Introduction to Multi-Armed Bandits——01 Scope and Motivation
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
Introduction to Multi-Armed Bandits——01 Scope and Motivation
参考资料
- Slivkins A. Introduction to multi-armed bandits[J]. Foundations and Trends® in Machine Learning, 2019, 12(1-2): 1-286.
- 项目地址 https://github.com/yijunquan-afk/bandit-learning
Bandit算法学习[网站优化]偏实战而本专栏偏理论学习。
Multi-armed bandits是一个非常简单强大的算法框架我们接下来从三个具体的例子进行学习
-
新闻网站
当一个新用户到达时网站选取一个文章标题来显示观察用户是否点击这个标题。该网站的目标是最大限度地提高总点击量。
-
动态定价
一家商店正在销售一种数字商品例如一个应用程序或一首歌。当一个新顾客到来时商店选择一个提供给这个顾客的价格。顾客购买或不购买然后离开。商店的目标是使总利润最大化。
-
投资
每天早上你选择一只股票然后投资1美元。在这一天结束的时候你观察每只股票的价值变化。目标是使总财富最大化。
Multi-armed bandits结合了这些例子(以及许多其他例子)。在基本版本中一个算法有 K K K 种可能的动作(action)可供选择也就是臂(arm) 和T轮。在每一轮中算法选择一只臂并为这只臂收集奖励(reward)。奖励是独立地从某种分布中提取的这种分布是固定的即只取决于所选择的臂但不为算法所知。

在基本模型中算法在每一轮之后都会观察所选臂的奖励但不会观察其他可能被选中的臂。因此算法通常需要探索(explore)尝试不同的臂以获得新的信息。需要有一个探索和利用exploration and exploitation之间的权衡根据现有信息做出最佳的近期决定。这种权衡在许多应用场景中都会出现在Multi-armed bandits中至关重要。从本质上讲该算法努力学习哪些臂是最好的同时不花太多的时间去探索。
一、多维问题空间
Multi-armed bandits是一个巨大的问题空间有许多的维度。接下来我们将讨论其中的一些建模维度。
1.1 辅助反馈(Auxiliary feedback)
在每一轮之后除了所选臂的奖励之外算法还能得到什么反馈?算法是否观察到其他臂的奖励?下面是一些例子:

我们将反馈类型分为三类:
-
bandit 反馈
算法只能观察到所选臂的奖励无法看到其他臂的。
-
完全反馈
算法可以观察到所有可能被选中的臂的奖励。
-
部分反馈
算法除了能观察到所选臂的奖励还能观察到其他信息但是不总是等同于完全反馈。
我们主要关注bandit反馈的问题还涵盖了一些关于完全反馈的基本结果。部分反馈有时出现在扩展和特殊情况下可用于提高性能。
1.2 奖励模型
奖励如何产生有以下几种方式
-
独立同分布奖励
每只臂的奖励是独立于固定分布的这取决于臂而不是轮次 t t t。
-
对抗性奖励
奖励可以是任意的就好像它们是由试图愚弄算法的“对手adversary”选择的。对手可能无视算法的选择oblivious或者对算法的选择是自适应的adaptive。
-
被限制的对手
奖励是由对手选择的该对手受到一些限制例如每只臂的奖励从一轮到另一轮不能有太大变化或者每只臂的奖励最多只能变化几次或者奖励的总变化是有上限的。
-
随机过程奖励
决定奖励的臂的状态随着时间的推移演变为一个随机过程random process例如马尔可夫链。在特定回合中的状态转换可能取决于算法是否选择了臂。
1.3 上下文
算法在选择行动之前可能会观察一些上下文。这样的上下文通常包含当前用户的已知属性并允许进行个性化操作。

现在奖励取决于环境和选择的臂。因此该算法的目标是找到将上下文映射到臂的最佳策略policy。
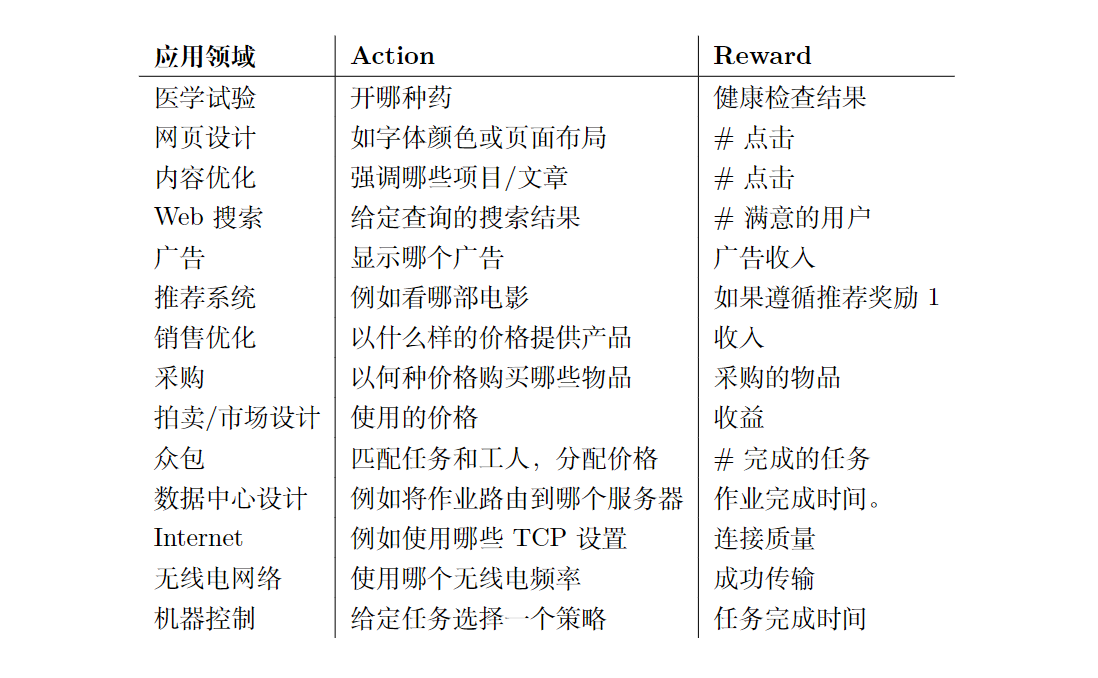
二、应用领域
MAB应用在各种领域举例如下