

Python实战项目1——自动获取小说工具
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |

🤵♂️ 个人主页@老虎也淘气 个人主页
✍🏻作者简介Python学习者
🐋 希望大家多多支持我们一起进步😄
如果文章对你有帮助的话
欢迎评论 💬点赞👍🏻 收藏 📂加关注
今天分享利用pyhton简单爬取小说以大家最爱的《斗罗大陆》为例。
准备
win11
pycharm
Edge浏览器
开始
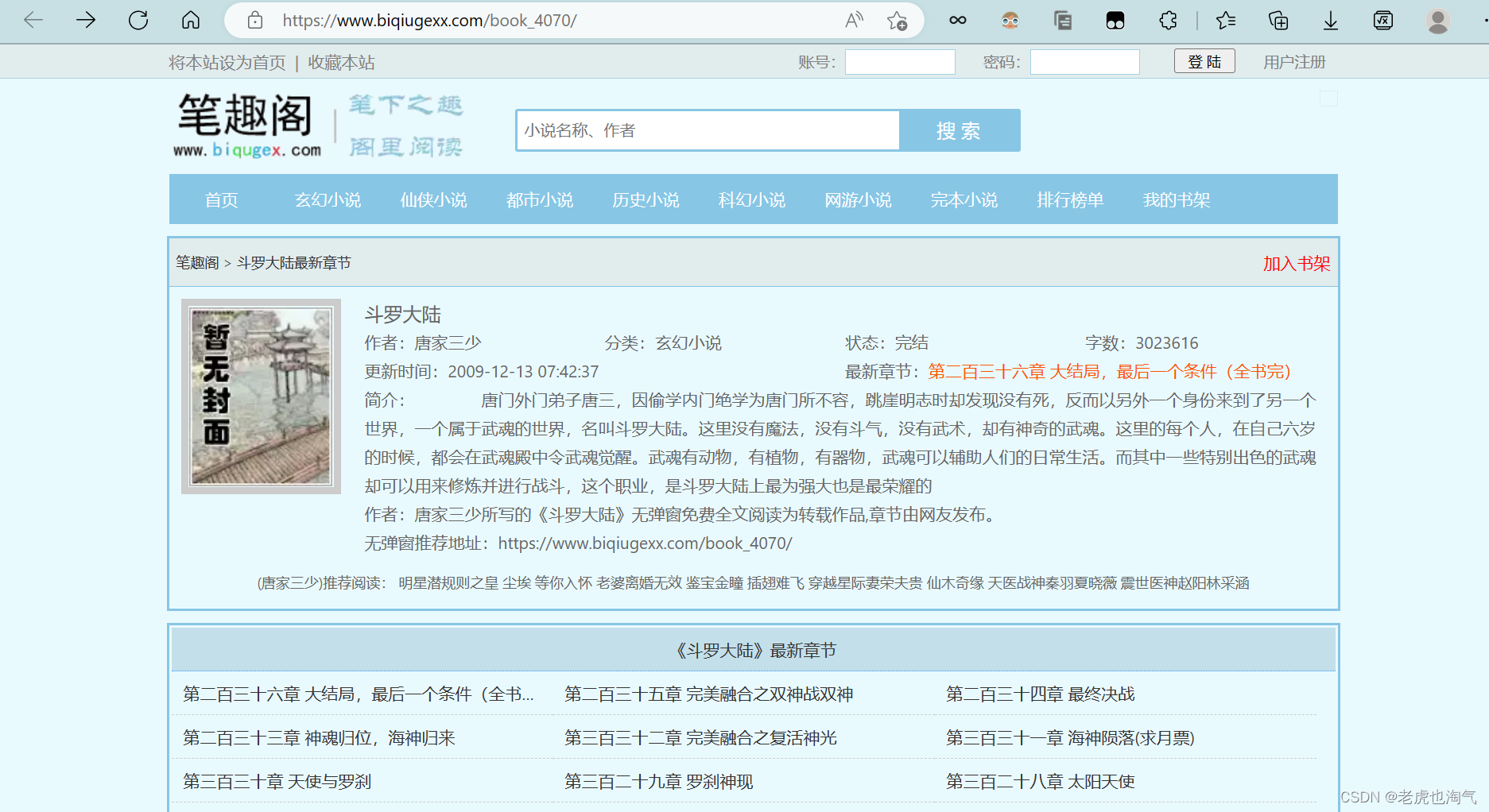
首先打开浏览器搜素《斗罗大陆》小说点开任意结果网站本次以下图为例
打开pycharm做准备工作
如若没有安装request 利用以下代码安装。
pip install requests
导入。
# 怎么发送请求
# pip install requests
import request
发送给谁
搞定URL地址即小说地址。
url = 'https://www.93xscc.com/9034/2126907.html'
