

Protobuf在Hadoop RPC中的应用
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
💡 阻碍阅读Hadoop源码的重要一环就是Hadoop RPC,当阅读这一块代码时,往往有各种proto文件。当我们想要寻找Hadoop服务端的API实现时,可能会直接跳转到protobuf生成的代码,这里面并不是业务代码的真正实现,往往会讲阅读者思路打乱。本文会介绍并实践 Rpc Writable和Rpc protobuf,对protobuf的概念有一定了解;下一篇文章会详细介绍Hadoop RPC的实现。
1. RPC基本流程
在早期,本人就写过netty中rpc的实现:https://blog.51cto.com/u_15327484/5406288。先回顾下RPC的基本调用流程:
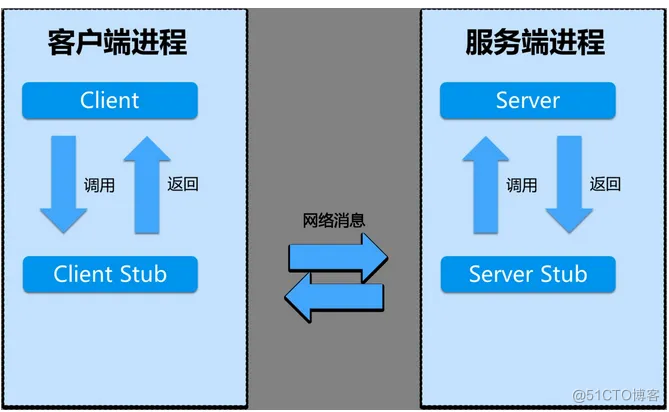
- 客户端调用客户端stub(client stub)。这个调用是在本地,并将调用参数push到栈(stack)中。
- 客户端stub(client stub)将这些参数包装,并通过系统调用发送到服务端机器。打包的过程叫 marshalling。(常见方式:XML、JSON、二进制编码)
- 客户端本地操作系统发送信息至服务器。(可通过自定义TCP协议或HTTP传输)
- 服务器系统将信息传送至服务端stub(server stub)。
- 服务端stub(server stub)解析信息。该过程叫 unmarshalling。
- 服务端stub(server stub)调用程序,处理客户端请求,返回结果给客户端,此过程无需调用客户端的rpc方法。 如图所示:
marshalling跟serialization的本质都是序列化,二者的区别如下:
- Serialization:负责传输对象、对象持久化。serialize对象的时候,只会将该对象内部数据写进字节流。
- Marshalling:负责远程传输参数(RMI的时候)。serialize对象的时候,除了对象内部数据,还会包含一些codebase信息(比如实现该对象的代码位置信息等)。
2. Hadoop Rpc
RPC有多种实现,例如grpc,java自带的rmi。Hadoop自己也实现了一套自用的Rpc框架,其实现是在hadoop-common模块中,如下:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.8.5</version>
</dependency>
通过引用这个模块,我们也可以创建Java服务。
Hadoop Rpc一直使用这套框架。
- 在Hadoop1.x版本中,基于Java的Writable接口进行序列化/反序列化。
- 在Hadoop2.x以上的版本中,升级序列化/反序列化工具为protobuf。
后续会基于两种序列化方式进行实践,代码在:https://github.com/boobpoop/hadoop_rpc_demo中。
3. Hadoop Rpc Writable序列化实践
代码分布如下所示:

Rpc调用方法中的输入参数和输出参数需要实现Writable接口的write和readFields方法。如下是:
package com.yuliang.writable_rpc;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class BusinessResponse implements Writable {
private String result;
public BusinessResponse() {
}
//省略
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(this.result);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
this.setResult(dataInput.readUTF());
}
}
定义协议的接口:
package com.yuliang.writable_rpc;
public interface BusinessProtocol {
BusinessResponse buy(BusinessRequest br);
long versionID = 345043000L;
}
定义服务端调用逻辑:
package com.yuliang.writable_rpc;
public class BusinessServerImpl implements BusinessProtocol{
@Override
public BusinessResponse buy(BusinessRequest br) {
return new BusinessResponse(br.getBrand() + " " + br.getNum() + " " + br.getPrice());
}
}
编写服务端代码:
package com.yuliang.writable_rpc;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.ipc.RPC;
import java.io.IOException;
public class Server {
public static void main(String[] args) throws IOException {
RPC.Server server = new RPC.Builder(new Configuration())
.setProtocol(BusinessProtocol.class)
.setInstance(new BusinessServerImpl())
.setBindAddress("localhost")
.setPort(12345)
.build();
server.start();
}
}
编写客户端启动代码:
package com.yuliang.writable_rpc;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.ipc.RPC;
import java.io.IOException;
public class Server {
public static void main(String[] args) throws IOException {
RPC.Server server = new RPC.Builder(new Configuration())
.setProtocol(BusinessProtocol.class)
.setInstance(new BusinessServerImpl())
.setBindAddress("localhost")
.setPort(12345)
.build();
server.start();
}
}
运行,发现执行正常:

4. Hadoop Rpc Writable缺点
Hadoop Writable序列化方式,能够快速构建服务。但是有以下几个缺点:
- 无法跨语言。客户端只能使用java进行编写,无法使用其他编程语言访问服务端。
- 序列化效率差。使用java的序列化方式,比protobuf效率差很多,影响服务传输效率。
- 输入参数和输出参数需要实现Writable接口的write和readFields方法,而这些方法其实没必要人工编写。
5. Hadoop Rpc Protobuf
protobuf作为序列化工具,只需要创建proto文件,里面定义好方法的输入参数和输出参数,通过proto工具生成java,c++的类即可,它会生成输入参数和输出参数实现类以及接口,完全解决了Writable的问题。
6. Hadoop Rpc Protobuf序列化实践
本小节中,将上面的Hadoop Rpc Writable代码改造成Protobuf。额外引入protobuf类:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.8.5</version>
</dependency>
<dependency>
<groupId>com.google.protobuf</groupId>
<artifactId>protobuf-java</artifactId>
<version>3.19.1</version>
</dependency>
代码分布:

其中,定义参数相关BusinessProto.proto:
syntax = "proto2";
option java_package = "com.yuliang.protobuf_rpc.proto";
option java_outer_classname = "Business";
option java_generic_services = true;
option java_generate_equals_and_hash = true;
message BusinessRequestProto {
required string brand = 1;
required int64 num = 2;
required double price = 3;
}
message BusinessResponseProto {
required string result = 1;
}
定义rpc方法BusinessServiceProto.proto:
syntax = "proto2";
import "com/yuliang/protobuf_rpc/proto/BusinessProto.proto";
option java_package = "com.yuliang.protobuf_rpc.proto";
option java_outer_classname = "BusinessService";
option java_generic_services = true;
option java_generate_equals_and_hash = true;
service BusinessServiceProto {
rpc buy(BusinessRequestProto) returns (BusinessResponseProto);
}
在proto文件所在目录生成rpc调用Interface:
protoc src/main/java/com/yuliang/protobuf_rpc/proto/BusinessProto.proto --java_out=src/main/java -I=src/main/java
protoc src/main/java/com/yuliang/protobuf_rpc/proto/BusinessServiceProto.proto --java_out=src/main/java -I=src/main/java
我们主要使用的是protoc生成的BusinessService.BusinessServiceProto.BlockingInterface接口。必须继承该接口,主要是设置versionID,不然客户端调用时报错;同时,后续实现起来,接口名称也变短了,比较方便:
package com.yuliang.protobuf_rpc;
import com.yuliang.protobuf_rpc.proto.BusinessService;
public interface BusinessServicePB extends BusinessService.BusinessServiceProto.BlockingInterface {
public static final long versionID=1L;
}
实现该接口,可以将实现的逻辑独立到一个新的类中,Hadoop就是这个干的:
package com.yuliang.protobuf_rpc;
import com.google.protobuf.RpcController;
import com.google.protobuf.ServiceException;
import com.yuliang.protobuf_rpc.proto.Business;
public class BusinessServerPBImpl implements BusinessServicePB {
@Override
public Business.BusinessResponseProto buy(RpcController controller, Business.BusinessRequestProto request) throws ServiceException {
String result = request.getBrand() + " " + request.getNum() + " " + request.getPrice();
return Business.BusinessResponseProto.newBuilder().setResult(result).build();
}
}
服务端启动,注意要指定ProtocolEngine为ProtobufRpcEngine,否则默认使用WritableRpcEngine:
public class Server {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
RPC.setProtocolEngine(conf, BusinessServicePB.class, ProtobufRpcEngine.class);
RPC.Server server = new RPC.Builder(conf)
.setProtocol(BusinessServicePB.class)
.setInstance(BusinessService.BusinessServiceProto.newReflectiveBlockingService(new BusinessServerPBImpl()))
.setBindAddress("localhost")
.setPort(12345)
.build();
server.start();
}
}
客户端启动:
package com.yuliang.protobuf_rpc;
import com.google.protobuf.ServiceException;
import com.yuliang.protobuf_rpc.proto.Business;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.ipc.ProtobufRpcEngine;
import org.apache.hadoop.ipc.RPC;
import java.io.IOException;
import java.net.InetSocketAddress;
public class Client {
public static void main(String[] args) throws IOException, ServiceException {
Configuration conf = new Configuration();
RPC.setProtocolEngine(conf, BusinessServicePB.class, ProtobufRpcEngine.class);
BusinessServicePB proxy = RPC.getProxy(BusinessServicePB.class, BusinessServicePB.versionID, new InetSocketAddress("localhost", 12345), conf);
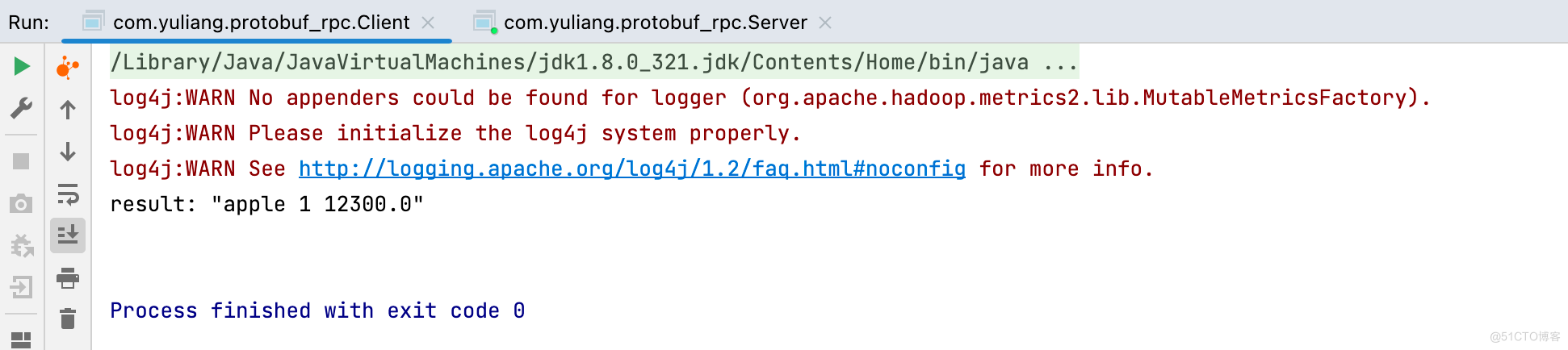
Business.BusinessResponseProto result = proxy.buy(null, Business.BusinessRequestProto.newBuilder().setBrand("apple").setNum(1).setPrice(12300).build());
System.out.println(result);
}
}
执行成功:
7. 总结
Protobuf作为序列化/反序列化工具。Hadoop RPC Protobuf比Hadoop RPC Writable优势如下:
- 跨语言。允许go、c++远程访问Hadoop服务。
- 效率高。Protobuf序列化/反序列化效率比Java自带高得多。
- 工作少。开发者无法手动实现Writable接口中的方法。
缺点:
- 引入了第三方组件protobuf,Hadoop项目复杂性增加,增加阅读难度。
Hadoop RPC Protobuf代码编写注意事项:
- 一定要实现Proto生成类的BlockingInterface,一定要定义versionID成员变量。
- 一定要手动指定ProtocolEngine为ProtobufRpcEngine。
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |