_INSTANTTIME_OPT_KEY, endTime).
load(basePath)
tripsPointInTimeDF.createOrReplaceTempView("hudi_trips_point_in_time")
- 查询
spark.sql("select `_hoodie_commit_time`, fare, begin_lon, begin_lat, ts from hudi_trips_point_in_time where fare > 20.0").show()7. 删除数据
根据传入的HoodieKeys来删除uuid + partitionpath只有append模式才支持删除功能。
- 获取总行数
spark.sql("select uuid, partitionpath from hudi_trips_snapshot").count()- 取其中2条用来删除
val ds = spark.sql("select uuid, partitionpath from hudi_trips_snapshot").limit(2)- 将待删除的2条数据构建DF
val deletes = dataGen.generateDeletes(ds.collectAsList())
val df = spark.read.json(spark.sparkContext.parallelize(deletes, 2))
- 执行删除
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(OPERATION_OPT_KEY,"delete").
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Append).
save(basePath)
- 统计删除数据后的行数验证删除是否成功
val roAfterDeleteViewDF = spark.
read.
format("hudi").
load(basePath)
roAfterDeleteViewDF.registerTempTable("hudi_trips_snapshot")
// 返回的总行数应该比原来少2行
spark.sql("select uuid, partitionpath from hudi_trips_snapshot").count()
8. 覆盖数据
对于表或分区来说如果大部分记录在每个周期都发生变化那么做upsert或merge的效率就很低。我们希望类似hive的 "insert overwrite "操作以忽略现有数据只用提供的新数据创建一个提交。
也可以用于某些操作任务如修复指定的问题分区。我们可以用源文件中的记录对该分区进行'插入覆盖'。对于某些数据源来说这比还原和重放要快得多。
Insert overwrite操作可能比批量ETL作业的upsert更快批量ETL作业是每一批次都要重新计算整个目标分区包括索引、预组合和其他重分区步骤。
- 查看当前表的key
spark.
read.format("hudi").
load(basePath).
select("uuid","partitionpath").
sort("partitionpath","uuid").
show(100, false)
- 生成一些新的行程数据
val inserts = convertToStringList(dataGen.generateInserts(10))
val df = spark.
read.json(spark.sparkContext.parallelize(inserts, 2)).
filter("partitionpath = 'americas/united_states/san_francisco'")
- 覆盖指定分区
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(OPERATION.key(),"insert_overwrite").
option(PRECOMBINE_FIELD.key(), "ts").
option(RECORDKEY_FIELD.key(), "uuid").
option(PARTITIONPATH_FIELD.key(), "partitionpath").
option(TBL_NAME.key(), tableName).
mode(Append).
save(basePath)
- 查询覆盖后的key发生了变化
spark.
read.format("hudi").
load(basePath).
select("uuid","partitionpath").
sort("partitionpath","uuid").
show(100, false)
注其他Hudi相关文章链接由此进 -> Hudi文章汇总