发送请求
resp = requests.get(url,headers=headers)
这里为什么要用get 解释一下
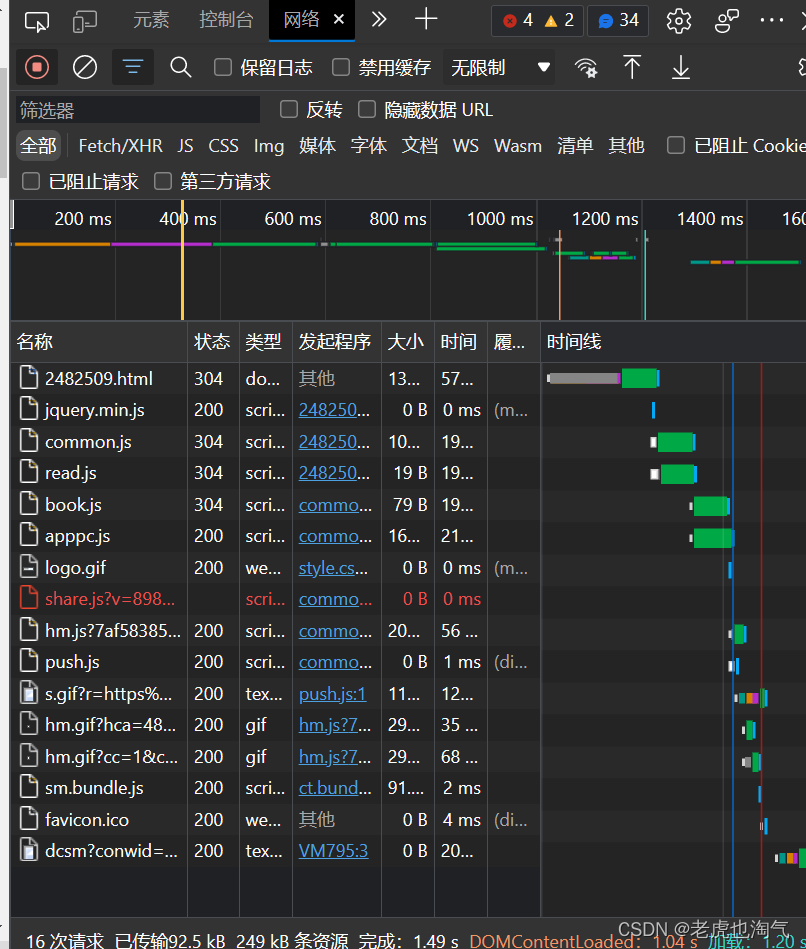
我们可以打开网页右键——检查——网络——Ctrl+r刷新
可以发现如图所示可以看到请求方法是.get方法。
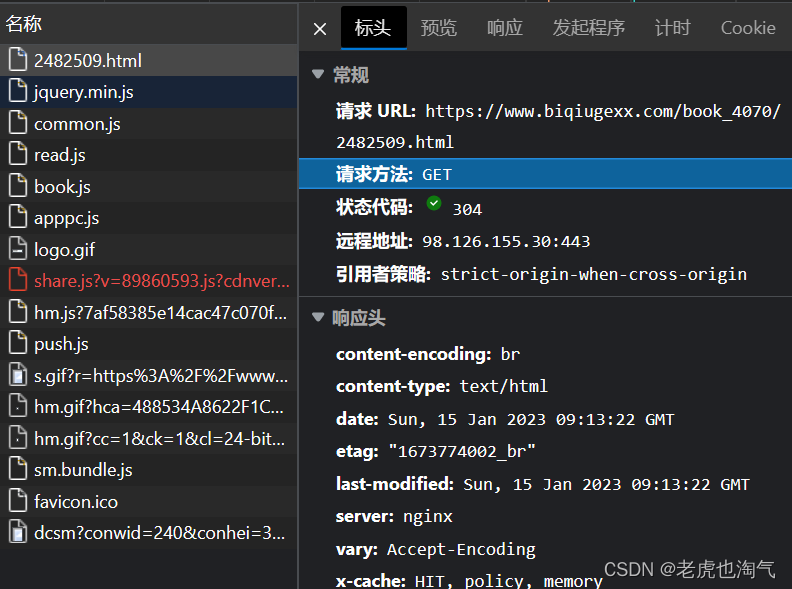
响应信息
print(resp.text)
注意我们平时访问是用浏览器访问但是由于我们编写代码利用python为了让网站认为我们的访问属于正常用户行为和范围为了打入内部我们只能伪装自己。现在去伪装
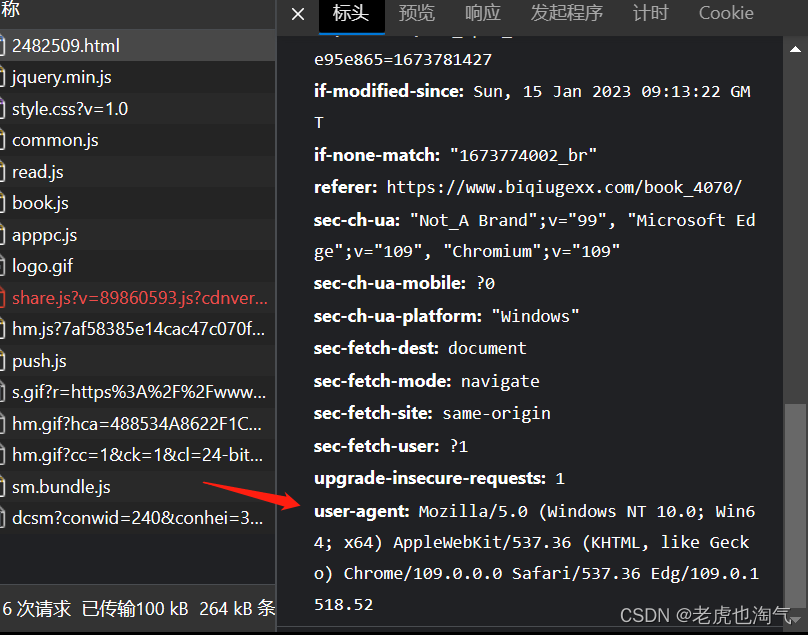
下拉继续找到箭头所指翻译过来叫用户代理简单来说就是表达了我们用的什么电脑系统和什么电脑浏览器访问的网址。
伪装自己
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 Edg/109.0.1518.52'
}
之后完整运行结果如图所示会出现一堆乱码。
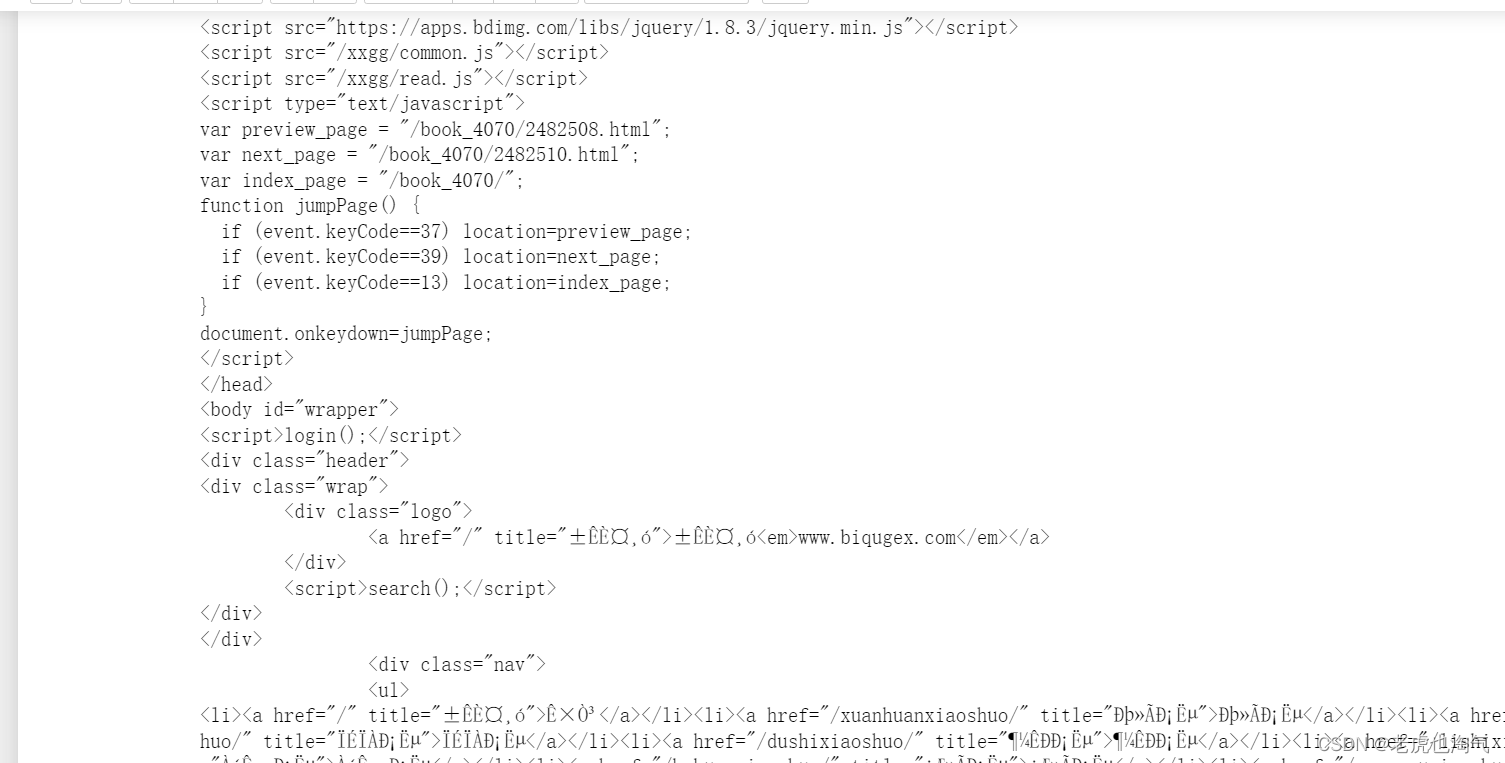
设置编码
# 设置编码
resp.encoding = 'utf-8'

之后即可看到完整信息。但是这并不是我们想要的我们只需要文字不需要那些符号字母。所以下一步我们可以提取文字。
提取文字
这会我们需要新的模块
pip install lxml
安装后导入
# pip install lxml
from lxml import etree
回来网页右键检查看一下效果。会发现文字都在p里面这是我们借助一个拓展程序
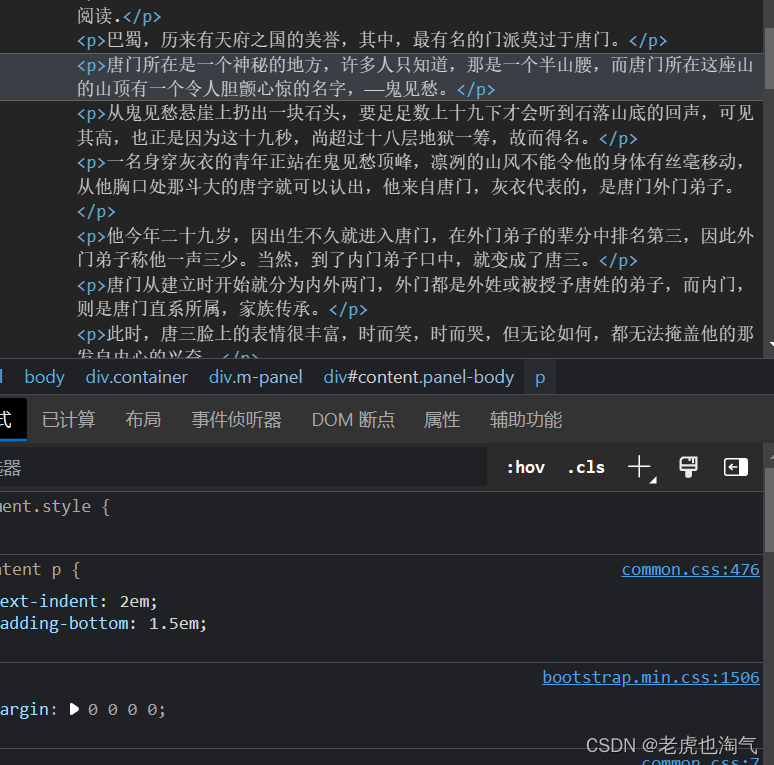
这时我们借助一个拓展程序

没有安装的可以去看这个文章。我们点开这个工具快捷键Ctrl+shift+z

此时我们该写什么呢因为我们在div中所以如图所示输入内容即可
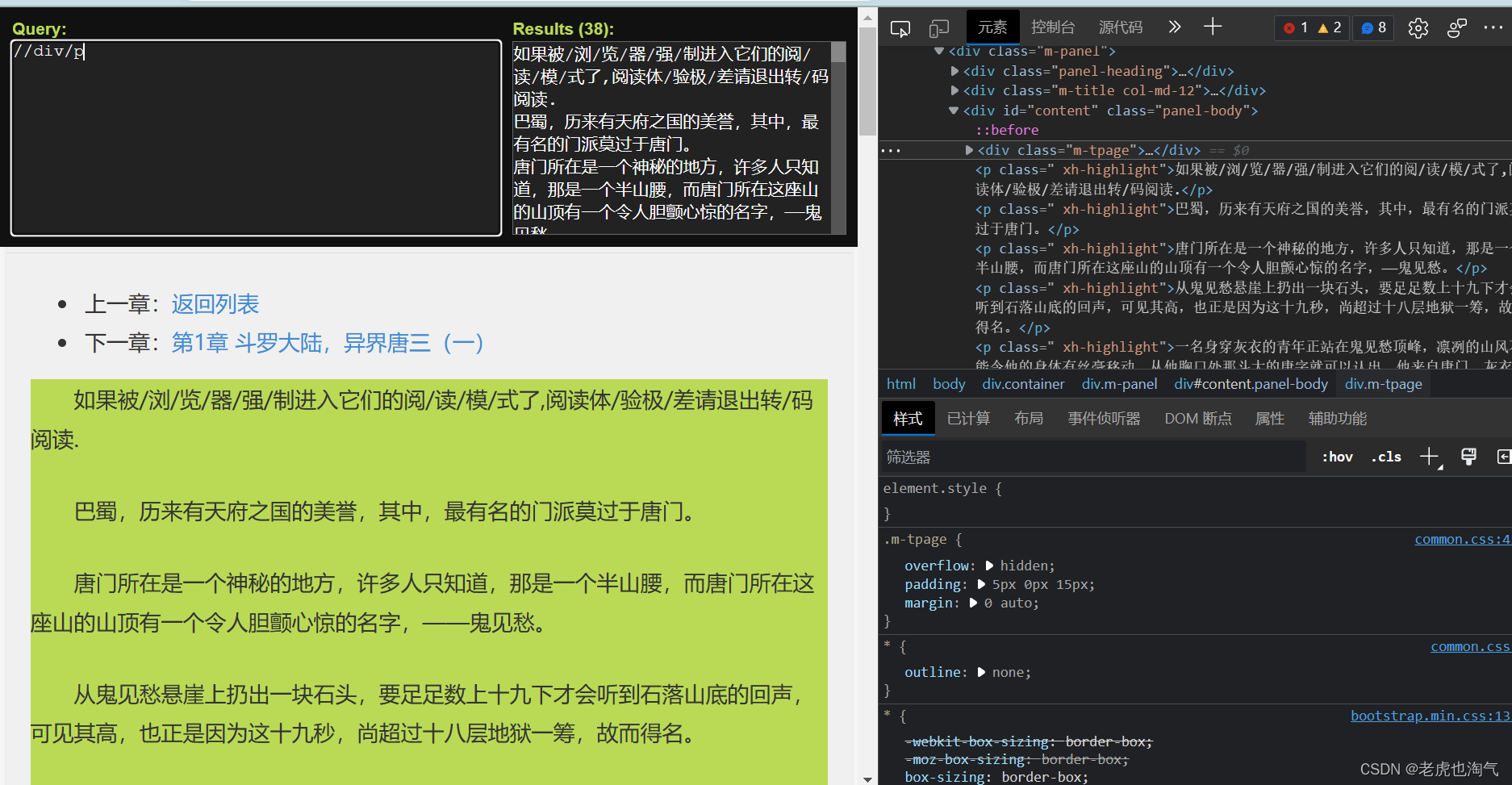
