

Spring Boot 项目 - API 文档搜索引擎
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
在线体验 : http://43.139.1.94:9090/index.html
项目 Gitee 链接 : API 文档搜索引擎
1.认识搜索引擎
我们平时查百度, 搜狗的时候, 结果页会显示若干条相关结果 , 每个结果几乎都包含图片, 标题, 描述, 展示 URL以及时间等等.

1.1 搜索引擎的本质
输入一个查询词, 得到若干个结果, 每个搜索结果包含了标题, 描述, 展示 URL , 以及点击 URL...
1.2 实现搜索引擎的核心思路
实现过程中, 我们主要考虑的问题有两个 :
查询出哪些网页和查询词具有一定的相关性.
如何高效的进行搜索.
==============
解决思路 >>
方案一 : 暴力检索
每当用户输入一个查询词, 就拿着这个查询词去所有的网页中遍历一次, 查找出包含该查询词的所有文档.
显然这个方案不满足高效检索, 随着文档数量的增多, 搜索的开销会线性增长.
方案二 : 倒排索引 + 正排索引
倒排索引是一种专门针对搜索引擎场景而设计的数据结构.
因为当前这个项目只是针对 Java 官方文档设计的一个搜索引擎, 总共也就一万多条记录, 所以我们可以提前将 Java官方文档下载到本地, 然后对其进行预处理. 此处的预处理就是构建正排, 倒排索引.
1. 正排索引 : 一个文档包含了哪些词, 描述了 一个文档的基本信息, 包括文档标题, 文档正文, 文档 URL 以及文档标题和正文的分词结果.
2. 倒排索引 : 查询词在哪些文档中出现, 描述了 一个词的基本信息, 包括这个词分别被哪些文档引用, 这个词在该文档中的相关性/权重, 以及这个词出现的位置等.
Java 官方文档线上链接 : https://docs.oracle.com/javase/8/docs/api/index.html
Java 官方文档下载链接 : https://www.oracle.com/technetwork/java/javase/downloads/index.html
2. Java 官方文档的搜索引擎
2.1 项目核心模块
索引模块 : 扫描下载到的文档, 分析数据内容构建正排+倒排索引, 并保存到文件中.
搜索模块: 加载索引. 根据输入的查询词, 基于正排+倒排索引进行检索, 得到检索结果.
web模块: 编写一个简单的页面, 展示搜索结果. 点击搜索结果能跳转到对应的 Java API 文档页面.
2.2 创建 SpringBoot 项目
创建项目具体流程就不再赘述. 引入常用的依赖 : devtools, lombok, Spring Web 以及项目中需要使用到的分词依赖 : ansj.
2.3 认识分词
分词操作是项目中的一个核心操作, 此处仅针对 Java官方文档进行分词, 就只需要考虑英文分词即可. 项目中使用现成的分词库 ansj.
分词库的简单使用示例 : https://blog.csdn.net/weixin_44112790/article/details/86756741
<dependency>
<groupId>org.ansj</groupId>
<artifactId>ansj_seg</artifactId>
<version>5.1.6</version>
</dependency>代码示例 :
public class TestAnsj {
public static void main(String[] args) {
String str = "Write a search engine blog today";
List<Term> terms = ToAnalysis.parse(str).getTerms();
for (Term term : terms) {
System.out.print(term.getName() + "/");
}
}
}分词结果 (分词库会将所有单词都转成小写):
write/ /a/ /search/ /engine/ /blog/ /today/
2.4 实现索引模块
2.4.1 实现 Parser 类
parser 主要做的工作有 :
构建一个可执行程序.
读取 HTML 文档, 制作并生成索引数据.
public class Parser {
// 指定一个加载文档的路径
private static final String INPUT_PATH = "D:/software-download/Java-Official-document/jdk-8u351-docs-all/docs/api";
// 整个 Parser 类的入口
public void run() {
long beg = System.currentTimeMillis();
System.out.println("索引制作开始!");
// 1. 根据指定的本地文档路径, 枚举出该路径中所有的 html 文件.
ArrayList<File> fileList = new ArrayList<>();
enumFile(INPUT_PATH, fileList);
// 2. 针对这些 html 文件的路径, 打开文件, 读取文件内容, 并解析, 并构建索引.
for(File f : fileList) {
System.out.println("开始解析: " + f.getAbsolutePath());
// 解析每个 HTML 文件
parseHTML(f);
}
// 3. TODO 将在内存中构造好的索引数据结构, 保存到指定文件中.(涉及 Index 类)
long end = System.currentTimeMillis();
System.out.println("索引制作完成! 消耗时间: " + (end - beg));
}
/**
* 枚举指定路径下的所有文件
* @param rootPath 从哪个目录开始进行递归遍历
* @param fileList 递归得到的结果集
*/
private void enumFile(String rootPath, ArrayList<File> fileList) {
File rootFile = new File(rootPath);
// 获取到 rootPath 当前目录下所包含的文件/目录
File[] files = rootFile.listFiles();
for(File f : files) {
// 如果 f 是一个目录, 就进行递归
// 如果 f 是一个普通文件, 就加入到 fileList 中
if(f.isDirectory()) {
enumFile(f.getAbsolutePath(), fileList);
} else {
// endsWith() 表示字符串以什么结尾
if(f.getAbsolutePath().endsWith(".html")) {
fileList.add(f);
}
}
}
}
private void parseHTML(File f) {
// 1. 解析出 HTML 文件的标题
String title = parseTitle(f);
// 2. 解析出 HTML 文件的 URL
String url = parseUrl(f);
// 3. 解析出 HTML 文件的正文(后续再处理描述)
String content = parseContent(f);
// String content = parseContentByRegex(f); 后续记得要将其改成正则表达式的版本.
// 4. TODO 把解析出来的 HTML 文件的具体信息加入到索引中.(涉及 Index 类)
}
private String parseTitle(File f) {
// 获取标题不必读取到 <title> 标签中的内容, 只需拿文件名即可
String name = f.getName();
return name.substring(0, name.length() - ".html".length());
}
//Java API 文档存在两份 : 线上文档,本地文档
// 这两文件路径的后缀很相似, 因此就可以拿着这两个路径的关键部分进行拼接, 就可以得到线上文档的网络路径了
private String parseUrl(File f) {
// 线上文档
String part1 = "https://docs.oracle.com/javase/8/docs/api";
// 线下文档
String part2 = f.getAbsolutePath().substring(INPUT_PATH.length());
String result = (part1 + part2).replaceAll("\\\\", "/");
return result;
}
private String parseContent(File f) {
// 按照字符来读取, 以正文中标签的 < 和 > 作为控制拷贝数据的开关
try(FileReader fileReader = new FileReader(f)) {
// 拷贝数据的开关
boolean isCopy = true;
// 用来保存结果
StringBuilder content = new StringBuilder();
while(true) {
// 一次读一个字符, 返回值为 int 是为了处理一些非法情况, 如果读到了末尾, 就会返回 -1
int ret = fileReader.read();
if (ret == -1) {
// 文件读完了
break;
}
char c = (char) ret;
if(isCopy) {
// 开关处于打开状态
if(c == '<') {
// 遇到 <, 就关闭开关
isCopy = false;
continue;
}
// 优化 : 将换行符转换成空格
if(c == '\n' || c == '\r') {
c = ' ';
}
// 其他字符, 就进行拷贝
content.append(c);
} else {
// 开关处于关闭状态
if(c == '>') {
// 遇到 >, 就关闭开关
isCopy = true;
}
}
}
return content.toString();
} catch (IOException e) {
e.printStackTrace();
}
return "";
}
}【Parser 类的一些实现细节】
🍁parseTitle() 方法
为什么直接拿文件名作为标题 >>>


当我们以记事本的方式打开每一个 html 文件时, 发现title 标签中的内容其实和文件名没啥区别, 只不过多了一个 (Java Platform SE 8), 我们只需要标题保持一致即可, 其他的都不重要.
🍁parseContent() 方法
1. 对于标签中间的正文, 有一个特点, 以 < 开头, 以 > 结尾, 于是就可以拿 < > 作为控制拷贝的开关, 当然不排除会拷贝到 <script> 标签中间的无关正文, 这个后面再处理.
2. 其次就是拷贝的时候, 碰见换行, 我们最好将其转换成空格, 否则大量的换行看起来就会不美观.
🍁parseUrl() 方法
Java API文档存在两份 >>
线上文档 : https://docs.oracle.com/javase/8/docs/api
线下文档 : D:/software-download/Java-Official-document/jdk-8u351-docs-all/docs/api/ArrayList.html
解析 URL 的目的就是为了实现页面点击能够跳转到对应的线上文档, 而线上文档和线下文档的 URL 有着相似的后缀, 于是就可以截取出线下文档的后半部分与线上文档的前半部分进行拼接, 就得到了对应的线上文档的链接.
2.4.2 实现 Index 类
Index 类的主要方法 :
1.给定一个 docId, 在正排索引中, 查询文档的详细信息.
2.给定一个词, 在倒排索引中, 查询哪些文档和这个词相关.
3. 往索引中新增一个文档.(正排 + 倒排)
4. 把内存中的索引结构保存到磁盘中.
5. 把磁盘中的索引数据加载到内存中.
2.4.2.1 Index 类大致框架
public class Index {
// 使用数组下标表示 docId 【正排索引】
private ArrayList<DocInfo> forwardIndex = new ArrayList<>();
// 使用 哈希表 来构建倒排索引 【倒排索引】
// key 表示词, value 就是一组和这个词关联的文章
private HashMap<String, ArrayList<Weight>> invertedIndex = new HashMap<>();
// 1. 给定一个 docId, 在正排索引中, 查询文档的详细信息. O(1)
public DocInfo getDocInfo(int docId) {
return null;
}
// 2. 给定一个词, 在倒排索引中, 查询哪些文档和这个词相关. O(1)
public List<Weight> getInverted(String term) {
return null;
}
// 3. 往索引中新增一个文档.(正排 + 倒排)
public void addDoc(String title, String url, String content) {
}
// 4. 把内存中的索引结构保存到磁盘中.
public void save() {
}
// 5. 把磁盘中的索引数据加载到内存中.
public void load() {
}
}@Data
public class DocInfo {
private int docId;
private String title;
private String content;
private String url;
}2.4.2.2 创建 Weight 类
@Data
public class Weight {
private int docId;
// weight 表示文档和词之间的 "相关性" (权重)
private int weight;
}创建这个类是用于在倒排索引中, 表示文档与词的相关性的. 倒排索引中的倒排拉链就是一个个的 Weight 对象.
2.4.2.3 实现 getDocInfo 和 getInverted
// 1. 给定一个 docId, 在正排索引中, 查询文档的详细信息. O(1)
public DocInfo getDocInfo(int docId) {
return forwardIndex.get(docId);
}
// 2. 给定一个词, 在倒排索引中, 查询哪些文档和这个词相关. O(1)
public List<Weight> getInverted(String term) {
return invertedIndex.get(term);
}2.4.2.4 实现构建索引 - addDoc
public void addDoc(String title, String url, String content) {
// 构建正排索引
DocInfo docInfo = buildForward(title,url, content);
// 构建倒排索引
buildInverted(docInfo);
}🍁构建正排索引 >>
private DocInfo buildForward(String title, String url, String content) {
DocInfo docInfo = new DocInfo();
docInfo.setTitle(title);
docInfo.setUrl(url);
docInfo.setContent(content);
// 数组下标 -> docId
docInfo.setDocId(forwardIndex.size());
forwardIndex.add(docInfo);
return docInfo;
}🍁构建倒排索引 >>
倒排索引的大致结构 (后面再合并权重)

从倒排索引的结构中可以看出来, 想要构建倒排索引, 我们要做的工作有 :
1. 针对文档标题进行分词, 遍历分词结果, 并统计每个词出现的次数.
2. 针对文档正文进行分词, 遍历分词结果, 并统计每个词出现的次数.
3. 把上面的结果汇总到一个 HashMap 中, 最终文档的权重, 就按照公式 ->
weight = 标题权重 * 10 + 正文权重 . 来计算.(拍脑门来的)
4. 遍历汇总后的 HashMap , 依次更新倒排索引中的结构.
上述第四个步骤, 最好结合上图看代码, 代码有点绕.
private void buildInverted(DocInfo docInfo) {
class WordCnt {
// 表示这个词在标题中出现的次数
public int titleCount;
// 表示这个词在正文中出现的次数
public int contentCount;
}
// 用于统计词频
HashMap<String, WordCnt> wordCntHashMap = new HashMap<>();
// 1. 针对文档标题进行分词 [分词库会帮我们将每个词都转成小写]
List<Term> terms = ToAnalysis.parse(docInfo.getTitle()).getTerms();
// 2. 遍历标题的分词结果, 统计每个词出现的次数, 并汇总到 HashMap 中
for(Term term : terms) {
// 拿到每一个词
String word = term.getName();
WordCnt wordCnt = wordCntHashMap.get(word);
if(wordCnt == null) {
// 不存在, 就创建一个新的键值对插入到 HashMap 中, 并把 titleCount 设为 1
WordCnt newWordCnt = new WordCnt();
newWordCnt.titleCount = 1;
newWordCnt.contentCount = 0;
wordCntHashMap.put(word, newWordCnt);
} else {
// 存在, 就找到对应的值, 然后直接将 titleCount += 1
wordCnt.titleCount += 1;
}
}
// 3. 针对正文页进行分词
terms = ToAnalysis.parse(docInfo.getContent()).getTerms();
// 4. 遍历正文的分词结果, 统计每个词出现的次数, 并汇总到 HashMap 中
for(Term term : terms) {
String word = term.getName();
WordCnt wordCnt = wordCntHashMap.get(word);
if(wordCnt == null) {
// 不存在, 就创建一个新的键值对插入到 HashMap 中, 并把 contentCount 设为 1
WordCnt newWordCnt = new WordCnt();
newWordCnt.titleCount = 0;
newWordCnt.contentCount = 1;
wordCntHashMap.put(word, newWordCnt);
} else {
// 存在, 就找到对应的值, 然后直接将 contentCount += 1
wordCnt.contentCount += 1;
}
}
// 4. 遍历 HashMap, 依次来更新倒排索引中的结构 [最好结合图中倒排索引的结构来看代码]
for(Map.Entry<String, WordCnt> entry : wordCntHashMap.entrySet()) {
// 先拿着词去倒排索引中查找, 看是否有倒排拉链 - Weight数组
List<Weight> invertedList = invertedIndex.get(entry.getKey());
if(invertedList == null) {
// 如果倒排拉链为空, 就创建一个新的键值对 (新的 list, Weight 对象), 加入到 HashMap 中
ArrayList<Weight> newInvertedList = new ArrayList<>();
Weight weight = new Weight();
weight.setDocId(docInfo.getDocId());
// 权重计算公式 : 标题出现次数 * 10 + 正文出现次数
weight.setWeight(entry.getValue().titleCount * 10 + entry.getValue().contentCount);
newInvertedList.add(weight);
invertedIndex.put(entry.getKey(), newInvertedList);
} else {
// 如果倒排拉链不为空 , 就创建一个 Weight 对象, 加入到倒排拉链中
Weight weight = new Weight();
weight.setDocId(docInfo.getDocId());
// 权重计算公式 : 标题出现次数 * 10 + 正文出现次数
weight.setWeight(entry.getValue().titleCount * 10 + entry.getValue().contentCount);
invertedList.add(weight);
}
}
}2.4.2.5 实现保存索引到磁盘
为什么要将索引保存到磁盘>>
构建索引过程, 其实是非常耗时的, 如果启动服务器的时候才构建索引, 整个服务器将会被拖慢很多很多, 因此我们不应该在服务器启动的时候才构建索引. 所以我们需要将这些耗时的操作, 单独的去执行, 执行完了之后, 再让线上的服务器直接加载这个构造好的索引.
具体如何进行保存 >>
保存到本地磁盘, 可以以文本文件的格式进行保存, 而文本文件无非就是一些二进制数据, 也就是一些字符串, 所以我妈妈就需要把内存中构造好的索引结构, 变成一个字符串, 然后写文件即可. 这个操作也叫作序列化. 相应的加载索引到内存也叫作反序列化. 此处使用的是 Json 库进行序列化操作.
// 用于保存索引和加载索引, 也叫作序列化和反序列化操作
private ObjectMapper objectMapper = new ObjectMapper();
// 4. 把内存中的索引结构保存到磁盘中.
public void save() {
// 使用两个文件, 分别保存正排索引和倒排索引
long beg = System.currentTimeMillis();
System.out.println("保存索引开始!");
// 1. 判定一下索引对应的目录是否存在, 不存在就创建
File indexPathFile = new File(INDEX_PATH);
if(indexPathFile.exists()) {
indexPathFile.mkdirs();
}
// 2.设置保存的文件名
File forwardIndexFile = new File(INDEX_PATH + "forward.txt");
File invertedIndexFile = new File(INDEX_PATH + "inverted.txt");
// 3. 将正排索引和倒排索引序列化到指定目录下的文件中
try {
objectMapper.writeValue(forwardIndexFile, forwardIndex);
objectMapper.writeValue(indexPathFile, invertedIndex);
} catch(IOException e) {
e.printStackTrace();
}
long end = System.currentTimeMillis();
System.out.println("保存索引结束! 消耗时间: " + (end - beg));
}2.4.2.6 实现加载索引到内存
因为我们保存索引的时候, 是以 Json格式的字符串进行保存的, 那么加载索引到内存时, 就需要把这个 Json格式的字符串, 构造成一个具体对象的类型.
JackSon 专门提供了一个辅助的工具类 - TypeReference<>
// 5. 把磁盘中的索引数据加载到内存中.
public void load() {
long beg = System.currentTimeMillis();
System.out.println("加载索引开始!");
// 1. 设置加载索引的路径
File forwardIndexFile = new File(INDEX_PATH + "forward.txt");
File invertedIndexFile = new File(INDEX_PATH + "inverted.txt");
try {
// 2. 从磁盘中进行反序列化操作, 将索引结构加载到内存
forwardIndex = objectMapper.readValue(forwardIndexFile,
new TypeReference<ArrayList<DocInfo>>() {});
invertedIndex = objectMapper.readValue(invertedIndexFile,
new TypeReference<HashMap<String, ArrayList<Weight>>>() {});
} catch(IOException e) {
e.printStackTrace();
}
long end = System.currentTimeMillis();
System.out.println("加载索引结束! 消耗时间: " + (end - beg));
}2.4.3 完善 Parser 类中的保存索引和新增索引
Parser 类和 Index 类之间的关系 >>
当前 Parser 类相当于制作索引的入口, 对应一个可执行程序, 而 Index 相当于实现了索引的数据结构, 提供了一些 api , Index 类要给 Parser 类进行调用, 才能完成整个制作索引的功能.
2.4.3.1 新增 Index 实例
public class Parser {
// .... 省略相同代码
private Index index = new Index();
// .... 省略相同代码
}2.4.3.2 完善 Parser 类中的新增索引
private void parseHTML(File f) {
// .... 省略相同代码
index.addDoc(title,url,content);
}2.4.3.3 完善 Parser 类中的保存索引
public void run() {
// .... 省略相同代码
index.save();
// .... 省略相同代码
}2.4.4 验证索引模块
2.4.4.1 验证保存索引
在 Parser 类中添加 main 方法 >>
public static void main(String[] args) {
Parser parser = new Parser();
parser.run();
}运行程序 >>
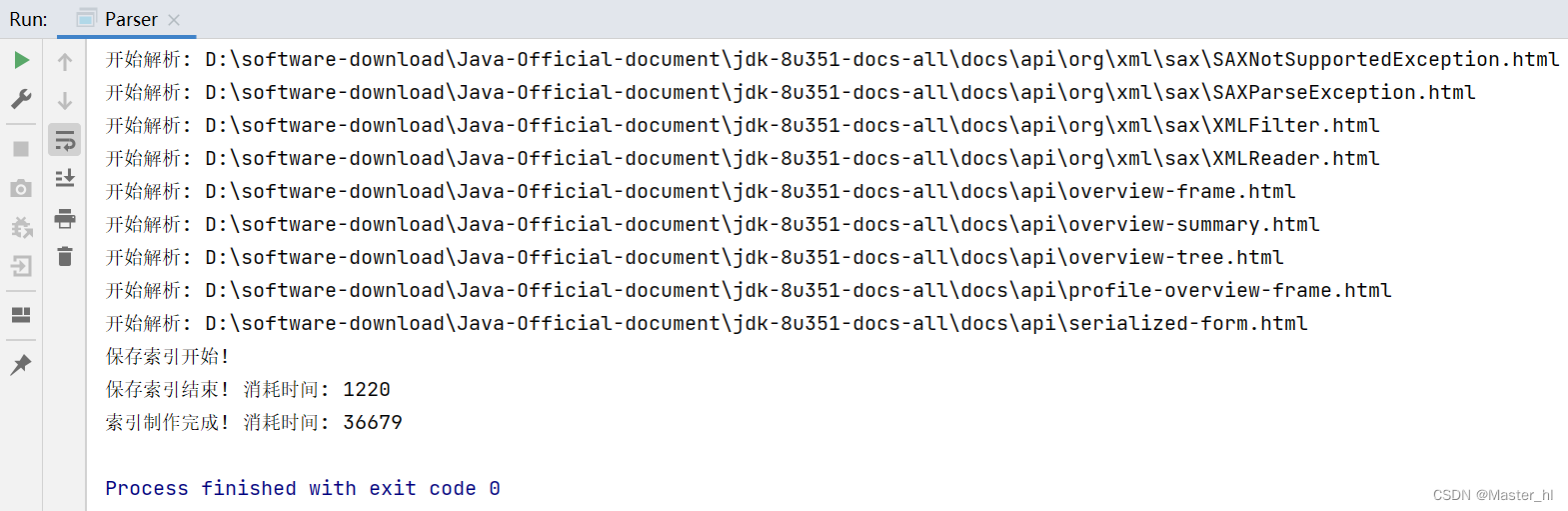
Parser 类运行结果
在本地 INDEX_PATH 对应的目录进行查看 >>
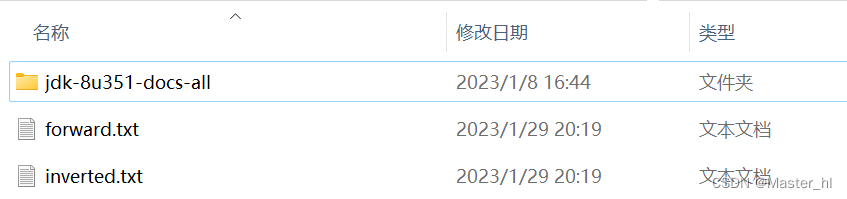
保存索引得到的文件
把 txt 文件拖到 VSCode 中查看索引结构 >> 符合预期!!

forward.txt

inverted.txt
2.4.4.2 验证加载索引
给 Index 类添加 main 方法 >>
public static void main(String[] args) {
Index index = new Index();
index.load();
System.out.println("索引加载完成!");
}给最后一个打印语句加上断点进行调试 >>
查看正排索引结构 :

查看倒排索引结构 :

2.4.5 优化制作索引的性能
关于性能优化 :
要想优化一段程序的性能, 就需要先通过测试的手段, 才能找到其中的 "性能瓶颈". 这就好比我们去医院看病, 医生问都不问, 直接上来就给你开药, 那能行吗 ? 所以说抛开测试谈性能优化, 就是 "耍流氓".
制作索的性能就是 run() 方法的性能, 而 run() 方法又分为: 枚举文件, 遍历文件, 保存文件三个主要的步骤. 于是可以分别给这三个步骤加上时间戳, 看看最耗时的步骤是哪一个.
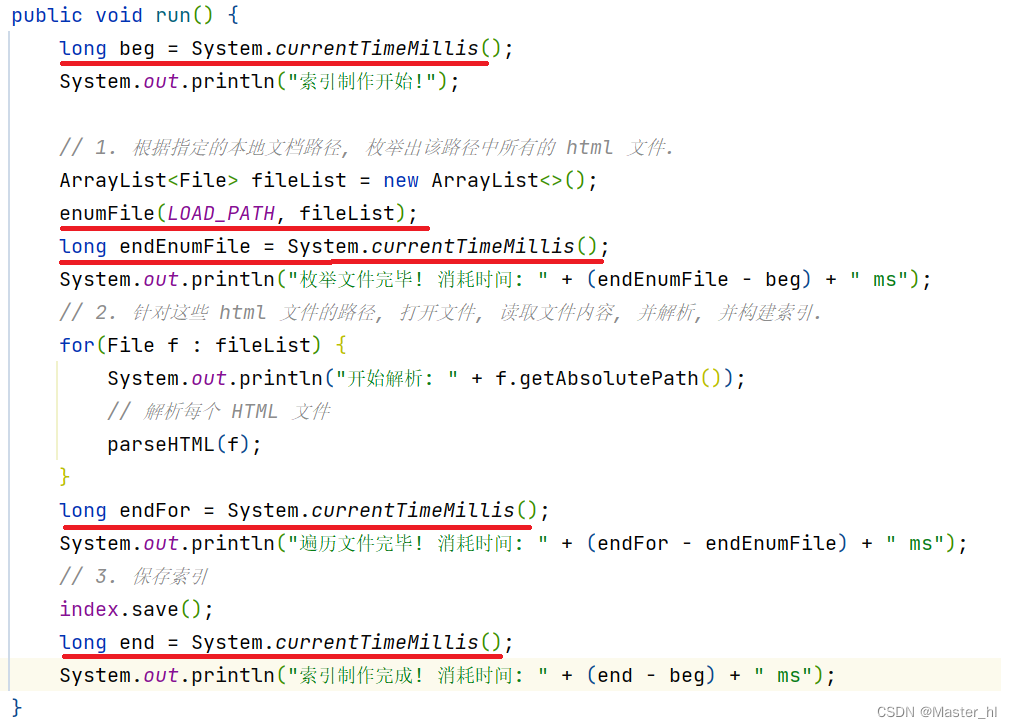
制作索引的主要步骤
运行结果 >>
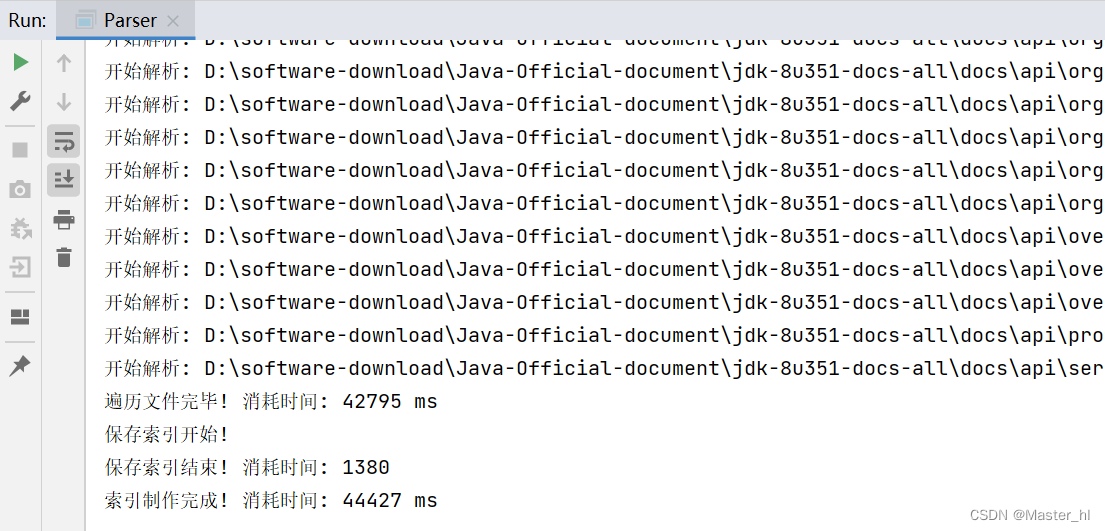
从运行结果中可以看出, 虽然枚举文件的时间被冲上去了, 但是总的制作索引时间可以看出是 44 s 左右 (电脑比较老的原因), 而遍历文件的时间就占了 42 s. 所以当前的性能瓶颈, 就在遍历文件上.
每次循环都要针对一个文件进行解析. 而解析又分为: 读文件, 分词, 解析内容. 这里的耗时主要是卡在 CPU 运算上, 读文件操作的时间是必不可少的, 而分词和解析内容是可以通过其他手段进行提升效率的.
我们 当前的 run() 方法是处在单线程环境下的, 所以这些任务都是串行执行的. 如果我们 使用多线程, 这些任务就可以并发执行了!!
2.4.5.1 通过多线程的方式优化索引制作
使用多线程制作索引的 runByThread() 方法代替原来的 run() 方法.
使用线程池来完成多线程索引制作.
使用 CountDownLatch 类来保证所有任务都执行完才保存索引.
public void runByThread() throws InterruptedException {
long beg = System.currentTimeMillis();
System.out.println("索引制作开始!");
// 1. 枚举出所有文件
ArrayList<File> files = new ArrayList<>();
enumFile(INPUT_PATH, files);
// 2. 循环遍历文件, 引入线程池完成多线程制作索引
CountDownLatch latch = new CountDownLatch(files.size());
ExecutorService executorService = Executors.newFixedThreadPool(6);
for(File f : files) {
executorService.submit(new Runnable() {
@Override
public void run() {
System.out.println("开始解析: " + f.getAbsolutePath());
parseHTML(f);
// 每个任务执行完都通知一下
latch.countDown();
}
});
}
// await() 方法会阻塞, 直到 countDown() 方法被调用的次数 == files.size() 时, 才能结束阻塞.
latch.await();
// 3. 保存索引
index.save();
long end = System.currentTimeMillis();
System.out.println("索引制作完成! 消耗时间: " + (end - beg) + " ms");
}【细节分析】
1. 使用线程池完成多线程索引制作时, 线程个数具体给多少也是需要进行测试才能下结论, 因为每个人的电脑不一样, 所以这个因人而异.
2. 使用线程池制作索引时, 务必要等待所有线程都执行完各自的任务时, 才能进行保存索引. 那么就需要引进 CountDownLatch 类来进行控制. 因为肯定存在 1万多次循环都 submit 完了, 但是线程池还没有把这 1万多个文档都解析完的情况. 而且可能性是非常大的. 而 CountDownLatch 就相当于跑步比赛的裁判,多个线程就相当于多个参赛选手, 只有当所有选手都撞线了, 才能认为比赛结束.(此处不考虑因伤退赛的情况) .
CountDownLatch 所做的工作 :
在构造 CountDownLatch 时指定比赛选手个数 - files.size().
每个选手撞线时, 都要通知一下 - 调用 countDown() 方法.
通过 await() 方法来等待所有选手都撞线完毕.
2.4.5.2 处理多线程制作索引中的线程安全问题
经过分析, 线程安全问题就发生在 parseHTML() 方法中, 并且具体在 addDoc 方法里面. (parseTitle, parseUrl, parseContent 三个方法中不涉及修改同一个对象, 所以是线程安全的)

那么我们是否可以直接给 addDoc() 方法直接套上一层 synchronized 呢 ??
这样做虽然能够解决线程安全问题, 但是锁的粒度太粗了, 我们使用线程池的目的就是为了并发执行, 而如果在 addDoc() 方法上加上 synchronized, 那么就只有 parseTitle, parseUrl, parseContent 三个方法能够并发执行了, addDoc() 就只能串行执行了, 并发程度不高. 于是就需要将锁的粒度细化.
涉及到线程安全的地方细化开来就是在构建正排索引和构建倒排索引中, 于是可以做出调整 >>>
🍁多线程环境下线程安全版本的 buildForward()
// 创建两个锁对象
private Object lock1 = new Object();
private Object lock2 = new Object();
private DocInfo buildForward(String title, String url, String content) {
DocInfo docInfo = new DocInfo();
docInfo.setTitle(title);
docInfo.setUrl(url);
docInfo.setContent(content);
synchronized (lock1) {
// 数组下标 -> docId
docInfo.setDocId(forwardIndex.size());
forwardIndex.add(docInfo);
}
return docInfo;
}🍁多线程环境下线程安全版本的 buildInverted()
private void buildInverted(DocInfo docInfo) {
// .... 省略相同代码
for(Map.Entry<String, WordCnt> entry : wordCntHashMap.entrySet()) {
// 先拿着词去倒排索引中查找, 看是否有倒排拉链 - Weight数组
synchronized (lock2) {
List<Weight> invertedList = invertedIndex.get(entry.getKey());
if(invertedList == null) {
// 如果倒排拉链为空, 就创建一个新的键值对 (新的 list, Weight 对象), 加入到 HashMap 中
ArrayList<Weight> newInvertedList = new ArrayList<>();
Weight weight = new Weight();
weight.setDocId(docInfo.getDocId());
// 权重计算公式 : 标题出现次数 * 10 + 正文出现次数
weight.setWeight(entry.getValue().titleCount * 10 + entry.getValue().contentCount);
newInvertedList.add(weight);
invertedIndex.put(entry.getKey(), newInvertedList);
} else {
// 如果倒排拉链不为空 , 就创建一个 Weight 对象, 加入到倒排拉链中
Weight weight = new Weight();
weight.setDocId(docInfo.getDocId());
// 权重计算公式 : 标题出现次数 * 10 + 正文出现次数
weight.setWeight(entry.getValue().titleCount * 10 + entry.getValue().contentCount);
invertedList.add(weight);
}
}
}
}画图理解 >>

关于 synchronized 锁对象的细节 >>
1. 此处 synchronized 括号中的锁对象为什么不写成 this, 因为 forwardIndex 和 invertedIndex 是两个不同的对象, 如果以 Index 对象作为锁对象, 就让这两个不同的对象也产生锁竞争了, 这是不合理的.
2. 其次最好创建两个专门的锁对象来作为 synchronized 的锁对象, 不要分别使用 forwardIndex 对象和 invertedIndex 对象作为锁对象, 如果任何一个对象都可以作为锁对象,有时候也容易产生困惑 .
验证多线程制作索引的速度 >>
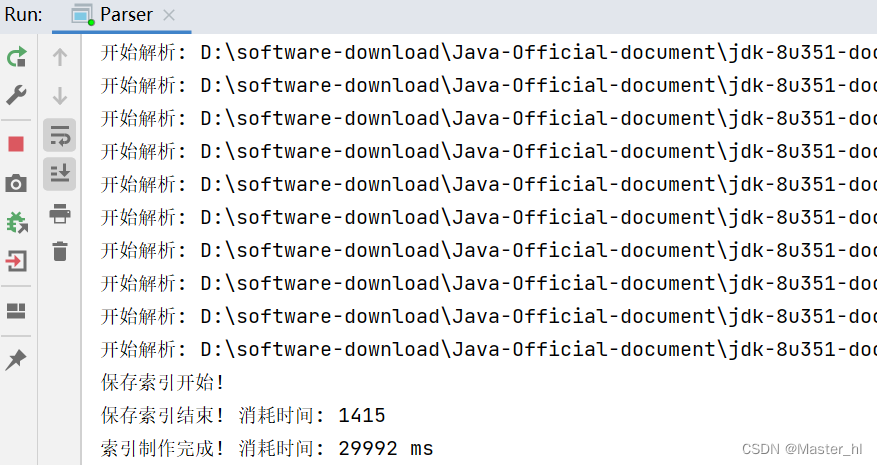
相比单线程环境下, 速度还是快了不少.
2.4.5.3 解决多线程环境下进程不退出问题
从上面的运行结果中可以看出虽然索引制作完成了, 但是进程还没有退出, 此处使用卸磨杀驴的方式来解决这个问题!
【卸磨杀驴】
public void runByThread() throws InterruptedException {
// .... 省略相同代码
latch.await();
// 等到所有任务都结束之后, 就可以销毁线程池了. 否则进程无法正常退出!
executorService.shutdown();
// 3. 保存索引
index.save();
// .... 省略相同代码
}关于守护线程 >> (进程不退出的原因)
1. 如果一个线程是守护线程 (后台线程), 那么这个线程的运行状态就不太影响到进程的结束.
2. 如果一个线程不是守护线程 (前台线程), 那么这个线程的运行状态就会影响到进程的结束. 当 mian 方法执行完了, 这些线程仍然在工作, 仍然在等待新任务的到来.
我们在学习多线程的时候, 默认创建出来的线程都是非守护线程, 需要手动调用 setDaemon() 方法才能编程守护线程. 而通过线程池创建的线程, 并不是守护线程, 而且它也没有提供相应的 setDaemon() 方法. 但它提供了 shutdown() 方法, 也就是在所有线程都执行完了后, 手动将所有线程都干掉.
2.4.5.4 解决首次制作索引速度比较慢的问题
【发现问题】
做到这里时, 发现了一个问题, 电脑开机之后, 首次制作索引会特别慢, 但是后面就会快很多. 然后重启机器后, 首次制作索引又会特别慢.
【定位问题】
由于计算机读取文件, 是一个开销比较大的操作. 于是就猜想开机之后, 首次制作索引比较慢的原因是不是因为首次运行时读取文件时速度特别慢, 于是给 parseContent() 和 addDoc() 方法加上时间累计, 运行两次程序, 看看问题到底出现在哪一个环节.


然后在 runByThread() 方法的末尾加上一句打印 :

由于运行结果会因电脑而异, 此处大家可以自己尝试. 最终发现问题就是在 parseContent() 方法中, 并且首次运行和第二次运行, 6 个线程 parseContent 的累计时间, 可能会相差几十甚至上百秒.
🍃为什么 parseContent() 方法会导致出现这样的问题>>>
parseContent() 方法导致首次制作索引非常慢的 万恶之源就是缓存!! 因为 parseContent 的核心操作, 就是读取文件. 而我们的操作系统有一个默认功能, 就是会对 "经常读取的文件" 进行缓存. 如果是开机首次制作索引时, 当前的这些 Java 文档, 都没有在内存中进行缓存, 因此读取的时候只能从硬盘上读取, 比起读内存还是相当耗时的. 后面再运行的时候, 由于前面已经读取过这些文档了, 所以这些文档在操作系统的默认功能下就会在内存中进行缓存, 那么后续再读取文件就不必再读取硬盘了, 而是直接读取内存, 所以速度就会相较于首次运行会快很多.
【解决问题】
使用 BufferedReader 搭配 FillReader 来解决 >>
private String parseContent(File f) {
// 按照字符来读取, 以正文中标签的 < 和 > 作为控制拷贝数据的开关
try(BufferedReader bufferedReader = new BufferedReader(new FileReader(f), 1024 * 1024)) {
// 拷贝数据的开关
boolean isCopy = true;
// 用来保存结果
StringBuilder content = new StringBuilder();
while(true) {
// 一次读一个字符, 返回值为 int 是为了处理一些非法情况, 如果读到了末尾, 就会返回 -1
int ret = bufferedReader.read();
// .... 省略相同代码
} catch (IOException e) {
e.printStackTrace();
}
return "";
}1. BufferedReader 内部会内置一个缓冲区, 就能够自动的把 FileReader 中的一些内容预读到内存中, 从而减少直接访问磁盘的次数. (此处是为了解决首次慢的问题, 后续执行时是否提高效率需要和操作系统的默认缓存比较, 其实都差不多)
2. 由于缓冲区默认大小是 8k, 而一个 Java 文档的一般都是几十 k, 所以此处可以手动设置一下缓冲区大小为 1M.
2.4.6 索引模块小结

2.5 实现搜索模块
该模块只有一个方法 - searcher >>
这个模块所要做的工作有
【分词】- 针对用户输入的查询词进行分词. (用户输入的查询词可能是一个词, 也可能是一句话)
【触发】- 针对分词结果来查倒排.
【排序】- 针对触发结果按照权重降序排序.
【包装结果】- 针对排序结果, 去查找正排, 获取每个文档的详细信息, 构造要返回的数据集合.
2.5.1创建 DocSearcher 类
public class DocSearcher {
// 加上索引对象的实例
private Index index = new Index();
public DocSearcher() {
// 内存中有索引结构才能根据查询词查处结果 所以要调用 load() 方法
index.load();
}
/**
* @param query 用户给出的查询词
* @return 搜索结果的集合
*/
public List<Result> searcher(String query) {
return null;
}
}2.5.2 创建 Result 类
@Data
public class Result {
private String title;
private String url;
// 描述时正文的一段摘要
private String desc;
}该类和 DocInfo 类不一样, Result 类中不包含 docId, 并且此处的 desc 不是正文, 只是正文的一段摘要, 简言之, 这个类的属性就是最后要呈现给用户的搜索结果的属性.
2.5.3 实现 searcher 方法
public List<Result> searcher(String query) {
// 1. [分词] 针对 query 查询词进行分词
List<Term> terms = ToAnalysis.parse(query).getTerms();
// 2. [触发] 针对分词结果来查倒排
List<Weight> allTermResult = new ArrayList<>();
for(Term term : terms) {
String word = term.getName();
List<Weight> invertedList = index.getInverted(word);
if(invertedList == null) {
// 说明这个词在所有文档中都不存在
continue;
}
// 查询出来的文档都装在一个 List 中
allTermResult.addAll(invertedList);
}
// 3. [排序] 针对触发结果按照权重降序排序
allTermResult.sort(new Comparator<Weight>() {
@Override
public int compare(Weight o1, Weight o2) {
return o2.getWeight() - o1.getWeight();
}
});
// 4. [包装结果] 针对排序结果, 去查正排, 构造要返回的数据.
List<Result> results = new ArrayList<>();
for(Weight weight : allTermResult) {
// 查正排
DocInfo docInfo = index.getDocInfo(weight.getDocId());
Result result = new Result();
// 构造数据
result.setTitle(docInfo.getTitle());
result.setUrl(docInfo.getUrl());
String desc = GenDesc(docInfo.getContent(), terms);
result.setDesc(desc);
// 添加进结果集
results.add(result);
}
return results;
}
// 从正文按照指定的规则获取描述
private String GenDesc(String content, List<Term> terms) {
// 遍历分词结果, 只要找到一个在 content 中出现的查询词, 就按照一定的规则截取一段描述
int firstPos = -1;
for(Term term : terms) {
// 此处分词库已经将 word 转小写了
String word = term.getName();
// 此处从正文查询分词结果需要按照全字匹配的规则, 不涉及同义词, 近义词
// 并且在使用 indexOf 方法之前, 需要将 content 转成小写
firstPos = content.toLowerCase().indexOf(" " + word + " "); // [并不严谨]
if(firstPos >= 0) {
// 找到一个词在正文中出现的位置了
break;
}
}
// query 的分词结果在正文中一个都没有找到 [仅在标题中出现]
if(firstPos == -1) {
// 一个都没找到, 就从正文的开始往后截取 160 个字符
if(content.length() > 160) {
return content.substring(0, 160) + "...";
}
return content;
}
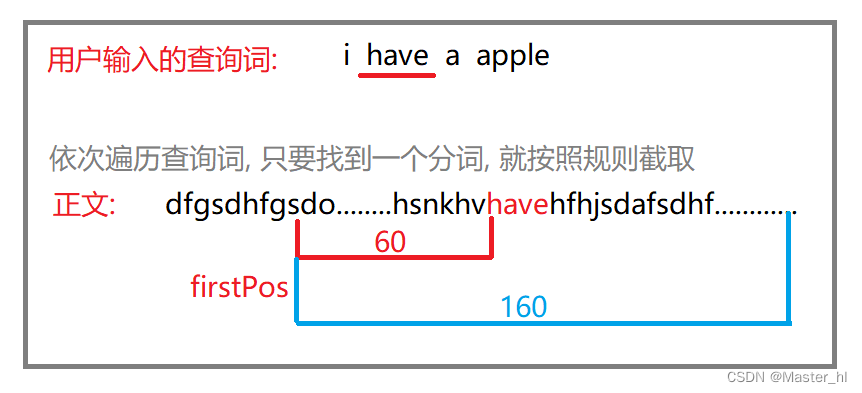
// 以 firstPos 作为基准位置, 往前找 60 个字符, 作为描述的起始位置, 然后往后截取 160 个字符
String desc = "";
int descBeg = firstPos < 60 ? 0 : firstPos - 60;
if(descBeg + 160 > content.length()) {
// 起始位置到末尾不够 160 个字符
desc = content.substring(descBeg);
} else {
desc = content.substring(descBeg, descBeg + 160);
}
return desc;
}实现过程中的注意点 >>
此处需要注意的就是 GenDesc() 方法, 这里指定的规则是 : 只要在正文中找到一个分词结果, 就从正文中该位置往前截取 60 个字符作为描述的起始位置, 然后再从该位置往后截取 160 个字符 【具体参照下图】.
另外从正文中找每个分词结果的时候, 注意分词库天然就将每个分词转成小写了, 所以在对 content 进行 indexOf 之前记得将 content 先转成小写. 其次就是此处的匹配规则是全字匹配, 不涉及同义词,近义词等. 也就是不会出现查询词为 List, 就把包含 ArrayList 的文档也查出来的情况【查正排会遇到, 查倒排则不会, 因为分词库不会把 ArrayList 拆分成 Array 和 List】. 但是可能会出现 List 前后带标点的情况, 这个后面再考虑.
2.5.4 验证 searcher 方法
给 DocSearcher 类添加 main 方法 >>
public static void main(String[] args) {
DocSearcher docSearcher = new DocSearcher();
Scanner scanner = new Scanner(System.in);
while(true) {
System.out.println("请输入查询词 -> ");
String query = scanner.next();
List<Result> results = docSearcher.searcher(query);
for(Result result : results) {
System.out.println("=======================");
System.out.println(result);
}
}
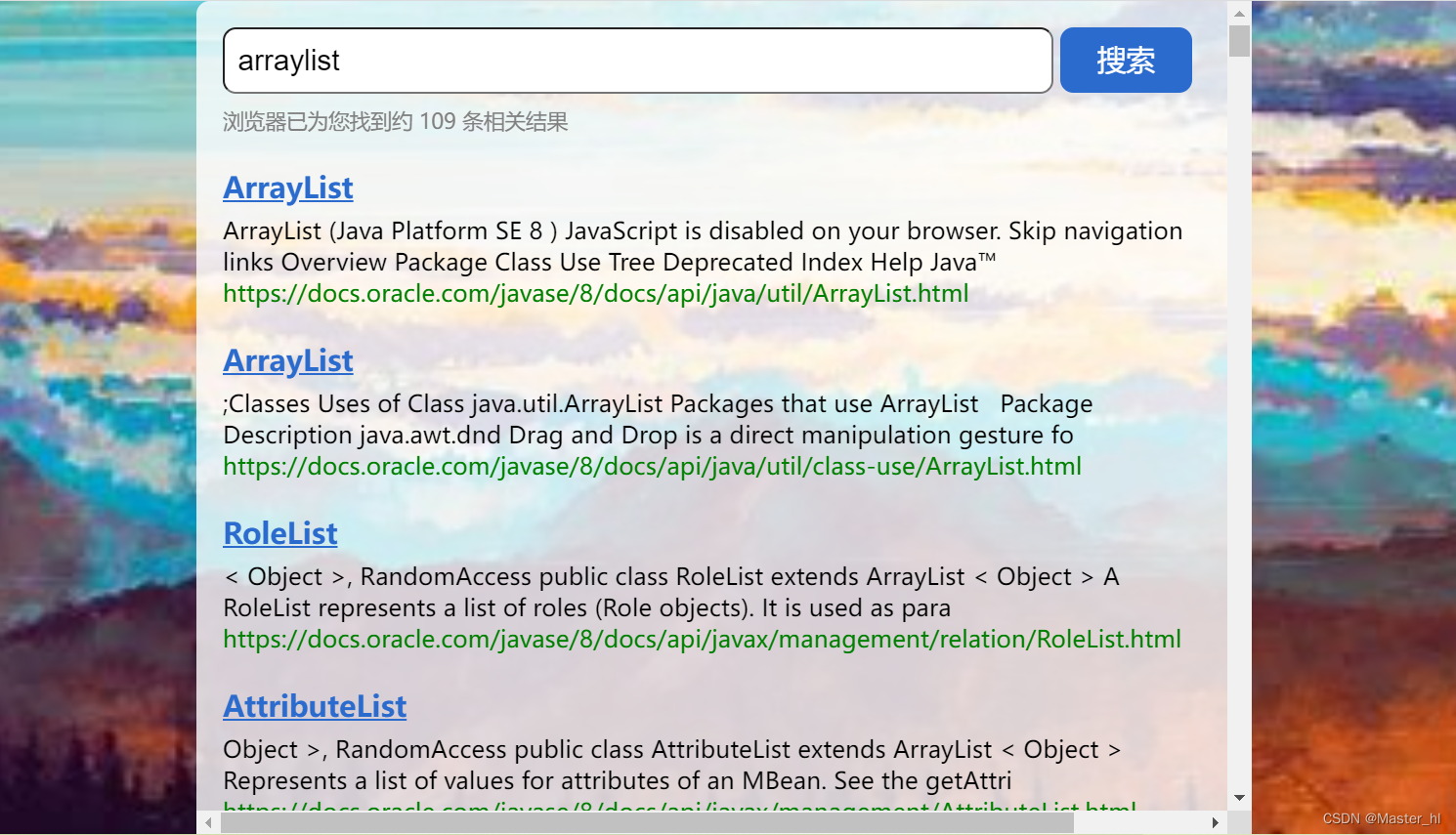
}输入 arraylist 后执行结果如下 :
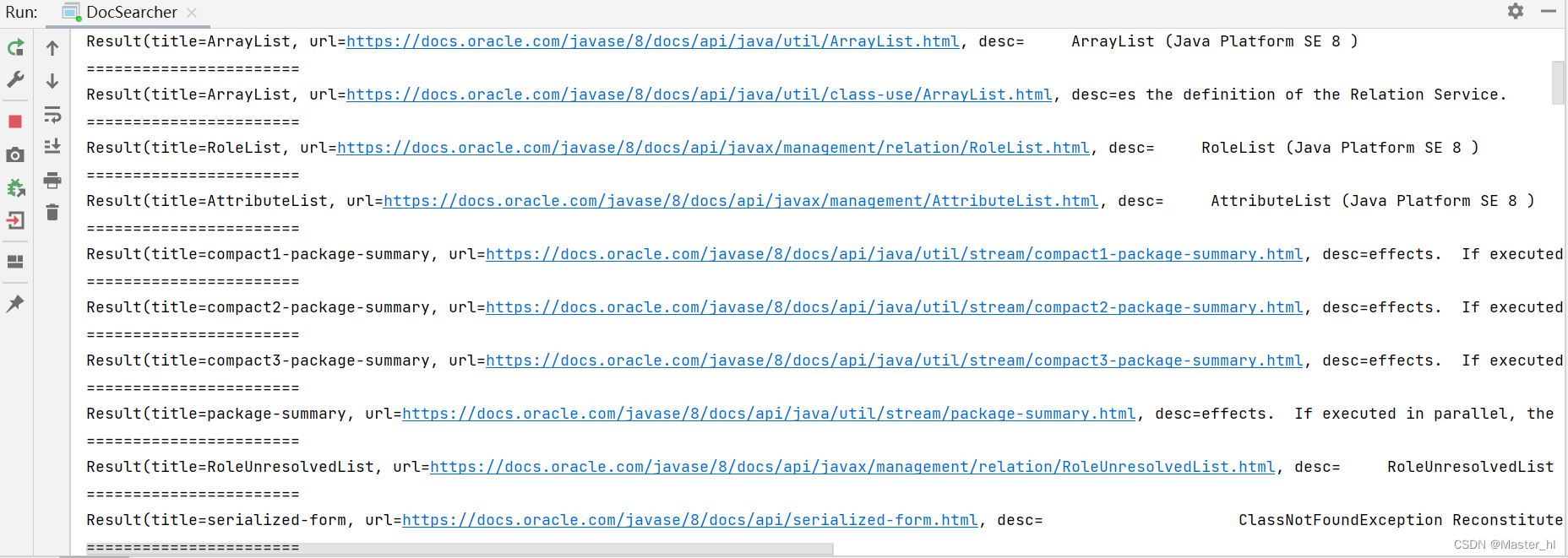
往后拖动后, 发现包含了 JS代码 >>
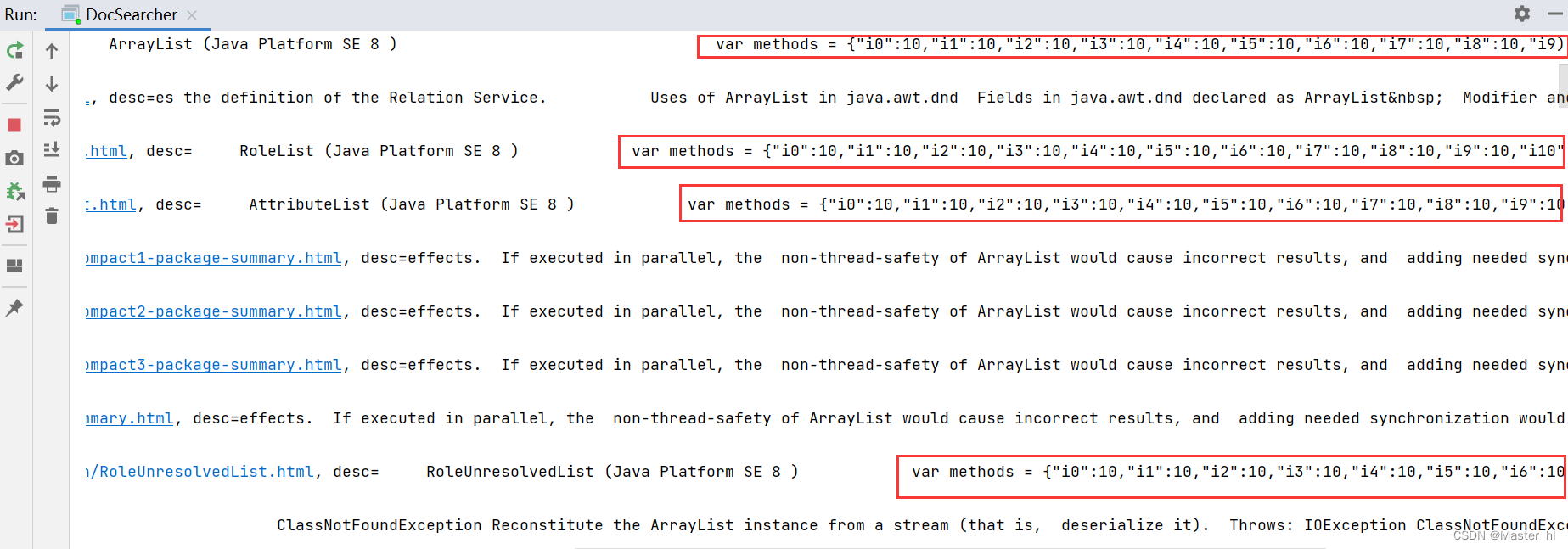
搜索结果的正文包含 JS 代码的原因 :
最初在 Parser 类中解析正文的时候, 我们只是以 < > 作为了控制是否拷贝的开关, 而正文中可能也会包含 <script> 标签, 于是在去标签的同时, 就把 scrip 中的内容也拷贝到正文中了.
2.5.5 使用正则表达式改进 parseContent 方法
parseContent 中需要改进的地方有两个 :
1.需要去除正文中的 JS 代码.
2.需要将多个空格合并成一个空格.
想要去除<script> 标签以及其中 JS代码, 就需要使用到如下几个正则表达式 :
. -> 表示匹配一个非换行字符. (不包含 \n 和 \r)
* -> 表示前面的字符可以出现若干次.
.* ->匹配非换行字符出现若干次.
? -> 表示非贪婪匹配,即匹配到一个符合条件的最短结果.
\s ->表示匹配任何空格字符, 包括空格, 制表符, 换页符等等.
此处需要注意的是贪婪匹配和非贪婪匹配之间的区别 >>
贪婪匹配 :

此处如果不加 ? , 那么就把这里的 <> 左右尖括号按照待匹配字符串中的第一个字符和最后一个字符来尽可能多的进行匹配了, 如果这样做的话, 就不只是将 JS 代码去除了, HTML 代码也会被一起匹配, 所以不妥.
非贪婪匹配 :
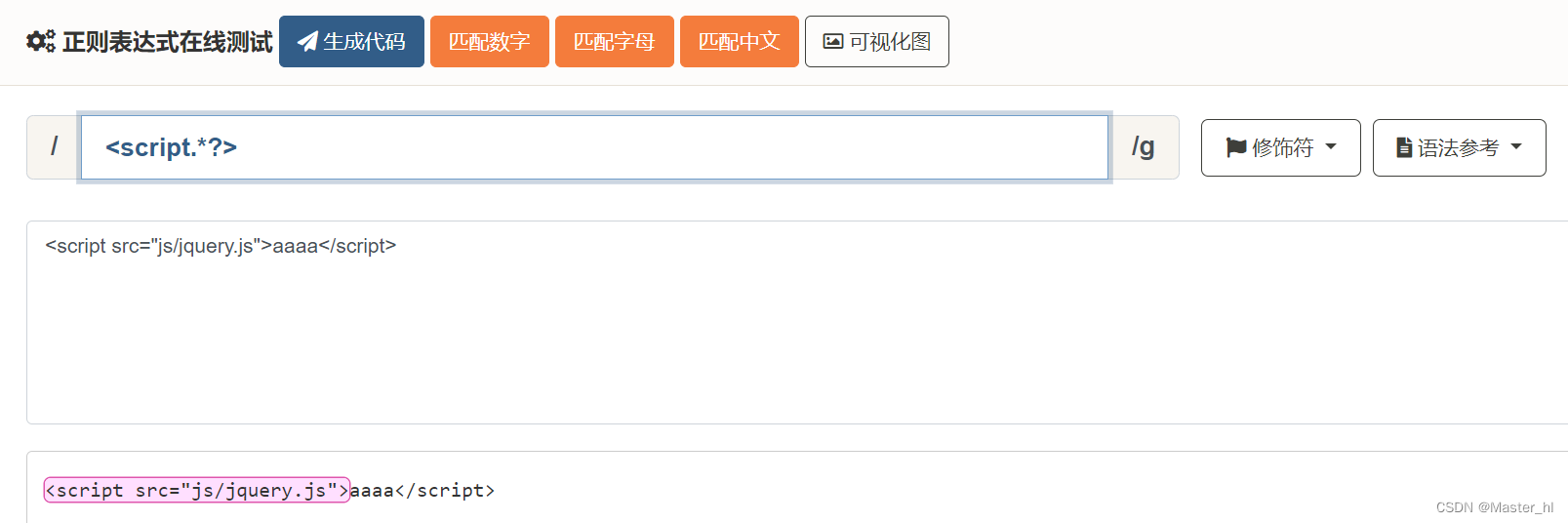
而这种非贪婪匹配, 正好符合我们的预期.
那么想要匹配所有的 <script> 标签以及 JS 代码只要按照以下方式进行匹配即可 >>

修改 Parser 类中的 parseContent 方法
public String readFile(File f) {
try(BufferedReader bufferedReader = new BufferedReader(new FileReader(f))) {
StringBuilder content = new StringBuilder();
while(true) {
int ret = bufferedReader.read();
// 文件读取完毕
if(ret == -1) {
break;
}
char c = (char) ret;
// 遇到换行符, 替换成空格
if(c == '\n' || c == '\r') {
c = ' ';
}
content.append(c);
}
return content.toString();
} catch(IOException e) {
e.printStackTrace();
}
return "";
}
// 基于正则表达式去标签, 已经去除 JS 代码
public String parseContentByRegex(File f) {
// 1. 先把整个文件都读到 String 里面
String content = readFile(f);
// 2. 替换 script 标签以及中间的 JS 代码
content = content.replaceAll("<script.*?>(.*?)</script>", " ");
// 3. 替换普通的 HTML 标签
content = content.replaceAll("<.*?>", " ");
// 4. 将多个空格合并成一个空格
content = content.replaceAll("\\s+", " ");
return content;
}1. 此处的 readFile 方法和之前的 parseContent 方法很相似, 只是少了开关这一操作. 先把正文所有内容都读到一个字符串中.
2. 其次要注意的是再使用正则表达式的时候, 前面的 2,3 步骤顺序不能颠倒, 否则就和之前的没区别了.
3. 在合并多个空格时, 使用正则表达式 \s 搭配 + 号来使用, 而不是搭配 * 号来使用, 因为搭配 + 号表示至少匹配一个空格, 而搭配 * 号可以匹配一个空格都没有的情况, 就不科学.
此时我们还要回过头把 Parse 类中调用 parseContent() 的地方改成调用 parseContentByRegex(), 并再次测试 Parse 类中制作索引的速度, 看看改成正则表达式之后, 有没有拖慢索引制作的速度. (大家可以自己测试一下, 答案是并没有拖慢).
😁代码改进后的搜索结果 >>

此时搜索结果看起来就科学很多了.
2.6 实现 web 模块
仅仅在控制台进行搜索, 这样用户体验不友好, 于是可以提供一个 web 接口, 最终以网页的形式, 把程序呈现给用户. 而实现 web 模块就需要前端 + 后端, 此处前端就使用 (HTML + CSS + JS), 后端基于 SpringBoot 来实现.
2.6.1 准备前端页面
此处没有细节可言, 因为我对前端非常陌生, 所以做出的页面也非常丑陋, 凑合着使用即可.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Java 文档搜索</title>
</head>
<body>
<div class="container">
<!-- 1. 搜索框 + 搜索按钮 -->
<div class="header">
<input type="text">
<button id="search-btn">搜索</button>
</div>
<!-- 2.显示搜索结果 -->
<div class="result">
<!-- 这里有很多条件记录 -->
<!-- 每个 .item 就表示一条记录 -->
<!-- <div class="item">
<a href="#">《绿茵信仰》放手一搏-决胜卡塔尔新版本开启!</a>
<div class="desc">来自百度《绿茵信仰》决胜卡塔尔版本开启!巅峰国家杯电竞模式和卡塔尔梦之队经理人模式完整还原世界杯赛场体验</div>
<div class="url">http://www.baidu.com</div>
</div> -->
</div>
</div>
<style>
* {
margin: 0;
padding: 0;
box-sizing: border-box;
}
html, body {
height: 100%;
background-image: url(image/bg3.jpg);
background-repeat: no-repeat;
background-position: center center;
background-size: cover;
}
.container {
width: 800px;
height: 100%;
margin: 0 auto;
background-color: rgba(255,255,255,0.8);
border-radius: 10px;
padding: 20px;
/* 加上这个属性, 超出元素的部分就会自动生成一个滚动条 */
overflow: auto;
}
.head {
width: 100%;
height: 50px;
display: flex;
justify-content: space-between;
align-items: center;
}
.header>input {
width: 630px;
height: 50px;
font-size: 22px;
line-height: 50px;
padding-left: 10px;
border-radius: 10px;
}
.header>button {
width: 100px;
height: 50px;
background-color: rgb(42,107,205);
color: #fff;
font-size: 22px;
line-height: 50px;
border-radius: 10px;
border: none;
}
.header>button:active {
background: gray;
}
.result .count {
color: gray;
margin-top: 10px;
}
.item {
width: 100%;
margin-top: 20px;
}
.item a {
display: block;
height: 40px;
font-size: 22px;
line-height: 40px;
font-weight: 700;
color: rgb(42,107,205);
}
.item .desc {
font-size: 18px;
}
.item .url {
font-size: 18px;
color: rgb(0,128,0);
}
</style>
</body>
</html>页面样式 >>
后续还会遇到很多问题,此处先了解页面的基本结构>>
2.6.2 搜索模块的前后端交互
🍁约定前后端交互接口
此处只需要提供一个接口 - 搜索接口
请求 >>
GET / searcher?query=[查询词] HTTP/1.1
响应 >>
HTTP/1.1 200 OK
返回的数据 : JSON 格式 >> [{title:"ArrayList", url:"http:xxxx.araylist",desc:"arraylist....."}, {.....}]
🍁前端代码
前后端交互流程, 前端使用 ajax 来构造 HTTP 请求, 此处不使用 JS原生的 ajax, 此处借助第三方库 jquery 提供的 ajax.
第三库 jquery 依赖下载链接 : https://code.jquery.com/jquery-3.6.3.min.js
进入链接后, 只需要 ctrl A, 然后复制, 然后在前端新创建 js文件, 将刚刚复制的代码粘贴进去即可, 然后哪些地方使用到了第三方库提供的 ajax , 就直接引用即可.
<!-- 引入 jQuery 依赖 -->
<script src="js/jquery.js"></script>
<script>
let button = document.querySelector("#search-btn");
button.onclick = function() {
let query = document.querySelector(".header input").val();
console.log("query: " + query);
jQuery.ajax({
type: "GET",
url: "searcher?query=" + query,
success: function(data, status) {
// 根据响应数据, 构造页面内容
buildResult(data);
}
});
// 将响应数据构成页面内容
function buildResult(data) {
// 获取到 .result 这个标签
let result = document.querySelector('.result');
// 清空上次的结果
result.innerHTML = '';
// 先构造一个 div 用来显示结果的个数
let countDiv = document.createElement('div');
countDiv.innerHTML = '浏览器已为您找到约 ' + data.length + " 条相关结果";
countDiv.className = 'count';
result.appendChild(countDiv);
// 遍历 data 中的每个元素 针对每个元素都创建一个 div.item,
// 然后把 title,url,desc 都构造好, 再把这个 div 加入到 div.result 中
for(let item of data) {
let itemDiv = document.createElement('div');
itemDiv.className = 'item';
// 构造一个标题
let title = document.createElement('a');
title.href = item.url;
title.innerHTML = item.title;
// 点击超连接的时候, 新打开一个页面展示
title.target = '_blank';
itemDiv.appendChild(title);
// 构造一个描述
let desc = document.createElement('div');
desc.className = 'desc';
desc.innerHTML = item.desc;
itemDiv.appendChild(desc);
// 构造一个 url
let url = document.createElement('div');
url.className = 'url';
url.innerHTML = item.url;
itemDiv.appendChild(url);
// 将 itemDiv 加到 .result 中
result.appendChild(itemDiv);
}
}
}
</script>【注意事项】
此处拿到响应数据, 在构造页面之前务必要进行一次清空操作, 否则每次搜索的结果都冉到一起了.这就不科学了.
🍁后端代码
创建一个 controller 包, 创建 DocSearcherController 类.
@RestController
public class DocSearcherController {
@Autowired
private DocSearcher docSearcher;
private ObjectMapper objectMapper = new ObjectMapper();
@RequestMapping(value = "/searcher", produces = "application/json;charset=utf-8")
@ResponseBody
public String search(@RequestParam("query") String query) throws JsonProcessingException {
List<Result> results = docSearcher.searcher(query);
return objectMapper.writeValueAsString(results);
}
}2.6.3 验证 web 模块
先搜索一个 arraylist >>

再搜索一个 Map >>

搜索结果看上去没啥问题, 但是相较于浏览器来说, 还有很大的区别, 对比搜狗搜出来的结果, 发现它会将关键词进行标红处理, 用户体验非常友好, 于是我们也实现一下标红处理 >>

2.7 实现标红逻辑
实现标红逻辑, 需要前后端配合 >>
后端处理 >>
后端针对生成搜索结果的描述部分, 把其中包含查询词的部分, 加上一个标记. 例如给这部分套上一层 <i> 标签.
前端处理 >>
前端针对响应中的数据, 给 <i> 标签设置样式即可.
2.7.1 修改 GenDesc() 方法
private String GenDesc(String content, List<Term> terms) {
// .... 省略相同代码
// 后端标红逻辑, 给描述中和分词结果相同的部分, 套上一层 <i> 标签
for(Term term : terms) {
String word = term.getName();
// 1.注意全字匹配
// 2.replace 的操作是生成一个新的 String, 记得拿 desc 接收
// 3. (?i) 表示忽略大小写匹配, 因为分词库天然将 word 转成小写了.
desc = desc.replaceAll("(?i)" + " " + word + " ", " <i>" + word + "</i> ");
}
return desc;
}2.7.2 前端添加标红样式
.item .desc i {
color: red;
/* 去掉斜体 */
font-style: normal;
}2.7.3 验证标红逻辑
输入查询词 arraylist >> (符合预期)

2.8 测试一些复杂的查询词
当我们输入 array list 查询词时 >> (中间多了一个空格)


此时搜索结果竟然比中间不带空格的 arraylist 多了一万多条, 而且搜出来的结果还有和 array, list 都毫不相关的结果, 这就很不科学.
【为什么会出现这样的原因】
1. 当查询词为中间带空格的 array list 时, 分词库会将空格也分出来, 那么拿着空格去倒排索引中查倒排拉链, 就会把所有文档给查出来, 毕竟哪个文档不带空格.
2. 而且并不只是空格这样的词会导致这样的情况, 像 a, is, have, 一, 是, 的, 有....这样词都属于高频词, 但又没啥意义. 这一类词也叫作暂停词.
2.8.1 处理暂停词
首先去网上搜索英文暂停词表, 然后使用记事本保存起来, 再把这个 txt 文件保存到一个路径下面.
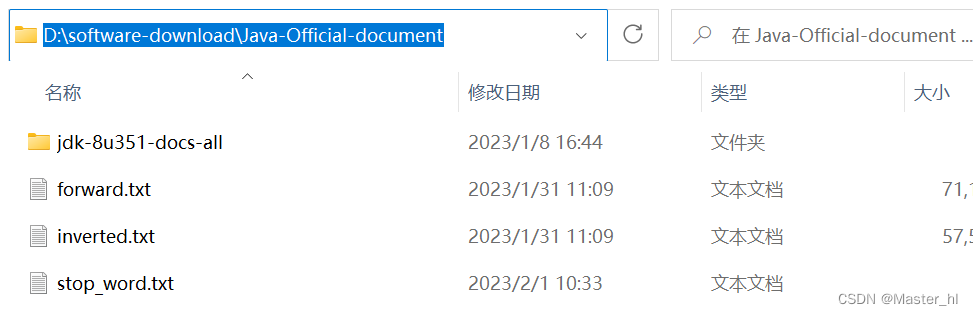
此处我是直接将其保存到了索引文件的目录下面 >>
2.8.1.1 修改 DocSearcher 类中的代码
引入暂停词表的文件路径, 并且创建一个 HashSet 来保存暂停词
// 停用词表的文件路径
private static final String STOP_WORD_PATH = "D:/software-download/Java-Official-document/stop_word.txt";
// 使用 HashSet 来保存停用词
private HashSet<String> stopWordsSet = new HashSet<>();编写加载暂停词到内存的方法
// 加载暂停词表到内存
public void loadStopWords() {
try(BufferedReader bufferedReader = new BufferedReader(new FileReader(STOP_WORD_PATH))) {
while(true) {
String stop_word = bufferedReader.readLine();
if(stop_word == null) {
// 读取文件完毕
break;
}
stopWordsSet.add(stop_word);
}
} catch(IOException e) {
e.printStackTrace();
}
}修改 searcher 方法
public List<Result> searcher(String query) {
// 1. [分词] 针对 query 查询词进行分词
List<Term> oldTerms = ToAnalysis.parse(query).getTerms();
List<Term> terms = new ArrayList<>();
// 针对分词结果, 使用暂停词表进行过滤
for(Term term : oldTerms) {
if(stopWordsSet.contains(term.getName())) {
continue;
}
terms.add(term);
}
// .... 省略相同代码
return results;
}在 DocSearcher 类的构造方法中调用 loadStopWords() 方法
public DocSearcher() {
// 内存中有索引结构才能根据查询词查处结果 所以要调用 load() 方法
index.load();
// 加载暂停词表
loadStopWords();
}2.8.1.2 验证处理暂停词效果
此时搜索结果就正常多了, 并且往下滑几乎就看不到与 array, list 不相关的搜索结果了 >>

2.8.2 使用正则表达式处理生成描述时出现的 Bug
通过 array list 的搜索结果往下滑, 发现还是有个别搜索结果出现既与 array 不相关, 也与 list 不相关的查询结果.

将其点开, 并查看网页源代码 >>
Ctrl f , 搜索 array, 出现了这样的结果

说明在生成描述的时候 (GenDesc()), 出现了问题, 于是找到相应的代码 >>
firstPos = content.toLowerCase().indexOf(" " + word + " "); // [并不严谨]我们前面写成 indexOf(" " + word + " ") 是为了防止出现查询词为 list, 搜索出与 arraylist 相关的结果. 却忽略了正文中会出现 " aaa array)", " aaa array.", " aaa array," 这样的搜索结果.
于是此处可以使用正则表达式进行处理 >>
\b -> 匹配一个单词的边界, 也就是只单词和空格, 以及各种标点符号, 括号间的位置.
使用在线正则在线工具进行示范 >>

实现思路
此处由于 indexOf 函数不支持正则表达式, 所以采取一种 曲线救国的方式, 我们可以 将单词与标点间的位置, 单词与括号间的位置, 转换成单词与空格间的位置, 于是就可以使用 replaceAll 方法来实现, 因为它是支持正则表达式的.
代码改进
private String GenDesc(String content, List<Term> terms) {
// 遍历分词结果, 只要找到一个在 content 中出现的查询词, 就按照一定的规则截取一段内容
int firstPos = -1;
for(Term term : terms) {
// 此处分词库已经将 word 转小写了
String word = term.getName();
// 此处从正文查询分词结果需要按照全字匹配的规则, 不涉及同义词, 近义词
// [改进代码] - 使用正则表达式 \b 处理单词与空格, 标点符号间的位置
content = content.toLowerCase().replaceAll("\\b" + word + "\\b"," " + word + " ");
firstPos = content.indexOf(" " + word + " ");
if(firstPos >= 0) {
// 找到一个词在正文中出现的位置了
break;
}
}
// ... 省略相同代码
return desc;
}
2.8.2.1 验证描述中是否还存在 Bug
输入查询词 array list >>
Ctrl f 找到刚才的 package-use :

此时搜索结果中的描述就变得正常了.
2.9 实现权重合并
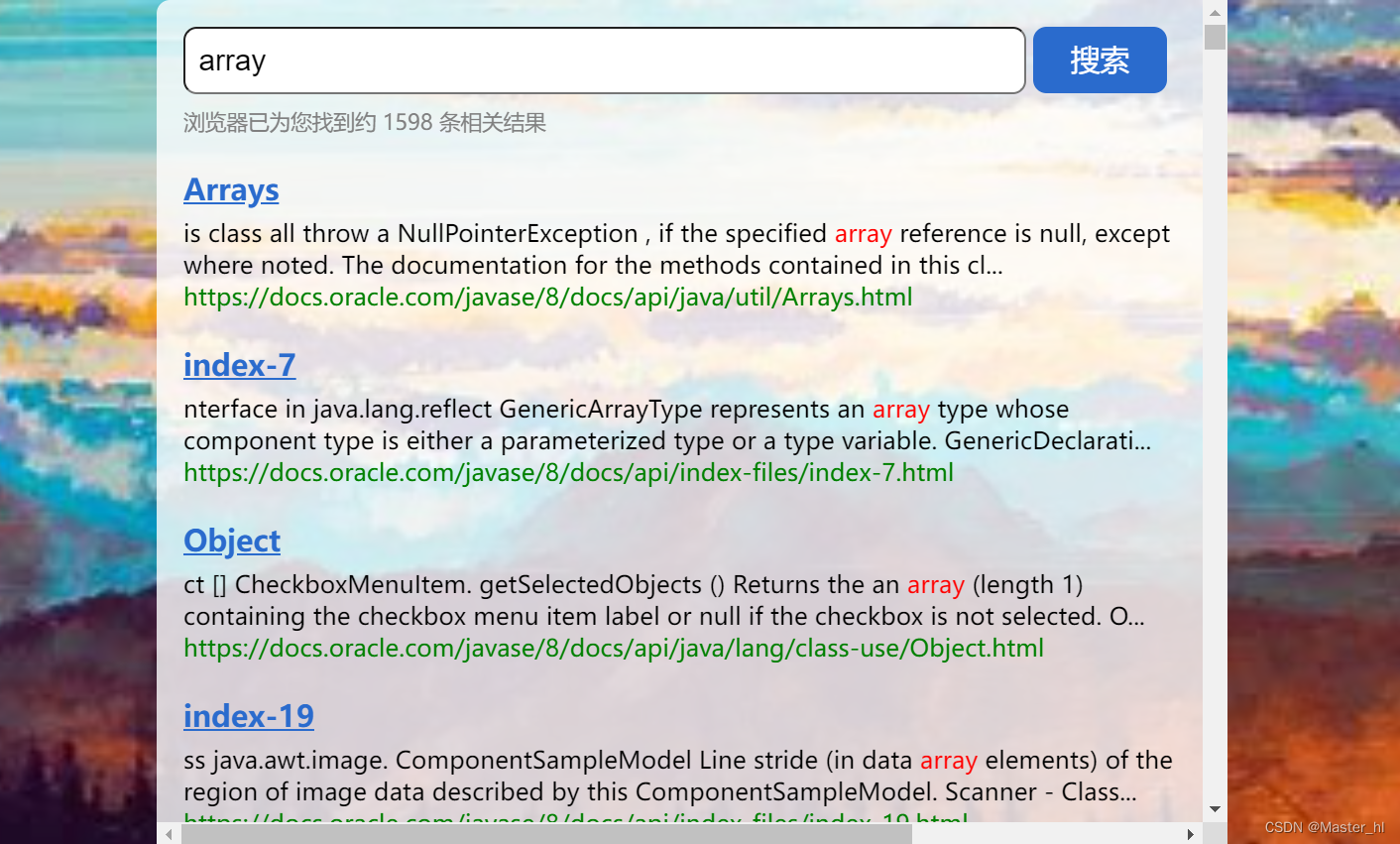
查询词为 array >> 搜索结果有 1598 条
查询词为 list >> 搜索结果有 1381 条
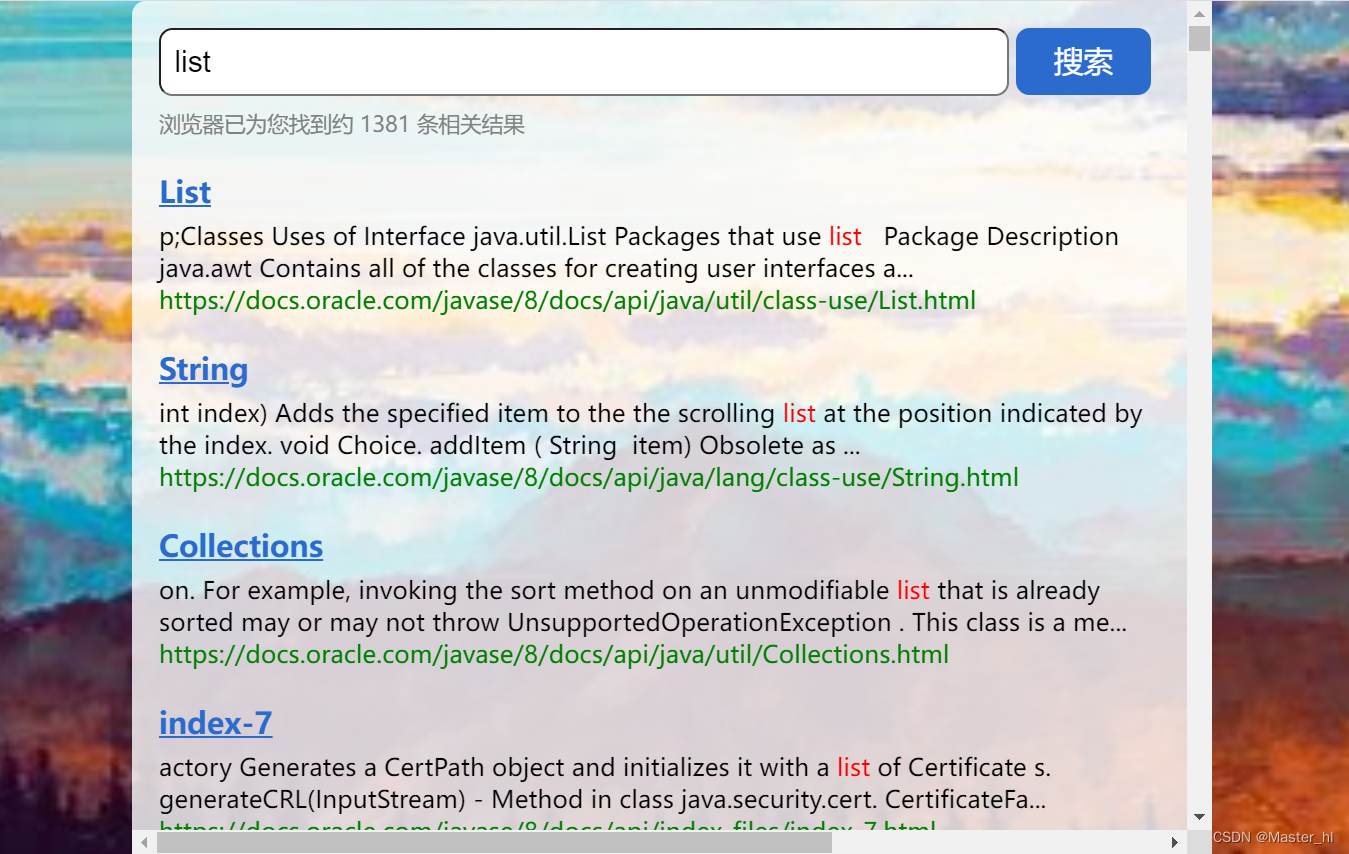
查询词为 array list >> 搜索结果有 2979 条
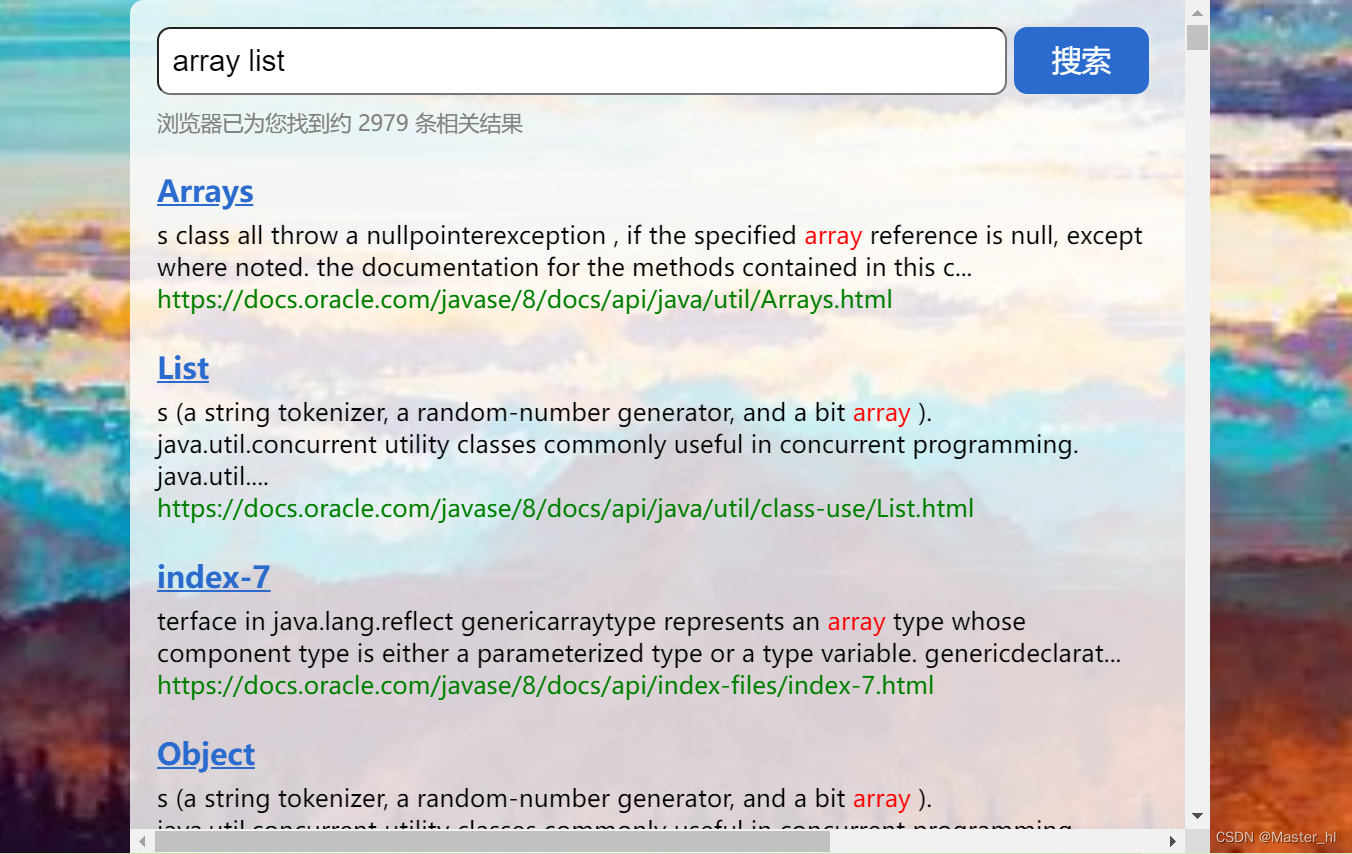
两次搜索结果的总次数为 2979 条, 和查询词为 array list 的搜索结果条数竟然一样多.
那么这样的结果是否正确 ??
通过滑动搜出来的结果, 仔细一思考就可以知道这里面有些文档是既包含 array , 又包含 list 的, 如果分开搜索和一起搜索查询出来的结果条数一样多的话, 那么当查询词为 array list 的时候, 查询出来的文档就一定会将同时包含 array 和 list 的文档查询出来两次, 这显然不合理.

为什么会出现这样的情况 >>
前面我们算权重, 是依次针对分词结果进行触发, 也就是说 array 会触发出一组 docId, list 会触发出一组 docId, 而这两组 docId 中可能就会出现相同的 docId 的情况, 如下图 >> 而我们前面是直接将所有文档触发出来的 Weight 对象都混合在一个一维数组中了, 所以才会出现这样的问题. (正确的做法是搞一个二维数组)

当前要解决的问题 >>
1. 一个文档不应该展示两次.
2. 像 Collections 这样的文档, 同时包含多个分词结果, 其实就意味着该文档的 "相关性" 更高!!
于是我们就需要提高这个文档的权重, 如何提高, 那么就需要进行多路归并.
此处多路归并的思路就和合并 k 个已排序链表的思路一样, 如果你会做下面这道算法题, 那么你就能想明白合并权重的思路. -- 合并 k 个已排序链表
2.9.1 改进 searcher 方法
public List<Result> searcher(String query) {
// .... 省略相同代码
// 2. [触发] 针对分词结果来查倒排 [改进代码 - 合并权重]
// [改进] 使用二维数组将每个分词结果查询出来的倒排拉链给保存起来
List<List<Weight>> termResult = new ArrayList<>();
for(Term term : terms) {
String word = term.getName();
List<Weight> invertedList = index.getInverted(word);
if(invertedList == null) {
// 说明这个词在所有文档中都不存在
continue;
}
// 查询出来的文档都装在一个 List 中
termResult.add(invertedList);
}
// 3. [合并] 针对多个分词结果, 触发出的相同文档, 进行权重合并
List<Weight> allTermResult = mergeResult(termResult);
// .... 省略相同代码
}2.9.2 实现多路归并的核心方法
static class Pos {
public int row;
public int col;
public Pos(int row, int col) {
this.row = row;
this.col = col;
}
}
private List<Weight> mergeResult(List<List<Weight>> source) {
// 在进行多路归并的时候, 是需要操作二维 list 里面的每一个元素的
// 而操作元素就涉及到 "行" 和 "列" 这样的概念, 为了方便确定每个元素, 于是提供一个内部类 Pos
// 1. 先针对每一个一维 list 按照 docId 进行升序排序
for(List<Weight> curRow : source) {
curRow.sort(new Comparator<Weight>() {
@Override
public int compare(Weight o1, Weight o2) {
return o1.getDocId() - o2.getDocId();
}
});
}
// 2. 使用优先级队列, 针对所有有序的一维 list 进行合并
List<Weight> target = new ArrayList<>(); // -- target 表示合并的结果
PriorityQueue<Pos> queue = new PriorityQueue<>(new Comparator<Pos>() {
@Override
public int compare(Pos o1, Pos o2) {
// 拿到数组中的一个 Weight 对象
Weight weight1 = source.get(o1.row).get(o1.col);
Weight weight2 = source.get(o2.row).get(o2.col);
// 指定排序规则
return weight1.getDocId() - weight2.getDocId();
}
});
// 初始化优先级队列
for(int row = 0; row < source.size(); row++) {
// 初始插入队列中元素的列为 0
queue.offer(new Pos(row, 0));
}
// 循环取队首元素
while(!queue.isEmpty()) {
Pos minPos = queue.poll();
Weight curWeight = source.get(minPos.row).get(minPos.col);
// 判断当前取出来的元素和前一个插入 target 中的元素的 docId 是否相同, 如果是就合并权重
if(target.size() > 0) {
// 取出上一次插入到 target 中的元素
Weight lastWeight = target.get(target.size() - 1);
// docId 相同, 合并权重
if(lastWeight.getDocId() == curWeight.getDocId()) {
// 合并后的权重
int newWeight = curWeight.getWeight() + lastWeight.getWeight();
lastWeight.setWeight(newWeight);
} else {
// docId 不同, 插入到 target
target.add(curWeight);
}
} else {
// target 为空, 直接插入
target.add(curWeight);
}
// 当前最小 docId 处理完之后, 就将该行的列往后移, 如果位置合法就入队列, 继续进行下一次循环
Pos newPos = new Pos(minPos.row, minPos.col + 1);
// 判断当前最小 docId 这一行 , 往后移动 1 格后, 下标是否合法
if(newPos.col >= source.get(newPos.row).size()) {
// 下标不合法, 这一行已经合并完了, 继续对剩下的行进行合并
continue;
}
queue.offer(newPos);
}
return target;
}此处的实现确实要合并 k 个有序链表稍微难以理解一些, 其实只要想到创建一个内部类来操作二维数组中的元素, 后面的逻辑就和合并 k 个有序链表差不多了.
2.9.3 验证权重合并的效果
查询词为 array list, 搜索结果 >>
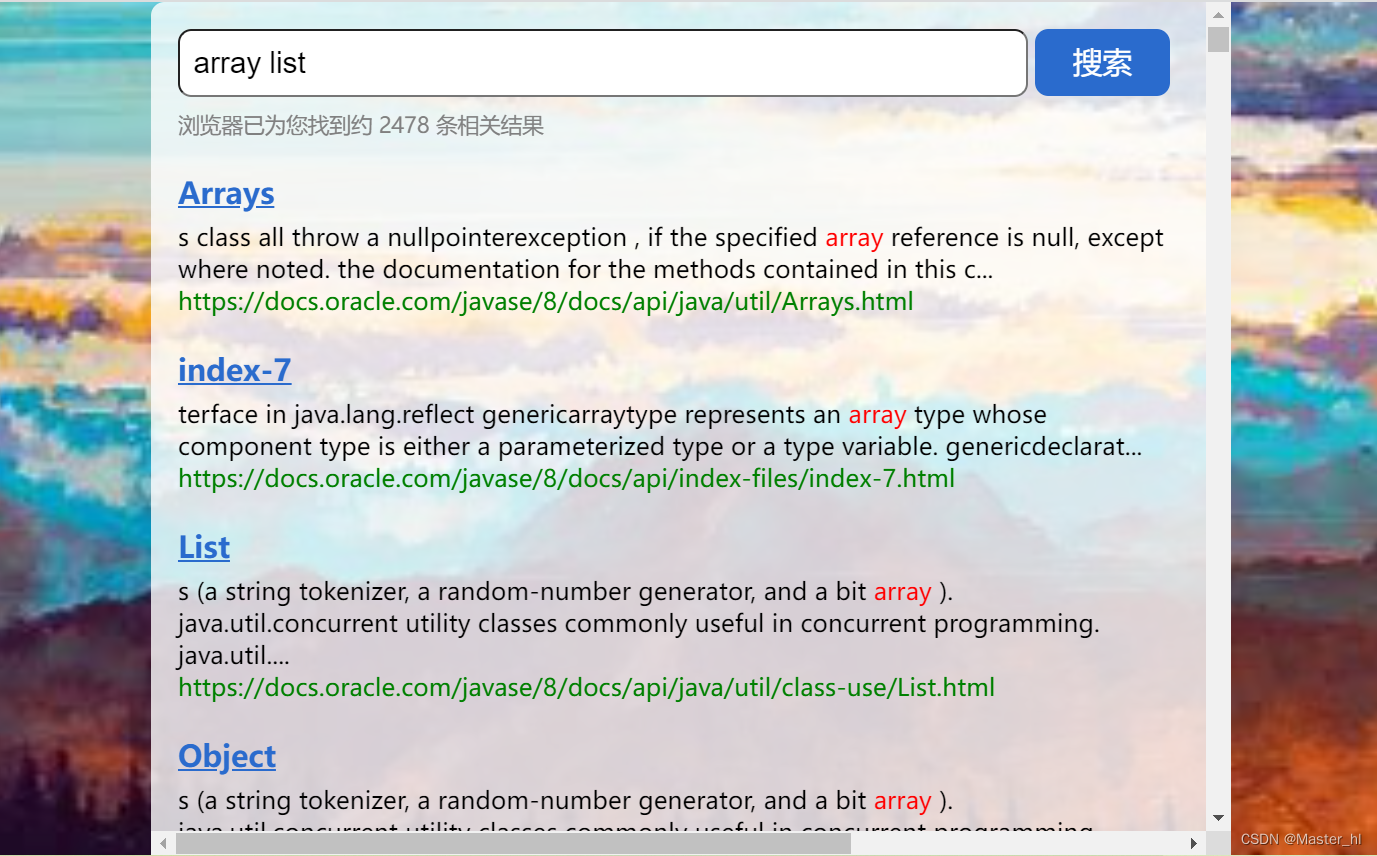
此时的搜搜结果就从原来的 2979 变成了 2478, 说明查询出两次的文档还是比较多的.
2.10 设置控制线上运行与线下运行的开关
此处省略了部署操作, 提供一个控制线上运行和线下运行的开关, 方便修改代码, 而不是每次都修改路径.
创建 Config 类 >>
public class Config {
// 变量为 true, 表示在云服务器上运行, 为 false 表示在本地运行
public static boolean isOnline = false;
}修改 Index 类中的索引路径 >>
// 保存和加载索引文件的路径
private static String INDEX_PATH = null;
static {
if(Config.isOnline) {
INDEX_PATH = "/root/install/doc_searcher_index/";
} else {
INDEX_PATH = "D:/software-download/Java-Official-document/";
}
}修改 DocSearcher 类中的暂停词加载路径 >>
// 停用词表的文件路径
private static String STOP_WORD_PATH = null;
static {
if(Config.isOnline) {
STOP_WORD_PATH = "/root/install/doc_searcher_index/stop_word.txt";
} else {
STOP_WORD_PATH = "D:/software-download/Java-Official-document/stop_word.txt";
}
}这里面的线上线下路径根据自己的实际情况来定.
实现到这里, 基本就完成了整个 SpringBoot 项目!!