

【HBase高级】6. HBase数据结构(下)——LSM树数据结构、布隆过滤器、StoreFiles(HFile)结构
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
5.3 LSM树数据结构
1、简介
传统关系型数据库一般都选择使用B+树作为索引结构而在大数据场景下HBase、Kudu这些存储引擎选择的是LSM树。LSM树即日志结构合并树(Log-Structured Merge-Tree)。
- LSM树主要目标是快速建立索引
- B+树是建立索引的通用技术但如果并发写入压力较大时B+树需要大量的磁盘随机IO而严重影响索引创建的速度在一些写入操作非常频繁的应用场景中就不太适合了
- LSM树通过磁盘的顺序写来实现最好的写性能
2、LSM树设计思想
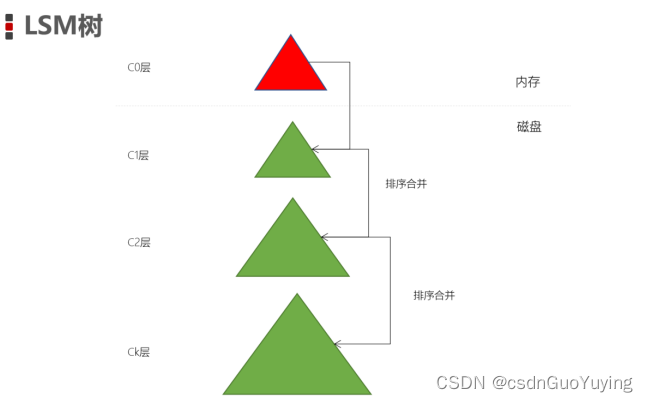
- LSM 的主要思想是划分不同等级的结构换句话来理解就是LSM中不止一个数据结构而是存在多种结构
- 一个结构在内存、其他结构在磁盘HBase存储结构中有内存——MemStore、也有磁盘——StoreFile
- 内存的结构可以是B树、红黑树、跳表等结构HBase中是跳表磁盘中的树就是一颗B+树
- C0层保存了最近写入的数据数据都是有序的而且可以随机更新、随机查询
- C1到CK层的数据都是存在磁盘中每一层中key都是有序存储的
3、LSM的数据写入操作
- 首先将数据写入到WALWrite Ahead log写日志是顺序写效率相对较高PUT、DELETE都是顺序写
- 数据项写入到内存中的C0结构中
- 只有内存中的C0结构超过一定阈值的时候将内存中的C0、和C1进行合并。这个过程就是Compaction合并
- 合并后的新的C1顺序写磁盘替换之前的C1
- 但C1层达到一定的大小会继续和下层合并合并后旧的文件都可以删除只保留最新的
- 整个写入的过程只用到了内存结构Compaction由后台异步完成不阻塞写入
4、LSM的数据查询操作
- 先在内存中查C0层
- 如果C0层中不存在数据则查询C1层
- 不断逐层查询最早的数据在CK层
- C0层因为是在内存中的结构中查询所以效率较高。因为数据都是分布在不同的层结构中所以一次查询可能需要多次跨层次结构查询所以读取的速度会慢一些。
- 根据以上LSM树结构的程序适合于写密集、少量查询的场景
布隆过滤器
1、简介
客户端这个key存在吗
服务器不存在/不知道
本质上布隆过滤器是一种数据结构是一种比较巧妙的概率型数据结构。它的特点是高效地插入和查询。但我们要检查一个key是否在某个结构中存在时通过使用布隆过滤器我们可以快速了解到「这个key一定不存在或者可能存在」。相比于以前学习过的List、Set、Map这些数据结构它更加高效、占用的空间也越少但是它返回的结果是概率性的是不确切的。
2、应用场景
缓存穿透
为了提高访问效率我们会将一些数据放在Redis缓存中。当进行数据查询时可以先从缓存中获取数据无需读取数据库。这样可以有效地提升性能。
- 在数据查询时首先要判断缓存中是否有数据如果有数据就直接从缓存中获取数据。
- 但如果没有数据就需要从数据库中获取数据然后放入缓存。如果大量访问都无法命中缓存会造成数据库要扛较大压力从而导致数据库崩溃。而使用布隆过滤器当访问不存在的缓存时可以迅速返回避免缓存或者DB crash。
判断某个数据是否在海量数据中存在
HBase中存储着非常海量数据要判断某个ROWKEYS、或者某个列是否存在使用布隆过滤器可以快速获取某个数据是否存在。但有一定的误判率。但如果某个key不存在一定是准确的。
3、HashMap的问题
要判断某个元素是否存在其实用HashMap效率是非常高的。HashMap通过把值映射为HashMap的Key这种方式可以实现O(1)常数级时间复杂度。
但是如果存储的数据量非常大的时候例如上亿的数据HashMap将会耗费非常大的内存大小。而且也根本无法一次性将海量的数据读进内存。
4、理解布隆过滤器
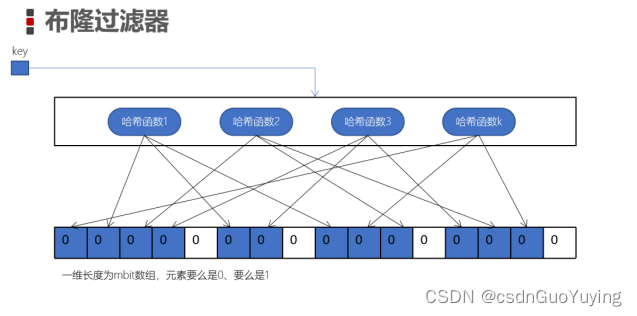
- 布隆过滤器是一个bit数组或者称为一个bit二进制向量
- 这个数组中的元素存的要么是0、要么是1
- k个hash函数都是彼此独立的并将每个hash函数计算后的结果对数组的长度m取模并将对一个的bit设置为1蓝色单元格
- 我们将每个key都按照这种方式设置单元格就是「布隆过滤器」
5、根据布隆过滤器查询元素
- 假设输入一个key我们使用之前的k个hash函数求哈希得到k个值
- 判断这k个值是否都为蓝色如果有一个不是蓝色那么这个key一定不存在
- 如果都有蓝色那么key是可能存在布隆过滤器会存在误判
- 因为如果输入对象很多而集合比较小的情况会导致集合中大多位置都会被描蓝那么检查某个key时候为蓝色时刚好某个位置正好被设置为蓝色了此时会错误认为该key在集合中
StoreFilesHFile结构
StoreFile是HBase存储数据的文件格式。
1、HFile的逻辑结构
HFile逻辑结构图
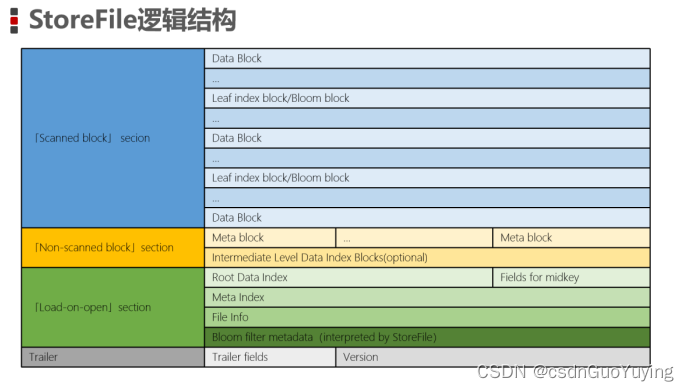
逻辑结构说明
4大部分
- Scanned block section
- 扫描StoreFile时所有的Data Block数据块都将会被读取
- Leaf IndexLSM + C1树索引、Bloom block布隆过滤器都会被读取
- Non-scanned block section
- 扫描StoreFile时不会被读取
- 包含MetaBlock和Intermediate Level Data Index Blocks
- Opening-time data section
- 在RegionServer启动时需要将数据加载到内存中包括数据块索引、元数据索引、布隆过滤器、文件信息。
- Trailer
- 记录了HFile的基本信息
- 各个部分的偏移值和寻址信息
2、StoreFile物理结构
StoreFile是以Hfile的形式存储在HDFS上的。Hfile的格式为下图
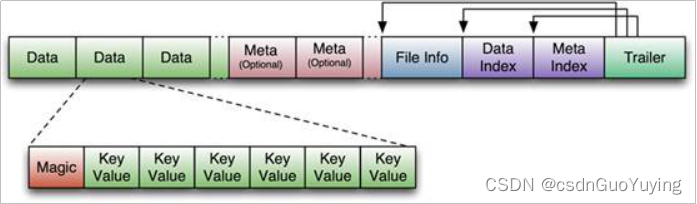
- HFile文件是不定长的长度固定的只有其中的两块Trailer和FileInfo。正如图中所示的Trailer中有指针指向其他数 据块的起始点。
- File Info中记录了文件的一些Meta信息例如AVG_KEY_LEN, AVG_VALUE_LEN, LAST_KEY, COMPARATOR, MAX_SEQ_ID_KEY等
- Data Index和Meta Index块记录了每个Data块和Meta块的起始点。
- Data Block是HBase I/O的基本单元为了提高效率HRegionServer中有基于LRU的Block Cache机制。每个Data块的大小可以在创建一个Table的时候通过参数指定大号的Block有利于顺序Scan小号Block利于随机查询。 每个Data块除了开头的Magic以外就是一个个KeyValue对拼接而成, Magic内容就是一些随机数字目的是防止数据损坏。
- HFile里面的每个KeyValue对就是一个简单的byte数组。但是这个byte数组里面包含了很多项并且有固定的结构。我们来看看里面的具体结构

1.开始是两个固定长度的数值分别表示Key的长度和Value的长度
2.紧接着是Key开始是固定长度的数值表示RowKey的长度
3.紧接着是 RowKey然后是固定长度的数值表示Family的长度
4.然后是Family接着是Qualifier
然后是两个固定长度的数值表示Time Stamp和Key TypePut/Delete——每一种操作都会生成一个Key-Value。Value部分没有这么复杂的结构就是纯粹的二进制数据了。
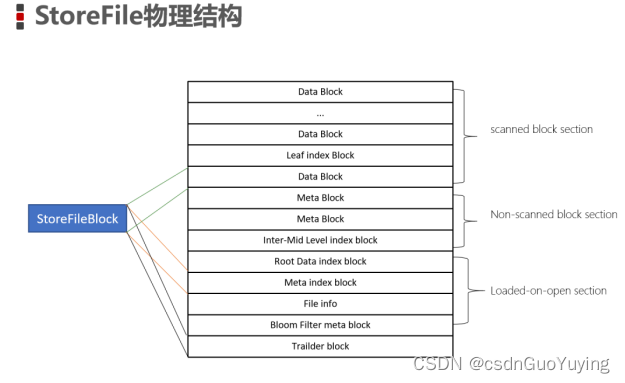
- Data Block段保存表中的数据这部分可以被压缩
- Meta Block段 (可选的)保存用户自定义的kv对可以被压缩。
- File Info段Hfile的元信息不被压缩用户也可以在这一部分添加自己的元信息
- Data Block Index段Data Block的索引。每条索引的key是被索引的block的第一条记录的key。
- Meta Block Index段 (可选的)Meta Block的索引。
- Trailer
这一段是定长的。保存了每一段的偏移量读取一个HFile时会首先 读取TrailerTrailer保存了每个段的起始位置(段的Magic Number用来做安全check)然后DataBlock Index会被读取到内存中这样当检索某个key时不需要扫描整个HFile而只需从内存中找到key所在的block通过一次磁盘io将整个 block读取到内存中再找到需要的key。DataBlock Index采用LRU机制淘汰