

今年,我只赚了一点点
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
大家好我是 Jack。
之前一直有小伙伴问我有没有免费的股票信息查询的 API 接口
我看了一圈很多免费的 API 接口都年久失修失效了。
那好吧咱自己写一个。
想要玩量化交易第一步那得有稳定的股票数据来源。
然后再谈什么量化策略怎么选股、何时买股。
怎么稳定的获取数据呢
只能是抄起我的老板行写个网络爬虫自动抓取数据。
玩股票、玩基金的应该多多少听过一款股票交流 APP 雪球。
这里面的数据很全就它了
前方提醒使用网络爬虫请控制好访问频率。
在雪球上想要获得各种股票信息那需要携带身份信息也就是要有 Cookie。
没有 Cookie很多信息是获取不到的。
2017 年的时候我就写过关于 Cookie 的文章。
一些基础知识忘记的小伙伴可以重温下我这个系列的文章。
想要获取 Cookie那就需要进行模拟登录。
模拟登录 - 准备篇
模拟登录顾名思义就是模拟人类的行为登录这个网站。
登录之后我们就可以用保存身份信息的 Cookie获取我们想要的各种数据股票信息、基金信息等。
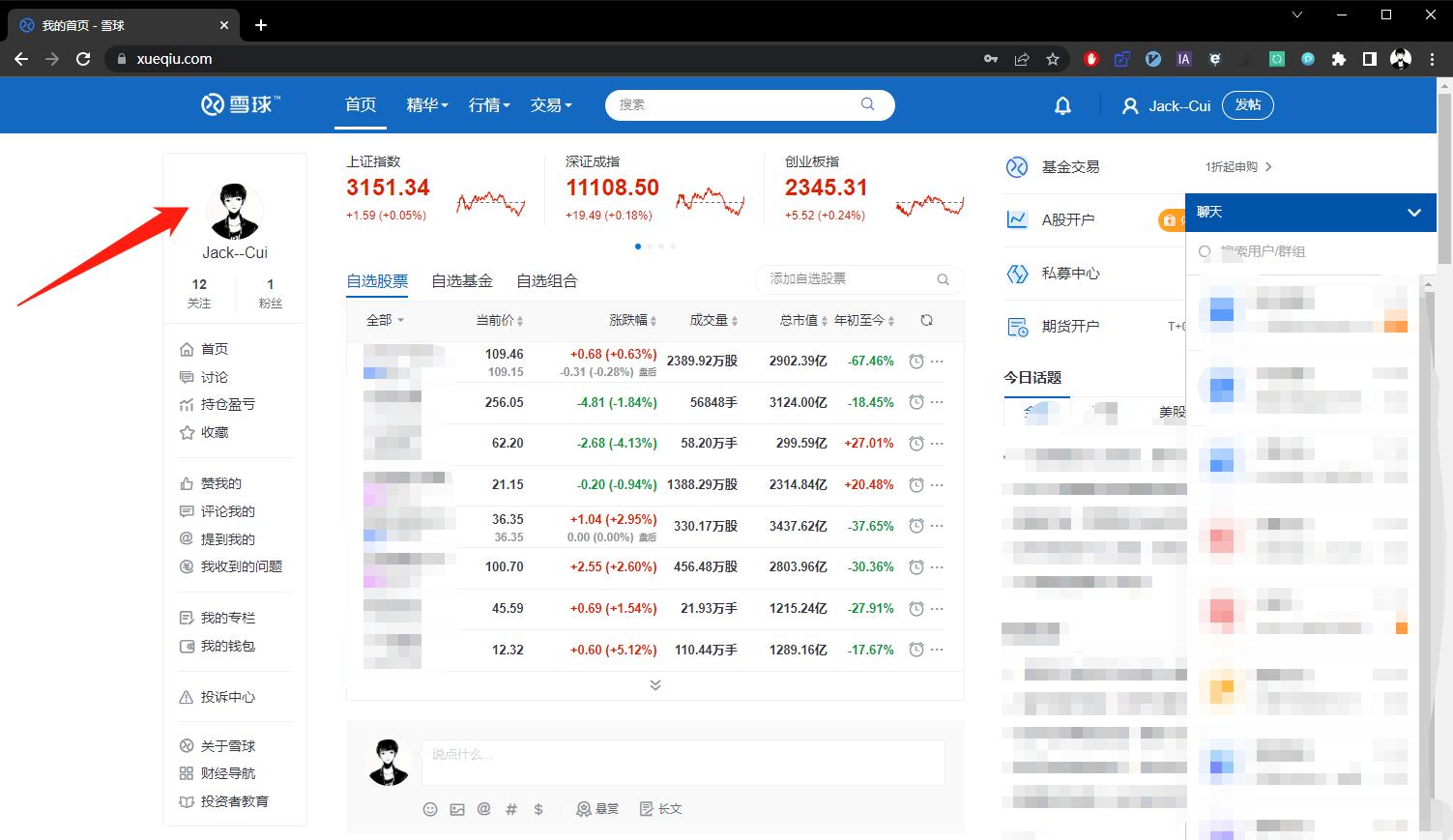
我们先手动登录体验一下整个登录流程。
手动登录
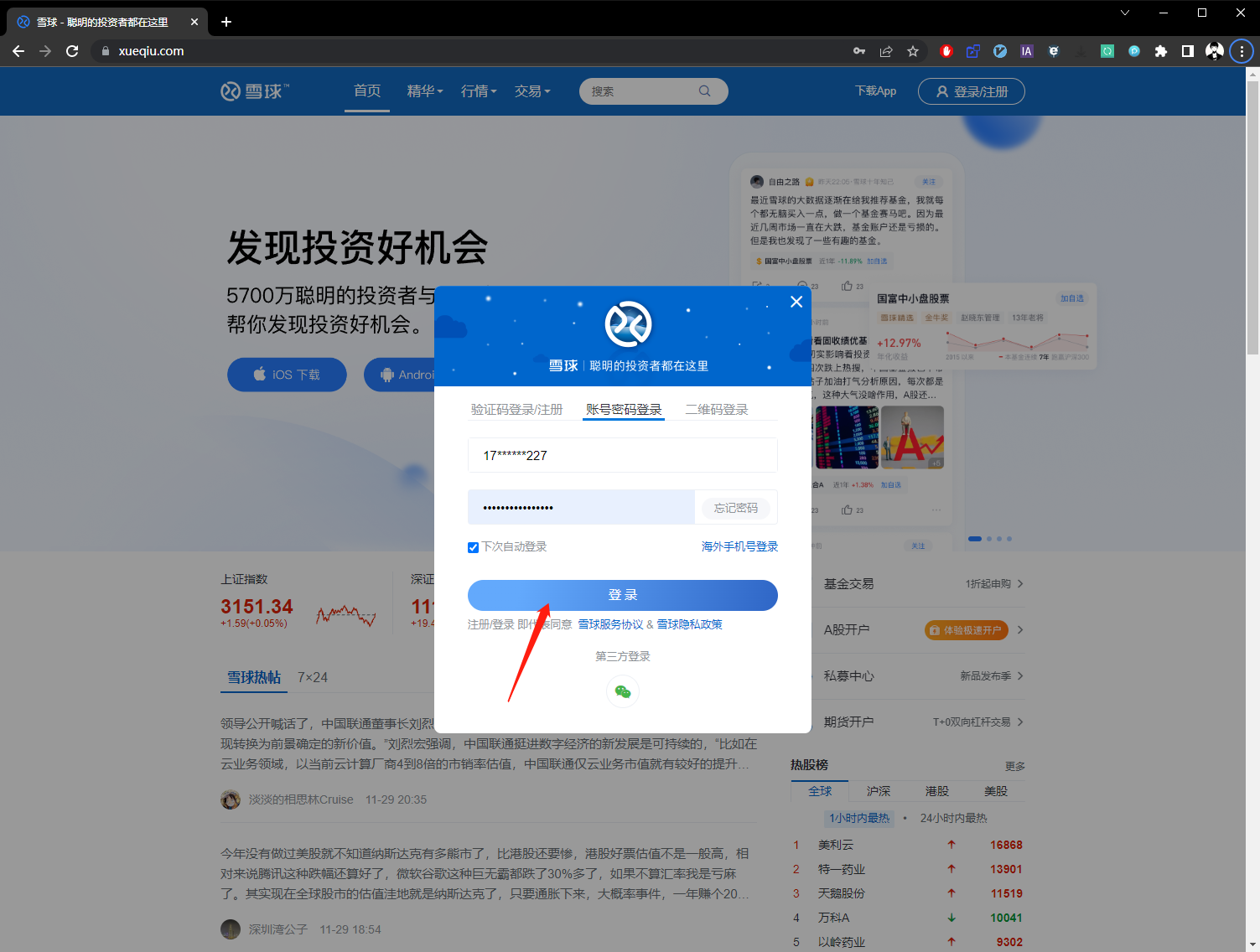
第一步点击登录按钮。

第二步输入帐号和密码并点击登录。
第三步解锁滑块。
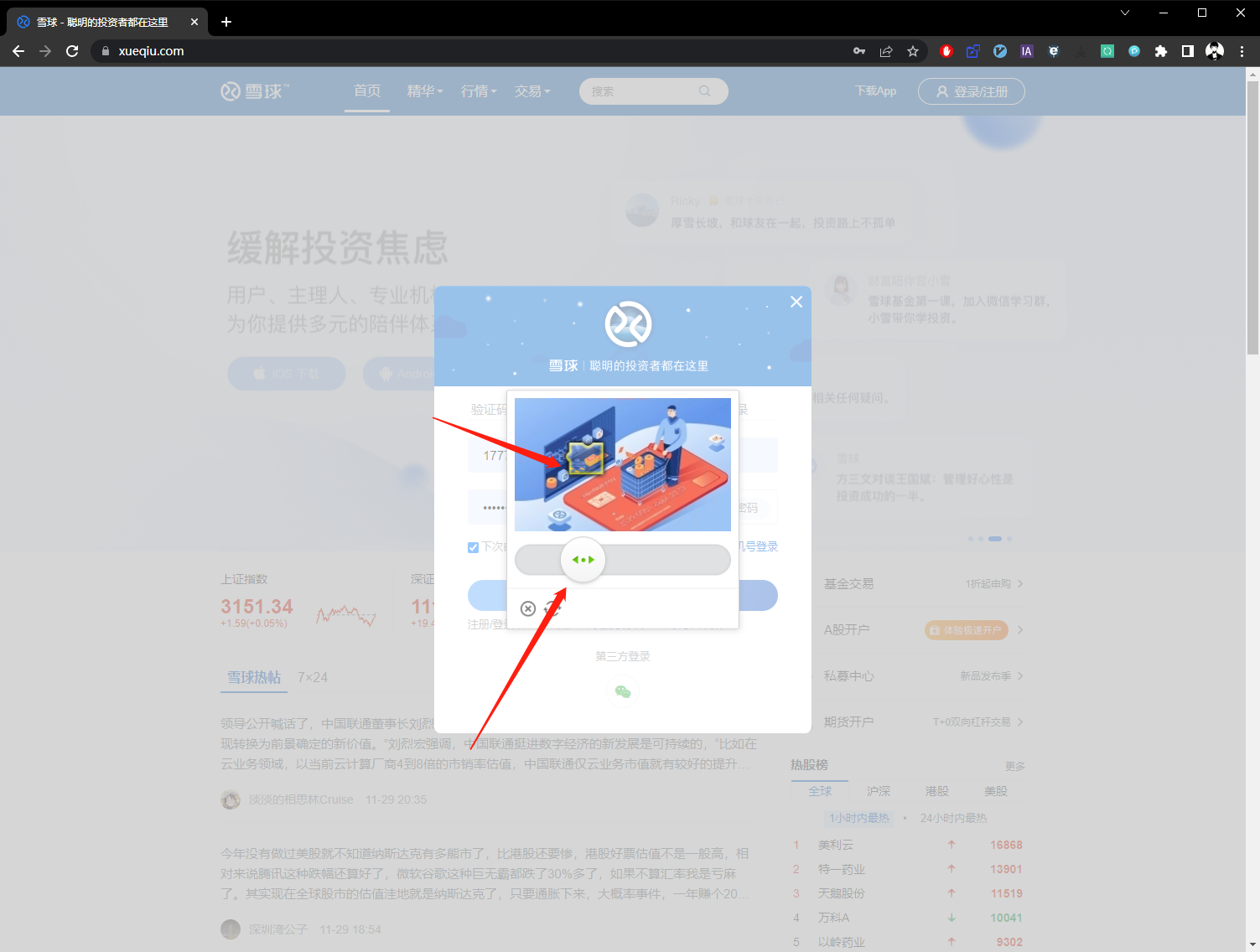
第四步登录成功。
模拟登录
接下来就是需要写个代码让代码替我们完成上述操作。
这里我使用 Selenium它是一款自动化测试工具。
不过说实话Selenium 这东西挺老了。
现在有不少更好的工具不过对于模拟登录的知识储备我还停留在 2017 年也只会用它了。
有更好更好的方法的话欢迎小伙伴们提交 PR。
不过好在 Selenium 虽然老了点但还能勉强胜任获取 Cookie 这项工作的。
Selenium 不会的小伙伴可以看我从前的教程
https://jackcui.blog.csdn.net/article/details/72331737
想要使用 Selenium首先需要下载浏览器驱动这里以 Chrome 浏览器为例。
打开 Chrome 浏览器查看 Chrome 版本号。
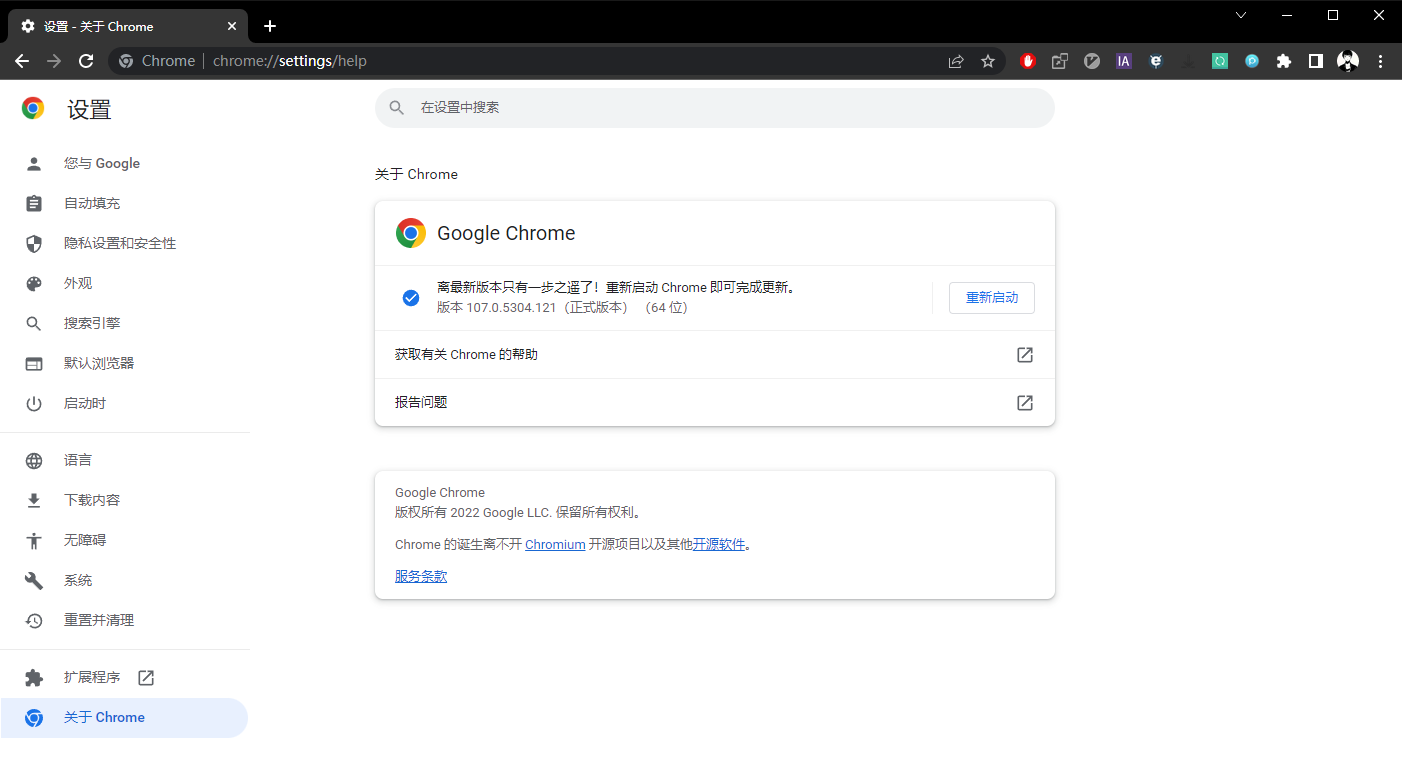
然后根据这个版本号下载相同大版本的驱动。
http://chromedriver.storage.googleapis.com/index.html

根据自己的操作系统选择对应的版本。
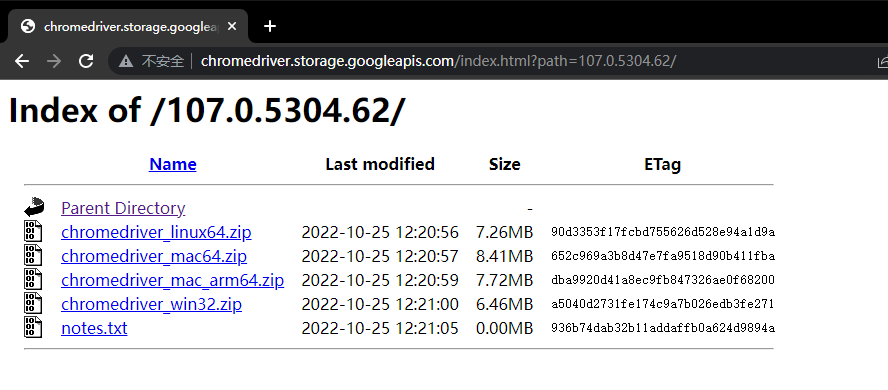
我的是 Windows 电脑选择 Win32 的版本。
下载好后解压备用。
最后安装 Selenium 第三方依赖库。
python -m pip install selenium==3.4 --user
注意需要安装 3.4 的版本Selenium 的新版本改动较多用我的代码会存在接口不兼容的情况。
模拟登录 - 实战篇
我们先睹为快看下让代码自动登录雪球的效果
https://cuijiahua.com/wp-content/uploads/2022/12/1.mp4
PS录屏时间 12.2由于大家都知道的原因页面为黑白
其实模拟登录的思路很简单就是根据审查元素找到各个元素的位置。
比如登录按钮右键审查元素然后选择 Copy Xpath。

就能拷贝路径地址。
使用这种方法找到帐号输入框、密码输入框的位置然后点击登录即可。
这里的难点在于验证码。
不过好在GEETEST 验证码的破解我还是有些经验的17 年的时候就写过相关内容。
很多代码直接复用即可。
整体思路就是
-
使用Selenium打开页面。
-
匹配到输入框输入账号密码点击登录。
-
读取验证码图片并做缺口识别。
-
根据缺口位置计算滑动距离。
-
根据滑动距离拖拽滑块到需要匹配的位置。
直接放代码
from selenium import webdriver
from selenium.webdriver import ActionChains
from io import BytesIO
import json
import base64
import time
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from time import sleep
from PIL import Image
from selenium import webdriver
# 账号
USERNAME = '***'
# 密码
PASSWORD = '***'
BORDER = 6
class Login(object):
def __init__(self):
self.url = 'https://xueqiu.com/'
opt = webdriver.ChromeOptions()
opt.add_experimental_option('w3c', False)
self.browser = webdriver.Chrome("chromedriver.exe", chrome_options=opt)
self.browser.maximize_window()#第一处修复设置浏览器全屏
self.username = USERNAME
self.password = PASSWORD
self.wait = WebDriverWait(self.browser, 20)
def __del__(self):
print("close")
def open(self):
self.browser.get(self.url)
ele = self.browser.find_element_by_xpath('//*[@id="app"]/nav/div[1]/div[2]/div/div')#第二处修复改xpath
ele.click()
username = self.wait.until(EC.presence_of_element_located((By.XPATH, '//input[@name="username"]')))
pwd = self.wait.until(EC.presence_of_element_located((By.XPATH, '//input[@name="password"]')))
username.send_keys(self.username)
time.sleep(2)
pwd.send_keys(self.password)
# 获取验证码按钮
def get_yzm_button(self):
button = self.wait.until(EC.presence_of_element_located((By.XPATH, '/html/body/div[2]/div[1]/div/div/div/div[2]/div[2]/div[2]')))#第三处修复改xpath
return button
# 获取验证码图片对象
def get_img_element(self):
element = self.wait.until(EC.presence_of_element_located((By.XPATH, '//cavas[@name="geetest_canvas_bg geetest_absolute"]')))
return element
def get_position(self):
# 获取验证码位置
element = self.get_img_element()
sleep(2)
location = element.location
size = element.size
top, bottom, left, right = location['y'], location['y'] + size['height'], location['x'], location['x'] + size[
'width']
return left, top, right, bottom
def get_geetest_image(self):
"""
获取验证码图片
:return: 图片对象
"""
'''
<canvas class="geetest_canvas_bg geetest_absolute" height="160" width="260"></canvas>
'''
# 带阴影的图片
# im = self.wait.until(EC.presence_of_element_located((By.XPATH, '/html/body/div[4]/div[2]/div[6]/div/div[1]/div[1]/div/a/div[1]/div/canvas[1]')))
im = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.geetest_canvas_bg')))
time.sleep(2)
im.screenshot('captcha.png')
# 执行 JS 代码并拿到图片 base64 数据
JS = 'return document.getElementsByClassName("geetest_canvas_fullbg")[0].toDataURL("image/png");' # 不带阴影的完整图片
im_info = self.browser.execute_script(JS) # 执行js文件得到带图片信息的图片数据
# 拿到base64编码的图片信息
im_base64 = im_info.split(',')[1]
# 转为bytes类型
captcha1 = base64.b64decode(im_base64)
# 将图片保存在本地
with open('captcha1.png', 'wb') as f:
f.write(captcha1)
JS = 'return document.getElementsByClassName("geetest_canvas_bg")[0].toDataURL("image/png");'
# 执行 JS 代码并拿到图片 base64 数据ng # 带阴影的图片
im_info = self.browser.execute_script(JS) # 执行js文件得到带图片信息的图片数据
# 拿到base64编码的图片信息
im_base64 = im_info.split(',')[1]
# 转为bytes类型
captcha2 = base64.b64decode(im_base64)
# 将图片保存在本地
with open('captcha2.png', 'wb') as f:
f.write(captcha2)
captcha1 = Image.open('captcha1.png')
captcha2 = Image.open('captcha2.png')
return captcha1, captcha2
# 获取网页截图
def get_screen_shot(self):
screen_shot = self.browser.get_screenshot_as_png()
screen_shot = Image.open(BytesIO(screen_shot))
return screen_shot
def get_yzm_img(self, name='captcha.png'):
# 获取验证码图片
left, top, right, bottom = self.get_position()
print('验证码位置', top, bottom, left, right)
screen_shot = self.get_screen_shot()
captcha = screen_shot.crop((left, top, right, bottom))
captcha.save(name)
return captcha
def get_slider(self):
# 获取滑块
# :return: 滑块对象
slider = self.wait.until(EC.element_to_be_clickable((By.CLASS_NAME, 'geetest_slider_track')))
return slider
def get_gap(self, image1, image2):
"""
获取缺口偏移量
:param image1: 不带缺口图片
:param image2: 带缺口图片
:return:
"""
left = 62
for i in range(left, image1.size[0]):
for j in range(image1.size[1]):
if not self.is_pixel_equal(image1, image2, i, j):
left = i
return left
# return left
def is_pixel_equal(self, image1, image2, x, y):
"""
判断两个像素是否相同
:param image1: 图片1
:param image2: 图片2
:param x: 位置x
:param y: 位置y
:return: 像素是否相同
"""
# 取两个图片的像素点
pixel1 = image1.load()[x, y]
pixel2 = image2.load()[x, y]
threshold = 60
if abs(pixel1[0] - pixel2[0]) < threshold and abs(pixel1[1] - pixel2[1]) < threshold and abs(
pixel1[2] - pixel2[2]) < threshold:
return True
else:
return False
def get_track(self, distance):
"""
根据偏移量获取移动轨迹
:param distance: 偏移量
:return: 移动轨迹
"""
# 初速度
v = 0
# 单位时间为0.2s来统计轨迹轨迹即0.2内的位移
t = 0.3
# 位移/轨迹列表列表内的一个元素代表0.2s的位移
tracks = []
# 当前的位移
current = 5
# 到达mid值开始减速
mid = distance * 3 / 5
while current < distance:
if current < mid:
# 加速度越小单位时间的位移越小,模拟的轨迹就越多越详细
a = 2
else:
a = -3
# 初速度
v0 = v
# 0.2秒时间内的位移
s = v0 * t + 0.4 * a * (t ** 2)
# 当前的位置
current += s
# 添加到轨迹列表
tracks.append(round(s))
# 速度已经达到v,该速度作为下次的初速度
v = v0 + a * t
return tracks
def move_to_gap(self, slider, track):
"""
拖动滑块到缺口处
:param slider: 滑块
:param track: 轨迹
:return:
"""
ActionChains(self.browser).click_and_hold(slider).perform()
for x in track:
ActionChains(self.browser).move_by_offset(xoffset=x, yoffset=0).perform()
time.sleep(0.5)
ActionChains(self.browser).release().perform()
def shake_mouse(self):
"""
模拟人手释放鼠标抖动
:return: None
"""
ActionChains(self.browser).move_by_offset(xoffset=-2, yoffset=0).perform()
ActionChains(self.browser).move_by_offset(xoffset=2, yoffset=0).perform()
def operate_slider(self, track):
'''
拖动滑块
'''
# 获取拖动按钮
back_tracks = [-1,-1, -1, -1]
slider_bt = self.browser.find_element_by_xpath('//div[@class="geetest_slider_button"]')
# 点击拖动验证码的按钮不放
ActionChains(self.browser).click_and_hold(slider_bt).perform()
# 按正向轨迹移动
for i in track:
ActionChains(self.browser).move_by_offset(xoffset=i, yoffset=0).perform()
time.sleep(1)
ActionChains(self.browser).release().perform()
def get_cookies(self):
try:
cookie_list = self.browser.get_cookies()
cookie_dict = {i['name']: i['value'] for i in cookie_list}
with open('xueqiu_cookies', 'w', encoding='utf8')as f:
cookie_dict = json.dumps(cookie_dict)
f.write(cookie_dict)
return cookie_dict
except:
print("cookie 获取失败")
return None
# 读取cookie
def return_cookie(self):
cookies = ''
with open('xueqiu_cookies', 'r')as f:
cookie = f.read()[1:-1]
cookie = cookie.split(', ')
for i in cookie:
cook = i.split(': ')
cookies += cook[0][1:-1] + '=' + cook[1][1:-1] + ';'
return cookies
def run(self):
# 破解入口
self.open(), sleep(3)
self.get_yzm_button().click(), sleep(2)# 点击验证按钮
# 点按呼出缺口
slider = self.get_slider()
# slider.click()
# 获取带缺口的验证码图片
image1, image2 = self.get_geetest_image()
gap = self.get_gap(image1, image2)
print('缺口位置', gap)
track = self.get_track(gap)
print('滑动轨迹', track)
self.operate_slider(track)
# 判定是否成功
time.sleep(8)
try:
elem = self.wait.until(
EC.text_to_be_present_in_element((By.CLASS_NAME, 'nav__btn--longtext'), '发帖'))
if elem:
cookie = self.get_cookies()
else:
print("get cookies errors")
except Exception as e:
print(e, 'fail! ')
time.sleep(3)
self.run()
finally:
self.browser.quit()
if __name__ == '__main__':
crack = Login()
crack.run()
代码我也上传到 Github 上了代码的后续更新维护会放在这里建议 Star 收藏下。
https://github.com/Jack-Cherish/quantitative
数据获取
等待模拟登录完成后会保存一个名为 xueqiu_cookies 的文件。
这里保存的是帐号的 Cookie使用这个 Cookie 就能获取雪球的数据了。
比如获取一下股票实时行情和现金流量表就可以这样写
#-*- coding:utf-8 -*-
import requests
import json
def fetch(url, xq_a_token):
headers = {'Host': 'stock.xueqiu.com',
'Accept': 'application/json',
'Cookie': 'xq_a_token={};'.format(xq_a_token),
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36',
'Accept-Language': 'zh-Hans-CN;q=1, ja-JP;q=0.9',
'Accept-Encoding': 'br, gzip, deflate',
'Connection': 'keep-alive'}
response = requests.get(url, headers = headers)
if response.status_code != 200:
raise Exception(response.content)
return json.loads(response.content)
if __name__ == '__main__':
# 获取股票 SH600000 实时行情
url = "http://stock.xueqiu.com/v5/stock/quote.json?extend=detail&symbol=SH600000&count=10"
with open("xueqiu_cookies", "r") as f:
cookies_info = json.load(f)
res = fetch(url, cookies_info['xq_a_token'])
print(res)
# 获取股票 SH600000 现金流量表
url = "http://stock.xueqiu.com/v5/stock/finance/cn/cash_flow.json?symbol=SH600000&count=10"
with open("xueqiu_cookies", "r") as f:
cookies_info = json.load(f)
res = fetch(url, cookies_info['xq_a_token'])
print(res)
运行结果
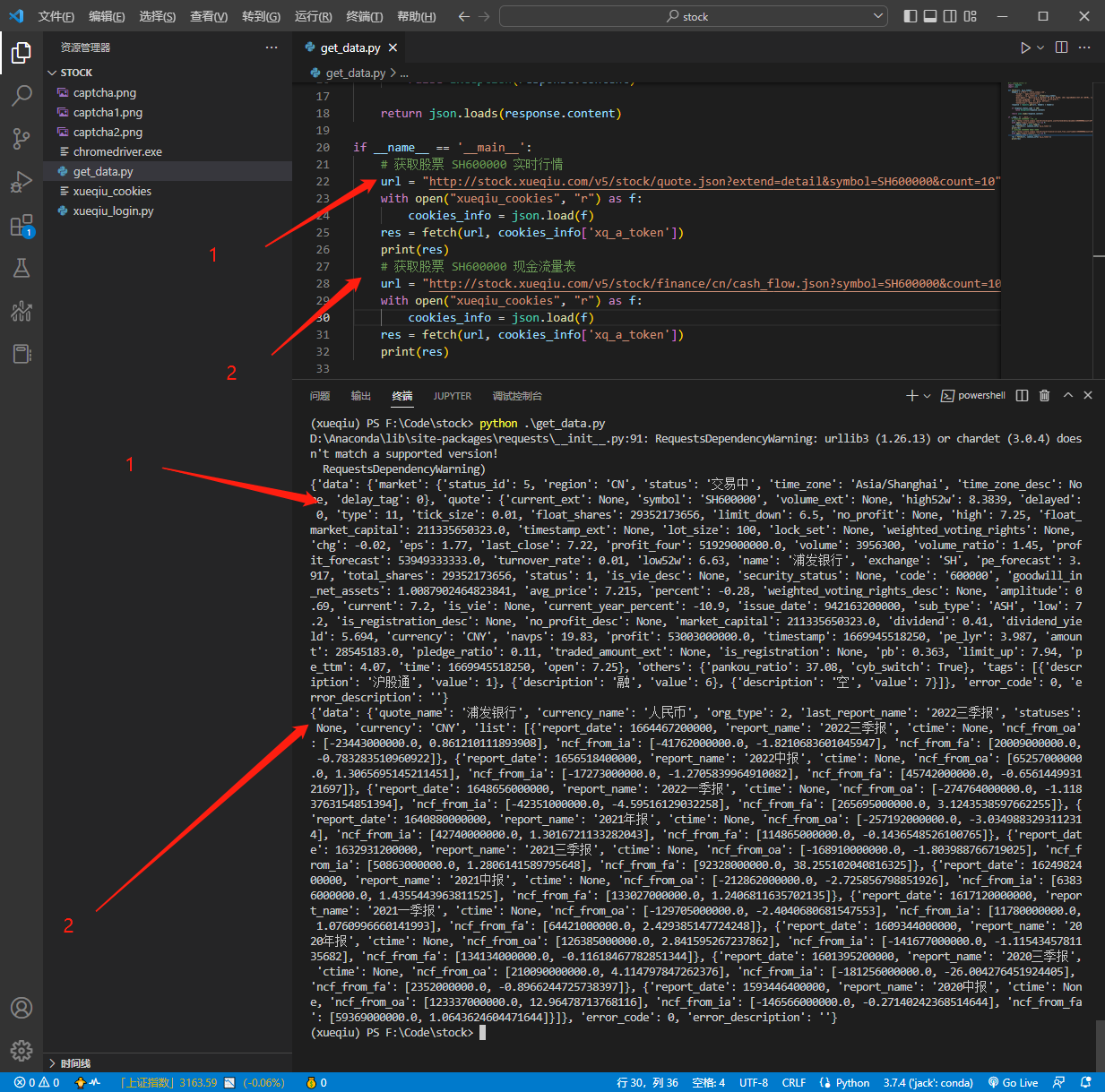
有了 Cookie很多接口数据都能获取实时行情、实时分笔、业绩预告、机构评级、资金流向趋势、资金流向历史、资金成交分布、大宗交易、融资融券、业绩指标、利润表、资产负债表、现金流量表、主营业务构成、F10 十大股东、F10 主要指标等等。
这些数据都能获取。
絮叨
篇幅有限今天就是带大家小小实战下。
后续我会完善各个常用查询接口方便大家获取各类数据用于量化分析。
万事开头难先弄好数据再看量化策略~
如果喜欢这类的内容记得点赞喜欢的人多的话我会快速加更的~
最后必须提醒一下各位
获取数据请温柔请勿高并发获取且用且珍惜。
对了还有不少小伙伴问我我的量化策略收益如何。
去年的五万元实验最后浮盈不到 10%清仓之后就换新的策略实验了。
6月份的时候又用上了新策略新的策略一直跑到今年 10 月份也就这样

实验没放多少钱随便玩玩你觉得这点收益如何
好了今天就聊这么多吧我是 Jack我们下期见~