

Self-Attention-自注意机制
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
Original paper:
- Bahdanau, Cho, & Bengio. Neural machine translation by jointly learning to align and translate. In ICLR, 2015.
- Cheng, Dong, & Lapata. Long Short-Term Memory-Networks for Machine Reading. In EMNLP, 2016.
Self-Attention-自注意机制
在此之前你应该知道
Simple RNN Model
Long Short Term Memory (LSTM)
Attention-自注意机制
初始c0 = 0h0 = 0 全0向量
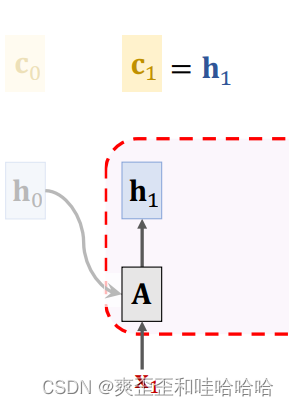
simple-RNN新的状态ht依赖于新的输入X1和上次状态ht-1
两者不一样的地方在于h0换成了c0

c1 = h1,
重复以下计算
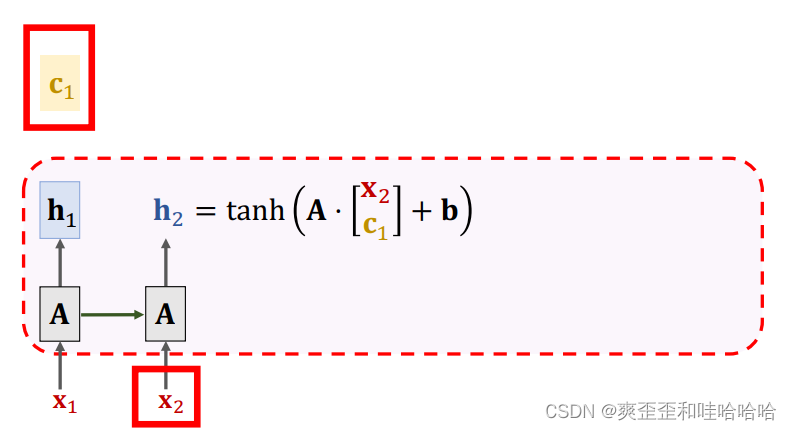
想要计算新的C2首先得计算hi与h2的相关性ai相关性计算在上一篇Attention-自注意机制有介绍这里便不累赘了


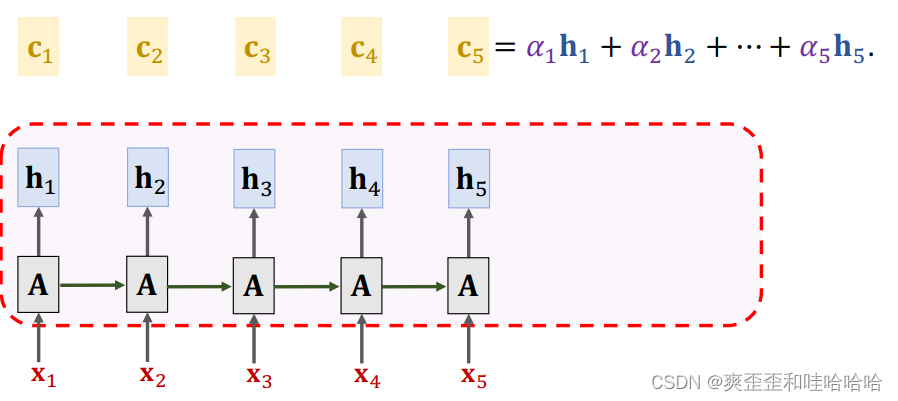
不断重复以上过程
通过self-attention自注意RNN 不太容易忘记且容易关注相关信息。

| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |