

字节跳动安全Ai挑战赛-基于文本和多模态数据的风险识别总结
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
本次比赛是最近比较火热的多模态比赛,业务和数据比较接近真实场景,任务比较有趣。我们队伍“石碑村”,队员有华仔、致Great,最终决赛取得第五名成绩,下面主要给大家分享下我们队伍的建模思路和方案,希望能够对大家有所帮助。
1 初赛方案
1.1 赛题描述
抖音APP中的抖音号水印是识别视频搬运的重要依据,很多黑灰产、搬运用户等会给搬运的视频进行低分辨率处理,以逃避搬运审核。根据低分辨率图像识别出该视频中包含的抖音号。
例如下面图片的抖音号为:6xdRyPM5TS

1.2 赛题指标
准确率(acc):输出的抖音号与真实抖音号标签完全一致,则表示该样本正确,否则为不正确。(注:由于低分辨率抖音号识别的人工矫正成本很高,所以本比赛优先使用准确率作为评估标准,而不是使用编辑距离)
1.3 解决方案与思路
我们初赛思路如下:
蒙版匹配:用opencv中传统的蒙版匹配方法,蒙版设置为“抖音号”三个字。根据阈值设置,将匹配比较好的几千张用于训练第二阶段的目标检测模型。

目标检测:用YoloX训练目标检测模型,将检测出来的框用于第三阶段的OCR识别。

OCR:采用CRNN+CTC进行OCR识别。
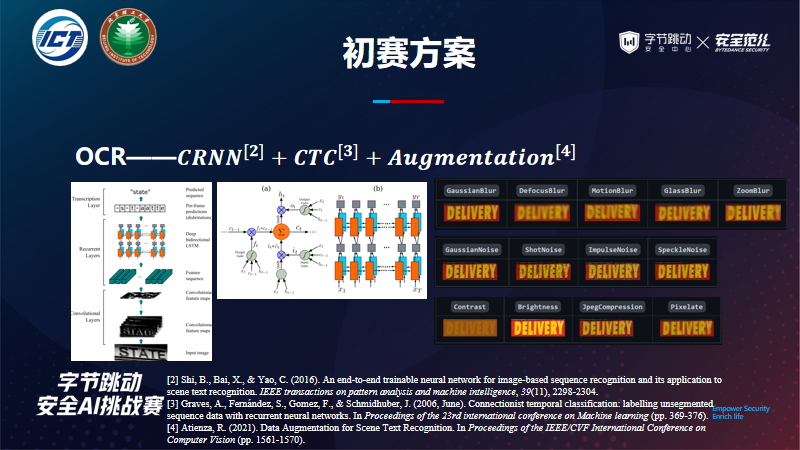
初赛总结是我们采用常规的思路先定位后识别,由于时间太紧,其他方法没时间尝试
开销太大,应该有不用定位的方法。
2 决赛方案
2.1 赛题描述
创作者为视频创作标题或添加文字时,基于种种目的,这些文本信息往往存在不规范的情况。因此,需要一个较为通用的模型对不规范的文本进行文本信息还原。

赛题指标
得分为百分制,分数越高成绩越好:

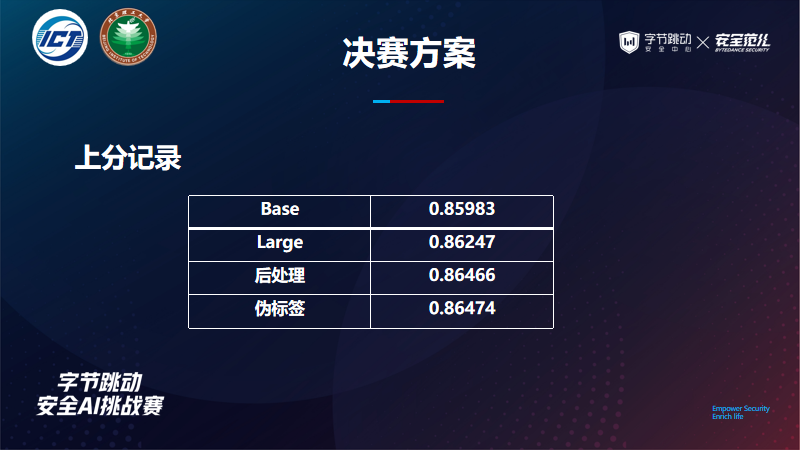
2.2 解决方案与思路
数据预处理
(1) 将文本数据中的emoji替换成还有特定含义的字符串,这里“含义”可以通过以下两种方式获取:
基于训练语料,构建每个emoji的对应词库
基于emojiswitch将emoji转换成中文含义
(2) 然后将emoji替换成中文明文,根据预训练模型分词的特点,我们采用以下的拼接方式:

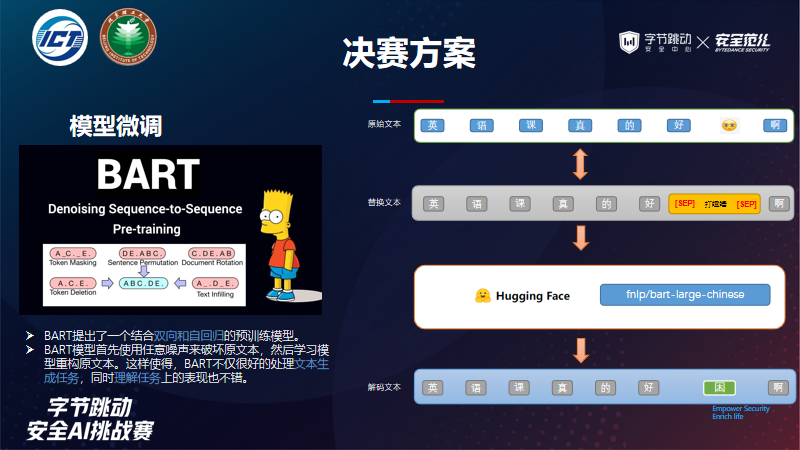
模型微调
基于Bart模型进行emoji翻译任务或者理解为文本生成、文本纠错任务等
后处理
基于原始数据还原被额外修改的字符,大致思路如下:(1)判断emoji中所在位置
(2)根据emoji位置判断前后的字符是否被修改
(3)如果存在额外字符被修改,那么进行还原
3 前排思路
答辩的时候看了下前排的思路,主要提分思路有:
(1)对抗学习,对embedding层添加扰动,基于fgm进行对抗学习
(2)提高模型泛化:ema,rdrop可以提升效果
(3)bart模型的超参数比较重要
(4)还有重要的一环是模型融合:生成任务的话融合方式常见有概率融合和投票融合
4 比赛总结
1.将赛题任务转换为文本生成任务,并且将emoji预先转换为明文,能够提升模型效果;
2.后处理能够提升效果,但是时间不足尝试较少;另外Bart模型基本裸跑,后续提分不足
3. 最后感谢字节跳动提供的数据与比赛任务
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |