

Pytorch实战笔记(3)——BERT实现情感分析
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
本文展示的是使用 Pytorch 构建一个 BERT 来实现情感分析。本文的架构是第一章详细介绍 BERT其中包括 Self-attentionTransformer 的 EncoderBERT 的输入与输出以及 BERT 的预训练和微调方式第二章是核心代码部分。
目录
1 BERT
1.1 self-attention
Self-attention 接受一个序列输入并输出等长的序列。其运行流程如下。
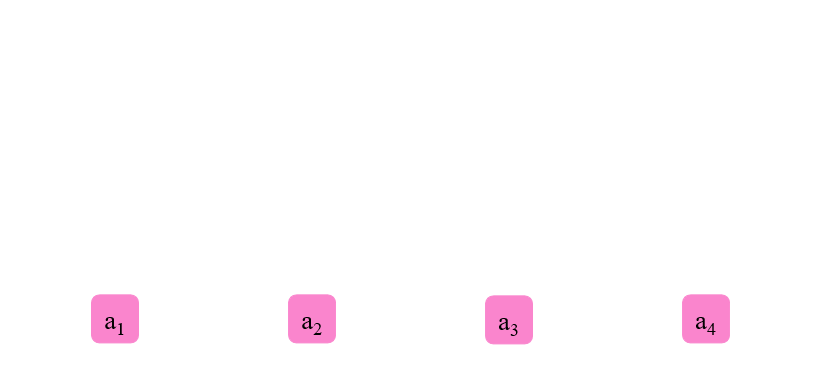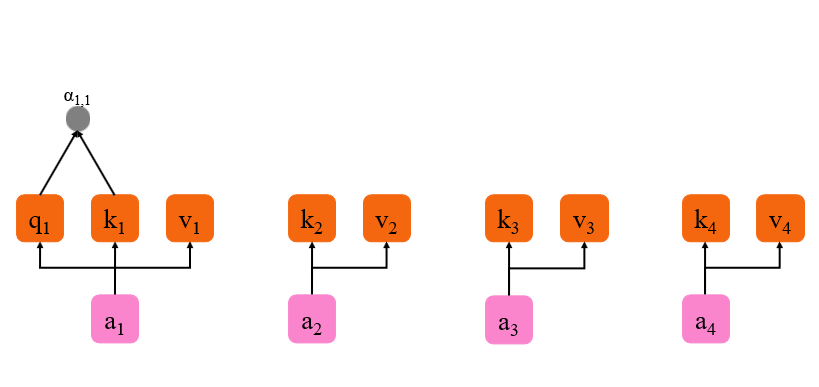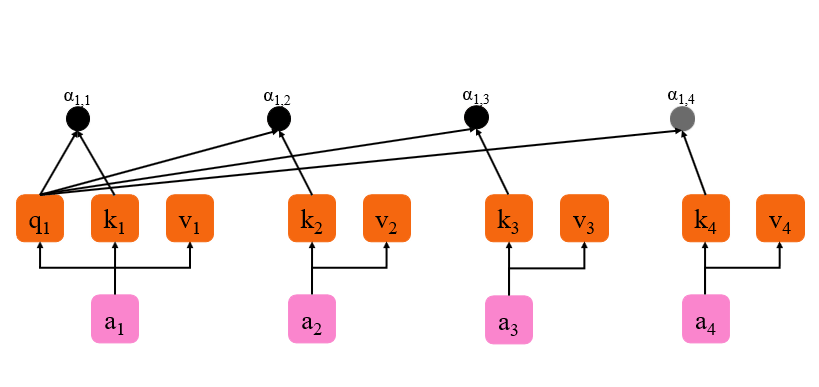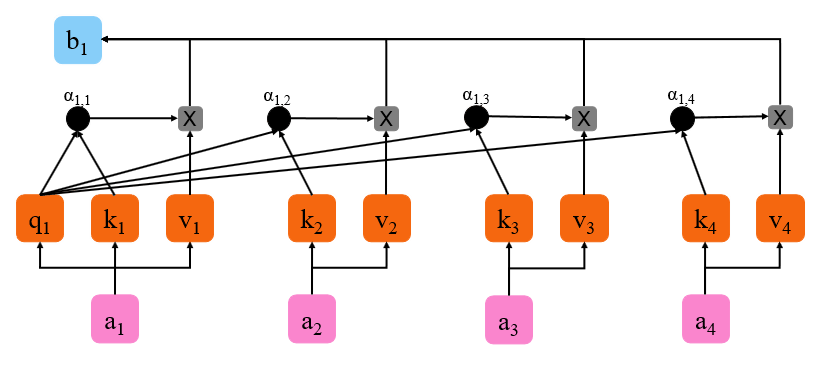
上图是 self-attention 的部分实例因为仅展示了
b
1
b_1
b1 的计算过程。其计算过程如下所述这里仅说明
b
1
b_1
b1 的计算过程
b
2
b_2
b2 到
b
4
b_4
b4 的计算方式与
b
1
b_1
b1 一样
- 对于输入序列
{
a
1
,
a
2
,
a
3
,
a
4
}
\{a_1, a_2, a_3, a_4\}
{a1,a2,a3,a4}当我们计算
a
1
a_1
a1 对该输入序列的注意力向量时
a
1
a_1
a1 会经过三次不同的线性变换得到
q
1
q_1
q1、
k
1
k_1
k1、
v
1
v_1
v1 向量公式如下。这里的 q (query)、k (key)、v (value) 可以用数据库来理解q 对应的就是 SQL 语句来查询某个键最后返回这个键的值就比如 q 是 ‘select age from girlfriend’这里 query 就是这个 sql 语句key 就是 agevalue 就是 18。
q 1 = W q a 1 , k 1 = W k a 1 , v 1 = W v a 1 . q_1=W^qa_1, \\ k_1=W^ka_1,\\ v_1=W^va_1. q1=Wqa1,k1=Wka1,v1=Wva1. - 而对于
{
a
2
,
a
3
,
a
4
}
\{a_2, a_3, a_4\}
{a2,a3,a4} 而言它们是被查询注意力的对象所以只生成 k 和 v这里需要注意的是
self-attention 是会计算自己对自己的注意力的所以会有 k1 和 v1。 - 接着
q
1
q_1
q1 会与
{
k
1
,
k
2
,
k
3
,
k
4
}
\{k_1, k_2, k_3, k_4\}
{k1,k2,k3,k4} 分别做一次点积操作得到注意力权重
{
α
1
,
1
,
α
1
,
2
,
α
1
,
3
,
α
1
,
4
}
\{\alpha_{1, 1}, \alpha_{1, 2}, \alpha_{1, 3}, \alpha_{1, 4}\}
{α1,1,α1,2,α1,3,α1,4}公式如下。这里需要注意的是由于
k
k
k 会经过一次转置所以注意力权重
α
\alpha
α 是标量。同时由于点积操作可以看做是一次
相似度的计算因为余弦相似度的计算公式是 c o s θ = a ⋅ b ∣ a ∣ ∣ b ∣ {\rm cos}\theta=\frac{a \cdot b}{|a||b|} cosθ=∣a∣∣b∣a⋅b即 a ⋅ b = ∣ a ∣ ∣ b ∣ c o s θ a \cdot b = |a||b|{\rm cos}\theta a⋅b=∣a∣∣b∣cosθ所以内积可以看做是计算两个向量的相似度所以这里内积就可以理解为计算 q 1 q_1 q1 与 { k 1 , k 2 , k 3 , k 4 } \{k_1, k_2, k_3, k_4\} {k1,k2,k3,k4} 的一次相似度权重计算因为 α \alpha α 是标量所以是相似度权重。
{ a 1 , 1 , α 1 , 2 , α 1 , 3 , α 1 , 4 } = q 1 { k 1 , k 2 , k 3 , k 4 } T . \{a_{1,1}, \alpha_{1, 2}, \alpha_{1, 3}, \alpha_{1, 4}\} = q_1 \{k_1, k_2, k_3, k_4\}^{\rm T}. {a1,1,α1,2,α1,3,α1,4}=q1{k1,k2,k3,k4}T. - 最后相似度权重 { α 1 , 1 , α 1 , 2 , α 1 , 3 , α 1 , 4 } \{\alpha_{1, 1}, \alpha_{1, 2}, \alpha_{1, 3}, \alpha_{1, 4}\} {α1,1,α1,2,α1,3,α1,4} 与 { v 1 , v 2 , v 3 , v 4 } \{v_1, v_2, v_3, v_4\} {v1,v2,v3,v4} 相乘分别得到 a 1 a_1 a1 对 a 1 a_1 a1 的注意力向量、 a 1 a_1 a1 对 a 2 a_2 a2 的注意力向量、 a 1 a_1 a1 对 a 3 a_3 a3 的注意力向量、和 a 1 a_1 a1 对 a 4 a_4 a4 的注意力向量。接着将这些向量拼起来就得到了 b 1 b_1 b1。 b 1 b_1 b1 里面就包含了 a 1 a_1 a1 对整个输入序列的所有注意力向量。
1.2 multi-head self-attention
多头自注意力机制实际上就是计算多次 self-attention。如下图所示。
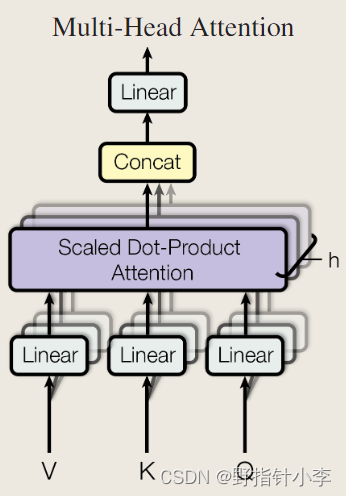
multi-head self-attention 就是输入的向量会经过
h
h
h 个不同的线性变换得到
h
h
h 个 q、k、v。比如
h
=
2
h=2
h=2 的时候
a
1
a_1
a1 会通过以下公式得到
q
1
1
q_1^1
q11、
k
1
1
k_1^1
k11、
v
1
1
v_1^1
v11 和
q
1
2
q_1^2
q12、
k
1
2
k_1^2
k12、
v
1
2
v_1^2
v12
q
1
1
=
W
1
q
a
1
,
k
1
1
=
W
1
k
a
1
,
v
1
1
=
W
1
v
a
1
,
q
1
2
=
W
2
q
a
1
,
k
1
2
=
W
2
k
a
1
,
v
1
2
=
W
2
v
a
1
.
q_1^1=W^q_1a_1, \\ k_1^1=W^k_1a_1,\\ v_1^1=W^v_1a_1,\\ q_1^2=W^q_2a_1, \\ k_1^2=W^k_2a_1,\\ v_1^2=W^v_2a_1.
q11=W1qa1,k11=W1ka1,v11=W1va1,q12=W2qa1,k12=W2ka1,v12=W2va1.
接着每个 self-attention 后的输出会拼在一起再通过一个线性转换得到 multi-head self-attention 的输出。设第一个头的输出为
h
e
a
d
1
head_1
head1第二个头的输出为
h
e
a
d
2
head_2
head2最后的输出为
O
O
O则其计算公式为
O
=
c
o
n
c
a
t
(
h
e
a
d
1
,
h
e
a
d
2
)
W
o
.
O = {\rm concat}(head_1, head_2)W^o.
O=concat(head1,head2)Wo.
1.3 Encoder
这里的 Encoder 特指的是 Transformer[1] 中的 Encoder左边是 Transformer 的 Encoder右边是 Decoder其模型结构如下
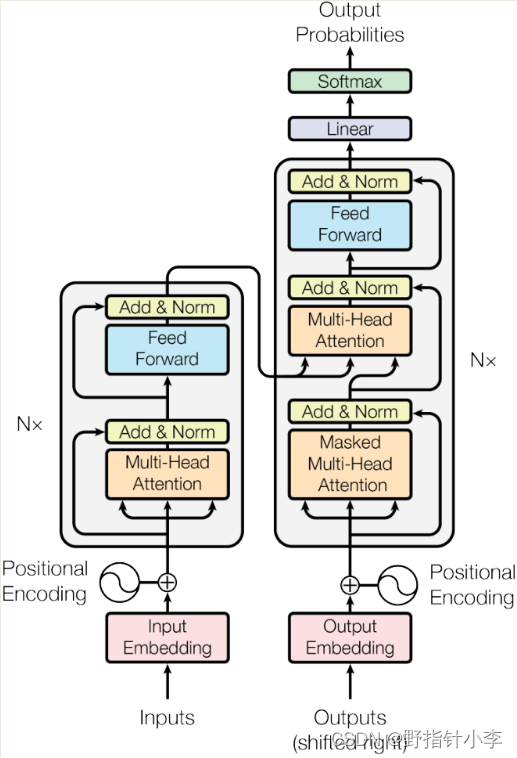
Encoder 中一共有以下几个部分
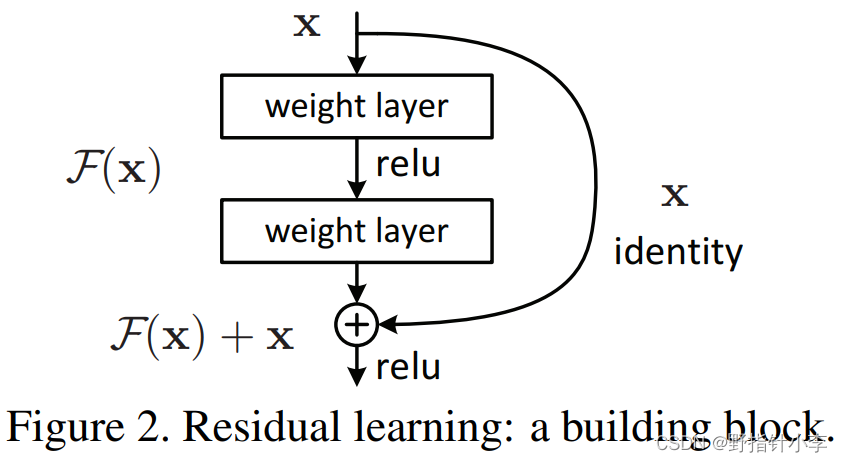
Multi-head self-attention在前面已介绍过了。残差连接 (Residual connection)[2]对应的是图中的Add。残差连接如下图所示。简单来说残差连接就是将一个模块的输入与其输出相加通常使用在层次较深的结构当中。那么为什么残差连接在深层次模型中有效具体而言如果不采用残差连接那么前向传播为 F ( x ) F(x) F(x)反向传播的时候求梯度就为 ∂ ( F ( x ) ) ∂ x \frac{\partial (F(x))}{\partial x} ∂x∂(F(x))当梯度消失的时候 ∂ ( F ( x ) ) ∂ x \frac{\partial (F(x))}{\partial x} ∂x∂(F(x)) 就为0就无法回传梯度。而当采用了残差连接后前向传播变为 F ( x ) + x F(x) + x F(x)+x。从直觉上来讲这样能够让模型更关注于经过了这个模块后变化的部分而从数学上来将在反向传播的时候会变成 ∂ ( F ( x ) + x ) ∂ x = ∂ ( F ( x ) ) ∂ x + 1 \frac{\partial (F(x)+x)}{\partial x}=\frac{\partial (F(x))}{\partial x}+1 ∂x∂(F(x)+x)=∂x∂(F(x))+1。当梯度消失后那么 ∂ ( F ( x ) ) ∂ x \frac{\partial (F(x))}{\partial x} ∂x∂(F(x)) 趋近于0所以 ∂ ( F ( x ) + x ) ∂ x \frac{\partial (F(x)+x)}{\partial x} ∂x∂(F(x)+x) 趋近于1使得梯度无法消失始终能够回传。
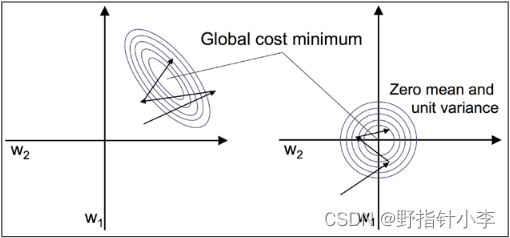
层归一化 (layer norm)[3]对应的是图中的Norm。层归一化的公式如下所示。其中 m m m 是向量 x i x_i xi 的均值 σ \sigma σ 是向量 x i x_i xi 的标准差。层归一化的示例图如下所示。具体而言如果数据不做归一化有可能在某些方向上梯度下降很快从左下到右上这样会导致越过最优点有的方向上下降很慢从右下到左上这样会导致半天收敛不到最优点。而通过层归一化后能够使得数据在各个方向上都能够下降的一样快使得能够更快收敛。
x i ′ = x i − m σ x_i'=\frac{x_i-m}{\sigma} xi′=σxi−m
位置嵌入 (Positional Encoding)对应的是图中最下面的Positional Encoding。为什么要位置嵌入由于 self-attention 可以看做是下图这样两个位置之间间隔为1。如果不能理解为什么是1可以再回过头看看上面那个 gif。那么这样会导致一个问题对于自然语言处理的任务而言词语的先后顺序肯定是很重要的就比如我现在这里写到了 positional encoding那么和第一小节写的 self-attention 关联就很弱了所以需要通过位置嵌入来控制词语与词语之间的位置。
全连接层对应图中的Feed forward没什么好说的唯一要注意的是这里是两层全连接层公式如下
F F N ( x ) = W 2 ( R e L U ( W 1 x + b 1 ) ) + b 2 FFN(x)=W_2({\rm ReLU}(W_1x+b_1))+b_2 FFN(x)=W2(ReLU(W1x+b1))+b2
1.4 BERT 的输入与输出
1.4.1 BERT 的输入
BERT 的输入与传统的语言模型输入不同传统的语言模型的输入就只是整个句子而 BERT 在输入中还加入了几个特殊的字符。其中包括
[CLS][CLS] 一定出现在句首这个特殊字符通过 BERT 后得到的隐藏状态代表了该句子的句向量。 [CLS] 是一定会有的。[SEP][SEP] 一定出现在句子的结尾。由于 BERT 支持单句和两句话输入所以用 [SEP] 来区分哪句话是哪句话。[SEP] 是一定会有的。[MASK][MASK] 会出现在 [CLS] 与 [SEP] 中的任意位置该特殊字符是让 BERT 去预测这个位置是什么词语。[MASK] 不一定会有。
以以下两句话为例 练习时长两年半 和 唱跳 rap 打篮球那么输入进 BERT 后会变成以下这样[CLS] 练习时长两年半 [SEP] 唱跳 rap 打篮球 [SEP]如果只有前一句话输入并且掩盖掉 半 的话那么是如下这样[CLS] 练习时长两年[MASK] [SEP]
1.4.2 BERT 的输出
与传统的序列模型一样BERT 的输出有两部分
句向量通过模型后[CLS] 的隐藏状态即句向量。如果是一句话输入那么就是这句话的句向量如果是两句话输入那么就是这两句话的句向量。每个词语的隐藏状态和 LSTM 一样BERT 也会输出每个词语的隐藏状态。这里特别需要注意的是所谓的 BERT 的词嵌入实际上指的就是这个通过 BERT 后的隐藏状态而非 BERT 的嵌入层。 这是因为 BERT 是基于上下文的词嵌入contextualized word embedding你得有上下文信息才能叫词嵌入。
1.5 BERT 预训练
BERT 预训练有两个部分第一个部分是 masked language model (MLM)第二部分是 next sentence prediction (NSP)。
- MLM 简单来说就是随机将输入文本中
15%的词语给提取出来然后进行以下处理1.80%的可能将词语替换为[MASK]这是让模型通过上下文来预测这[MASK]是什么词语10%的可能将词语随机替换为另外一个词语10%的可能保持词语不变。MLM 如下图所示。MLM 是个 V V V 分类任务其中 V V V 是词表大小。
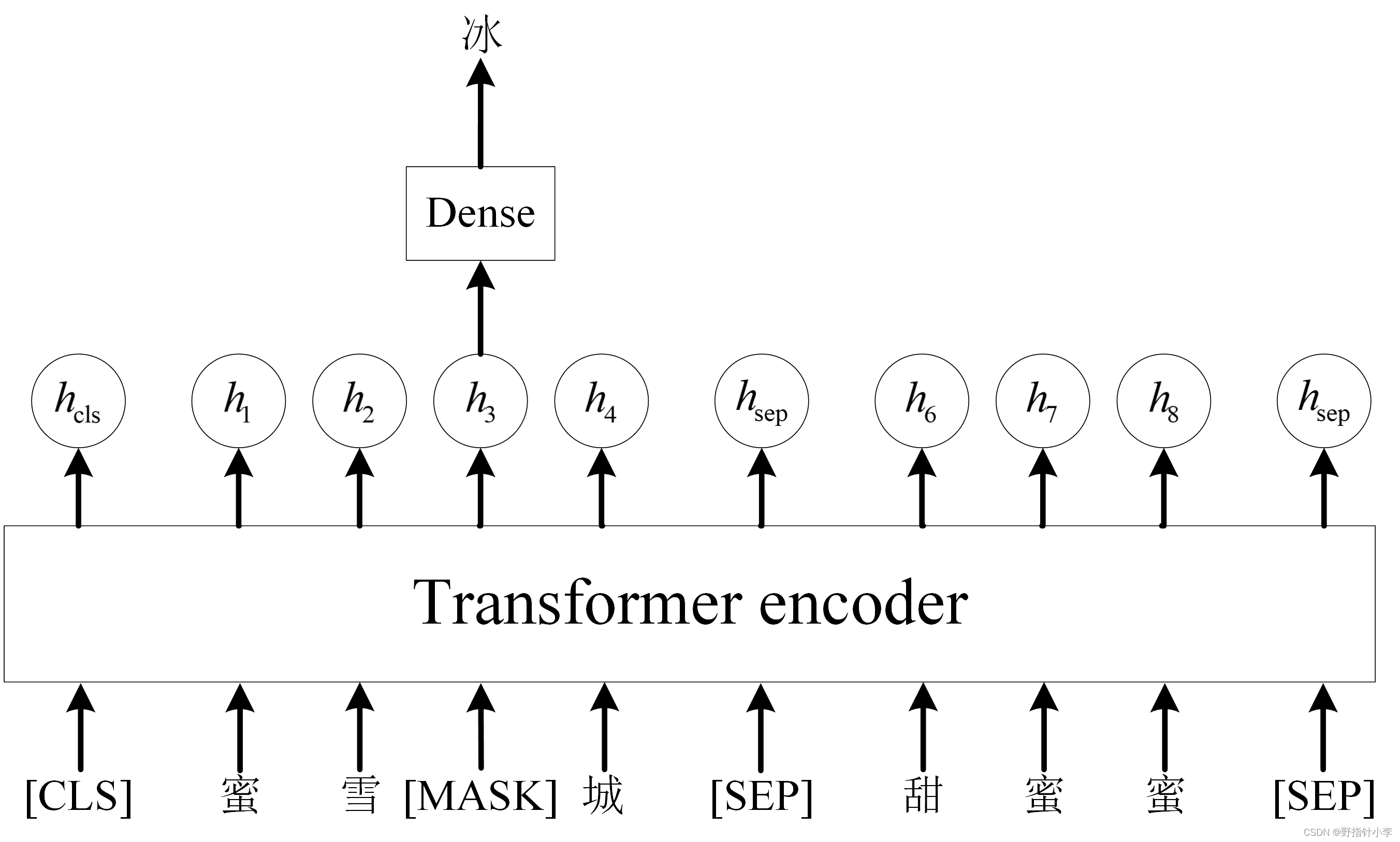
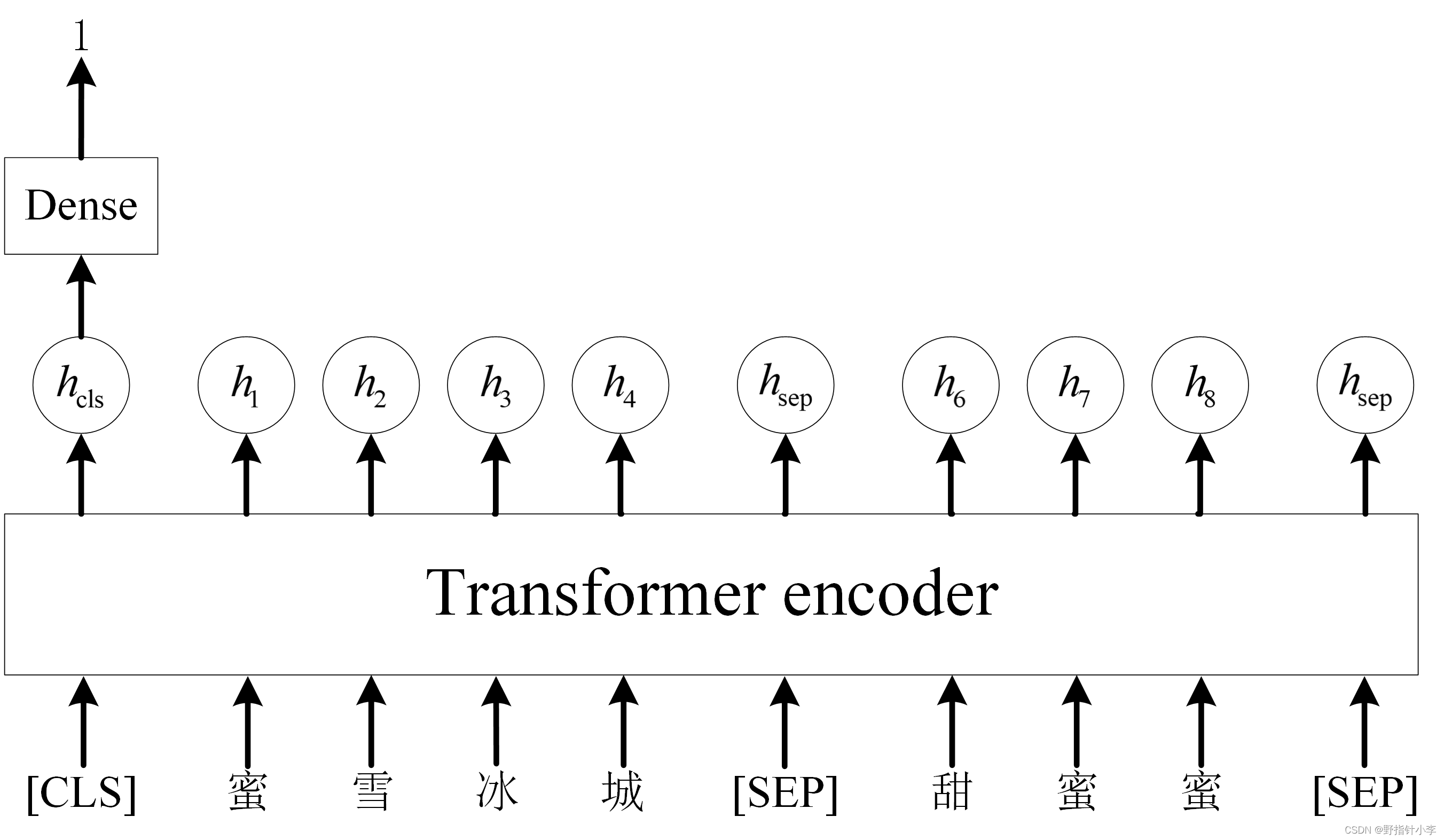
- NSP 简单来说就是输入两句话到模型中让模型判断后一句话是否与前一句话有关联。NSP 如下图所示。NSP 是个二分类任务其中 1 代表上下两句话有关联0 代表没有关联。
1.6 BERT 微调
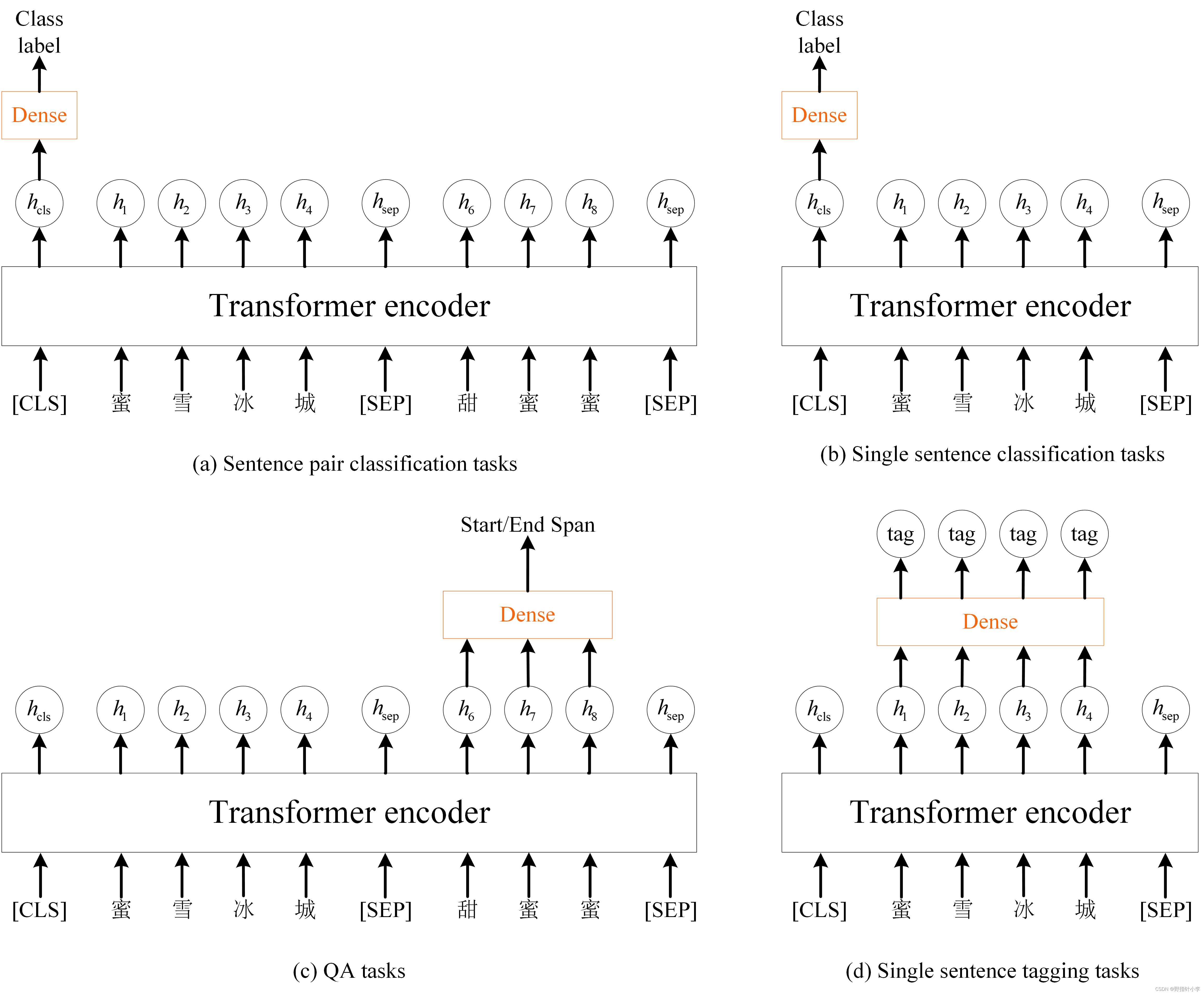
微调阶段首先 BERT 会先加载预训练好的参数并额外添加上部分随机初始化的参数。如下图所示。图中用橙色标出来的全连接层就是在微调阶段随机初始化的参数。所以微调阶段训练的为两部分内容
模型本身这部分是可以不参与训练的因为模型已经在预训练阶段训练好了不是必须训练的。随机初始化的参数这部分是必须训练的参数。
2 BERT 实现情感分析
- 全部代码在 github 上网址为https://github.com/Balding-Lee/Pytorch4NLP
- 我采用的是 IMDb 数据集由于数据集没有验证集而且读取起来很麻烦所以我将数据给读取出来放到了一个文件中并且将训练集中的10%划分为了验证集数据集链接如下 https://pan.baidu.com/s/128EYenTiEirEn0StR9slqw提取码xtu3 。
- 采用的词嵌入是谷歌的词嵌入词嵌入的链接如下链接https://pan.baidu.com/s/1SPf8hmJCHF-kdV6vWLEbrQ提取码r5vx
在本博客中仅介绍模型部分详细代码见 github。
具体的模型代码如下
import torch
import torch.nn as nn
from transformers import BertTokenizer, BertConfig, BertForSequenceClassification
class Config:
def __init__(self):
# 训练配置
self.seed = 22
self.batch_size = 64
self.lr = 1e-5
self.weight_decay = 1e-4
self.num_epochs = 100
self.early_stop = 512
self.max_seq_length = 128
self.save_path = '../model_parameters/BERT_SA.bin'
# 模型配置
self.bert_hidden_size = 768
self.model_path = 'bert-base-uncased'
self.num_outputs = 2
class Model(nn.Module):
def __init__(self, config, device):
super().__init__()
self.config = config
self.device = device
tokenizer_class, bert_class, model_path = BertTokenizer, BertForSequenceClassification, config.model_path
bert_config = BertConfig.from_pretrained(model_path, num_labels=config.num_outputs)
self.tokenizer = tokenizer_class.from_pretrained(model_path)
self.bert = bert_class.from_pretrained(model_path, config=bert_config).to(device)
def forward(self, inputs):
tokens = self.tokenizer.batch_encode_plus(inputs,
add_special_tokens=True,
max_length=self.config.max_seq_length,
padding='max_length',
truncation='longest_first')
input_ids = torch.tensor(tokens['input_ids']).to(self.device)
att_mask = torch.tensor(tokens['attention_mask']).to(self.device)
logits = self.bert(input_ids, attention_mask=att_mask).logits
return logits
实验结果如下
test loss 0.281900 | test accuracy 0.878846 | test precision 0.853424 | test recall 0.915280 | test F1 0.883270
参考
[1] Ashish Vaswani, Noam Shazeer, Niki Parmar, et al. Attention is all you need [EB/OL]. https://arxiv.org/abs/1706.03762, 2017.
[2] Kaiming He, Xiangyu Zhang, Shaoqing Ren, et al. Deep Residual Learning for Image Recognition [EB/OL]. https://arxiv.org/abs/1512.03385, 2015.
[3] Jimmy Lei Ba, Jamie Ryan Kiros, Geoffrey E. Hinton. Layer Normalization [EB/OL]. https://arxiv.org/abs/1607.06450, 2016.