

知识图:人工智能和数据科学的游戏规则改变者
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
[知识图谱]已成为人工智能和数据科学中一种强大而通用的方法,用于记录结构化信息,以促进成功的数据检索、推理和推理。本文探讨了最先进的知识图谱,包括构造、表示、查询、嵌入、推理、对齐和融合。
我们还讨论了知识图谱的许多应用,例如推荐引擎和问答系统。最后,为了为新的进展和研究机会铺平道路,我们探讨了该主题的问题和潜在的未来路线。
知识图谱通过提供灵活且可扩展的机制来表达实体和特征之间的复杂联系,彻底改变了信息的组织和使用方式。在这里,我们一般介绍知识图谱,它们的重要性以及它们在各个领域的潜在用途。
学习目标
- 理解知识图谱作为信息的结构化表示的概念和目的。
- 了解知识图谱的关键组件:节点、边和属性。
- 探索构建过程,包括数据提取和集成技术。
- 了解知识图谱嵌入如何将实体和关系表示为连续向量。
- 探索推理方法,从现有知识中推断出新的见解。
- 深入了解知识图谱可视化,以便更好地理解。
本文作为[数据科学博客马拉松]的一部分发布。
目录
知识图谱可以在信息提取操作期间存储提取的信息。许多基础知识图实现都利用了三元组的概念,三元组是三个元素(主语、谓词和宾语)的集合,可以保存有关任何内容的信息。
图形是节点和边的集合。
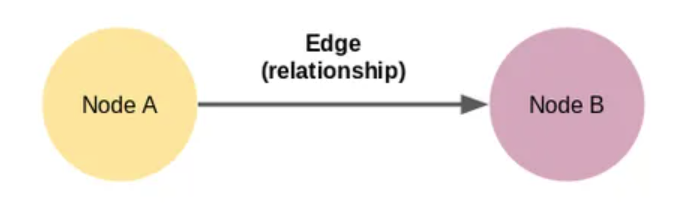
这是我们能设计的最小的知识图谱,也称为三元组。知识图谱有多种形式和大小。在这里,节点 A 和节点 B 是两个独立的东西。这些节点通过显示两个节点之间关系的边连接。
以下短语为例:
伦敦是英格兰的首都。威斯敏斯特位于伦敦。
我们稍后会看到一些基本的处理,但最初,我们将有两个三元组,如下所示:
(伦敦,成为首都,英格兰),(威斯敏斯特,定位,伦敦)
在此示例中,我们有三个不同的实体(伦敦、英国和威斯敏斯特)和两个关系(资本、位置)。构建知识图谱只需要网络中两个具有实体的相关节点和具有关系的顶点。生成的结构如下:手动创建知识图谱不可扩展。没有人会通过数百页来提取所有实体及其关系!
因为它们可以轻松地对数百甚至数千张论文进行分类,所以机器人比人类更适合处理这项工作。机器无法掌握自然语言的事实带来了另一个困难。在这种情况下使用[自然语言处理 (NLP)] 非常重要。
如果我们想从文本中创建知识图谱,让我们的计算机理解自然语言至关重要。使用 NLP 方法执行此操作,包括句子分割、依赖项解析、词性标记和实体识别。
import re
import pandas as pd
import bs4
import requests
import spacy
from spacy import displacy
nlp = spacy.load('en_core_web_sm')
from spacy.matcher import Matcher
from spacy.tokens import Span
import networkx as nx
import matplotlib.pyplot as plt
from tqdm import tqdm
pd.set_option('display.max_colwidth', 200)
%matplotlib inline
# import wikipedia sentences
candidate_sentences = pd.read_csv("../input/wiki-sentences1/wiki_sentences_v2.csv")
candidate_sentences.shape

candidate_sentences['sentence'].sample(5)

将文本文章或文档拆分为句子是创建知识图谱的第一阶段。然后,我们将只列出恰好具有一个主语和一个宾语的短语。
doc = nlp("the drawdown process is governed by astm standard d823")
for tok in doc:
print(tok.text, "...", tok.dep_)

可以轻松删除句子的单个单词部分。我们可以通过使用词性 (POS) 标签快速实现这一点。名词和专有名词将是我们的实体。
当一个实体跨越许多单词时,仅靠 POS 标签是不够的。必须解析语句的依赖树。
在开发知识图谱时,节点及其关系是最重要的。
这些节点将由维基百科文本中的实体组成。边反映这些元素之间的关系。我们将使用无监督的方法从短语结构中提取这些元素。
基本思想是阅读一个短语并在遇到主题和对象时识别它们。但是,也有一些缺点。例如,“红酒”是一个跨越短语的实体,而依赖关系解析器仅将单个单词标识为主语或宾语。
由于上述问题,我创建了下面的代码来从句子中提取主语和宾语(实体)。为了您的方便,我将代码分为许多部分:
def get_entities(sent):
## chunk 1
ent1 = ""
ent2 = ""
prv_tok_dep = "" # dependency tag of previous token in the sentence
prv_tok_text = "" # previous token in the sentence
prefix = ""
modifier = ""
#############################################################
for tok in nlp(sent):
## chunk 2
# if token is a punctuation mark then move on to the next token
if tok.dep_ != "punct":
# check: token is a compound word or not
if tok.dep_ == "compound":
prefix = tok.text
# if the previous word was also a 'compound' then add the current word to it
if prv_tok_dep == "compound":
prefix = prv_tok_text + " "+ tok.text
# check: token is a modifier or not
if tok.dep_.endswith("mod") == True:
modifier = tok.text
# if the previous word was also a 'compound' then add the current word to it
if prv_tok_dep == "compound":
modifier = prv_tok_text + " "+ tok.text
## chunk 3
if tok.dep_.find("subj") == True:
ent1 = modifier +" "+ prefix + " "+ tok.text
prefix = ""
modifier = ""
prv_tok_dep = ""
prv_tok_text = ""
## chunk 4
if tok.dep_.find("obj") == True:
ent2 = modifier +" "+ prefix +" "+ tok.text
## chunk 5
# update variables
prv_tok_dep = tok.dep_
prv_tok_text = tok.text
#############################################################
return [ent1.strip(), ent2.strip()]
上面的代码块定义了几个空变量。前面单词的依赖项和单词本身将分别保留在变量prv_tok_dep和prv_tok_text中。前缀和修饰符将保存与主题或对象关联的文本。
然后,我们将逐一检查短语中的所有令牌。将首先建立令牌作为标点符号的状态。如果是这种情况,我们将忽略它并继续下一个令牌。如果令牌是复合短语(依赖标签 = “复合”)的组成部分,我们会将其放在前缀变量中。
人们将许多单词组合在一起形成一个复合词,并生成具有新含义的新短语(例如“足球场”和“动物爱好者”)。
他们会将此前缀附加到句子中的每个主语或宾语。类似的方法将用于形容词,例如“漂亮的衬衫”,“大房子”等。
如果使用者是此方案中的令牌,它将作为 ent1 变量中的第一个实体输入。变量前缀、修饰符、prv_tok_dep和prv_tok_text都将重置。
如果令牌是对象,它将作为第二个实体放置在 ent2 变量中。变量前缀、修饰符、prv_tok_dep和prv_tok_text都将重置。
确定短语的主题和对象后,我们将更新前面的令牌及其依赖项标记。
让我们用一个短语来测试这个函数:
get_entities("the film had 200 patents")

哇,一切看起来都按计划进行。在上面的话中,“电影”是主题,“200项专利”是目标。
现在,我们可以使用此方法为数据中的所有短语提取这些实体配对:
entity_pairs = []
for i in tqdm(candidate_sentences["sentence"]):
entity_pairs.append(get_entities(i))
该列表entity_pairs包括维基百科句子中的所有主宾对。让我们来看看其中的一些。
entity_pairs[10:20]
如您所见,这些实体对中存在一些代词,例如“我们”、“它”、“她”等。相反,我们想要专有名词或名词。我们可能会更新 get_entities() 代码以过滤掉代词。
实体的提取只是任务的一半。我们需要边缘来链接节点(实体)以形成知识图谱。这些边表示两个节点之间的连接。
根据我们的假设,谓语是短语中的主要动词。例如,在陈述“1929 年发行了六十部好莱坞音乐剧”中,动词“发行于”被用作该句子构成的三重组的谓语。
以下函数可以从句子中提取此类谓词。在这种情况下,我使用了spaCy基于规则的匹配:
def get_relation(sent):
doc = nlp(sent)
# Matcher class object
matcher = Matcher(nlp.vocab)
#define the pattern
pattern = [{'DEP':'ROOT'},
{'DEP':'prep','OP':"?"},
{'DEP':'agent','OP':"?"},
{'POS':'ADJ','OP':"?"}]
matcher.add("matching_1", None, pattern)
matches = matcher(doc)
k = len(matches) - 1
span = doc[matches[k][1]:matches[k][2]]
return(span.text)
该函数的模式尝试发现短语的 ROOT 单词或主要谓词。识别 ROOT 后,模式会检查它后面是否跟着介词 ('prep') 或代理词。如果是这种情况,则会将其附加到 ROOT 单词中。请允许我演示这个函数:
get_relation("John completed the task")
relations = [get_relation(i) for i in tqdm(candidate_sentences['sentence'])]
让我们看一下我们刚刚提取的最常见的关系或谓词:
pd.Series(relations).value_counts()[:50]

最后,我们将使用检索到的实体(主客体对)和谓词(实体之间的关系)构建知识图谱。让我们构建一个包含实体和谓词的数据帧:
# extract subject
source = [i[0] for i in entity_pairs]
# extract object
target = [i[1] for i in entity_pairs]
kg_df = pd.DataFrame({'source':source, 'target':target, 'edge':relations})
然后,将使用 networkx 库从此数据帧形成网络。节点将表示实体,而节点之间的边或连接将反映节点的关系。
这将是一个有向图。换句话说,每个链接节点对的关系只是单向的,从一个节点到另一个节点。
# create a directed-graph from a dataframe
G=nx.from_pandas_edgelist(kg_df, "source", "target",
edge_attr=True, create_using=nx.MultiDiGraph())
plt.figure(figsize=(12,12))
pos = nx.spring_layout(G)
nx.draw(G, with_labels=True, node_color='skyblue', edge_cmap=plt.cm.Blues, pos = pos)
plt.show()
让我们用一个小例子来绘制网络:
import networkx as nx
import matplotlib.pyplot as plt
# Create a KnowledgeGraph class
class KnowledgeGraph:
def __init__(self):
self.graph = nx.DiGraph()
def add_entity(self, entity, attributes):
self.graph.add_node(entity, **attributes)
def add_relation(self, entity1, relation, entity2):
self.graph.add_edge(entity1, entity2, label=relation)
def get_attributes(self, entity):
return self.graph.nodes[entity]
def get_related_entities(self, entity, relation):
related_entities = []
for _, destination, rel_data in self.graph.out_edges(entity, data=True):
if rel_data["label"] == relation:
related_entities.append(destination)
return related_entities
if __name__ == "__main__":
# Initialize the knowledge graph
knowledge_graph = KnowledgeGraph()
# Add entities and their attributes
knowledge_graph.add_entity("United States", {"Capital": "Washington,
D.C.", "Continent": "North America"})
knowledge_graph.add_entity("France", {"Capital": "Paris", "Continent": "Europe"})
knowledge_graph.add_entity("China", {"Capital": "Beijing", "Continent": "Asia"})
# Add relations between entities
knowledge_graph.add_relation("United States", "Neighbor of", "Canada")
knowledge_graph.add_relation("United States", "Neighbor of", "Mexico")
knowledge_graph.add_relation("France", "Neighbor of", "Spain")
knowledge_graph.add_relation("France", "Neighbor of", "Italy")
knowledge_graph.add_relation("China", "Neighbor of", "India")
knowledge_graph.add_relation("China", "Neighbor of", "Russia")
# Retrieve and print attributes and related entities
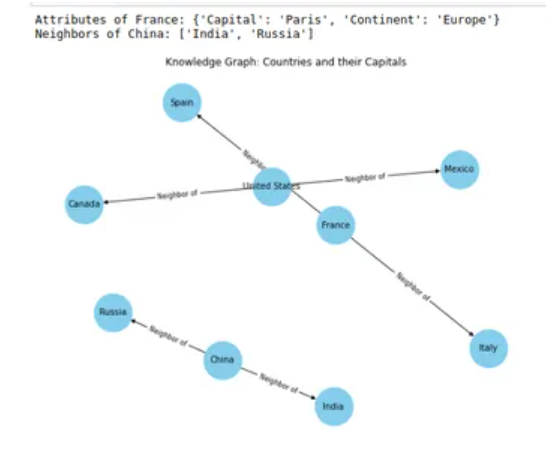
print("Attributes of France:", knowledge_graph.get_attributes("France"))
print("Neighbors of China:", knowledge_graph.get_related_entities("China", "Neighbor of"))
# Visualize the knowledge graph
pos = nx.spring_layout(knowledge_graph.graph, seed=42)
edge_labels = nx.get_edge_attributes(knowledge_graph.graph, "label")
plt.figure(figsize=(8, 6))
nx.draw(knowledge_graph.graph, pos, with_labels=True,
node_size=2000, node_color="skyblue", font_size=10)
nx.draw_networkx_edge_labels(knowledge_graph.graph, pos,
edge_labels=edge_labels, font_size=8)
plt.title("Knowledge Graph: Countries and their Capitals")
plt.show()
这不是我们想要的(但它仍然是一个相当的景象!我们发现我们已经生成了一个包含所有关系的图表。具有如此多关系或谓词的图形变得非常难以看到。
因此,最好只使用几个关键关系来可视化图形。我会一次处理一种关系。让我们从“组成”的关系开始:
G=nx.from_pandas_edgelist(kg_df[kg_df['edge']=="composed by"],
"source", "target",
edge_attr=True, create_using=nx.MultiDiGraph())
plt.figure(figsize=(12,12))
pos = nx.spring_layout(G, k = 0.5)
nx.draw(G, with_labels=True, node_color='skyblue',
node_size=1500, edge_cmap=plt.cm.Blues, pos = pos)
plt.show()
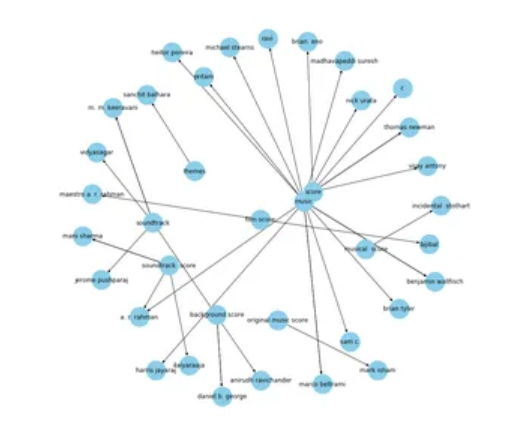
这是一个更好的图表。在这种情况下,箭头指向作曲家。在上图中,著名音乐作曲家 A.R. Rahman 与“配乐”、“电影配乐”和“音乐”等内容相关联。
让我们看一些额外的连接。现在我想为“写入者”关系绘制图形:
G=nx.from_pandas_edgelist(kg_df[kg_df['edge']=="written by"], "source",
"target",
edge_attr=True, create_using=nx.MultiDiGraph())
plt.figure(figsize=(12,12))
pos = nx.spring_layout(G, k = 0.5)
nx.draw(G, with_labels=True, node_color='skyblue', node_size=1500,
edge_cmap=plt.cm.Blues, pos = pos)
plt.show()
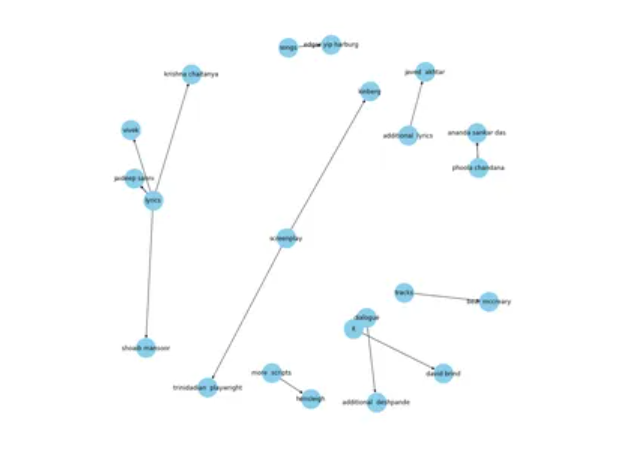
这个知识图谱为我们提供了一些惊人的数据。著名的作词家包括贾韦德·阿赫塔尔、克里希纳·柴坦尼亚和贾迪普·萨尼;这张图雄辩地描绘了他们的关系。
让我们看一下另一个关键谓词的知识图谱,“发布于”:
G=nx.from_pandas_edgelist(kg_df[kg_df['edge']=="released in"],
"source", "target",
edge_attr=True, create_using=nx.MultiDiGraph())
plt.figure(figsize=(12,12))
pos = nx.spring_layout(G, k = 0.5)
nx.draw(G, with_labels=True, node_color='skyblue', node_size=1500,
edge_cmap=plt.cm.Blues, pos = pos)
plt.show()
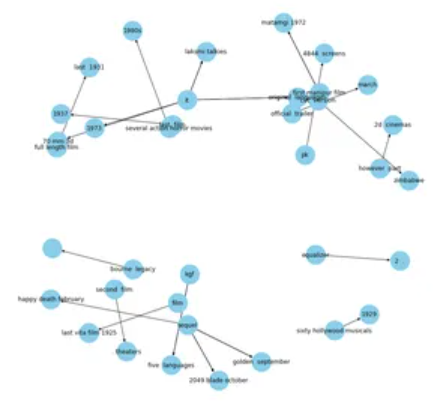
总之,知识图谱已成为人工智能和数据科学中一种强大而通用的工具,用于表示结构化信息,从而实现高效的数据检索、推理和推理。在本文中,我们探讨了强调知识图谱在不同领域的重要性和影响的要点。以下是关键点:
- 知识图谱以图形格式提供信息的结构化表示,其中包含节点、边和属性。
- 它们支持灵活的数据建模,无需固定模式,便于来自不同来源的数据集成。
- 知识图谱推理允许根据现有知识推断新的事实和见解。
- 应用程序跨越多个领域,包括自然语言处理、推荐系统和语义搜索引擎。
- 知识图谱嵌入在连续向量中表示实体和关系,从而支持对图进行机器学习。
总之,知识图谱对于组织和理解大量相互关联的信息至关重要。随着研究和技术的进步,知识图谱无疑将在塑造人工智能、数据科学、信息检索和各行各业决策系统的未来方面发挥核心作用。
问题 1.使用知识图谱有什么好处?
答:知识图谱可实现高效的数据检索、推理和推理。它们支持语义搜索,促进数据集成,并为构建推荐和问答系统等智能应用程序提供强大的基础。
问题 2.知识图谱是如何构建的?
答:各种来源提取和整合信息来构建知识图谱。他们使用数据提取技术、实体解析和实体链接来构建连贯而全面的图形。
问题 3.什么是知识图谱对齐?
答:知识图谱对齐是整合来自多个知识图谱或数据集的信息,以创建一个统一且相互关联的知识库。
问题 4.知识图谱如何用于自然语言处理?
答:知识图谱通过提供上下文信息和实体之间的语义关系,改进实体识别、情感分析和问答系统来增强自然语言处理任务。
问题 5.什么是知识图谱嵌入?
答:知识图谱嵌入将实体和关系表示为低维空间中的连续向量。它们用于捕获图中实体和关系的语义含义和结构信息。
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |