

MySQL:关于ID的选择问题,自增/UUID/雪花ID_mysql uuid
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
𝑰’𝒎 𝒉𝒉𝒈, 𝑰 𝒂𝒎 𝒂 𝒈𝒓𝒂𝒅𝒖𝒂𝒕𝒆 𝒔𝒕𝒖𝒅𝒆𝒏𝒕 𝒇𝒓𝒐𝒎 𝑵𝒂𝒏𝒋𝒊𝒏𝒈, 𝑪𝒉𝒊𝒏𝒂.
- 🏫 𝑺𝒉𝒄𝒐𝒐𝒍: 𝑯𝒐𝒉𝒂𝒊 𝑼𝒏𝒊𝒗𝒆𝒓𝒔𝒊𝒕𝒚
- 🌱 𝑳𝒆𝒂𝒓𝒏𝒊𝒏𝒈: 𝑰’𝒎 𝒄𝒖𝒓𝒓𝒆𝒏𝒕𝒍𝒚 𝒍𝒆𝒂𝒓𝒏𝒊𝒏𝒈 𝒅𝒆𝒔𝒊𝒈𝒏 𝒑𝒂𝒕𝒕𝒆𝒓𝒏, 𝑳𝒆𝒆𝒕𝒄𝒐𝒅𝒆, 𝒅𝒊𝒔𝒕𝒓𝒊𝒃𝒖𝒕𝒆𝒅 𝒔𝒚𝒔𝒕𝒆𝒎, 𝒎𝒊𝒅𝒅𝒍𝒆𝒘𝒂𝒓𝒆 𝒂𝒏𝒅 𝒔𝒐 𝒐𝒏.
- 💓 𝑯𝒐𝒘 𝒕𝒐 𝒓𝒆𝒂𝒄𝒉 𝒎𝒆𝑽𝑿
- 📚 𝑴𝒚 𝒃𝒍𝒐𝒈: 𝒉𝒕𝒕𝒑𝒔://𝒉𝒉𝒈𝒚𝒚𝒅𝒔.𝒃𝒍𝒐𝒈.𝒄𝒔𝒅𝒏.𝒏𝒆𝒕/
- 💼 𝑷𝒓𝒐𝒇𝒆𝒔𝒔𝒊𝒐𝒏𝒂𝒍 𝒔𝒌𝒊𝒍𝒍𝒔𝒎𝒚 𝒅𝒓𝒆𝒂𝒎

{kind=link}
1 理论
1.1 从存储大小上
- UUID
System.out.println(UUID.randomUUID().toString().getBytes(StandardCharsets.UTF_8).length);
36个字节也就是36*8个bit去掉4个’-'也就是32个字节
-
雪花算法以百度的UidGenerator为例

64bit的long也就是说8个字节。 -
自增ID可以是int也可以是bigint也就是long。4字节或者8字节。
1.2 数据结构-B+树索引
根据上一个博客MySQL关于innodb里面的聚集索引组成结构。B+树。我们知道了聚集索引的索引结构索引是B+树的结构像单调递增的雪花id和自增id都是递增的那么他们就会一直操作数据页的最后一页一个记录一个记录往里面添加就行添加完了再在一个新的页上面去添加那么有页的分裂过程吗没有反看UUIDuuid你知道该插在哪吗你不知道因为它是随机的如果在一个满的页里插入一个记录那么就会导致页的分裂如果碰巧B+树的节点也满了B+树不得进行调整来维持B+树的特性。
1.3 键值比较性能
数字的比较的性能要远远高过字符串的比较那么多字符串进行比较每插入一个记录都是从上向下进行比一次的过程这个不用多说两个速度差很多。
1.4 IO
CPU是不直接读磁盘的得读进内存当中那么CPU是一页一页将磁盘中 的数据读到内存中去的根据局部性原理cpu倾向把连续的页预读进内存中去UUID的页是随机的零散的那么就势必需要读更多的页而自增ID和雪花都是局部页上面进行的操作。
1.5 并发程度
UUID和雪花都支持并发的但是auto_increment自增懂的都懂是阻塞的一个一个排队用。
1.6 多库多表问题
自增的id属于表里面唯一要是几个表合并那肯定是没法合并的起冲突了呀在业务上你有多少数据可以从id上判断出来了。
1.7 生成的位置
uuid和雪花均由客户端生成不占用MySQL资源而自增就需要MySQL自己去做。
2 实验
测试数据 一共6163561条真实数据非人造
CPU i7 12700F
每1000条数据插入一次批处理的不是一条一条插10001000插
插入工具mybatis-plusjdbc连接已打开rewrite
总左边是ms,横坐标是每1000条数据
数据插入时间图如下
自增

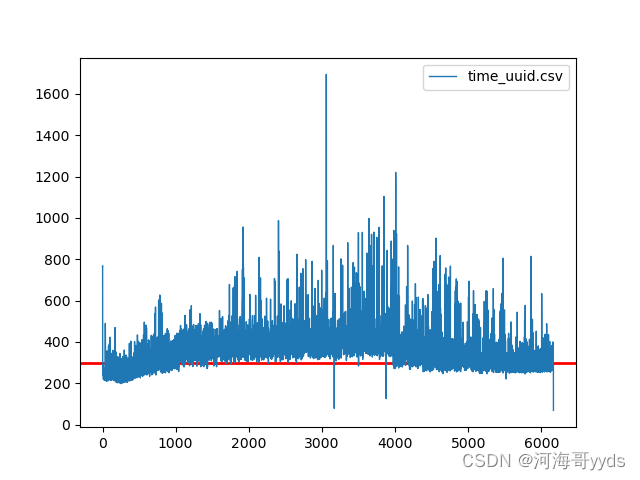
UUID:
雪花id
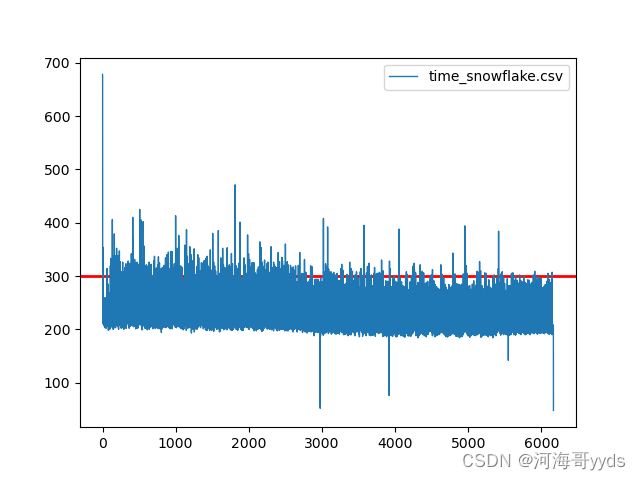
从图上看来自增和雪花id性能基本上一样uuid就比较差了。
总结
这么看来雪花算法好像是比较全面的但是有一个最大的问题就是时钟回拨的问题。百度的生成器里面已经解决了这个问题。