

浅谈如何使用Redis实现分布式锁
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
文章目录
- 一、基础版(含自动释放锁)
- 二、改良版(含过期时间)
- 三、进阶版(含唯一性验证)
- 四、单节点版(含Redisson)
- 五、多节点版(含RedLock)
写在前面:
既然已经上升到了分布式场景,那么传统单机下保证线程安全的锁自然就不起作用了,如synchronized、AQS、ThrealLocal等,因为他们锁的都是JVM级别的,分布式项目已经跨越了JVM级别,所以他们都会失效。
一、基础版(含自动释放锁)
使用setnx完成一个最基础的分布式锁
该锁能够对指定的key完成加锁,在执行完业务逻辑后,也能释放对应的锁。
问题:
如果在执行业务代码的过程中,遇到宕机,那么当程序再次启动,对应的锁已经存在,此时就会出现死锁问题。基于此,我们想要达到的目的是,添加的锁能在自动释放,于是就引出了我们的第二版,在添加分布式锁的时候,给指定key增加一个过期时间。
二、改良版(含过期时间)
在设置添加锁和设置过期时间的时候,我们不要使用两条命令去执行,因为如果不是原子操作,依然还会出现第一版中的问题,我们可以使用setIfAbsent的含有过期时间的重载方法。如下面的代码
问题:
我们给锁设置了20S的过期时间,即20S后锁自动释放。试想一下,如果对应的业务逻辑执行了25S,此时会出现什么样的问题?
线程1添加了一个20S的分布式锁,业务执行了25S,即在第20.0001S的时候,线程2又添加了一个分布式锁,在第25.0001S的时候,线程1执行到了finally中的代码,此时他会去释放对应的锁信息。我们要明确的是,如果线程1的锁没有因为锁过期,那么线程2就不可能加锁成功,那么释放的所信息就是线程1的,现在线程1的过期了,那么释放的锁信息就变成了释放线程2的锁信息。当线程2的锁信息释放后,线程3又开始加锁成功,等到线程2来释放锁的时候,就变成释放线程3的锁了。基于此我们不难发现,线程释放错了别人的锁会引发一些的雪崩效应,最终照成业务数据混乱。
如果解决呢?我们可以给锁的value设置一个随机值,在删除锁的时候再进行value的判定,是自己的锁才释放,于是代码可以写成第三版。
三、进阶版(含唯一性验证)
基本代码和第二版一致,仅多了一个使用UUID生成的随机数,并把对应的随机数设置为分布式锁的value,当我们在释放锁的时候,取出对应的value,如果相同再删除,不同则说明过期,直接略过。
问题:
其实上面的解决办法仅仅解决了释放锁的时候不会释放错的问题,并没有在本质上解决锁的并发安全问题。第一点,还是上面的例子,如果线程1在第20.3S的时候才操作了数据,而线程2在第3S的时候就操作了数据,即依然会出现线程安全问题。第二点,虽然我们的代码多了一个value值得唯一性校验,试想一下,线程1执行到finally的第一行equals方法时,判断为true,随即马上去执行delete操作,此时刚好线程1设置的锁信息过期,并且线程2刚好又加锁成功,此时依旧出现了释放错锁的现象。
上面的问题可以归结为两点,第一就是锁的过期时间不能时一个固定值,需要随着业务代码的变化而变化。第二点就是判断锁信息和释放锁信息需要使用一个原子操作。当然,你也可以理解为第一点才是问题的关键。
解决办法,第一点可以在后台能再启动一个线程去监控对应的锁过期时间和业务执行时间就能够达到目的。第二点,redis中可以利用lua脚本去复合执行很多操作,那么我们也就可以使用lua脚本编写判断和删除两个操作的脚本。巧在,我们能想到的别人早就已经想到,Redisson就是基于该原理实现了对应的分布式锁,即第四版代码。
四、单节点版(含Redisson)
引入Redisson,按照其指定的加锁方式即可完成对应的分布式锁的逻辑
观察上面的代码,你会发现和Java自带的AQS锁(ReentrantLock锁是AQS的其中一种实现)很相似,都是先lock,再unlock。在查看了Redisson的底层源码之后,你也就会发现很多东西就是AQS那一套,很多方法名字都是一样的如tryAcquire。不了解AQS底层实现的,小伙伴可以参考我之前的博客:浅谈AQS同步队列(含ReentrantLock加锁和解锁源码分析)
定时任务无限延长锁有效时间代码:
1)判断主线程的锁是否还存在,如果还存在,就延长internalLockLeaseTime(该值就是我们设置的锁的有效时间)时间
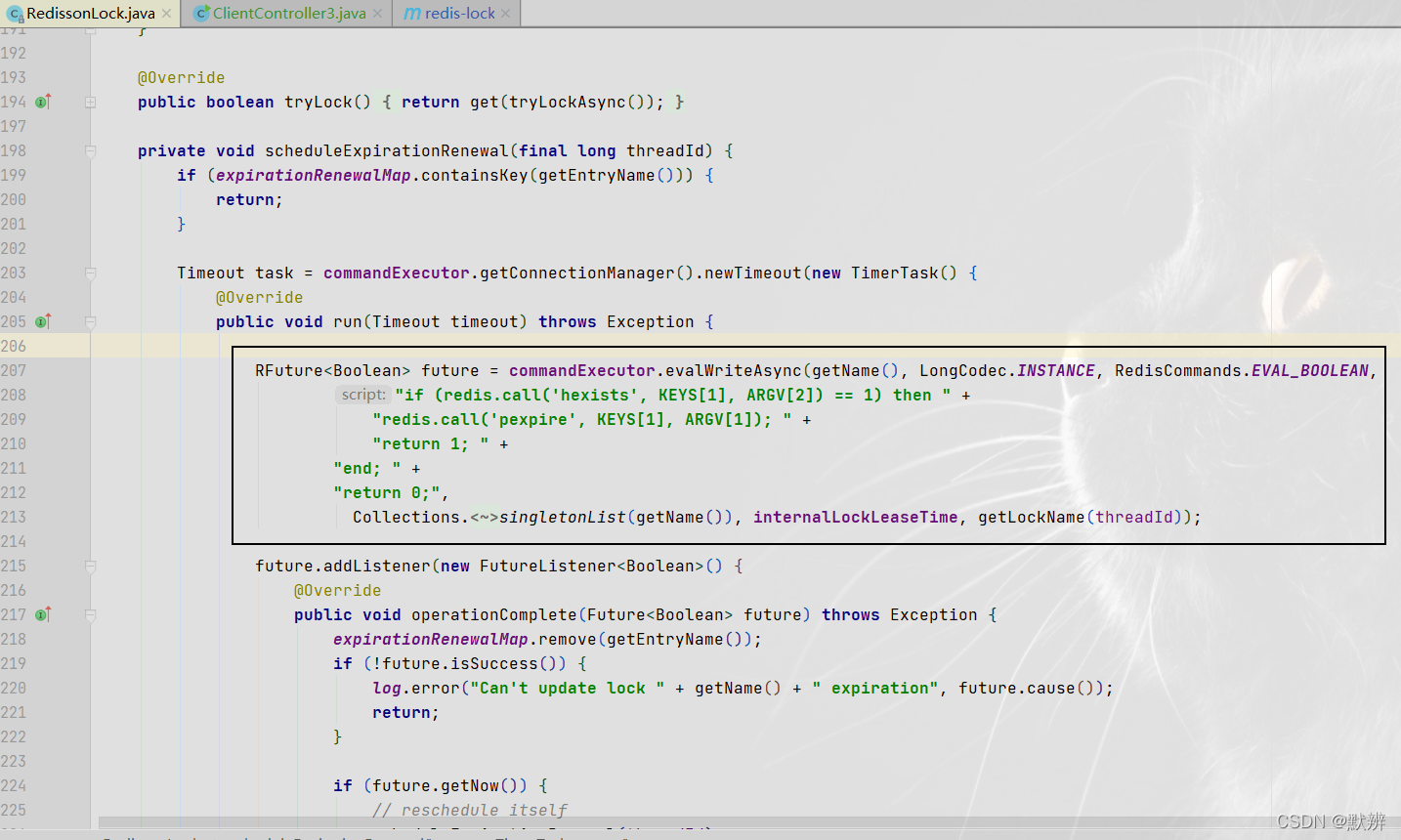
2)如果锁续命成功,则再次递归调用自己,再次完成锁续命

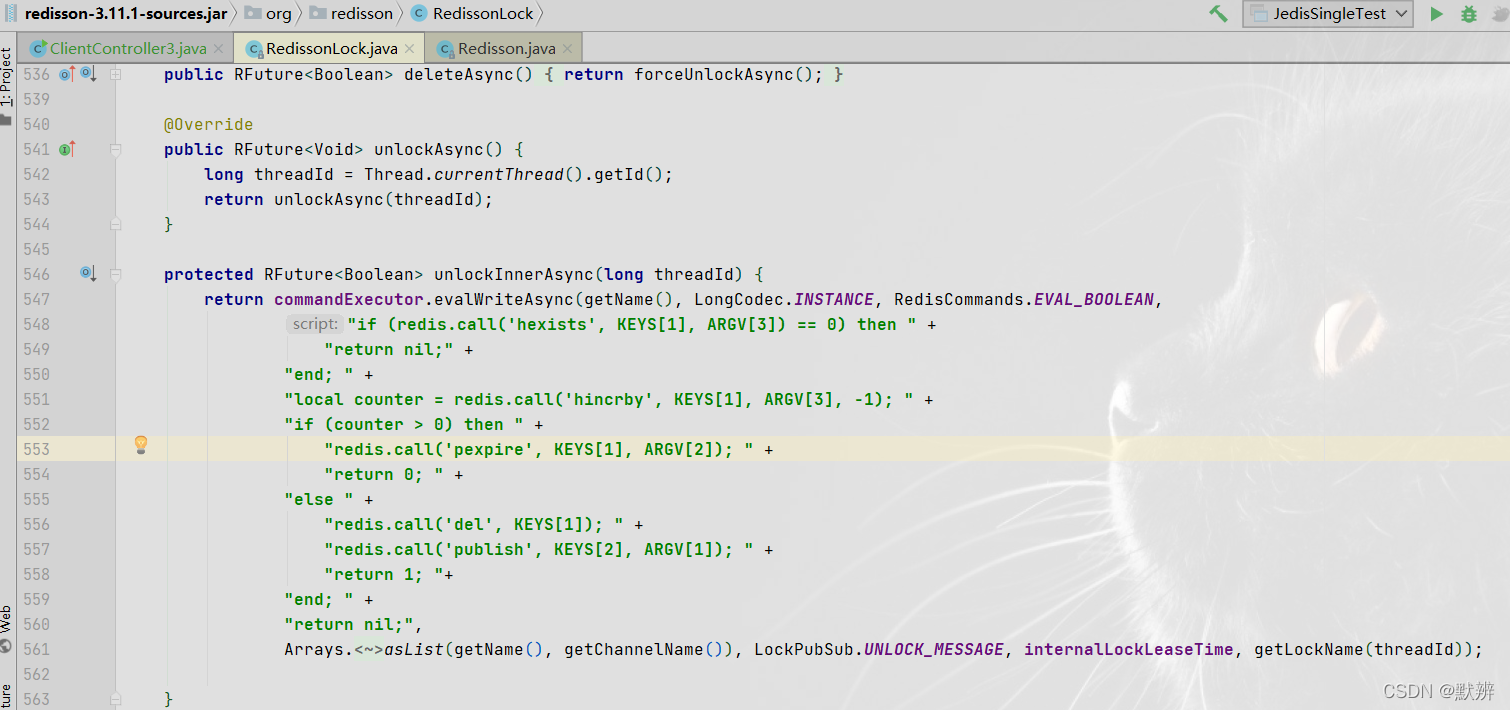
判断锁和释放锁原子化操作代码:
如果不是我们自己添加的锁,发布一个事件,然后直接返回nil。如果是我们添加的锁,就释放对应的锁,再返回 1
补充一张,Redisson底层加锁的大致流程图,如果你是从博客开头看到这里的,我不说,我相信你也能明白下图的逻辑。
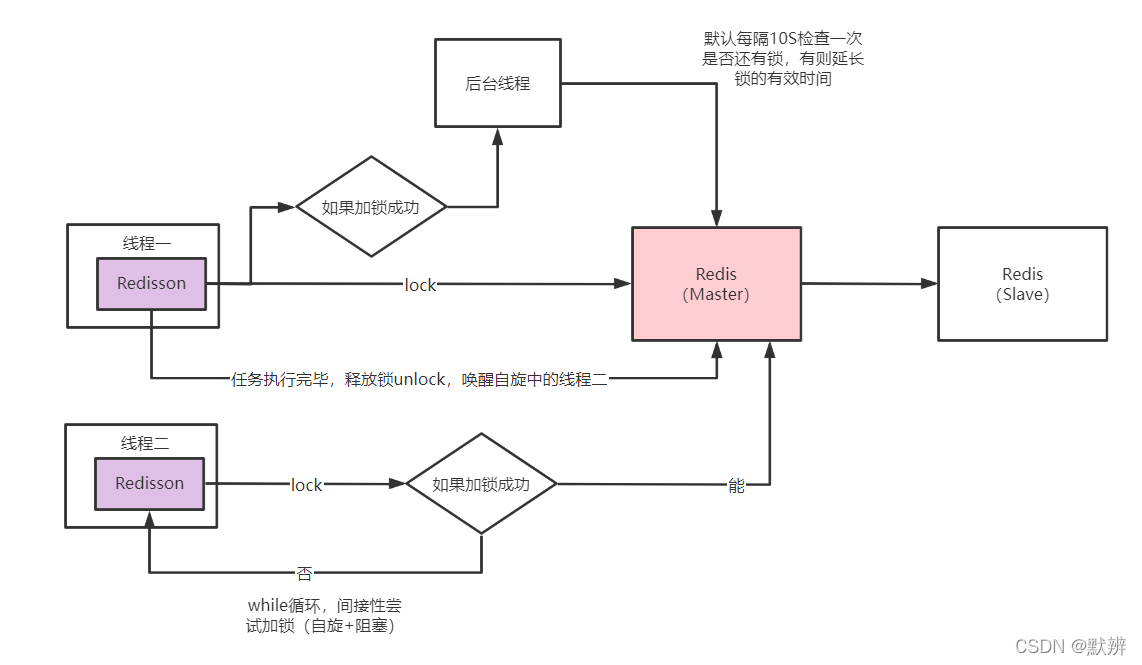
问题:
使用Redisson是能够完成分布式场景下单Redis节点的数据安全问题。但是如果真实的业务为了数据安全,是采用Redis的多个对等单节点架构出现,我们还是会出现数据不一致问题。毕竟目前的逻辑是无法实现对Redis多节点架构同时加锁成功的,此时就引入了我们的RedLock
五、多节点版(含RedLock)
想要实现多个节点下的分布式锁,可以使用RedLock来实现,代码如下
含有三个独立的Redis节点

通过Java API对Redis多节点进行加锁操作,只有当redis节点中半数以上的节点返回加锁成功,才能算此次加锁成功。即线程1中的key在redis1和redis2都加锁成功了,就算redis3因为意外宕机,那么我们也认为此次加锁成功。当线程2发送同样的key的时,此时redis3机器恢复正常,此时redis3能够加锁成功,但是redis1和redis2中已经存在对应的锁信息,即线程2的加锁不成功。
问题:
既然要保证半数节点都能加锁成功,那如果redis挂了两台怎么办?此时就会出现永远加锁不成功的现象,这是我们不愿意看到的。也许你会想到多扩展几台,不可能同时那么多Redis机器一起宕机。确实也有道理,可过多的Redis节点,一来增加了项目的复杂度,二来失去了Redis本来的高可用意义。
