三表相连 mapjoin
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
三表相连 mapjoin
要求
输出的样式

三张表
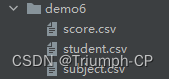
score.csv
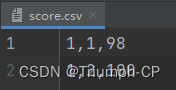
student.csv
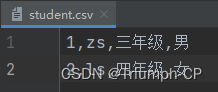
subject.csv
创建三个类
StudentSc

getset方法
插入getset方法可用javabean插件一键生成
实现类
public StudentSc(String stuName, String subName, Integer scScore, String flag) {
this.stuName = stuName;
this.subName = subName;
this.scScore = scScore;
}
@Override
public int compareTo(nj.zb.kb21.demo5.StudentScore o) {
return 0;
}
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(stuName);
dataOutput.writeUTF(subName);
dataOutput.writeInt(scScore);
}
MapJoinDriver
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class MapJoinDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
job.setJarByClass(MapJoinDriver.class);
job.setMapperClass(MapJoinMapper.class);
job.setMapOutputKeyClass(StudentSc.class);
job.setMapOutputValueClass(NullWritable.class);
Path inPath = new Path("D:\\kb21\\myworkspace\\njzb\\hadoopexec\\in\\demo6\\score.csv");
FileInputFormat.setInputPaths(job,inPath);
Path outPath = new Path("D:\\kb21\\myworkspace\\njzb\\hadoopexec\\out7");
FileSystem fs = FileSystem.get(outPath.toUri(), configuration);
if (fs.exists(outPath)){
fs.delete(outPath,true);
}
FileOutputFormat.setOutputPath(job,outPath);
//设置Reduce阶段的任务数量
job.setNumReduceTasks(0);
//配置Map阶段的缓存尽量使用小文件做缓存如果文件太大会引起OOM内存溢出
Path cachePath = new Path("D:\\kb21\\myworkspace\\njzb\\hadoopexec\\in\\demo6\\student.csv");
job.addCacheFile(cachePath.toUri());
Path cachePath2 = new Path("D:\\kb21\\myworkspace\\njzb\\hadoopexec\\in\\demo6\\subject.csv");
job.addCacheFile(cachePath2.toUri());
boolean result = job.waitForCompletion(true);
System.out.println(result);
}
}
用mapjoin不需要reduce
MapJoinMapper
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.HashMap;
import java.util.Map;
public class MapJoinMapper extends Mapper<LongWritable, Text, StudentSc, NullWritable> {
Map<Integer, StudentSc> studentScMap = new HashMap<Integer, StudentSc>();
Map<Integer, StudentSc> studentScMap2 = new HashMap<Integer, StudentSc>();
@Override
protected void setup(Mapper<LongWritable, Text, StudentSc, NullWritable>.Context context) throws IOException, InterruptedException {
URI[] cacheFiles = context.getCacheFiles();
for (URI uri : cacheFiles) {
String currentFileName = new Path(uri).getName();
if (currentFileName.startsWith("student")) {
String path = uri.getPath();
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(path)));
String line;
while ((line = br.readLine()) != null) {
String[] fields = line.split(",");
StudentSc studentSc = new StudentSc(fields[1],"",0,"");
studentScMap.put(Integer.parseInt(fields[0]), studentSc);
> 这里按照要求将student的名字添加到studentScMap表中
}
br.close();
}
if (currentFileName.startsWith("subject")) {
String path = uri.getPath();
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(path)));
String line;
while ((line = br.readLine()) != null) {
String[] fields = line.split(",");
StudentSc studentSc = new StudentSc("",fields[1],0,"");
studentScMap2.put(Integer.parseInt(fields[0]), studentSc);
>这里按照要求将subject的科目名字添加到studentScMap2表中
}
br.close();
}
}
}
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, StudentSc, NullWritable>.Context context) throws IOException, InterruptedException {
String[] scFields = value.toString().split(",");//这个集合读取的是driver中的inpath的表 score
StudentSc currentStudent = studentScMap.get(Integer.parseInt(scFields[0]));
StudentSc currentStudent2 = studentScMap2.get(Integer.parseInt(scFields[1]));
StudentSc studentScs = new StudentSc();
studentScs.setStuName(currentStudent.getStuName());
studentScs.setFlag("0");//flag不重要是我上一个项目多写的懒得删
studentScs.setSubName(currentStudent2.getSubName());
studentScs.setScScore(Integer.parseInt(scFields[2]));
context.write(studentScs, NullWritable.get());
}
}
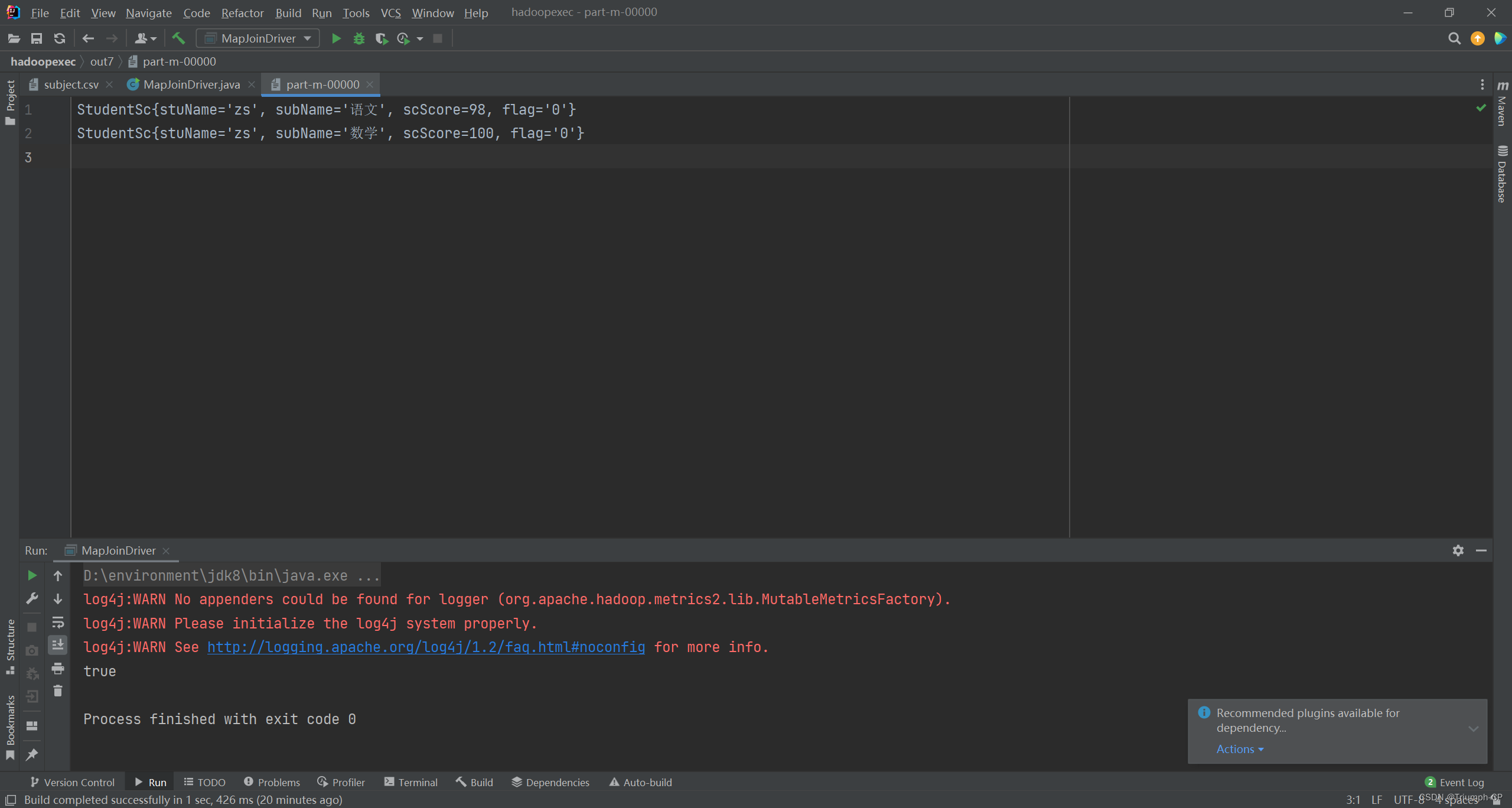
运行结果