基于梅尔频谱的音频信号分类识别(Pytorch)_pytroch音频分类
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
基于梅尔频谱的音频信号分类识别(Pytorch)
目录
本项目将使用Pytorch实现一个简单的的音频信号分类器可应用于机械信号分类识别鸟叫声信号识别等应用场景。
项目使用librosa进行音频信号处理backbone使用mobilenet_v2在Urbansound8K数据上最终收敛的准确率在训练集99%测试集96%如果想进一步提高识别准确率可以使用更重的backbone和更多的数据增强方法。
【完整的项目代码】基于梅尔频谱的音频信号分类识别(Pytorch)
【尊重原创转载请注明出处】https://panjinquan.blog.csdn.net/article/details/120601437
目录
1. 项目结构

2. 环境配置
pytorch==1.7.1,其他依赖库请使用pip命令安装libsora和pyaudio,pydub等库
librosa==0.8.1
pyaudio==0.2.11
pydub==0.23.1
3.音频识别基础知识
(1) STFT和声谱图(spectrogram)
声音信号是一维信号直观上只能看到时域信息不能看到频域信息。通过傅里叶变换(FT)可以变换到频域但是丢失了时域信息无法看到时频关系。为了解决这个问题产生了很多方法短时傅里叶变换小波等都是很常用的时频分析方法。
短时傅里叶变换(STFT)就是对短时的信号做傅里叶变换。原理如下对一段长语音信号分帧、加窗再对每一帧做傅里叶变换之后把每一帧的结果沿另一维度堆叠得到一张图类似于二维信号这张图就是声谱图。
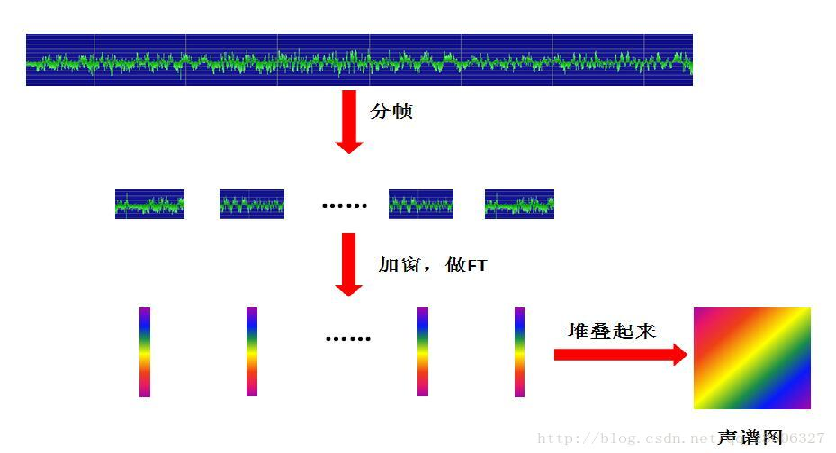
(2) 梅尔频谱
人耳能听到的频率范围是20-20000HZ但是人耳对HZ单位不是线性敏感而是对低HZ敏感对高HZ不敏感将HZ频率转化为梅尔频率则人耳对频率的感知度就变为线性。
例如如果我们适应了1000Hz的音调如果把音调频率提高到2000Hz我们的耳朵只能觉察到频率提高了一点点根本察觉不到频率提高了一倍 。
将普通频率转化到Mel频率的公式是
![]()
在Mel频域内人对音调的感知度为线性关系。举例来说如果两段语音的Mel频率相差两倍则人耳听起来两者的音调也相差两倍。

(3) 梅尔频率倒谱MFCC
:梅尔频率倒谱系数简称MFCCMel-frequency cepstral coefficients)
- 梅尔频谱就是一般的频谱图加上梅尔滤波函数这一步是为了模拟人耳听觉对实际频率的敏感程度
- 梅尔倒谱就是再对梅尔频谱进行一次频谱分析具体就是对梅尔频谱取对数然后做DCT变换目的是抽取频谱图的轮廓信息这个比较能代表语音的特征。
- 如果取低频的13位就是最经典的语音特征mfcc了
(4) MFCC特征的过程
- 先对语音进行预加重、分帧和加窗
- 对每一个短时分析窗通过FFT得到对应的频谱
- 将上面的频谱通过Mel滤波器组得到Mel频谱
- 在Mel频谱上面进行倒谱分析取对数做逆变换实际逆变换一般是通过DCT离散余弦变换来实现
- 取DCT后的第2个到第13个系数作为MFCC系数获得Mel频率倒谱系数MFCC这个MFCC就是这帧语音的特征了

4.数据处理
1数据集Urbansound8K
Urbansound8K是目前应用较为广泛的用于自动城市环境声分类研究的公共数据集
包含10个分类空调声、汽车鸣笛声、儿童玩耍声、狗叫声、钻孔声、引擎空转声、枪声、手提钻、警笛声和街道音乐声,类别定义如下
data/UrbanSound8K/class_name.txt
air_conditioner car_horn children_playing dog_bark drilling engine_idling gun_shot jackhammer siren street_music
数据集下载https://zenodo.org/record/1203745/files/UrbanSound8K.tar.gz
2自定义数据集
可以自己录制音频信号制作自己的数据集参考[audio/dataloader/record_audio.py]
每个文件夹存放一个类别的音频数据每条音频数据长度在3秒左右,建议每类的音频数据均衡
生产train和test数据列表参考[audio/dataloader/create_data.py],train.txt和test.txt格式如下
[path/to/audio.wav,labels_name]
如:
ID1/audio.wav,label_names1
ID2/audio.wav,label_names2
...
IDn/audio.wav,label_namesn
同时你需要定义class_name指定类别的序列训练代码会根据你的class_name进行训练
label_names1 label_names2 ... label_namesn
3音频特征提取:
音频信号是一维的语音信号不能直接用于模型训练需要使用librosa将音频转为梅尔频谱Mel Spectrogram。
librosa提供python接口在音频、乐音信号的分析中经常用到
wav, sr = librosa.load(data_path, sr=16000)
# 使用librosa获得音频的梅尔频谱
spec_image = librosa.feature.melspectrogram(y=wav, sr=sr, hop_length=256)
# 计算音频信号的MFCC
spec_image = librosa.feature.mfcc(y=wav, sr=sr)librosa.feature.mfcc实现MFCC源码如下
# -- Mel spectrogram and MFCCs -- #
def mfcc(y=None, sr=22050, S=None, n_mfcc=20, dct_type=2, norm="ortho", lifter=0, **kwargs):
"""Mel-frequency cepstral coefficients (MFCCs)
"""
if S is None:
# 先调用melspectrogram计算梅尔频谱然后取对数:power_to_db
S = power_to_db(melspectrogram(y=y, sr=sr, **kwargs))
# 最后进行DCT变换
M = scipy.fftpack.dct(S, axis=0, type=dct_type, norm=norm)[:n_mfcc]
if lifter > 0:
M *= (1 + (lifter / 2) * np.sin(np.pi * np.arange(1, 1 + n_mfcc, dtype=M.dtype) / lifter)[:, np.newaxis])
return M
elif lifter == 0:
return M
else:
raise ParameterError("MFCC lifter={} must be a non-negative number".format(lifter))
可以看到librosa库中梅尔倒谱就是再对梅尔频谱取对数然后做DCT变换
关于librosa的使用方法请参考
5.训练Pipeline
1构建训练和测试数据
def build_dataset(self, cfg):
"""构建训练数据和测试数据"""
input_shape = eval(cfg.input_shape)
# 获取数据
train_dataset = AudioDataset(cfg.train_data, data_dir=cfg.data_dir, mode='train', spec_len=input_shape[3])
train_loader = DataLoader(dataset=train_dataset, batch_size=cfg.batch_size, shuffle=True,
num_workers=cfg.num_workers)
test_dataset = AudioDataset(cfg.test_data, data_dir=cfg.data_dir, mode='test', spec_len=input_shape[3])
test_loader = DataLoader(dataset=test_dataset, batch_size=cfg.batch_size, shuffle=False,
num_workers=cfg.num_workers)
print("train nums:{}".format(len(train_dataset)))
print("test nums:{}".format(len(test_dataset)))
return train_loader, test_loader由于librosa.load加载音频数据特别慢建议使用cache先进行缓存方便加速
def load_audio(audio_file, cache=False):
"""
加载并预处理音频
:param audio_file:
:param cache: librosa.load加载音频数据特别慢建议使用进行缓存进行加速
:return:
"""
# 读取音频数据
cache_path = audio_file + ".pk"
# t = librosa.get_duration(filename=audio_file)
if cache and os.path.exists(cache_path):
tmp = open(cache_path, 'rb')
wav, sr = pickle.load(tmp)
else:
wav, sr = librosa.load(audio_file, sr=16000)
if cache:
f = open(cache_path, 'wb')
pickle.dump([wav, sr], f)
f.close()
# Compute a mel-scaled spectrogram: 梅尔频谱图
spec_image = librosa.feature.melspectrogram(y=wav, sr=sr, hop_length=256)
return spec_image2构建backbone模型
backbone是一个基于CNN+FC的网络结构与图像CNN分类模型不同的是图像CNN分类模型的输入维度(batch,3,H,W)输入数据depth=3而音频信号的梅尔频谱图是深度为depth=1可以认为是灰度图输入维度(batch,1,H,W)因此实际使用中只需要将传统的CNN图像分类的backbone的第一层卷积层的in_channels=1即可。需要注意的是由于维度不一致导致不能使用imagenet的pretrained模型。
当然可以将梅尔频谱图(灰度图)是转为3通道RGB图这样就跟普通的RGB图像没有什么区别了也可以imagenet的pretrained模型如
# 将梅尔频谱图(灰度图)是转为为3通道RGB图 spec_image = cv2.cvtColor(spec_image, cv2.COLOR_GRAY2RGB)
def build_model(self, cfg):
if cfg.net_type == "mbv2":
model = mobilenet_v2.mobilenet_v2(num_classes=cfg.num_classes)
elif cfg.net_type == "resnet34":
model = resnet.resnet34(num_classes=args.num_classes)
elif cfg.net_type == "resnet18":
model = resnet.resnet18(num_classes=args.num_classes)
else:
raise Exception("Error:{}".format(cfg.net_type))
model.to(self.device)
return model3训练参数配置
相关的命令行参数可参考
def get_parser():
data_dir = "/home/dataset/UrbanSound8K/audio"
train_data = 'data/UrbanSound8K/train.txt'
test_data = 'data/UrbanSound8K/test.txt'
class_name = 'data/UrbanSound8K/class_name.txt'
parser = argparse.ArgumentParser(description=__doc__)
parser.add_argument('--batch_size', type=int, default=32, help='训练的批量大小')
parser.add_argument('--num_workers', type=int, default=8, help='读取数据的线程数量')
parser.add_argument('--num_epoch', type=int, default=100, help='训练的轮数')
parser.add_argument('--class_name', type=str, default=class_name, help='类别文件')
parser.add_argument('--learning_rate', type=float, default=1e-3, help='初始学习率的大小')
parser.add_argument('--input_shape', type=str, default='(None, 1, 128, 128)', help='数据输入的形状')
parser.add_argument('--gpu_id', type=int, default=0, help='GPU ID')
parser.add_argument('--net_type', type=str, default="mbv2", help='backbone')
parser.add_argument('--data_dir', type=str, default=data_dir, help='数据路径')
parser.add_argument('--train_data', type=str, default=train_data, help='训练数据的数据列表路径')
parser.add_argument('--test_data', type=str, default=test_data, help='测试数据的数据列表路径')
parser.add_argument('--work_dir', type=str, default='work_space/', help='模型保存的路径')
return parser配置好数据路径其他参数默认设置即可以开始训练了
# data_dir是你的数据路径
python train.py --data_dir="dataset/UrbanSound8K/audio1"
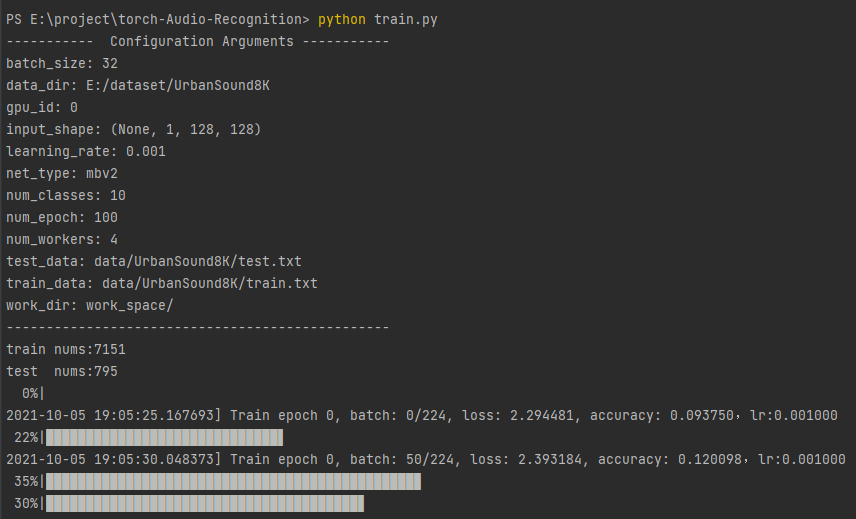
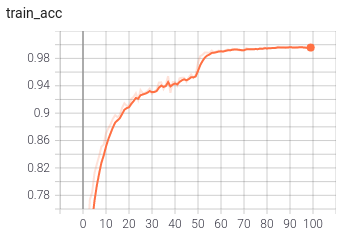
训练完成使用mobilenet_v2,最终训练集准确率99%左右测试集96%左右看起来有点过拟合了。
如果想进一步提高识别准确率可以使用更重的backbone如resnet34,采用更多的数据增强方法提高模型的泛发性。
 |  |
完整的训练代码train.py
import argparse
import os
import numpy as np
import torch
import tensorboardX as tensorboard
from datetime import datetime
from easydict import EasyDict
from tqdm import tqdm
from torch.utils.data import DataLoader
from torch.optim.lr_scheduler import StepLR, MultiStepLR
from audio.dataloader.audio_dataset import AudioDataset
from audio.utils.utility import print_arguments
from audio.utils import file_utils
from audio.models import mobilenet_v2, resnet
class Train(object):
"""Training Pipeline"""
def __init__(self, cfg):
cfg = EasyDict(cfg.__dict__)
self.device = "cuda:{}".format(cfg.gpu_id) if torch.cuda.is_available() else "cpu"
self.num_epoch = cfg.num_epoch
self.net_type = cfg.net_type
self.work_dir = os.path.join(cfg.work_dir, self.net_type)
self.model_dir = os.path.join(self.work_dir, "model")
self.log_dir = os.path.join(self.work_dir, "log")
file_utils.create_dir(self.model_dir)
file_utils.create_dir(self.log_dir)
self.tensorboard = tensorboard.SummaryWriter(self.log_dir)
self.train_loader, self.test_loader = self.build_dataset(cfg)
# 获取模型
self.model = self.build_model(cfg)
# 获取优化方法
self.optimizer = torch.optim.Adam(params=self.model.parameters(),
lr=cfg.learning_rate,
weight_decay=5e-4)
# 获取学习率衰减函数
self.scheduler = MultiStepLR(self.optimizer, milestones=[50, 80], gamma=0.1)
# 获取损失函数
self.losses = torch.nn.CrossEntropyLoss()
def build_dataset(self, cfg):
"""构建训练数据和测试数据"""
input_shape = eval(cfg.input_shape)
# 加载训练数据
train_dataset = AudioDataset(cfg.train_data,
class_name=cfg.class_name,
data_dir=cfg.data_dir,
mode='train',
spec_len=input_shape[3])
train_loader = DataLoader(dataset=train_dataset, batch_size=cfg.batch_size, shuffle=True,
num_workers=cfg.num_workers)
cfg.class_name = train_dataset.class_name
cfg.class_dict = train_dataset.class_dict
cfg.num_classes = len(cfg.class_name)
# 加载测试数据
test_dataset = AudioDataset(cfg.test_data,
class_name=cfg.class_name,
data_dir=cfg.data_dir,
mode='test',
spec_len=input_shape[3])
test_loader = DataLoader(dataset=test_dataset, batch_size=cfg.batch_size, shuffle=False,
num_workers=cfg.num_workers)
print("train nums:{}".format(len(train_dataset)))
print("test nums:{}".format(len(test_dataset)))
return train_loader, test_loader
def build_model(self, cfg):
"""构建模型"""
if cfg.net_type == "mbv2":
model = mobilenet_v2.mobilenet_v2(num_classes=cfg.num_classes)
elif cfg.net_type == "resnet34":
model = resnet.resnet34(num_classes=args.num_classes)
elif cfg.net_type == "resnet18":
model = resnet.resnet18(num_classes=args.num_classes)
else:
raise Exception("Error:{}".format(cfg.net_type))
model.to(self.device)
return model
def epoch_test(self, epoch):
"""模型测试"""
loss_sum = []
accuracies = []
self.model.eval()
with torch.no_grad():
for step, (inputs, labels) in enumerate(tqdm(self.test_loader)):
inputs = inputs.to(self.device)
labels = labels.to(self.device).long()
output = self.model(inputs)
# 计算损失值
loss = self.losses(output, labels)
# 计算准确率
output = torch.nn.functional.softmax(output, dim=1)
output = output.data.cpu().numpy()
output = np.argmax(output, axis=1)
labels = labels.data.cpu().numpy()
acc = np.mean((output == labels).astype(int))
accuracies.append(acc)
loss_sum.append(loss)
acc = sum(accuracies) / len(accuracies)
loss = sum(loss_sum) / len(loss_sum)
print("Test epoch:{:3.3f},Acc:{:3.3f},loss:{:3.3f}".format(epoch, acc, loss))
print('=' * 70)
return acc, loss
def epoch_train(self, epoch):
"""模型训练"""
loss_sum = []
accuracies = []
self.model.train()
for step, (inputs, labels) in enumerate(tqdm(self.train_loader)):
inputs = inputs.to(self.device)
labels = labels.to(self.device).long()
output = self.model(inputs)
# 计算损失值
loss = self.losses(output, labels)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
# 计算准确率
output = torch.nn.functional.softmax(output, dim=1)
output = output.data.cpu().numpy()
output = np.argmax(output, axis=1)
labels = labels.data.cpu().numpy()
acc = np.mean((output == labels).astype(int))
accuracies.append(acc)
loss_sum.append(loss)
if step % 50 == 0:
lr = self.optimizer.state_dict()['param_groups'][0]['lr']
print('[%s] Train epoch %d, batch: %d/%d, loss: %f, accuracy: %flr:%f' % (
datetime.now(), epoch, step, len(self.train_loader), sum(loss_sum) / len(loss_sum),
sum(accuracies) / len(accuracies), lr))
acc = sum(accuracies) / len(accuracies)
loss = sum(loss_sum) / len(loss_sum)
print("Train epoch:{:3.3f},Acc:{:3.3f},loss:{:3.3f}".format(epoch, acc, loss))
print('=' * 70)
return acc, loss
def run(self):
# 开始训练
for epoch in range(self.num_epoch):
train_acc, train_loss = self.epoch_train(epoch)
test_acc, test_loss = self.epoch_test(epoch)
self.tensorboard.add_scalar("train_acc", train_acc, epoch)
self.tensorboard.add_scalar("train_loss", train_loss, epoch)
self.tensorboard.add_scalar("test_acc", test_acc, epoch)
self.tensorboard.add_scalar("test_loss", test_loss, epoch)
self.scheduler.step()
self.save_model(epoch, test_acc)
def save_model(self, epoch, acc):
"""保持模型"""
model_path = os.path.join(self.model_dir, 'model_{:0=3d}_{:.3f}.pth'.format(epoch, acc))
if not os.path.exists(os.path.dirname(model_path)):
os.makedirs(os.path.dirname(model_path))
torch.jit.save(torch.jit.script(self.model), model_path)
def get_parser():
data_dir = "/home/dataset/UrbanSound8K/audio"
train_data = 'data/UrbanSound8K/train.txt'
test_data = 'data/UrbanSound8K/test.txt'
class_name = 'data/UrbanSound8K/class_name.txt'
parser = argparse.ArgumentParser(description=__doc__)
parser.add_argument('--batch_size', type=int, default=32, help='训练的批量大小')
parser.add_argument('--num_workers', type=int, default=8, help='读取数据的线程数量')
parser.add_argument('--num_epoch', type=int, default=100, help='训练的轮数')
parser.add_argument('--class_name', type=str, default=class_name, help='类别文件')
parser.add_argument('--learning_rate', type=float, default=1e-3, help='初始学习率的大小')
parser.add_argument('--input_shape', type=str, default='(None, 1, 128, 128)', help='数据输入的形状')
parser.add_argument('--gpu_id', type=int, default=0, help='GPU ID')
parser.add_argument('--net_type', type=str, default="mbv2", help='backbone')
parser.add_argument('--data_dir', type=str, default=data_dir, help='数据路径')
parser.add_argument('--train_data', type=str, default=train_data, help='训练数据的数据列表路径')
parser.add_argument('--test_data', type=str, default=test_data, help='测试数据的数据列表路径')
parser.add_argument('--work_dir', type=str, default='work_space/', help='模型保存的路径')
return parser
if __name__ == '__main__':
parser = get_parser()
args = parser.parse_args()
print_arguments(args)
t = Train(args)
t.run()
6.预测demo.py
【完整的项目代码】基于梅尔频谱的音频信号分类识别(Pytorch)
import os
import cv2
import argparse
import librosa
import torch
import numpy as np
from audio.dataloader.audio_dataset import load_audio, normalization
from audio.dataloader.record_audio import record_audio
from audio.utils import file_utils, image_utils
class Predictor(object):
def __init__(self, cfg):
# self.device = "cuda:{}".format(cfg.gpu_id) if torch.cuda.is_available() else "cpu"
self.device = "cpu"
self.class_name, self.class_dict = file_utils.parser_classes(cfg.class_name, split=None)
self.input_shape = eval(cfg.input_shape)
self.spec_len = self.input_shape[3]
self.model = self.build_model(cfg.model_file)
def build_model(self, model_file):
# 加载模型
model = torch.jit.load(model_file, map_location="cpu")
model.to(self.device)
model.eval()
return model
def inference(self, input_tensors):
with torch.no_grad():
input_tensors = input_tensors.to(self.device)
output = self.model(input_tensors)
return output
def pre_process(self, spec_image):
"""音频数据预处理"""
if spec_image.shape[1] > self.spec_len:
input = spec_image[:, 0:self.spec_len]
else:
input = np.zeros(shape=(self.spec_len, self.spec_len), dtype=np.float32)
input[:, 0:spec_image.shape[1]] = spec_image
input = normalization(input)
input = input[np.newaxis, np.newaxis, :]
input_tensors = np.concatenate([input])
input_tensors = torch.tensor(input_tensors, dtype=torch.float32)
return input_tensors
def post_process(self, output):
"""输出结果后处理"""
scores = torch.nn.functional.softmax(output, dim=1)
scores = scores.data.cpu().numpy()
# 显示图片并输出结果最大的label
label = np.argmax(scores, axis=1)
score = scores[:, label]
label = [self.class_name[l] for l in label]
return label, score
def detect(self, audio_file):
"""
:param audio_file: 音频文件
:return: label:预测音频的label
score: 预测音频的置信度
"""
spec_image = load_audio(audio_file)
input_tensors = self.pre_process(spec_image)
# 执行预测
output = self.inference(input_tensors)
label, score = self.post_process(output)
return label, score
def detect_file_dir(self, file_dir):
"""
:param file_dir: 音频文件目录
:return:
"""
file_list = file_utils.get_files_lists(file_dir, postfix=["*.wav"])
for file in file_list:
print(file)
label, score = self.detect(file)
print("pred-label:{}, score:{}".format(label, score))
print("---" * 20)
def detect_record_audio(self, audio_dir):
"""
:param audio_dir: 录制音频并进行识别
:return:
"""
time = file_utils.get_time()
file = os.path.join(audio_dir, time + ".wav")
record_audio(file)
label, score = self.detect(file)
print(file)
print("pred-label:{}, score:{}".format(label, score))
print("---"*20)
def get_parser():
model_file = 'data/pretrained/model_075_0.965.pth'
file_dir = "data/audio"
class_name = 'data/UrbanSound8K/class_name.txt'
parser = argparse.ArgumentParser(description=__doc__)
parser.add_argument('--class_name', type=str, default=class_name, help='类别文件')
parser.add_argument('--input_shape', type=str, default='(None, 1, 128, 128)', help='数据输入的形状')
parser.add_argument('--net_type', type=str, default="mbv2", help='backbone')
parser.add_argument('--gpu_id', type=int, default=0, help='GPU ID')
parser.add_argument('--model_file', type=str, default=model_file, help='模型文件')
parser.add_argument('--file_dir', type=str, default=file_dir, help='音频文件的目录')
return parser
if __name__ == '__main__':
parser = get_parser()
args = parser.parse_args()
p = Predictor(args)
p.detect_file_dir(file_dir=args.file_dir)
# audio_dir = 'data/record_audio'
# p.detect_record_audio(audio_dir=audio_dir)
7.源码下载
【完整的项目代码】基于梅尔频谱的音频信号分类识别(Pytorch)
更多AI博客请参考
人体关键点检测需要用到人体检测请查看鄙人另一篇博客2D Pose人体关键点实时检测(Python/Android /C++ Demo)_pan_jinquan的博客-CSDN博客