含有三个独立的节点,并且每个节点都含有主从关系
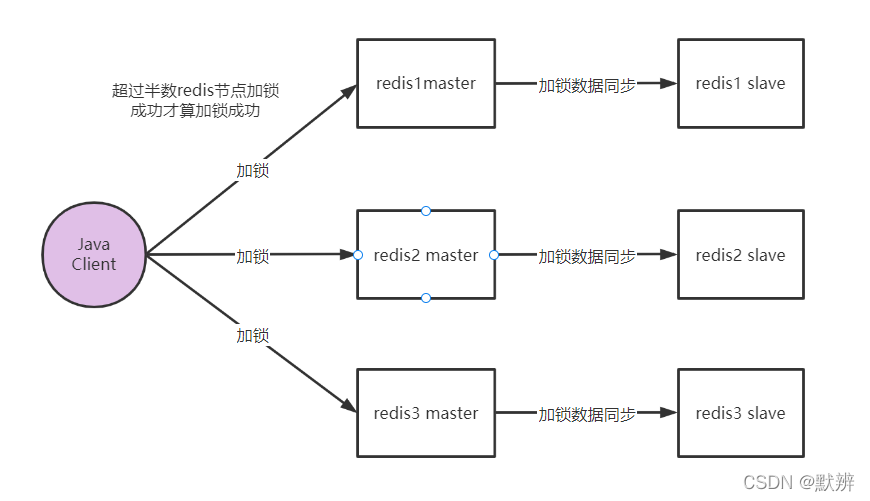
基于此,常规操作就是给每台Redis的master节点配置对应的slave节点,具体流程参考上面的流程图。当master节点接收到对应的加锁信息后,会在master节点完成加锁逻辑,然后返回加锁成功的信息,于此同时会将加锁信息同步给对应的slave节点。以此达到了高可用效果。
问题:
试想一下,线程1进行加锁操作,redis1主节点加锁成功,并且从节点数据同步成功,redis2主节点加锁成功,并且返回给client加锁成功提示,就在它将数据信息同步给slave节点的时候,主节点宕机,redis2的从节点就无法收到对应的线程1的加锁的数据,并且后期redis2的slave节点就被推举为master节点。紧接着线程2又进行加锁操作,此时就会出现redis3节点加锁成功,redis2节点也能够加锁成功,超过半数节点加锁成功,即线程2加锁成功。但此次加锁不应该成功,即还是出现了数据的不一致问题。
补充一个概念:
- 主从:一份数据,一个redis库,为了数据安全,将数据由master节点备份到slave节点;
- 集群:一份数据,多个redis库,将数据拆分为多个数据库存放(类似mysql的分库分表),每个redis数据库只存放一部分数据;
- 对等的节点:多份数据,多个redis库,多个数据库的数据都是全量数据,且数据保持一致,每次操作都会进行三个数据库的操作。
以上的思想和zookeeper实现分布式锁思想相同,也就逐渐的由AP转向了CP(CAP理论: Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可得兼),如果业务场景十分在意数据一致性,那为什么不直接使用zookeeper实现分布式锁呢?既然使用了Redis,势必会在数据一致性上做出让步。
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |