

【Python】用xpath爬取2022热梗保存到txt中并生成词云
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
本文收录于 《python学习笔记》专栏这个专栏主要是我学习Python中遇到的问题学习的新知识或总结的一些知识点我也是初学者可能遇到的问题和大部分新人差不多在这篇专栏里我尽可能的分享出我学习的内容专栏在持续更新中……

hello😁大家好最近新学习了xpath在网站上爬取静态文字就想着做一个东西恰好前几天翻看博客是看到了wordcloud词云⛅这个库就有一个想法涌入我的脑中爬取2022年比较火的几个梗生成词云。
但是受技术的限制好多想法实现不了比如想让词云上某个梗的大小由某个梗的热度决定……
步骤👉
网页原码获取💪
这是我本次用到的文件要把它们放到一个文件夹下图一

图一
xpath的知识我就不展开叙述了不会的可以先去进修一下不懂HTML的朋友也没事。
找到你想爬取的网页按F12,点红框框的按钮然后点击你想爬取的文本内容网页源码就会跳到相应的位置图二
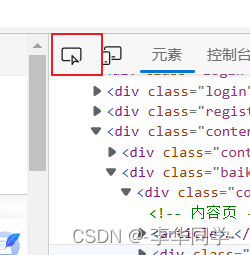
图二
找到你想爬取的某行右击复制Xpath图三

图三
xpath💪
这四行代码就是本程序的核心
from lxml import etree
html = """
要爬取的网页原码"""
parse_html = etree.HTML(html)
# 这里放上复制的xpath路径就行 text意思是要文本内容
index = parse_html.xpath("/html/body/li/div/div[1]/div[2]/div/div[2]/a/i[1]/text()" )列表导TXT💪
这四行的作用是把爬取的内容保存到txt中。
with open('wordcloud.txt', 'w', encoding='utf-8') as f:
# 把列表转换成字符串
Ls = " ".join('%s' % d for d in ls)
# 对文本进行转码和解码不然到txt中就会成乱码
content = Ls.encode("utf-8").decode("unicode_escape")
f.write(Ls)全部代码👉
import jieba
from wordcloud import WordCloud
from lxml import etree
html = """
要爬取的网页原码"""
parse_html = etree.HTML(html)
# 用列表存储的到的文本内容
ls = []
# 用遍历得到多个内容
i = 1
while i <= 10:
index = parse_html.xpath("/html/body/li/div/div[%d]/div[2]/div/div[2]/a/i[1]/text()" % i)
ls.append(index)
i += 1
# print(ls)
# 将得到的内容转变成字符串并保存到TXT文本文档中
with open('wordcloud.txt', 'w', encoding='utf-8') as f:
Ls = " ".join('%s' % d for d in ls)
content = Ls.encode("utf-8").decode("unicode_escape")
# print(content)
f.write(Ls)
# 词云这个是借鉴的链接在文末
def trans_ch(txt):
words = jieba.lcut(txt)
newtxt = ''.join(words)
return newtxt
f = open('wordcloud.txt', 'r', encoding='utf-8')
txt = f.read()
f.close()
txt = trans_ch(txt)
wordcloud = WordCloud(background_color="white",
# 画布长宽
width=500,
height=500,
# 文字的最大数量
max_words=100,
文字大小的最大和最小
max_font_size=120,
min_font_size=20,
contour_width=100,
# 字体
font_path="STCAIYUN.TTF"
).generate(txt)
wordcloud.to_file('词云图.png')可能就有朋友要问了这么几个字还要用这么多代码爬取直接复制不得了吗现在爬取的内容少只是为了练习当真正需要爬取大量数据的时候相比直接复制效率可不止快了一两倍。
今年学习PythonHTMLcss,了解了sql和C语言今年第一次接触编程未来会继续学习。
本文词云制作借鉴文章 python词云制作最全最详细的教程

喜欢的话留下你的赞给予我最好的反馈