此时我们的文字就提取出来了。然而有些内容我们是不需要的如下图。
输入以下代码。
//div[@class="m-tpage"]/p
获取title信息
//h1/test
到此基本搞定尝试打印结果。
print(info)
print(title)
这是我们发现一堆内容因为没有显示文本内容。

加上text即可
//div[@class="m-post"]/p/text()
之后保存文件。即可实现运行。
完整代码如下
# 怎么发送请求
# pip install requests
import requests
# pip install lxml
from lxml import etree
# 发送给谁
url = 'https://www.93xscc.com/9034/2126907.html'
while True:
# 伪装自己
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 Edg/109.0.1518.52'
}
# 发送请求
resp = requests.get(url,headers=headers)
# 设置编码
resp.encoding = 'utf-8'
# 响应信息
# print(resp.text)
e = etree.HTML(resp.text)
info = '\n'.join(e.xpath('//div[@class="m-post"]/p/text()'))
title = e.xpath('//h1/text()')[0]
url = f'https://www.85xs.cc{e.xpath("//tr/td[2]/a/@href")[0]}'
# print(info)
# print(title)
# 保存
with open('斗罗大陆.txt','w',encoding='utf-8') as f:
f.write(title+'\n\n'+info+'\n\n')
'''
退出循环 break
if url == '/book/douluodalu1/'
'''