

【机器学习】Logistic Regression 逻辑回归算法详解 + Java代码实现
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
文章目录
一、逻辑回归简介
1.1 什么是逻辑回归
逻辑回归Logistic Regression是一种用于解决二分类0 or 1问题的机器学习方法用于估计某种事物的可能性。比如某用户购买某商品的可能性某病人患有某种疾病的可能性以及某广告被用户点击的可能性等。
逻辑回归不是一个回归算法而是一个分类算法
逻辑回归的决策边界可以是非线性的
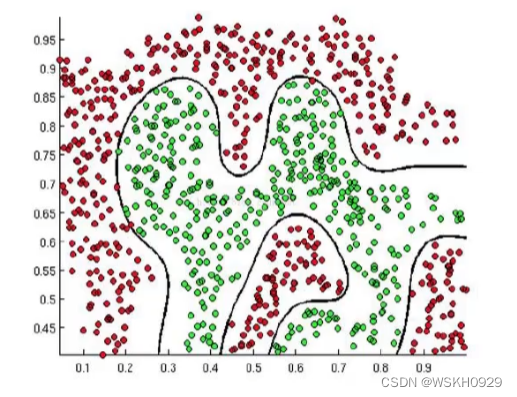
逻辑回归是最简单的分类算法。通常来说在进行分类任务时我们都会用逻辑回归做一个BaseLine然后再尝试其他算法不断改进。
逻辑回归不是只能做二分类它也可以做多分类问题
1.2 Sigmoid函数
Sigmoid函数是逻辑回归实现非线性决策边界的基础
Sigmoid函数的公式:
g ( z ) = 1 1 + e − z g(z)=\frac{1}{1+e^{-z}} g(z)=1+e−z1
特点自变量取值为任意实数值域 [ 0 , 1 ] [0,1] [0,1]
解释: 将任意的输入映射到了[0,1]区间 − ∞ -\infty −∞我们在线性回归中可以得到一个预测值再将该值映射到Sigmoid 函数 中这样就完成了由值到概率的转换也就是分类任务
绘制Sigmoid函数
x = np.arange(-10, 10, 0.01)
y = 1 / (1 + np.exp(-x))
plt.plot(x, y)
plt.plot([0, 0], [max(y), min(y)], 'r--', alpha=0.4)
plt.plot([max(x), min(x)], [0, 0], 'r--', alpha=0.4)
plt.xlabel("$x$")
plt.ylabel("$y$")
plt.show()
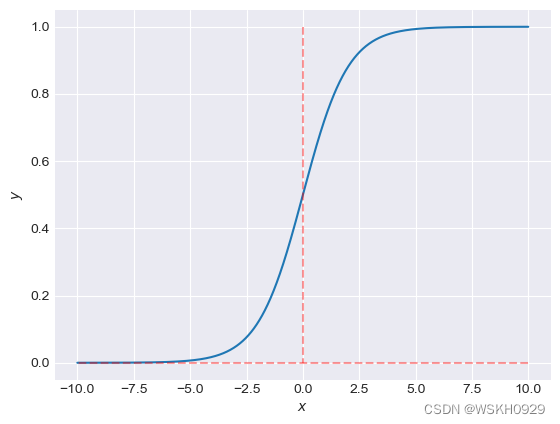
1.3 预测函数
预则函数 :
h θ ( x ) = g ( θ T x ) = 1 1 + e − θ T x h_\theta(x)=g\left(\theta^T x\right)=\frac{1}{1+e^{-\theta^T x}} hθ(x)=g(θTx)=1+e−θTx1
其中
θ 0 + θ 1 x 1 + , … , + θ n x n = ∑ i = 1 n θ i x i = θ T x \theta_0+\theta_1 x_1+, \ldots,+\theta_n x_n=\sum_{i=1}^n \theta_i x_i=\theta^T x θ0+θ1x1+,…,+θnxn=i=1∑nθixi=θTx
分类任务
P ( y = 1 ∣ x ; θ ) = h θ ( x ) P ( y = 0 ∣ x ; θ ) = 1 − h θ ( x ) \begin{aligned} &P(y=1 \mid x ; \theta)=h_\theta(x) \\ &P(y=0 \mid x ; \theta)=1-h_\theta(x) \end{aligned} P(y=1∣x;θ)=hθ(x)P(y=0∣x;θ)=1−hθ(x)
整合 :
P ( y ∣ x ; θ ) = ( h θ ( x ) ) y ( 1 − h θ ( x ) ) 1 − y P(y \mid x ; \theta)=\left(h_\theta(x)\right)^y\left(1-h_\theta(x)\right)^{1-y} P(y∣x;θ)=(hθ(x))y(1−hθ(x))1−y
解释 : 对于二分类任务 ( 0 1 ) (0 1) (01) 整合后y取0只保留 ( 1 − h θ ( x ) ) 1 − y \left(1-h_\theta(x)\right)^{1-y} (1−hθ(x))1−y y \mathrm{y} y 取1只保留 ( h θ ( x ) ) y \left(h_\theta(x)\right)^y (hθ(x))y
似然函数 :
L ( θ ) = ∏ i = 1 m P ( y i ∣ x i ; θ ) = ∏ i = 1 m ( h θ ( x i ) ) y i ( 1 − h θ ( x i ) ) 1 − y i L(\theta)=\prod_{i=1}^m P\left(y_i \mid x_i ; \theta\right)=\prod_{i=1}^m\left(h_\theta\left(x_i\right)\right)^{y_i}\left(1-h_\theta\left(x_i\right)\right)^{1-y_i} L(θ)=i=1∏mP(yi∣xi;θ)=i=1∏m(hθ(xi))yi(1−hθ(xi))1−yi
对数似然 :
l ( θ ) = log L ( θ ) = ∑ i = 1 m ( y i log h θ ( x i ) + ( 1 − y i ) log ( 1 − h θ ( x i ) ) ) l(\theta)=\log L(\theta)=\sum_{i=1}^m\left(y_i \log h_\theta\left(x_i\right)+\left(1-y_i\right) \log \left(1-h_\theta\left(x_i\right)\right)\right) l(θ)=logL(θ)=i=1∑m(yiloghθ(xi)+(1−yi)log(1−hθ(xi)))
此时应用梯度上升求最大值引入 J ( θ ) = − 1 m l ( θ ) J(\theta)=-\frac{1}{m} l(\theta) J(θ)=−m1l(θ) 转换为梯度下降任务
求导过程 :
l ( θ ) = log L ( θ ) = ∑ i = 1 m ( y i log h θ ( x i ) + ( 1 − y i ) log ( 1 − h θ ( x i ) ) ) δ δ θ J ( θ ) = − 1 m ∑ i = 1 m ( y i 1 h θ ( x i ) δ δ θ h θ ( x i ) − ( 1 − y i ) 1 1 − h θ ( x i ) δ δ θ h θ ( x i ) ) = − 1 m ∑ i = 1 m ( y i 1 g ( θ T x i ) − ( 1 − y i ) 1 1 − g ( θ T x i ) ) δ δ j g ( θ T x i ) = − 1 m ∑ i = 1 m ( y i 1 g ( θ T x i ) − ( 1 − y i ) 1 1 − g ( θ T x i ) ) g ( θ T x i ) ( 1 − g ( θ T x i ) ) δ δ θ θ T x i = − 1 m ∑ i = 1 m ( y i ( 1 − g ( θ T x i ) ) − ( 1 − y i ) g ( θ T x i ) ) x i j = − 1 m ∑ i = 1 m ( y i − g ( θ T x i ) ) x i j \begin{aligned} & l(\theta)=\log L(\theta)=\sum_{i=1}^m\left(y_i \log h_\theta\left(x_i\right)+\left(1-y_i\right) \log \left(1-h_\theta\left(x_i\right)\right)\right) \\ & \frac{\delta}{\delta_\theta} J(\theta)=-\frac{1}{m} \sum_{i=1}^m\left(y_i \frac{1}{h_\theta\left(x_i\right)} \frac{\delta}{\delta_\theta} h_\theta\left(x_i\right)-\left(1-\mathrm{y}_{\mathrm{i}}\right) \frac{1}{1-h_\theta\left(x_i\right)} \frac{\delta}{\delta_\theta} h_\theta\left(x_i\right)\right) \\=&-\frac{1}{m} \sum_{i=1}^m\left(y_i \frac{1}{g\left(\theta^{\mathrm{T}} x_i\right)}-\left(1-\mathrm{y}_{\mathrm{i}}\right) \frac{1}{1-g\left(\theta^{\mathrm{T}} x_i\right)}\right) \frac{\delta}{\delta_j} g\left(\theta^{\mathrm{T}} x_i\right) \\=&-\frac{1}{m} \sum_{i=1}^m\left(y_i \frac{1}{g\left(\theta^{\mathrm{T}} x_i\right)}-\left(1-\mathrm{y}_{\mathrm{i}}\right) \frac{1}{1-g\left(\theta^{\mathrm{T}} x_i\right)}\right) g\left(\theta^{\mathrm{T}} x_i\right)\left(1-g\left(\theta^{\mathrm{T}} x_i\right)\right) \frac{\delta}{\delta_\theta} \theta^{\mathrm{T}} x_i \\ &=-\frac{1}{m} \sum_{i=1}^m\left(y_i\left(1-g\left(\theta^{\mathrm{T}} x_i\right)\right)-\left(1-\mathrm{y}_{\mathrm{i}}\right) g\left(\theta^{\mathrm{T}} x_i\right)\right) x_i^j \\=&-\frac{1}{m} \sum_{i=1}^m\left(y_i-g\left(\theta^{\mathrm{T}} x_i\right)\right) x_i^j \end{aligned} ===l(θ)=logL(θ)=i=1∑m(yiloghθ(xi)+(1−yi)log(1−hθ(xi)))δθδJ(θ)=−m1i=1∑m(yihθ(xi)1δθδhθ(xi)−(1−yi)1−hθ(xi)1δθδhθ(xi))−m1i=1∑m(yig(θTxi)1−(1−yi)1−g(θTxi)1)δjδg(θTxi)−m1i=1∑m(yig(θTxi)1−(1−yi)1−g(θTxi)1)g(θTxi)(1−g(θTxi))δθδθTxi=−m1i=1∑m(yi(1−g(θTxi))−(1−yi)g(θTxi))xij−m1i=1∑m(yi−g(θTxi))xij
参数更新 :
θ j : = θ j − α 1 m ∑ i = 1 m ( h θ ( x i ) − y i ) x i j \theta_j:=\theta_j-\alpha \frac{1}{m} \sum_{i=1}^m\left(h_\theta\left(x_i\right)-y_i\right) x_i^j θj:=θj−αm1i=1∑m(hθ(xi)−yi)xij
多分类的softmax:
h θ ( x ( i ) ) = [ p ( y ( i ) = 1 ∣ x ( i ) ; θ ) p ( y ( i ) = 2 ∣ x ( i ) ; θ ) ⋮ p ( y ( i ) = k ∣ x ( i ) ; θ ) ] = 1 ∑ j = 1 k e θ j T x ( i ) [ e o T x ( i ) e σ 2 T x ( i ) ⋮ ⋮ e T k ( i ) x ( i ) ] h_\theta\left(x^{(i)}\right)=\left[\begin{array}{c}p\left(y^{(i)}=1 \mid x^{(i)} ; \theta\right) \\ p\left(y^{(i)}=2 \mid x^{(i)} ; \theta\right) \\ \vdots \\ p\left(y^{(i)}=k \mid x^{(i)} ; \theta\right)\end{array}\right]=\frac{1}{\sum_{j=1}^k e^{\theta_j^T x^{(i)}}}\left[\begin{array}{c}e^{o T} x^{(i)} \\ e^{\sigma_2^T x^{(i)}} \\ \vdots \\ \vdots \\ e^{T_k^{(i)} x^{(i)}}\end{array}\right] hθ(x(i))= p(y(i)=1∣x(i);θ)p(y(i)=2∣x(i);θ)⋮p(y(i)=k∣x(i);θ) =∑j=1keθjTx(i)1 eoTx(i)eσ2Tx(i)⋮⋮eTk(i)x(i)
总结 : 逻辑回归真的真的很好很好用 !
二、逻辑回归实战 - Java代码实现
TrainDataSet 训练集对象
public class TrainDataSet {
/**
* 特征集合
**/
public List<double[]> features = new ArrayList<>();
/**
* 标签集合
**/
public List<Double> labels = new ArrayList<>();
/**
* 特征向量维度
**/
public int featureDim;
public int size() {
return labels.size();
}
public double[] getFeature(int index) {
return features.get(index);
}
public double getLabel(int index) {
return labels.get(index);
}
public void addData(double[] feature, double label) {
if (features.isEmpty()) {
featureDim = feature.length;
} else {
if (featureDim != feature.length) {
throwDimensionMismatchException(feature.length);
}
}
features.add(feature);
labels.add(label);
}
public void throwDimensionMismatchException(int errorLen) {
throw new RuntimeException("DimensionMismatchError: 你应该传入维度为 " + featureDim + " 的特征向量 , 但你传入了维度为 " + errorLen + " 的特征向量");
}
}
LogisticRegression: 逻辑回归算法对象
public class LogisticRegression {
/**
* 训练数据集
**/
TrainDataSet trainDataSet;
/**
* 学习率
**/
double lr;
/**
* 最大迭代次数
**/
int epochs;
/**
* 权重参数矩阵
**/
double[] weights;
/**
* 最佳权重参数矩阵
**/
double[] bestWeights;
/**
* 最佳准确率
**/
double bestAcc;
/**
* @param trainDataSet: 训练数据集
* @param lr: 学习率
* @param epochs: 最大迭代次数
*/
public LogisticRegression(TrainDataSet trainDataSet, double lr, int epochs) {
this.trainDataSet = trainDataSet;
this.lr = lr;
this.epochs = epochs;
}
// 初始化模型
public void initModel() {
weights = new double[trainDataSet.featureDim];
bestWeights = new double[trainDataSet.featureDim];
bestAcc = 0d;
}
// 训练函数
public void fit() {
initModel();
for (int epoch = 1; epoch <= epochs; epoch++) {
// 对整个训练集进行预测
double[] predicts = new double[trainDataSet.size()];
for (int i = 0; i < predicts.length; i++) {
predicts[i] = sigmoid(dotProduct(weights, trainDataSet.getFeature(i)));
}
// 计算 MSE-Loss
double loss = 0d;
for (int i = 0; i < predicts.length; i++) {
loss += Math.pow(predicts[i] - trainDataSet.getLabel(i), 2);
}
loss /= trainDataSet.size();
double acc = calcAcc(predicts);
if (epoch % 1000 == 0 || epoch == 1) {
System.out.println("epoch: " + epoch + " , loss: " + loss + " , acc: " + acc);
}
if (acc > bestAcc) {
bestAcc = acc;
bestWeights = weights.clone();
}
// 梯度下降法更新参数
double[] diffs = new double[trainDataSet.size()];
for (int i = 0; i < trainDataSet.size(); i++) {
diffs[i] = trainDataSet.getLabel(i) - predicts[i];
}
for (int i = 0; i < weights.length; i++) {
double step = 0d;
for (int j = 0; j < trainDataSet.size(); j++) {
step += trainDataSet.getFeature(j)[i] * diffs[j];
}
step = step / trainDataSet.size();
weights[i] += (lr * step);
}
}
}
// 计算正确率
private double calcAcc(double[] predicts) {
int acc = 0;
for (int i = 0; i < trainDataSet.size(); i++) {
if ((int) Math.round(predicts[i]) == trainDataSet.getLabel(i)) {
acc++;
}
}
return (double) acc / trainDataSet.size();
}
// 传入特征返回预测值用最佳的权重矩阵进行预测
public int predict(double[] feature) {
if (feature.length != trainDataSet.featureDim) {
trainDataSet.throwDimensionMismatchException(feature.length);
}
return (int) Math.round(sigmoid(dotProduct(bestWeights, feature)));
}
// 向量点积
private double dotProduct(double[] vector1, double[] vector2) {
double res = 0d;
for (int i = 0; i < vector1.length; i++) {
res += (vector1[i] * vector2[i]);
}
return res;
}
// sigmoid 函数
public double sigmoid(double x) {
return 1.0 / (1.0 + Math.exp(-x));
}
}
Run: 测试类
public class Run {
public static void main(String[] args) {
// 随机数种子
long seed = 929L;
// 训练集大小
int dataSize = 100;
// 特征向量维度数
int featureDim = 60;
// 随机构造数据集
TrainDataSet trainDataSet = createRandomTrainDataSet(seed, dataSize, featureDim);
// 开始逻辑回归算法
long startTime = System.currentTimeMillis();
LogisticRegression logisticRegression = new LogisticRegression(trainDataSet, 2e-03, 50000);
logisticRegression.fit();
System.out.println("用时: " + (System.currentTimeMillis() - startTime) / 1000d + " s");
}
// 随机生成测试数据
public static TrainDataSet createRandomTrainDataSet(long seed, int dataSize, int featureDim) {
TrainDataSet trainDataSet = new TrainDataSet();
Random random = new Random(seed);
for (int i = 0; i < dataSize; i++) {
double[] feature = new double[featureDim];
double sum = 0d;
for (int j = 0; j < feature.length; j++) {
feature[j] = random.nextDouble();
sum += feature[j];
}
double label = sum >= 0.5 * featureDim ? 1 : 0;
trainDataSet.addData(feature, label);
}
return trainDataSet;
}
}
输出
epoch: 1 , loss: 0.25 , acc: 0.57
epoch: 1000 , loss: 0.23009206054491824 , acc: 0.57
epoch: 2000 , loss: 0.22055342908355904 , acc: 0.57
epoch: 3000 , loss: 0.2119690514733919 , acc: 0.62
epoch: 4000 , loss: 0.20424003587074643 , acc: 0.68
epoch: 5000 , loss: 0.19727002863958823 , acc: 0.71
epoch: 6000 , loss: 0.19096949150899337 , acc: 0.72
epoch: 7000 , loss: 0.18525745498286608 , acc: 0.77
epoch: 8000 , loss: 0.18006202781346625 , acc: 0.77
epoch: 9000 , loss: 0.1753201537243613 , acc: 0.8
epoch: 10000 , loss: 0.1709769595639883 , acc: 0.8
epoch: 11000 , loss: 0.16698491959902464 , acc: 0.79
epoch: 12000 , loss: 0.16330297319030188 , acc: 0.82
epoch: 13000 , loss: 0.15989567356751072 , acc: 0.84
epoch: 14000 , loss: 0.1567324071471881 , acc: 0.84
epoch: 15000 , loss: 0.15378669947061832 , acc: 0.84
epoch: 16000 , loss: 0.15103561034798546 , acc: 0.84
epoch: 17000 , loss: 0.14845921356649672 , acc: 0.84
epoch: 18000 , loss: 0.1460401531041619 , acc: 0.85
epoch: 19000 , loss: 0.143763266598652 , acc: 0.85
epoch: 20000 , loss: 0.141615266856612 , acc: 0.85
epoch: 21000 , loss: 0.13958447284858422 , acc: 0.85
epoch: 22000 , loss: 0.1376605825635673 , acc: 0.85
epoch: 23000 , loss: 0.1358344810954265 , acc: 0.85
epoch: 24000 , loss: 0.13409807829499976 , acc: 0.85
epoch: 25000 , loss: 0.13244417119628302 , acc: 0.85
epoch: 26000 , loss: 0.13086632719356164 , acc: 0.85
epoch: 27000 , loss: 0.12935878460708283 , acc: 0.85
epoch: 28000 , loss: 0.12791636783482388 , acc: 0.85
epoch: 29000 , loss: 0.12653441475794497 , acc: 0.85
epoch: 30000 , loss: 0.12520871445955495 , acc: 0.85
epoch: 31000 , loss: 0.12393545364204453 , acc: 0.85
epoch: 32000 , loss: 0.12271117039803882 , acc: 0.85
epoch: 33000 , loss: 0.12153271421325021 , acc: 0.85
epoch: 34000 , loss: 0.12039721126413588 , acc: 0.85
epoch: 35000 , loss: 0.11930203422599839 , acc: 0.85
epoch: 36000 , loss: 0.11824477593360722 , acc: 0.85
epoch: 37000 , loss: 0.1172232263412268 , acc: 0.85
epoch: 38000 , loss: 0.11623535231592816 , acc: 0.86
epoch: 39000 , loss: 0.11527927987040722 , acc: 0.86
epoch: 40000 , loss: 0.11435327850180353 , acc: 0.86
epoch: 41000 , loss: 0.11345574735333493 , acc: 0.86
epoch: 42000 , loss: 0.11258520295767636 , acc: 0.86
epoch: 43000 , loss: 0.11174026835632704 , acc: 0.86
epoch: 44000 , loss: 0.11091966341890613 , acc: 0.86
epoch: 45000 , loss: 0.11012219621134119 , acc: 0.86
epoch: 46000 , loss: 0.10934675528306022 , acc: 0.86
epoch: 47000 , loss: 0.10859230276120614 , acc: 0.86
epoch: 48000 , loss: 0.10785786815509599 , acc: 0.86
epoch: 49000 , loss: 0.10714254278709882 , acc: 0.86
epoch: 50000 , loss: 0.10644547477714164 , acc: 0.86