

【ResNet】Pytorch从零构建ResNet18_pytorch resnet18
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
Pytorch从零构建ResNet
第一章 从零构建ResNet18
第二章 从零构建ResNet50
文章目录
前言
-
ResNet 目前是应用很广的网络基础框架所以有必要了解一下并且resnet结构清晰适合练手
-
pytorch就更不用多说了。(
坑自坑) 懂自懂 -
本文使用以下环境构筑
torch 1.11 torchvision 0.12.0 python 3.9
一、ResNet是什么
深度残差网络Deep residual network, ResNet的提出是CNN图像史上的一件里程碑事件,具体多牛大家自己某度咯。ResNet的作者何恺明也因此摘得CVPR2016最佳论文奖当然何博士的成就远不止于此感兴趣的也可以去搜一下他后来的辉煌战绩。下面简单讲述ResNet的理论及实现。
1. 残差学习
深度网络的退化问题至少说明深度网络不容易训练。但是我们考虑这样一个事实现在你有一个浅层网络你想通过向上堆积新层来建立深层网络一个极端情况是这些增加的层什么也不学习仅仅复制浅层网络的特征即这样新层是恒等映射Identity mapping。在这种情况下深层网络应该至少和浅层网络性能一样也不应该出现退化现象。
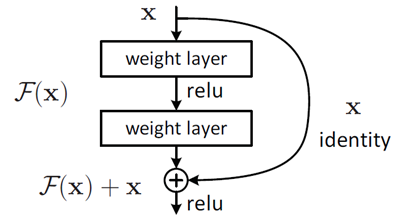
这个有趣的假设让何博士灵感爆发他提出了残差学习来解决退化问题。对于一个堆积层结构几层堆积而成。对于一个堆积层结构几层堆积而成当输入为 x时其学习到的特征记为F(x), 现在再加一条分支直接跳到堆积层的输出则此时最终输出H(x) = F(x) + x
如下图
这种跳跃连接就叫做shortcut connection类似电路中的短路。具体原理这边不展开叙说感兴趣的可以去看原论文。上面这种两层结构的叫BasicBlock一般适用于ResNet18和ResNet34而ResNet50以后都使用下面这种三层的残差结构叫Bottleneck
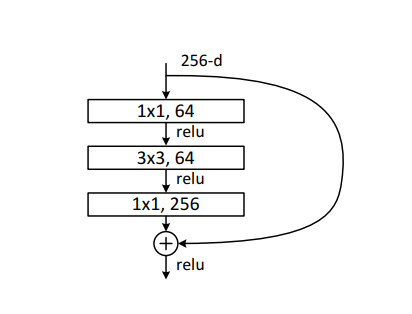
2. ResNet具体结构
上面简单说了以下残差网络与普通卷积的区别接下来用图来看一下网络的结构
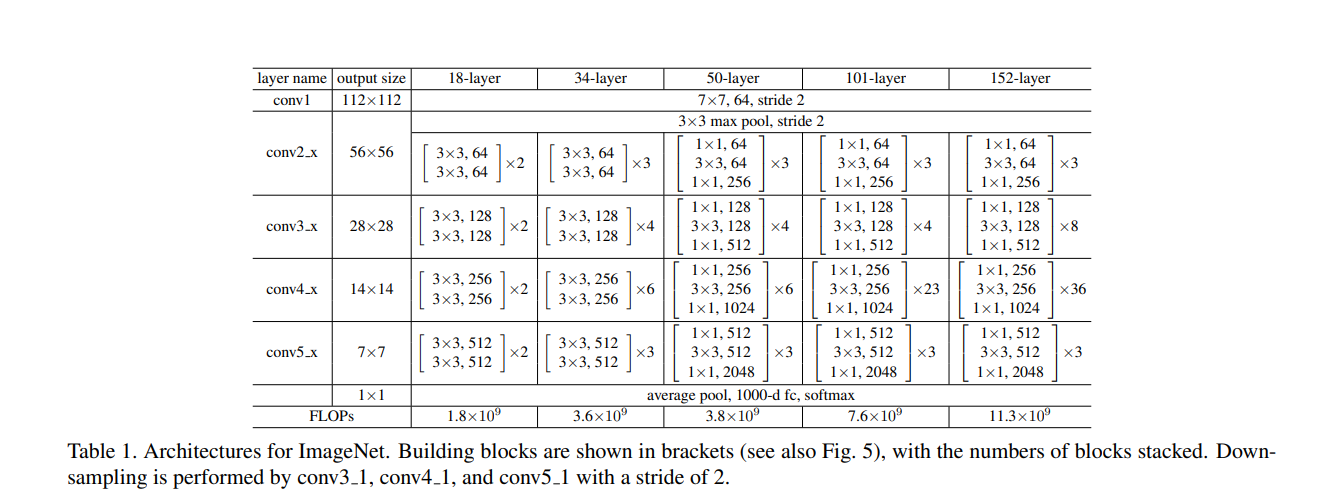
可以看到18层的网络有五个部分组成从conv2开始每层都有两个有残差块并且每个残差块具有2个卷积层。接下来再具体看看18层以及50层的具体结构
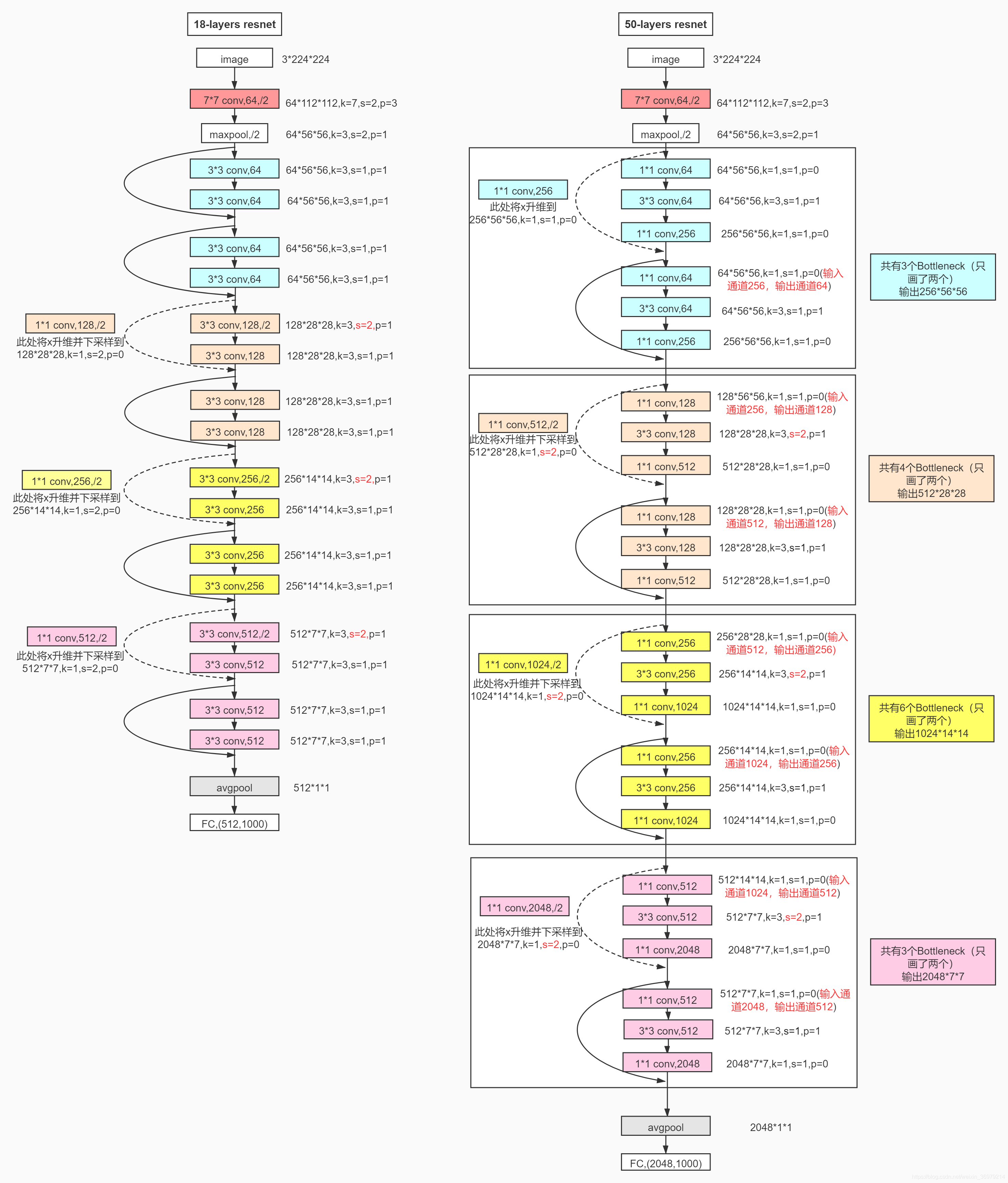
其中蓝色部分为conv2,然后往下依次按颜色划分为conv3、conv4conv5。需要注意的是从conv3开始第一个残差块的第一个卷积层的stride为2这是每层图片尺寸变化的原因。另外stride为2的时候每层的维度也就是channel也发生了变化这这时候残差与输出不是直接相连的因为维度不匹配需要进行升维也就是上图中虚线连接的残差块实线部分代表可以直接相加.
二、ResNet分步骤实现
首先实现残差块
class BasicBlock(nn.Module):
def __init__(self,in_channels,out_channels,stride=[1,1],padding=1) -> None:
super(BasicBlock, self).__init__()
# 残差部分
self.layer = nn.Sequential(
nn.Conv2d(in_channels,out_channels,kernel_size=3,stride=stride[0],padding=padding,bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True), # 原地替换 节省内存开销
nn.Conv2d(out_channels,out_channels,kernel_size=3,stride=stride[1],padding=padding,bias=False),
nn.BatchNorm2d(out_channels)
)
# shortcut 部分
# 由于存在维度不一致的情况 所以分情况
self.shortcut = nn.Sequential()
if stride[0] != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(
# 卷积核为1 进行升降维
# 注意跳变时 都是stride==2的时候 也就是每次输出信道升维的时候
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride[0], bias=False),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
out = self.layer(x)
out += self.shortcut(x)
out = F.relu(out)
return out
接下来是ResNet18的具体实现
# 采用bn的网络中卷积层的输出并不加偏置
class ResNet18(nn.Module):
def __init__(self, BasicBlock, num_classes=10) -> None:
super(ResNet18, self).__init__()
self.in_channels = 64
# 第一层作为单独的 因为没有残差快
self.conv1 = nn.Sequential(
nn.Conv2d(3,64,kernel_size=7,stride=2,padding=3,bias=False),
nn.BatchNorm2d(64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
# conv2_x
self.conv2 = self._make_layer(BasicBlock,64,[[1,1],[1,1]])
# conv3_x
self.conv3 = self._make_layer(BasicBlock,128,[[2,1],[1,1]])
# conv4_x
self.conv4 = self._make_layer(BasicBlock,256,[[2,1],[1,1]])
# conv5_x
self.conv5 = self._make_layer(BasicBlock,512,[[2,1],[1,1]])
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512, num_classes)
#这个函数主要是用来重复同一个残差块
def _make_layer(self, block, out_channels, strides):
layers = []
for stride in strides:
layers.append(block(self.in_channels, out_channels, stride))
self.in_channels = out_channels
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv1(x)
out = self.conv2(out)
out = self.conv3(out)
out = self.conv4(out)
out = self.conv5(out)
# out = F.avg_pool2d(out,7)
out = self.avgpool(out)
out = out.reshape(x.shape[0], -1)
out = self.fc(out)
return out
可以输出网络结构看一下
res18 = ResNet18(BasicBlock)
print(res18)
ResNet18(
(conv1): Sequential(
(0): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
)
(conv2): Sequential(
(0): BasicBlock(
(layer): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential()
)
(1): BasicBlock(
(layer): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential()
)
)
(conv3): Sequential(
(0): BasicBlock(
(layer): Sequential(
(0): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(layer): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential()
)
)
(conv4): Sequential(
(0): BasicBlock(
(layer): Sequential(
(0): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(layer): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential()
)
)
(conv5): Sequential(
(0): BasicBlock(
(layer): Sequential(
(0): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(layer): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential()
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=10, bias=True)
)
至此Resnet18就构建好了
三、完整例子+测试
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets, utils
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plt
import numpy as np
from torch.utils.data.dataset import Dataset
from torchvision.transforms import transforms
from pathlib import Path
import cv2
from PIL import Image
import torch.nn.functional as F
%matplotlib inline
%config InlineBackend.figure_format = 'svg' # 控制显示
transform = transforms.Compose([ToTensor(),
transforms.Normalize(
mean=[0.5,0.5,0.5],
std=[0.5,0.5,0.5]
),
transforms.Resize((224, 224))
])
training_data = datasets.CIFAR10(
root="data",
train=True,
download=True,
transform=transform,
)
testing_data = datasets.CIFAR10(
root="data",
train=False,
download=True,
transform=transform,
)
class BasicBlock(nn.Module):
def __init__(self,in_channels,out_channels,stride=[1,1],padding=1) -> None:
super(BasicBlock, self).__init__()
# 残差部分
self.layer = nn.Sequential(
nn.Conv2d(in_channels,out_channels,kernel_size=3,stride=stride[0],padding=padding,bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True), # 原地替换 节省内存开销
nn.Conv2d(out_channels,out_channels,kernel_size=3,stride=stride[1],padding=padding,bias=False),
nn.BatchNorm2d(out_channels)
)
# shortcut 部分
# 由于存在维度不一致的情况 所以分情况
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(
# 卷积核为1 进行升降维
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride[0], bias=False),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
# print('shape of x: {}'.format(x.shape))
out = self.layer(x)
# print('shape of out: {}'.format(out.shape))
# print('After shortcut shape of x: {}'.format(self.shortcut(x).shape))
out += self.shortcut(x)
out = F.relu(out)
return out
# 采用bn的网络中卷积层的输出并不加偏置
class ResNet18(nn.Module):
def __init__(self, BasicBlock, num_classes=10) -> None:
super(ResNet18, self).__init__()
self.in_channels = 64
# 第一层作为单独的 因为没有残差快
self.conv1 = nn.Sequential(
nn.Conv2d(3,64,kernel_size=7,stride=2,padding=3,bias=False),
nn.BatchNorm2d(64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
# conv2_x
self.conv2 = self._make_layer(BasicBlock,64,[[1,1],[1,1]])
# self.conv2_2 = self._make_layer(BasicBlock,64,[1,1])
# conv3_x
self.conv3 = self._make_layer(BasicBlock,128,[[2,1],[1,1]])
# self.conv3_2 = self._make_layer(BasicBlock,128,[1,1])
# conv4_x
self.conv4 = self._make_layer(BasicBlock,256,[[2,1],[1,1]])
# self.conv4_2 = self._make_layer(BasicBlock,256,[1,1])
# conv5_x
self.conv5 = self._make_layer(BasicBlock,512,[[2,1],[1,1]])
# self.conv5_2 = self._make_layer(BasicBlock,512,[1,1])
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512, num_classes)
#这个函数主要是用来重复同一个残差块
def _make_layer(self, block, out_channels, strides):
layers = []
for stride in strides:
layers.append(block(self.in_channels, out_channels, stride))
self.in_channels = out_channels
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv1(x)
out = self.conv2(out)
out = self.conv3(out)
out = self.conv4(out)
out = self.conv5(out)
# out = F.avg_pool2d(out,7)
out = self.avgpool(out)
out = out.reshape(x.shape[0], -1)
out = self.fc(out)
return out
# 保持数据集和测试机能完整划分
batch_size=100
train_data = DataLoader(dataset=training_data,batch_size=batch_size,shuffle=True,drop_last=True)
test_data = DataLoader(dataset=testing_data,batch_size=batch_size,shuffle=True,drop_last=True)
images,labels = next(iter(train_data))
print(images.shape)
img = utils.make_grid(images)
img = img.numpy().transpose(1,2,0)
mean=[0.5,0.5,0.5]
std=[0.5,0.5,0.5]
img = img * std + mean
print([labels[i] for i in range(64)])
plt.imshow(img)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = res18.to(device)
cost = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters())
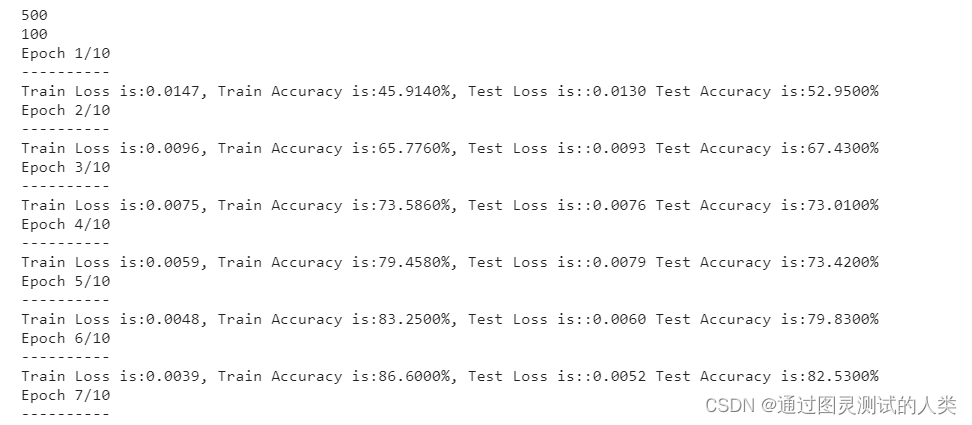
print(len(train_data))
print(len(test_data))
epochs = 10
for epoch in range(epochs):
running_loss = 0.0
running_correct = 0.0
model.train()
print("Epoch {}/{}".format(epoch+1,epochs))
print("-"*10)
for X_train,y_train in train_data:
# X_train,y_train = torch.autograd.Variable(X_train),torch.autograd.Variable(y_train)
X_train,y_train = X_train.to(device), y_train.to(device)
outputs = model(X_train)
_,pred = torch.max(outputs.data,1)
optimizer.zero_grad()
loss = cost(outputs,y_train)
loss.backward()
optimizer.step()
running_loss += loss.item()
running_correct += torch.sum(pred == y_train.data)
testing_correct = 0
test_loss = 0
model.eval()
for X_test,y_test in test_data:
# X_test,y_test = torch.autograd.Variable(X_test),torch.autograd.Variable(y_test)
X_test,y_test = X_test.to(device), y_test.to(device)
outputs = model(X_test)
loss = cost(outputs,y_test)
_,pred = torch.max(outputs.data,1)
testing_correct += torch.sum(pred == y_test.data)
test_loss += loss.item()
print("Train Loss is:{:.4f}, Train Accuracy is:{:.4f}%, Test Loss is::{:.4f} Test Accuracy is:{:.4f}%".format(
running_loss/len(training_data), 100*running_correct/len(training_data),
test_loss/len(testing_data),
100*testing_correct/len(testing_data)
))
可以看看结果 还是不错的
到目前为止pytorch构建resnet18就完成了。接下来会构建50
总结
通过手写网络可以加深对网络的理解同时运用pytorch更加熟练。
PS: 此博客同时更新于个人博客