274. H 指数
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
274. H 指数
一、题目描述

二、题目分析
这道题比较绕理解题目意思根据题目的说法所谓的H指数就是总共有 h 篇论文分别被引用了至少 h 次。且其余的 n - h 篇论文每篇被引用次数 不超过 h 次。
解释示例2
总共有1篇论文分别被引用了至少1次且剩余的2篇论文每篇被引用次数不超过1次之所以可以这么说因为序号为2的这篇论文引用次数是3大于1所以被引用至少1次。而剩下的序号为1的论文和序号为3的论文引用次数均为1不超过1次。所以H指数为1。当H指数为2的时候显然不成立所以1就是最大的H值。
三、解题思路
3.1 更换H指数定义
题目中给出的H指数定义比较绕如果查询百度百科可以发现一个更加简单的H指数的定义

那么问题就变得很简单了将citations数组逆序排序然后找到当前citations[i]<=i的下标i返回i即可。比如示例1中的[6,5,3,1,0]发现i=3的时候满足条件因此H指数为3。
解题的时候并没有采用逆序排序的方法原因是Arrays工具类仅支持对基本类型数组升序排序此时该如何做呢?
- 首先百度百科中的序号是从1开始的而数组下标是从0开始的百度百科中说的是直到某篇论文的序号大于该论文被引次数序号减1就是H指数。换言之也就是在降序数组中直到某篇论文的索引(索引从0开始编号)大于等于该论文的被引次数该索引就是H指数。
- 对百科中的条件进一步转换百科中要求的是正向遍历降序数组找到第一个索引值大于等于元素值的索引下标换句话说也就是找逆序遍历降序数组时索引值小于元素值的索引下标+1的位置。
- 逆向遍历降序数组等同于正向遍历升序数组并且升序数组中每一个元素的索引i对应着降序数组中的length - i - 1位置。
- 因此只需要正向遍历升序数组找到第一个citations[i] > citations.length - 1的i然后返回citations.length - i - 1 + 1
class Solution {
public int hIndex(int[] citations) {
Arrays.sort(citations);
// 0 1 3 5 6
// 6 5 3 3 0
for (int i = 0; i < citations.length; i++) {
if (citations[i] > citations.length - i - 1) {
return citations.length - i;
}
}
return 0;
}
}
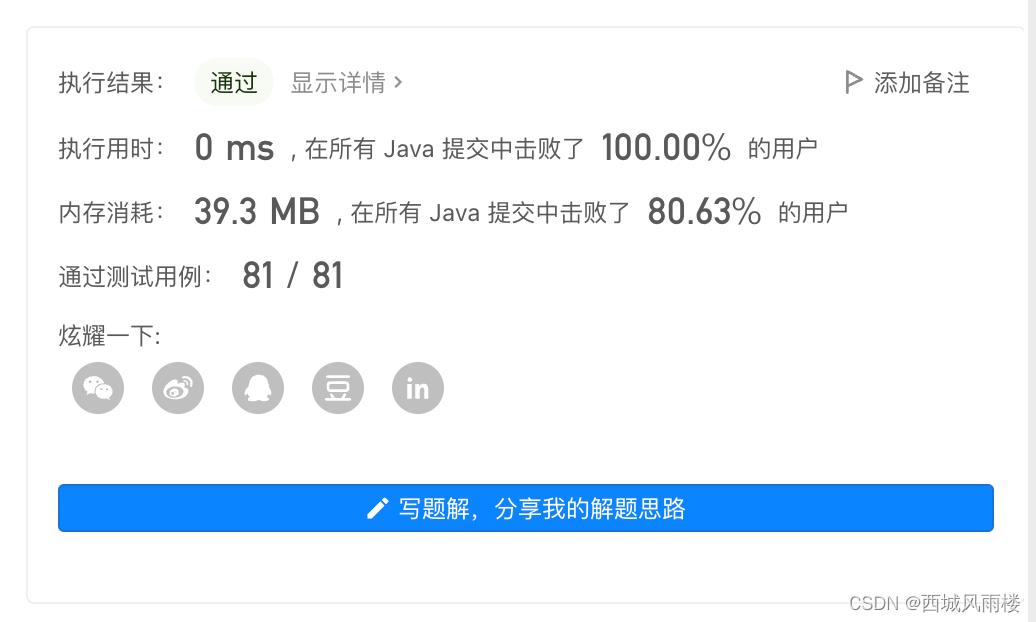
时间复杂度O(nlogn)因为存在排序算法空间复杂度O(1)
3.2 二分法枚举H指数
思路2采用的是一种常规思路就是枚举求解H指数但是枚举的过程使用二分枚举。降低枚举过程中的时间复杂度。
先说暴力枚举思路
- 根据题意发现H指数最大就是数组的长度因此H指数的范围是
[0,length]比如[4,4,4,4]的H指数就是4[0,0,0,0]的H指数就是0 - 第一层for循环枚举所有可能的H指数然后对于每一个枚举的H指数编写第二层for循环判断当前H指数是否满足题目中的H指数判定条件找到最大的H指数。
class Solution {
public int hIndex(int[] citations) {
return solve01(citations);
}
public int solve01(int[] citations) {
int ans = 0;
for (int i = 0; i <= citations.length; i++) {
if (verifyH(citations, i)) {
ans = Math.max(ans, i);
}
}
return ans;
}
private boolean verifyH(int[] citations, int H) {
int moreH = 0;
for (int i = 0; i < citations.length; i++) {
if (citations[i] >= H) {
moreH++;
}
}
return moreH >= H;
}
}
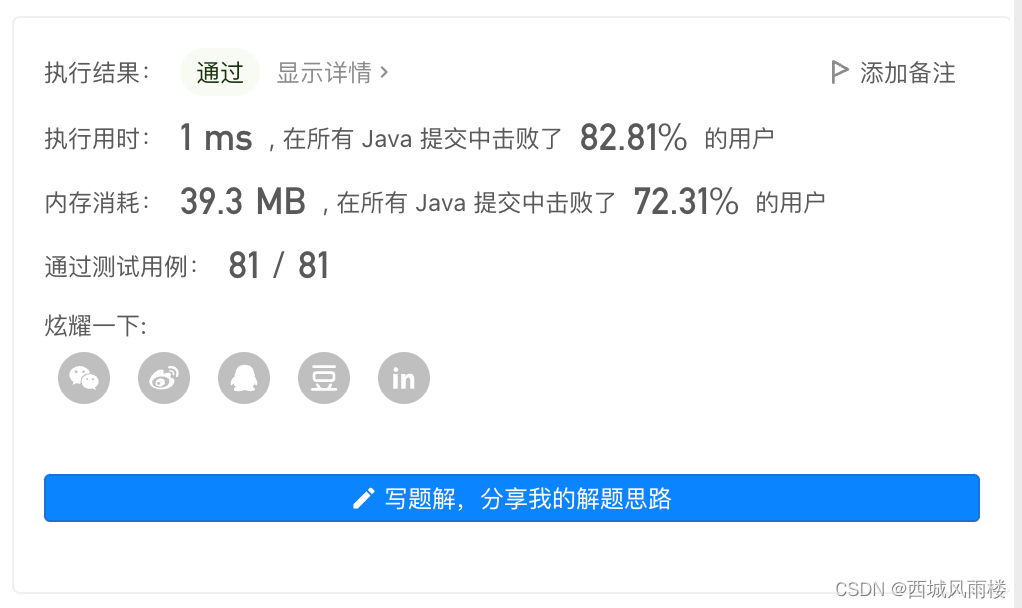
显然这种暴力枚举H的思路的时间复杂度是O(N)空间复杂度是O(1)
然后看二分枚举思路
- left=0right = citations.length
[left,right]是H可能的值 - H = (left + right) / 2
- 验证H是否合法如果合法说明可能存在更大的H当然当前H也可能是最大的H此时记录下H的值将区间变为
[H+1,right] - 如果H不合法说明不存在H篇论文至少被引用了H次也就是少于H篇至少被引用了H次此时缩小搜索区间
[left, H-1]
class Solution {
// 总体二分的思路就是二分枚举H指数
// 对于枚举的H指数找到最大的那一个
// 假设当前考虑的H指数是N如果刚好满足
// 引用数组中有>N篇引用超过了N次那么说明
// 可能还有比当前N更大的H指数
// 如果数组中>N篇引用低于N次说明H指数枚举大了需要缩小
public int hIndex(int[] citations) {
return solve02(citations);
}
public int solve02(int[] citations) {
int left = 0;
int right = citations.length;
int ansH = 0;
while (left <= right) {
int mid = left + ((right - left) >> 1);
if (verifyH(citations, mid)) {
ansH = mid;
left = mid + 1;
} else {
right = mid - 1;
}
}
return ansH;
}
private boolean verifyH(int[] citations, int H) {
int moreH = 0;
for (int i = 0; i < citations.length; i++) {
if (citations[i] >= H) {
moreH++;
}
}
return moreH >= H;
}
}
时间复杂度O(nlogn)空间复杂度O(1)