

Windows 上下载并提取 Wikipedia
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
下载资源
很久以前看过了 Wikipedia 是支持 dump 的不得不说真是造福人类的壮举。我其实也用不到这个但是看见不少人是用来做 NLP 语料训练的。不过最近我也想尝试一些新的东西我就是单纯想要这个文本数据所以就去把它给下载下来了。这个东西很大的下载可能需要很久的时间所以需要自己解决这个过程中面临的问题。
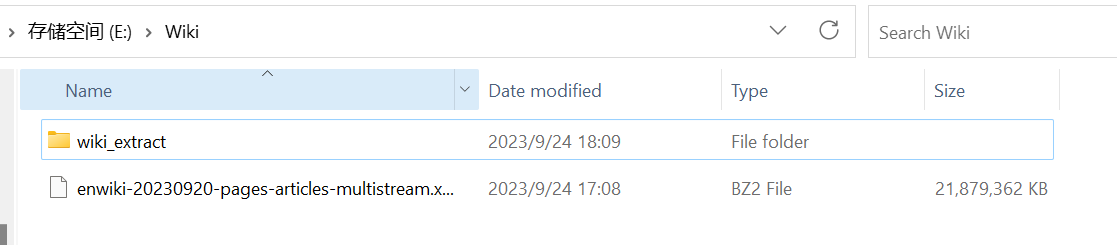
我下载的是 English Wikipedia差不多 20 G上面的 wiki_extract 是我自己建立的空目录准备用来存放提取的文件的。
提取资源
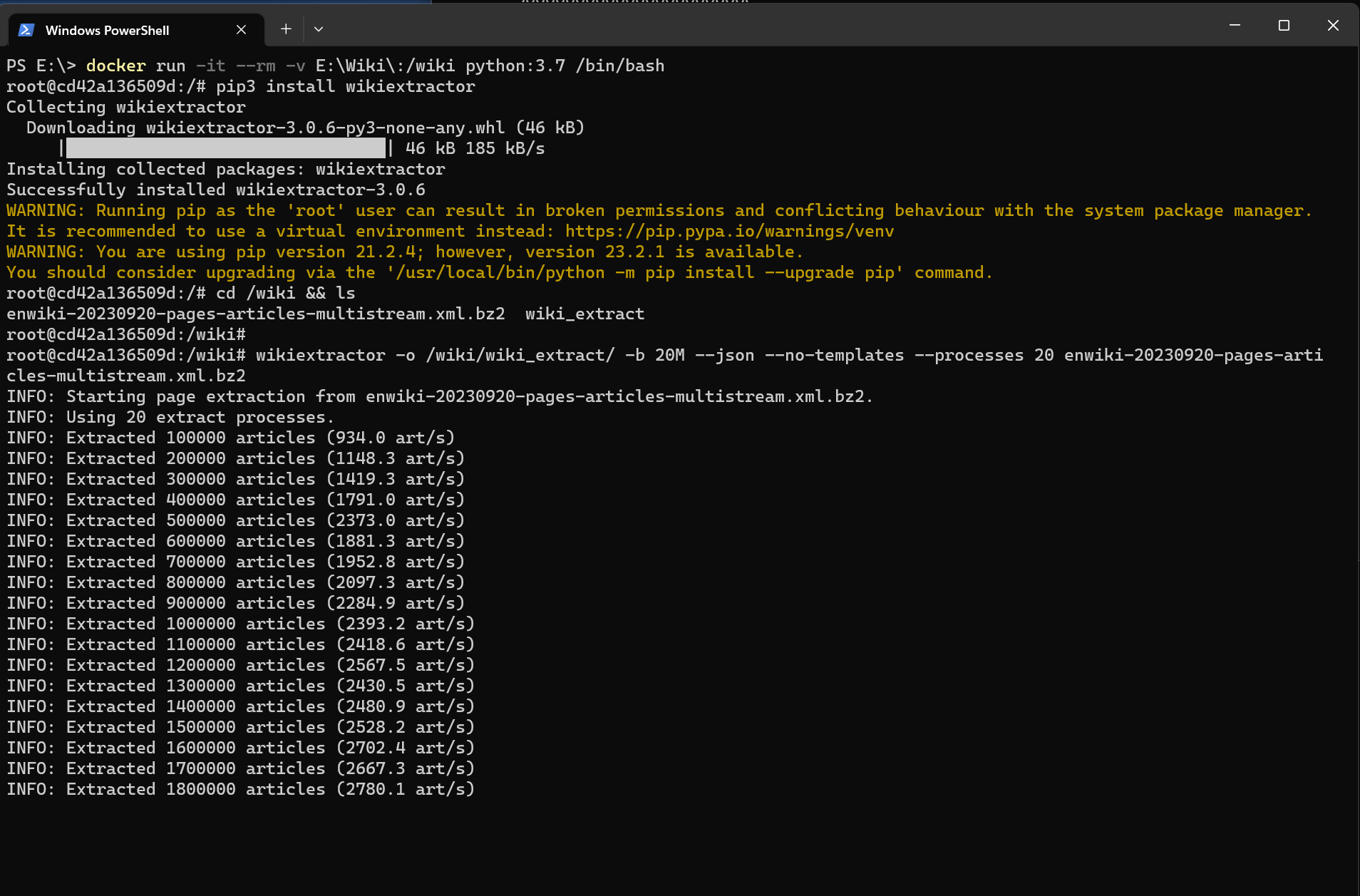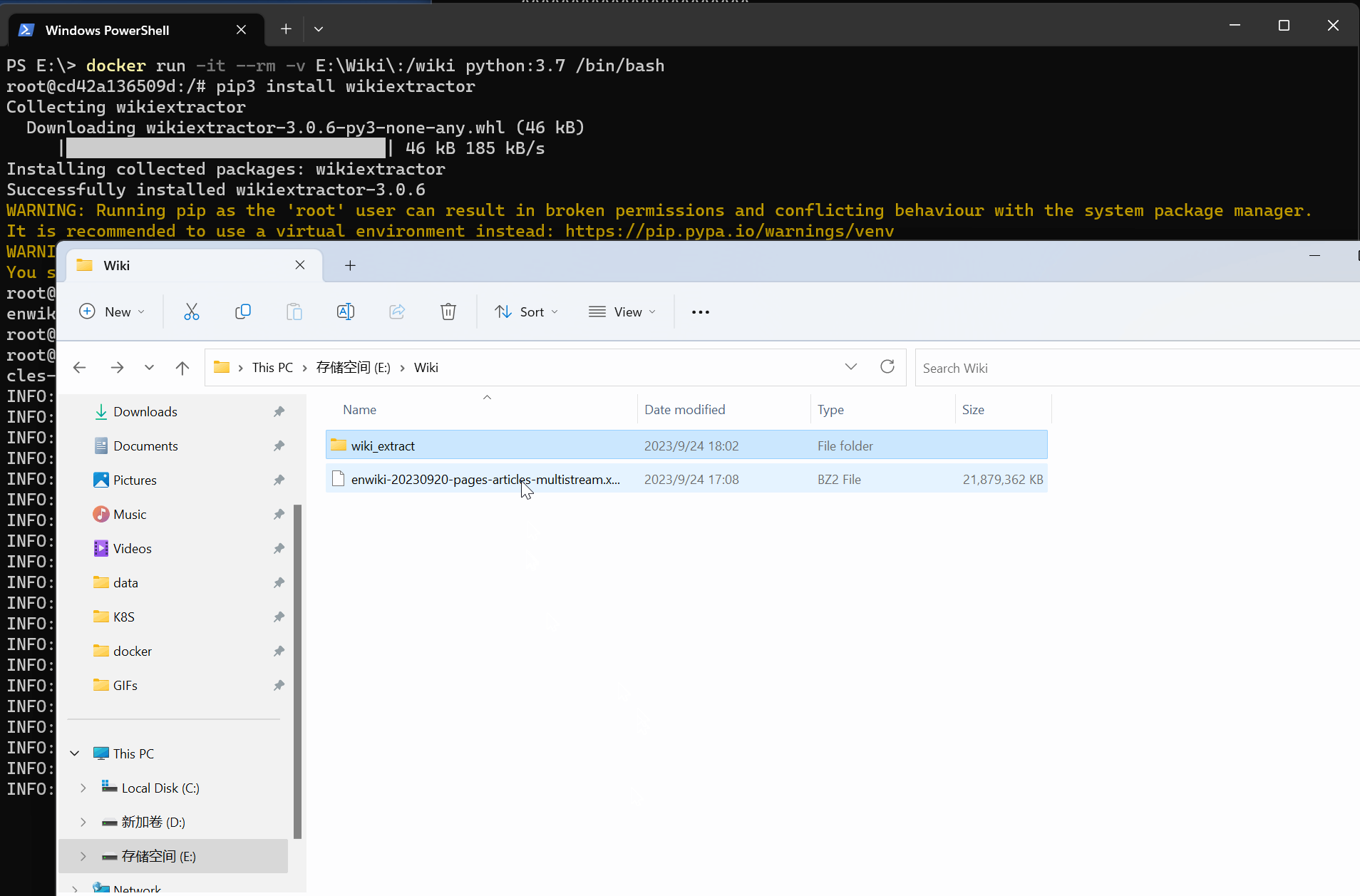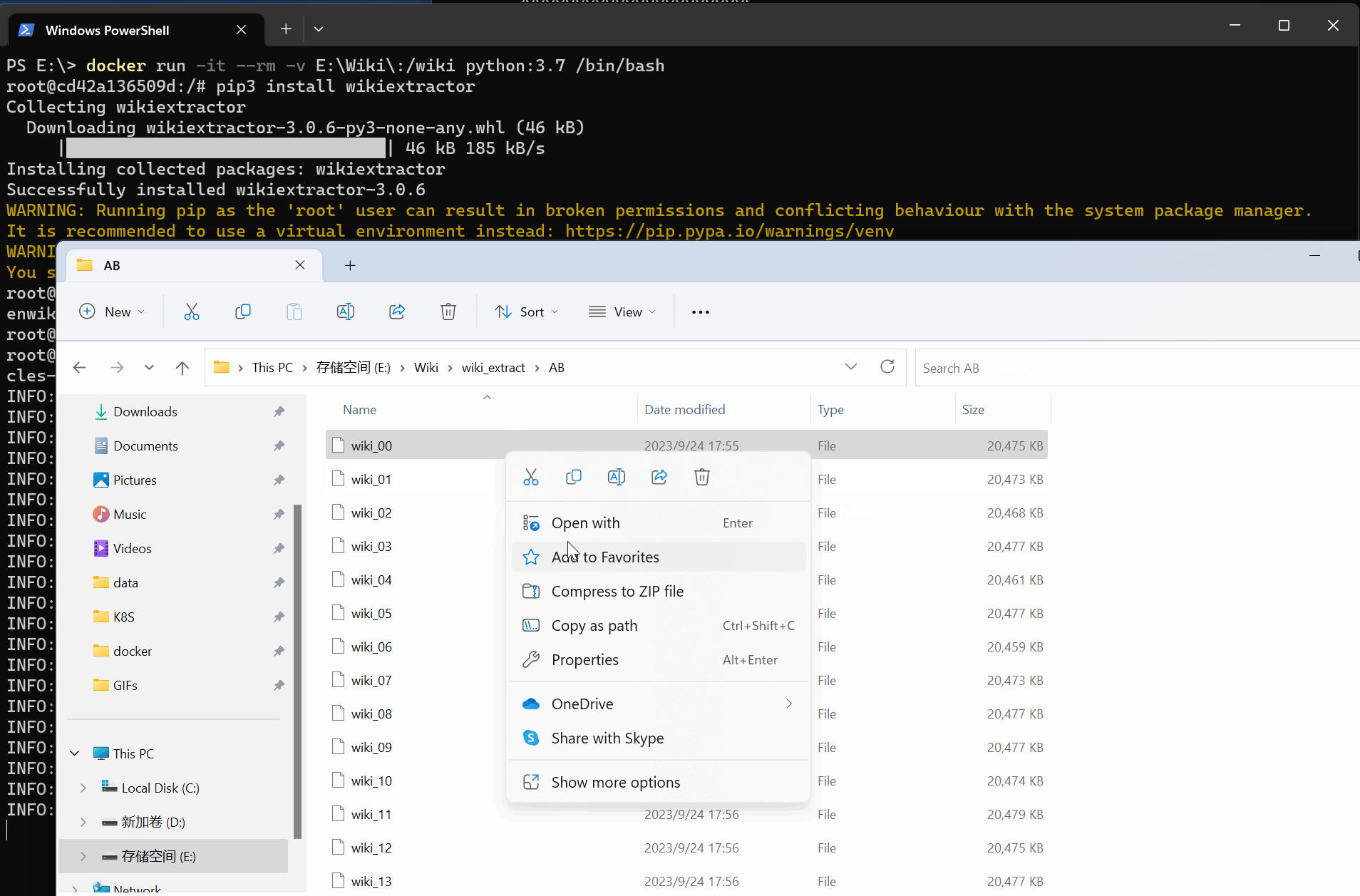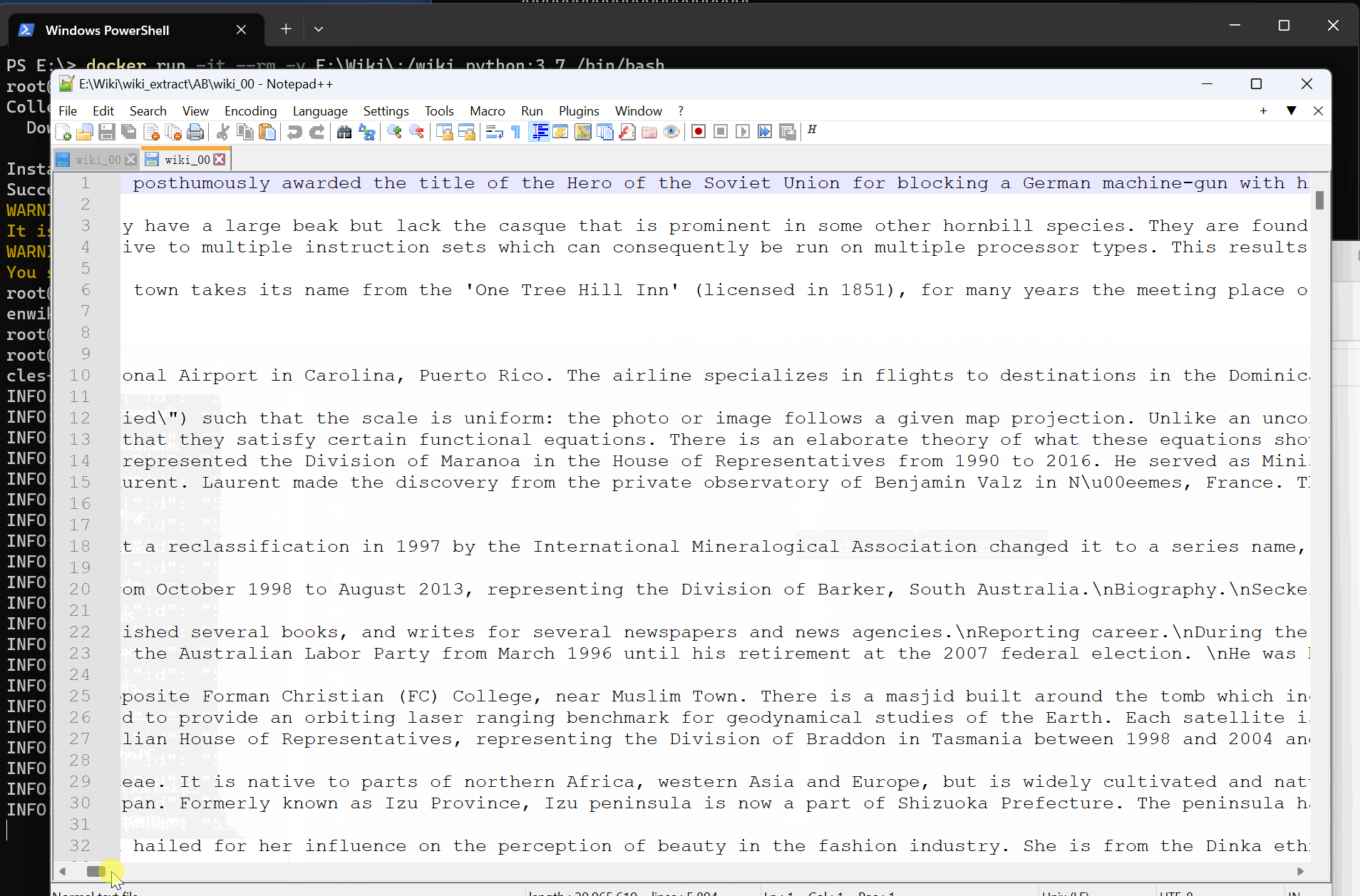
下载的是一个压缩文件里面是 xml 格式的这里不直接解压它了。而是通过一个程序来提取它wikiextractor。
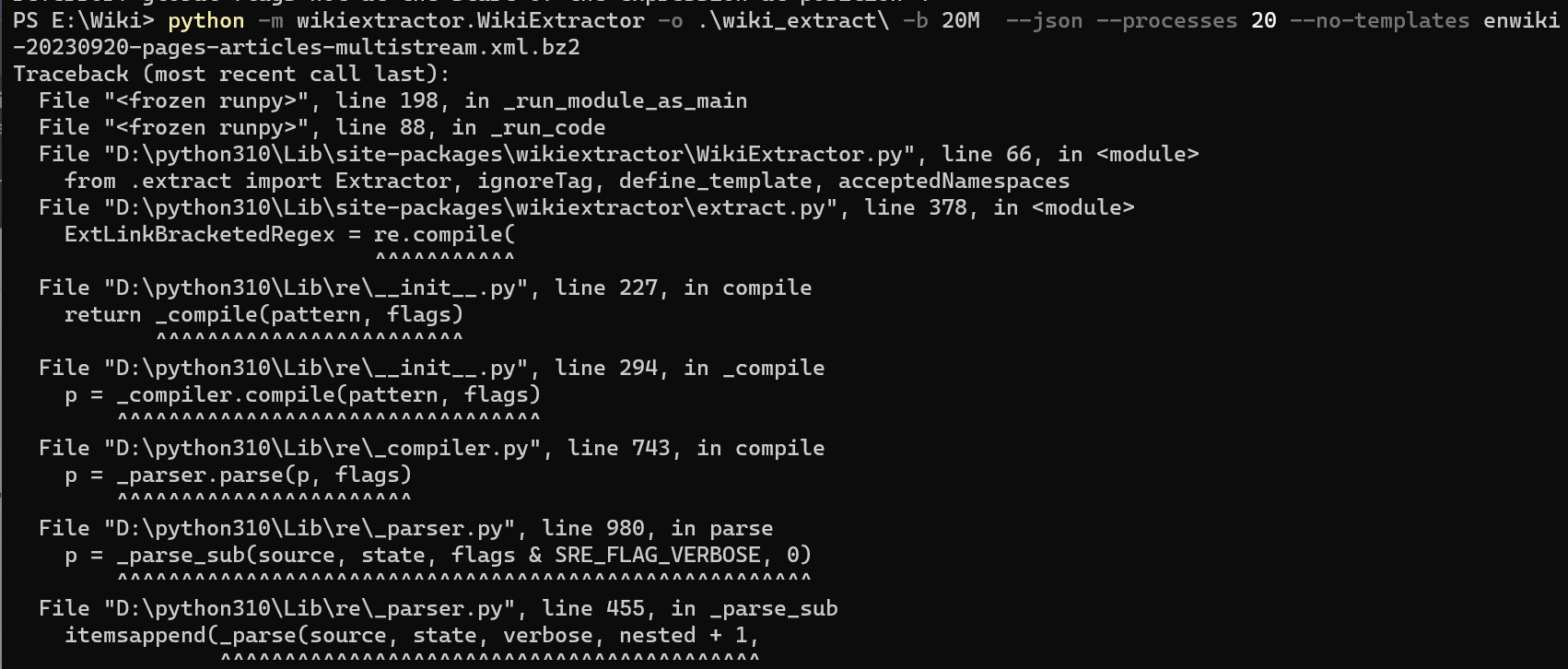
不过这个程序的作者说了它在 Windows 平台可能会有问题我不信邪真的去尝试了结果真的报错了这里看起来是我的 Python 版本Python 3.11太高了导致
那怎么办好呢我最近安装了 Docker Desktop以前我对这个东西是十分抗拒的因为很多年以前它对 Windows 的支持并不好但是今非昔比了现在它和 WSL2 结合之后真的成了一个十分有用的工具了
DockerDesktop 安装并启动
不过在国内拉取镜像受到网络因素的影响十分难受。我因为我大学时弄的一个阿里云的服务器所以添加了阿里云的镜像加速功能。下面的内容要求你了解一些 docker 的内容其实也很简单了直接按部就班应该也没有问题。
拉取python镜像这里选择一个版本相对较低
docker pull python:3.7
然后把本地的 E:\Wiki 挂载到容器的 /wiki 目录再开一个交互式终端直接跟着下面的操作来一气呵成吧
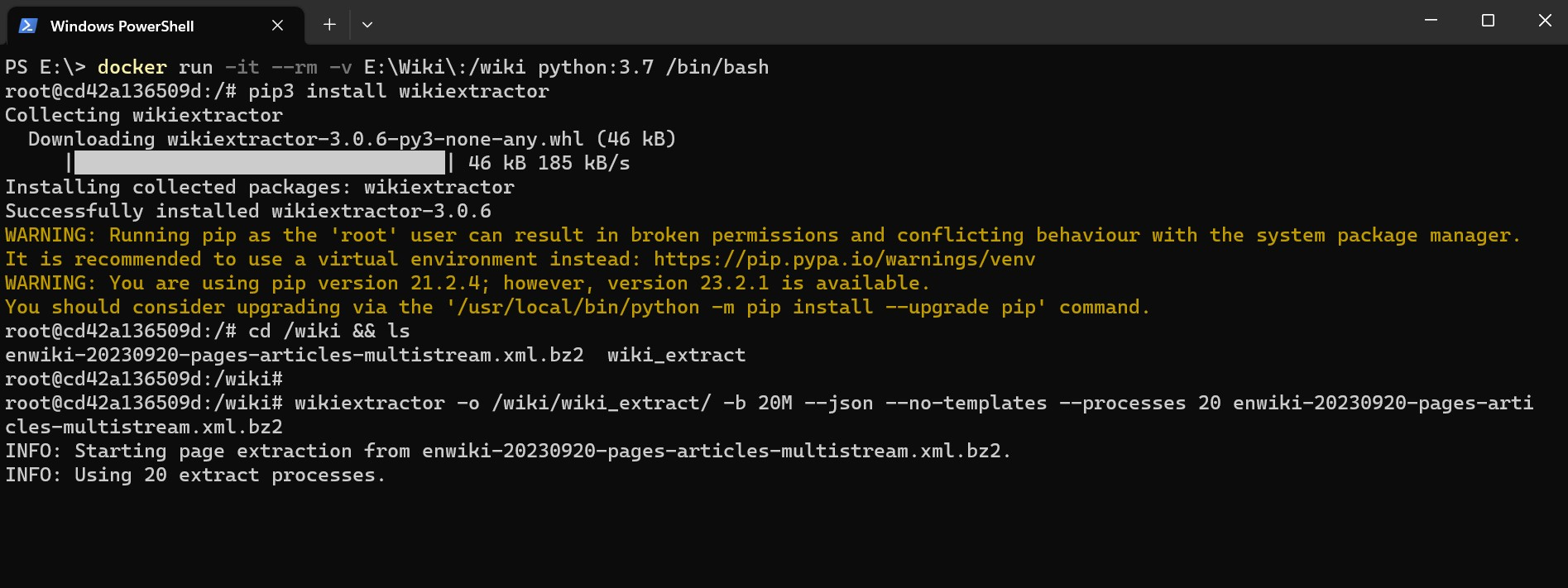
因为容器里面是没有 wikiextractor 的所以需要自己安装一下也不用写一个 Dockerfile 来构建镜像了那简直是浪费时间反正你也就用一次。即用即装反而是最优解了不过容器停止了以后啥也没有了哈哈。。
我把 processes 参数设置成了 20这个任务对于 CPU 的压力还是蛮大的
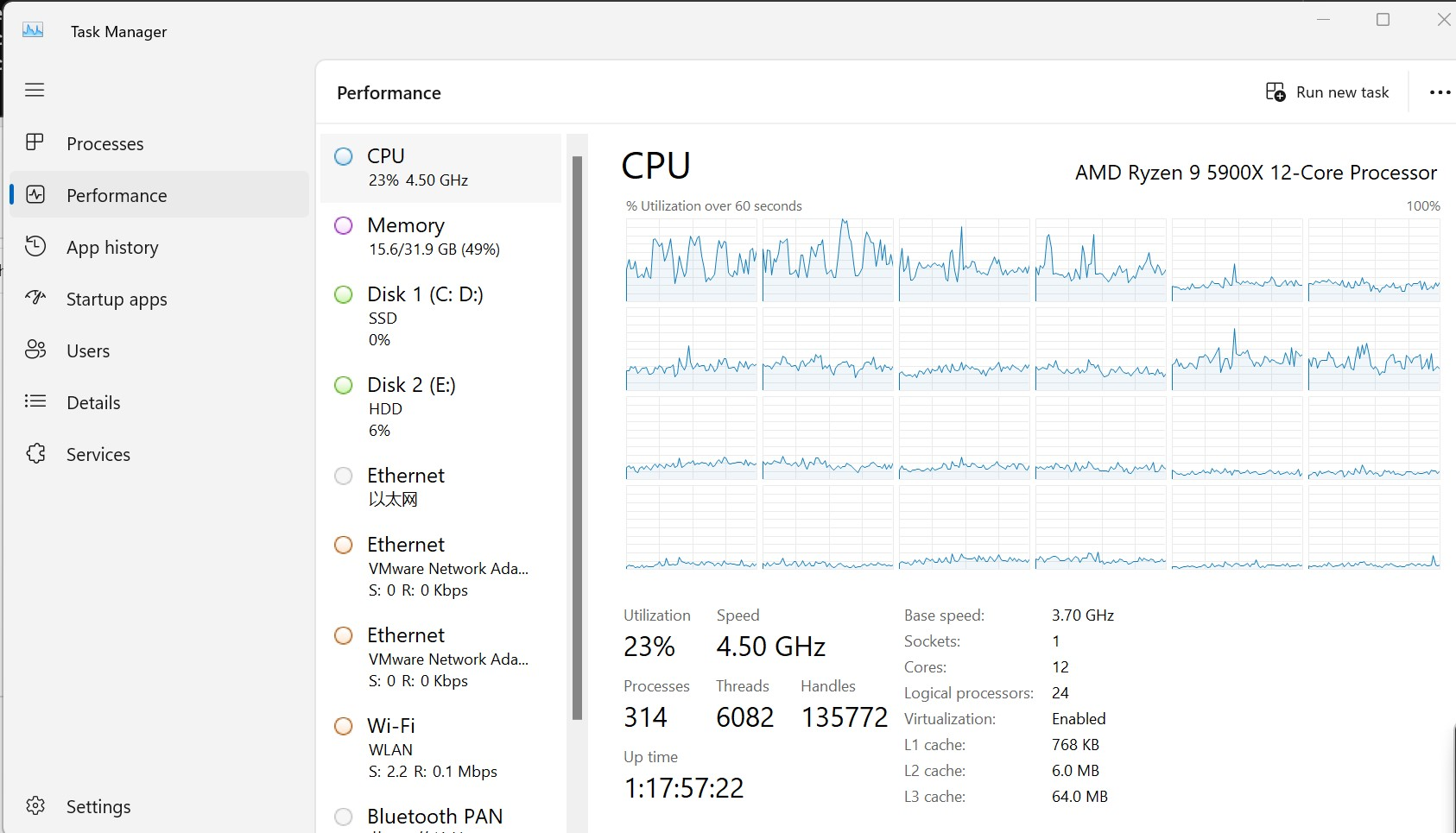
下面补充一个提取的 Gif 图
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |