

PyTorch实战2:彩色图片识别(CIFAR10)
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
- 本文为365天深度学习训练营 中的学习记录博客
- 参考文章365天深度学习训练营-第P2周彩色图片识别
- 原作者K同学啊|接辅导、项目定制
目录
一、数据准备
torchvision.datasets详解 http://t.csdn.cn/DCqMk
本次案例依然使用Pytorch自带的一个数据库torchvision.datasets通过代码在线下载数据这里使用的是torchvision.datasets中的CIFAR10数据集。
具体代码
train_ds = torchvision.datasets.CIFAR10('data',
train=True,
transform=torchvision.transforms.ToTensor(), # 将数据类型转化为Tensor
download=True)
test_ds = torchvision.datasets.CIFAR10('data',
train=False,
transform=torchvision.transforms.ToTensor(), # 将数据类型转化为Tensor
download=True)
在这里简单展示一下部分彩色图片

后面具体实现操作可参考http://t.csdn.cn/DCqMk这里直接进入构建网络部分。
二、构建简单CNN网络
⭐1. torch.nn.Conv2d()详解
函数原型如下
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros')
参数说明
- in_channels输入特征图的通道数
- out_channels输出特征图的通道数即卷积核的个数
- kernel_size卷积核的大小可以是int、tuple型变量。如kernel_size=3表示使用3x3的卷积核进行卷积
- stride卷积核的步长可以是int、tuple型变量。如stride=2表示每隔1行/列卷积一次
- padding填充的长度可以是int、tuple型变量。如padding=1表示在输入特征图的四周各加1圈0以减小特征图尺寸
- dilation空洞卷积操作的空洞率dilation rate可以是int、tuple型变量
- groups组卷积的分组数量默认为1表示普通卷积操作
- bias是否添加偏置项默认添加
- padding_mode填充模式可取’zeros’或’circular’。
例子
import torch
import torch.nn as nn
conv = nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1)
input_data = torch.randn(1, 3, 32, 32) # 输入特征图大小为[1, 3, 32, 32]
output = conv(input_data) # 输出特征图大小为[1, 16, 32, 32]
以上代码定义了一个输入特征图通道数为3输出特征图通道数为16卷积核大小为3x3步长为1填充长度为1的卷积层。将随机生成的大小为[1, 3, 32, 32]的张量作为输入经过一次卷积操作后得到输出特征图大小为[1, 16, 32, 32]的张量。
⭐2. torch.nn.Linear()详解
torch.nn.Linear()用于实现线性变换或全连接层。它将大小为in_features的输入张量映射到大小为out_features的输出张量通过以下公式实现
y = xA^T + b
函数原型
torch.nn.Linear(in_features, out_features, bias=True, device=None, dtype=None)
参数说明
- in_features每个输入样本的大小
- out_features每个输出样本的大小
其中x是输入张量A是权重矩阵b是偏置向量y是输出张量。
使用torch.nn.Linear()可以方便地定义神经网络模型中的全连接层并自动管理权重和偏置等参数。例如
import torch
import torch.nn as nn
# 定义一个输入维度为3输出维度为4的全连接层
linear_layer = nn.Linear(3, 4)
# 随机生成一个大小为(2, 3)的输入张量
input_tensor = torch.randn(2, 3)
# 将输入张量传入全连接层进行前向计算
output_tensor = linear_layer(input_tensor)
# 查看输出张量的形状
print(output_tensor.shape)
上述代码定义了一个输入维度为3输出维度为4的全连接层并随机生成了一个大小为(2,3)的输入张量进行前向计算。输出张量的形状应该为(2, 4)。
除了输入维度和输出维度之外torch.nn.Linear()还可以设置其他参数如是否包括偏置项、权重初始化方法等。这些参数可以通过传递关键字参数进行设置。
⭐3. torch.nn.MaxPool2d()详解
torch.nn.MaxPool2d() 用于进行 2D 最大池化操作的函数。它可以将输入的二维数据张量按照指定大小进行划分并在每个子区域中取最大值从而得到一个更小的输出张量。
函数原型
torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
以下是 torch.nn.MaxPool2d() 的常用参数
kernel_size池化窗口的大小可以是一个整数表示正方形或一个元组表示长方形。如果设置为 ( k , k ) (k,k) (k,k) 或者 k k k则表示使用 k × k k\times k k×k 的池化窗口。stride池化窗口的步幅可以是一个整数表示横向和纵向相同的步幅也可以是一个元组表示横向和纵向不同的步幅。padding填充的大小可以是一个整数表示正方形或一个元组表示长方形与卷积的 padding 参数类似。dilation卷积核的扩张率即卷积核中各个元素之间的间隔距离。return_indices是否返回最大值的索引。ceil_mode当 stride 不被整除时是否向上取整可以避免出现边界像素没有参与池化的情况。
具体用法如下
import torch.nn as nn
maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
input = torch.randn(1, 3, 64, 64)
output = maxpool(input)
上面的代码中我们创建了一个 3x3 的池化窗口步幅为 2填充大小为 1 的最大池化层并将其应用于一个输入张量。最后得到的输出张量形状会因为池化操作而变小。
⭐4. torch.nn.BatchNorm2d()详解
torch.nn.BatchNorm2d()用于批量标准化Batch Normalization操作。它可以对输入数据进行标准化并将其缩放和移位以使其均值为0方差为1。该层通常用于神经网络中可使训练更稳定且加快收敛速度。
该层的输入是形状为 (batch_size, num_channels, height, width) 的4D张量其中 batch_size 表示批次大小num_channels 表示通道数height 和 width 分别表示输入数据的高度和宽度。
参数说明:
- num_features (int)输入特征的数量即
num_channels。 - eps (float, optional)防止除以0的小数默认为1e-5。
- momentum (float, optional)用于计算统计信息的动量应在0到1之间默认为0.1。
- affine (bool, optional)是否使用可学习的仿射变换默认为True。
- track_running_stats (bool, optional)是否计算并跟踪运行时统计数据默认为True。
首先通过 nn.Conv2d 进行卷积操作然后传递给 nn.BatchNorm2d 层进行标准化操作接着再使用ReLU激活函数进行非线性变换。最后将做过标准化和非线性变换的输出传递到全连接层以生成最终的预测结果。
⭐5. 关于卷积层、池化层的计算
下面的网络数据shape变化过程为
3, 32, 32输入数据
-> 64, 30, 30经过卷积层1-> 64, 15, 15经过池化层1
-> 64, 13, 13经过卷积层2-> 64, 6, 6经过池化层2
-> 128, 4, 4经过卷积层3 -> 128, 2, 2经过池化层3
-> 512 -> 256 -> num_classes(10)
注此处计算过程只是作为例子参考
6.构建稀疏卷积的CNN
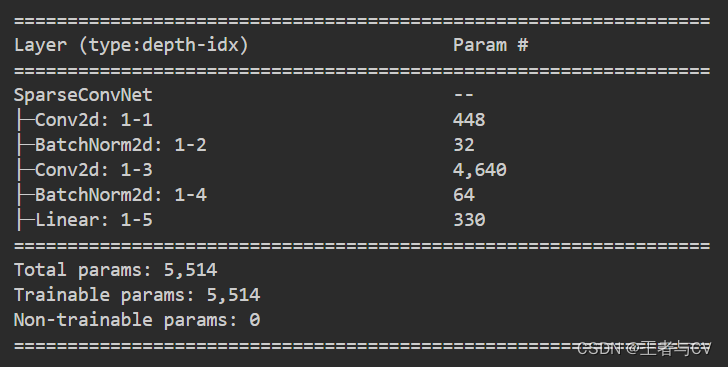
定义一个基于稀疏卷积神经网络的分类器包括了三个主要的组成部分卷积层、批量归一化层以及全连接层。
首先在初始化函数__init__中我们定义了卷积层conv1使用的卷积核大小为3x3有16个输出通道。然后我们加入了一个批量归一化层bn1其输入通道数为16。接下来我们定义了一个稀疏卷积层sparse_conv其输入通道数为16输出通道数为32且不使用padding。最后我们添加了另一个批量归一化层bn2其输入通道数为32用于归一化稀疏卷积层的输出。最终我们加入了一个全连接层fc1将32个特征图转换为10个类别的概率值。
在前向传递函数forward中我们首先对输入数据x应用第一层卷积操作然后使用ReLU激活函数和批量归一化对其进行处理。接着我们将输出结果再次通过稀疏卷积层、批量归一化层及ReLU激活函数处理。之后我们使用平均池化层将特征图压缩成一个1x1的向量以便我们可以将其送入一个全连接层进行分类。在最后一步中我们应用softmax激活函数并返回对数值作为输出结果这个输出结果包含每个类别出现的概率。
class SparseConvNet(nn.Module):
def __init__(self):
super(SparseConvNet, self).__init__()
# 第一层卷积
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(16) # 批量归一化层
# 稀疏卷积层
self.sparse_conv = nn.Conv2d(16, 32, kernel_size=3, stride=1, padding=0, bias=False)
self.bn2 = nn.BatchNorm2d(32) # 批量归一化层
# 全连接层
self.fc1 = nn.Linear(32, 10)
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x))) # 第一层卷积 + 批量归一化 + 激活函数ReLU
x = F.relu(self.bn2(self.sparse_conv(x))) # 稀疏卷积层 + 批量归一化 + 激活函数ReLU
x = F.avg_pool2d(x, kernel_size=x.size()[2:]) # 平均池化层
x = x.view(-1, 32) # 将特征图拉成向量
x = self.fc1(x) # 全连接层
return F.log_softmax(x, dim=1) # 输出层应用softmax激活函数并返回对数值
网络结构展示
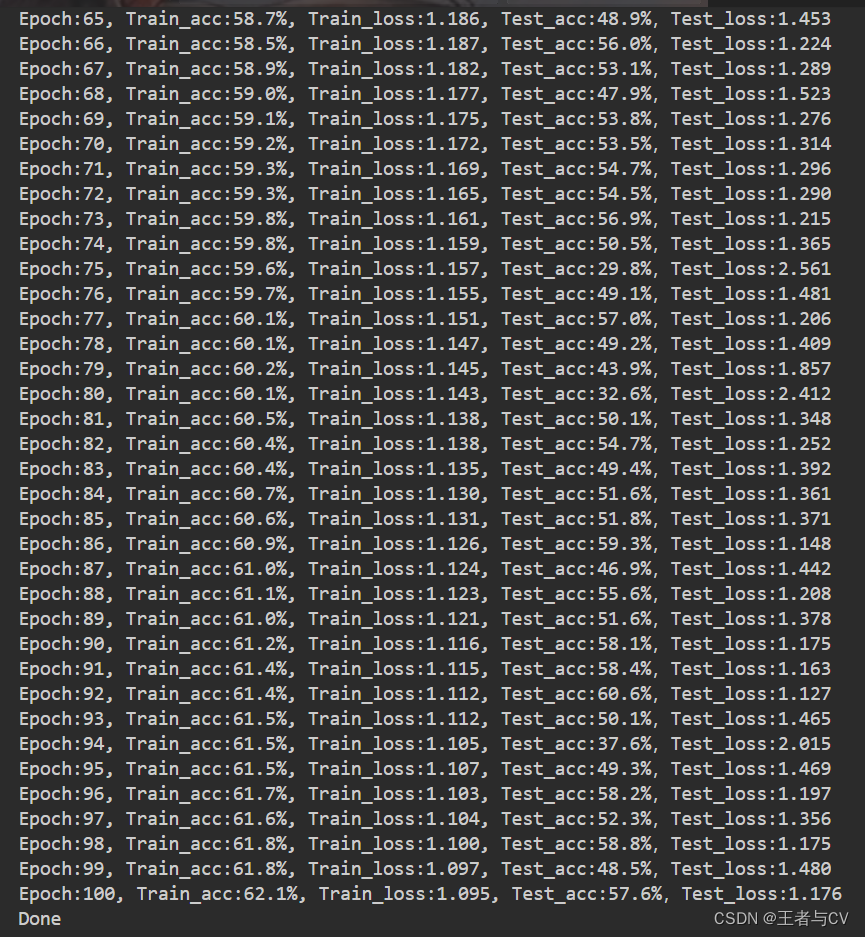
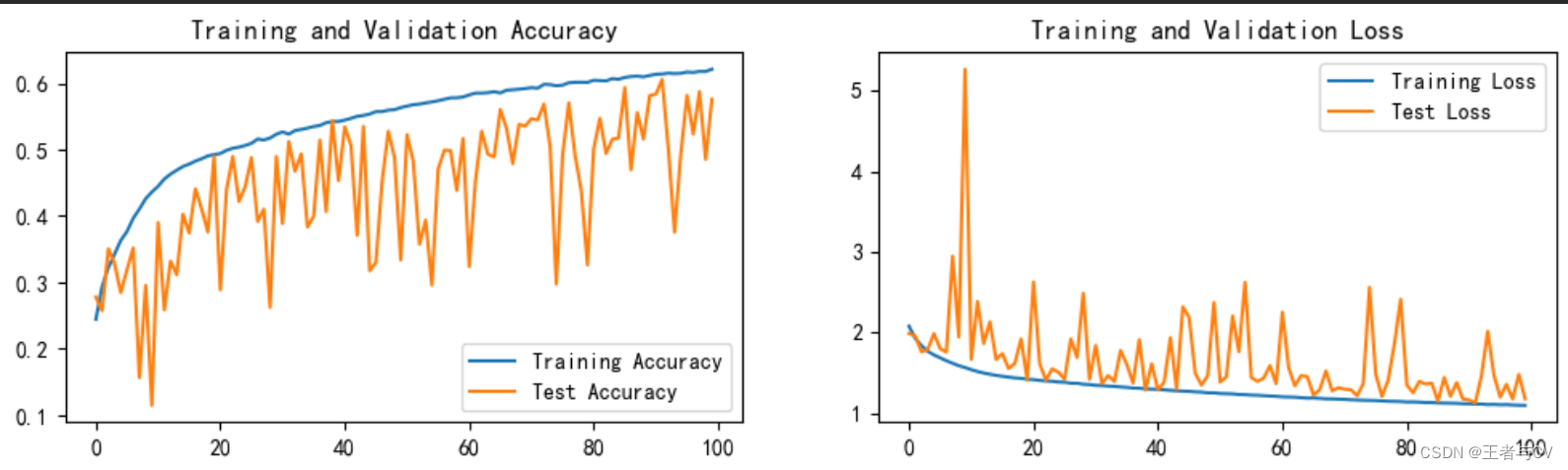
训练模型与结果可视化在上一篇PyTorch实战1实现mnist手写数字识别已有详细的赘述
在此就直接摆出本文案例的运行结果图
三、总结
本文实战并没有使用深度学习训练营中的网络结构进行模型训练而是自己设计了一个较为简单的、易于理解的网络结构发现亲手设计从0到1的网络会遇到一些问题比如每个层的参数该如何设置卷积层、池化层如何计算使用多少个卷积层、池化层、全连接层尝试不用正规卷积而改用稀疏卷积如何去实现等等。
本次实战运用自己设计的网络结构开始训练模型最终结果证明效果一般般毕竟这是第一次且刚入门的小案例后续熟练了再试着去调参优化将模型的精度提高至80甚至90。
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |