

解救Kubernetes混乱:Descheduler快速实现资源平衡-CSDN博客
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
By default, Kubernetes doesn’t recompute and rebalance workloads. You could have a cluster with fewer overutilized nodes and others with a handful of pods How can you fix this?
关注【云原生百宝箱】公众号快速掌握云原生
默认情况下Kubernetes不会重新计算和重新平衡工作负载。
你可能会遇到一些节点过度利用的集群而其他节点只有少量的Pod。
你可以如何解决这个问题呢
1只有一个节点的集群
Let’s consider a cluster with a single node that can host 2 Pods You maxed out all available resources so you can scale the cluster to have a second node and spread the load
让我们考虑一个只有一个节点可以承载2个Pod的集群。
你已经使用了所有可用资源所以你可以扩展集群增加一个第二个节点来分担负载。

2准备第二个节点
You provision a second node; what happens next? Does Kubernetes notice that there’s a space for your Pod? Does it move the second Pod and rebalance the cluster?
Unfortunately, it does not. But why?
你准备了第二个节点接下来会发生什么Kubernetes会注意到有一个Pod的空间吗它会移动第二个Pod并重新平衡集群吗
不幸的是它不会这样做。但为什么呢

3部署Deployment
When you define a Deployment, you specify:
- The template for the Pod
- The number of copies (replicas)
当你定义一个部署Deployment时你需要指定
- Pod的模板template
- 副本数量replicas
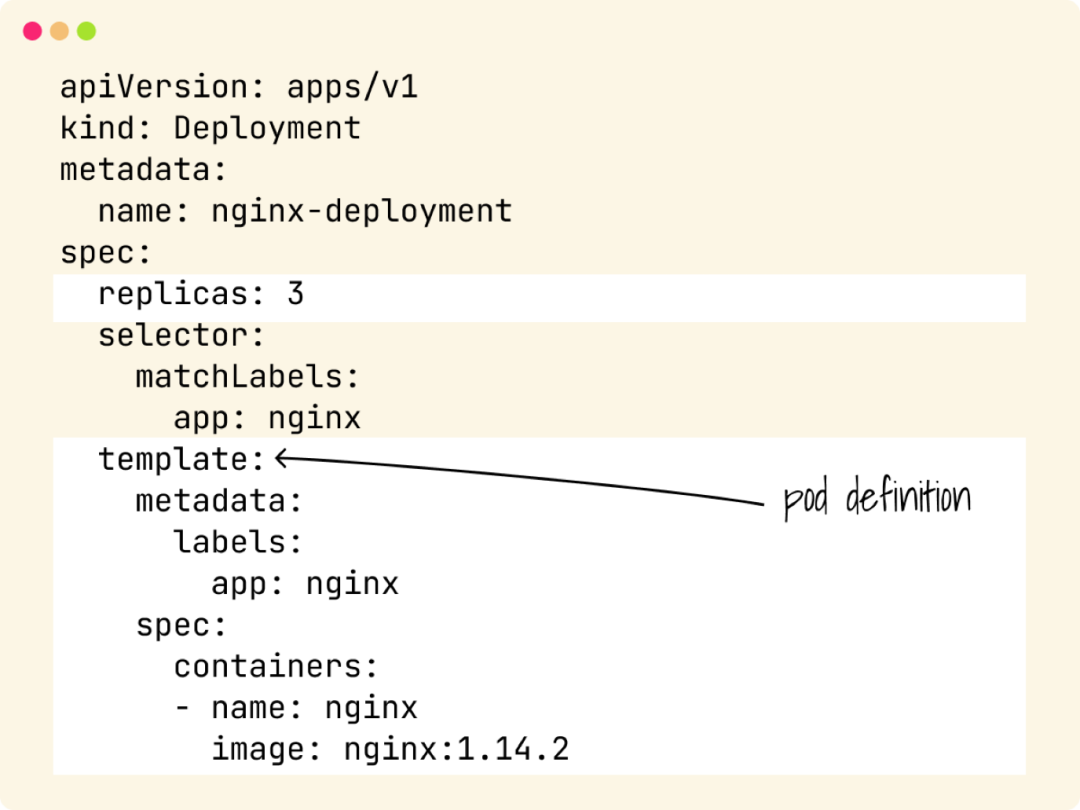
4Kubernetes不会自动重新平衡你的Pod
But nowhere in that file, you said you want one replica for each node! The ReplicaSet counts 2 Pods, and that matches the desired state Kubernetes won’t take any further action
但是在文件中你并没有指定每个节点一个副本ReplicaSet 计数为2个Pod这与期望的状态相匹配Kubernetes 不会采取任何进一步的动作。

5Descheduler定期扫描集群
In other words, Kubernetes does not rebalance your pods automatically But you can fix this with the descheduler The Descheduler scans your cluster at regular intervals, and if it finds a node that is more utilized than others, it deletes a pod in that node
换句话说Kubernetes不会自动重新平衡你的Pod。但是你可以通过使用Descheduler来解决这个问题。
Descheduler会定期扫描你的集群如果发现某个节点的利用率高于其他节点它会删除该节点上的一个Pod。

6一个Pod被删除
What happens when a Pod is deleted? The ReplicaSet will create a new Pod, and the scheduler will likely place it in a less utilized node
当一个Pod被删除时会发生什么
ReplicaSet会创建一个新的Pod调度器scheduler很可能会将其放置在一个利用率较低的节点上。

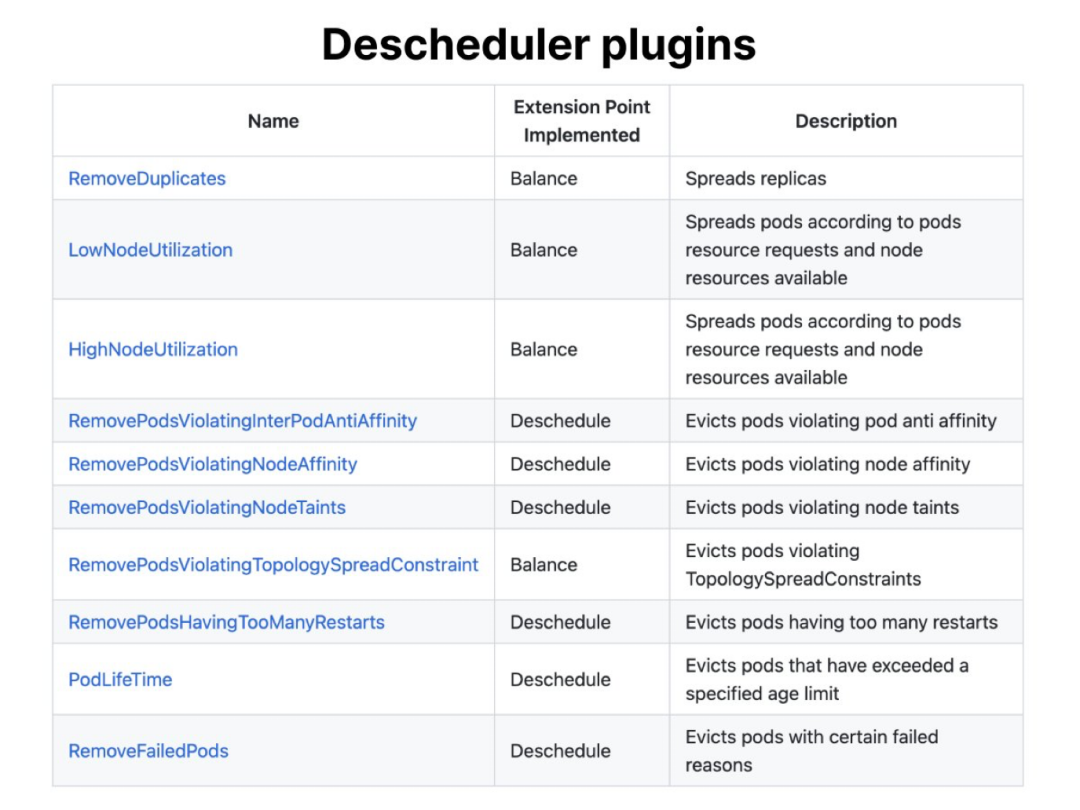
7Descheduler按策略驱逐
The Descheduler can evict pods based on policies such as:
- Node utilization
- Pod age
- Failed pods
- Duplicates
- Affinity or taints violations
Descheduler可以根据以下策略驱逐Pod
- 节点利用率
- Pod的年龄
- 失败的Pod
- 重复的Pod
- 亲和性或污点违规
8策略1CPU、内存或Pod数量
If your cluster has been running long, the resource utilization is not very balanced The following two strategies can be used to rebalance your cluster based on CPU, memory or number of pods
如果你的集群已经运行了一段时间资源利用可能不太平衡。
以下两种策略可以根据CPU、内存或Pod数量来重新平衡你的集群。

9策略2删除超过特定时间阈值的Pod
Another practical policy is deleting pods older than a certain threshold In this example, pods running for more than seven days are deleted
另一个实用的策略是删除超过特定时间阈值的Pod。在这个例子中运行超过七天的Pod将被删除。

10策略3RemoveDuplicate插件
Or you can use the RemoveDuplicate plugin to remove similar Pods from running on the same node This is useful to ensure higher availability if a node is lost
或者你可以使用RemoveDuplicate插件来删除在同一个节点上运行的相似Pod。
这对于确保更高的可用性非常有用特别是当一个节点丢失时。


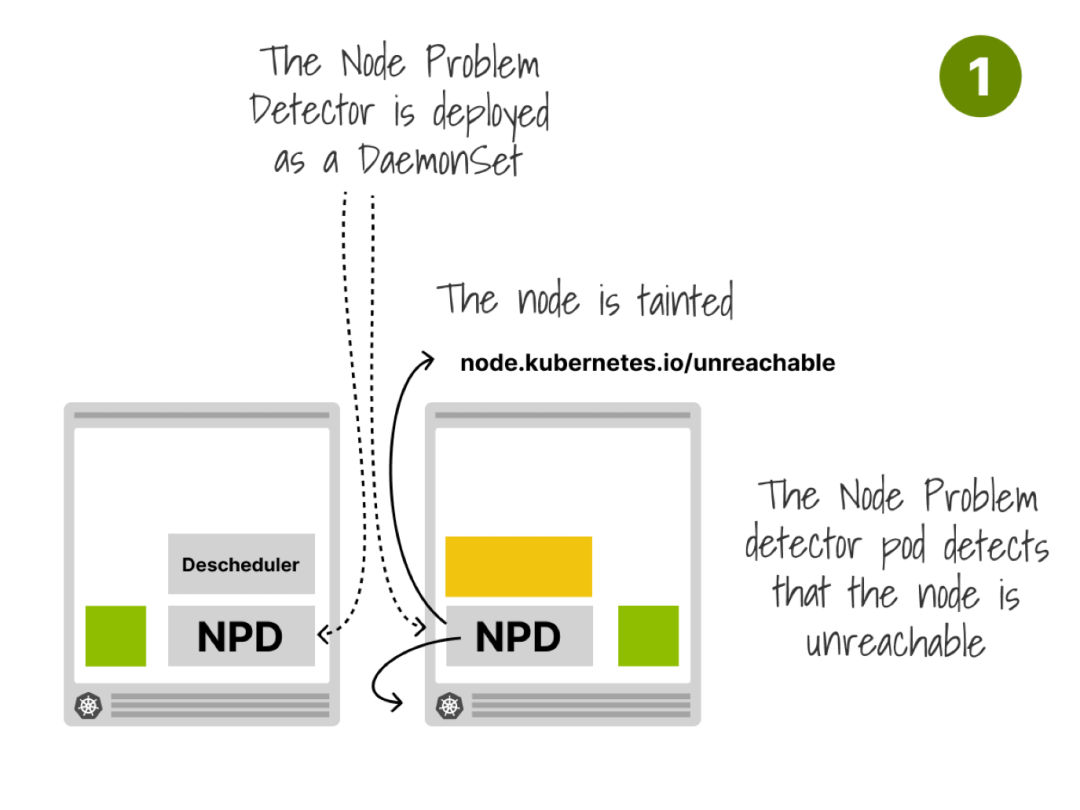
11集成Node Problem Detector
And lastly, you can combine the Descheduler with Node Problem Detector and Cluster Autoscaler to automatically remove Nodes with problems Let me explain with an example
最后你可以将Descheduler与Node Problem Detector和Cluster Autoscaler结合使用以自动删除出现问题的节点。
让我通过一个例子来解释。
Node Problem Detector can detect specific Node problems such as PIDPressure, MemoryPressure, etc. and report them to the API server The node controller can be configured to apply a taint to a node for a given state (TaintNodeByCondition)
Node Problem Detector可以检测特定的节点问题例如PIDPressure、MemoryPressure等并将它们报告给API服务器。
节点控制器可以配置为根据给定状态对节点施加污点TaintNodeByCondition。
12使用RemovePodsViolatingNodeTaints策略
After the taint is assigned to the node, you can have the Descheduler evict workloads from that tainted node using the RemovePodsViolatingNodeTaints strategy
在节点被标记taint之后你可以使用RemovePodsViolatingNodeTaints策略让Descheduler从被标记的节点上驱逐工作负载workload。

The pods can’t be allocated to the same node since they don’t tolerate the taint So, they are scheduled elsewhere in the cluster
由于Pods不容忍tolerate该污点它们无法分配到相同的节点上。
因此它们会在集群中的其他地方进行调度。

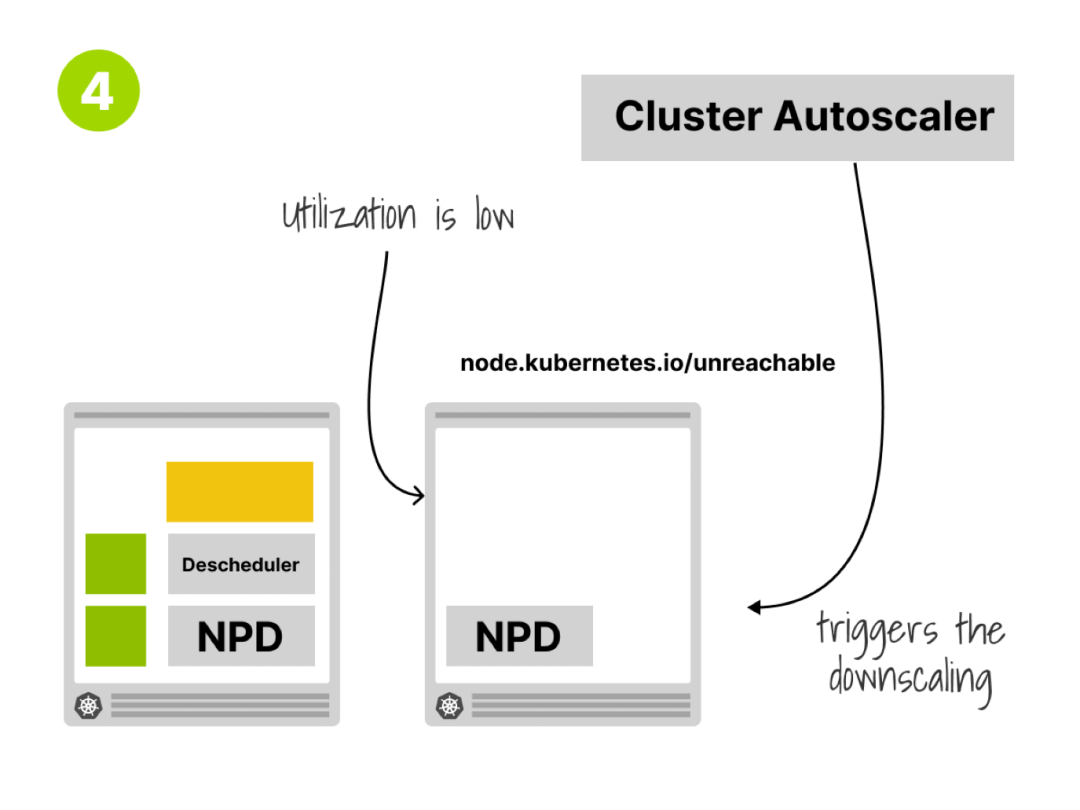
Finally, the node is likely to fall below the Cluster Autoscaler’s scale-down threshold and become a scale-down candidate and can be removed by Cluster Autoscaler
最后该节点很可能会低于Cluster Autoscaler的缩容阈值成为一个缩容候选节点并可以被Cluster Autoscaler移除。
13总结
The Descheduler is an excellent choice to keep your cluster efficiency in check, but it isn’t installed by default It can be deployed as a Job, CronJob or Deployment More info:
Descheduler是一个很好的选择可以保持集群的效率但它不是默认安装的。
它可以作为Job、CronJob或Deployment部署。
更多信息https://github.com/kubernetes-sigs/descheduler
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |