

【C++】位图 | 布隆过滤器
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
🌠 作者@阿亮joy.
🎆专栏《吃透西嘎嘎》
🎇 座右铭每个优秀的人都有一段沉默的时光那段时光是付出了很多努力却得不到结果的日子我们把它叫做扎根

目录
👉哈希函数👈
引起哈希冲突的一个原因可能是哈希函数设计不够合理。
哈希函数的设计原则
- 哈希函数的定义域必须包括需要存储的全部关键码而如果散列表允许有 m 个地址时其值域必须在 0 到 m-1 之间
- 哈希函数计算出来的地址能均匀分布在整个空间中
- 哈希函数应该比较简单
常见哈希函数
- 直接定址法常用
取关键字的某个线性函数为散列地址Hash(Key) = A * Key + B
优点简单、均匀且不存在哈希冲突
缺点需要事先知道关键字的分布情况
使用场景适合查找比较小且连续的情况
面试题字符串中第一个只出现一次字符- 除留余数法常用
设散列表中允许的地址数为 m取一个不大于 m但最接近或者等于 m 的质数 p 作为除数按照哈希函数Hash(key) = key% p(p <= m)将关键码转换成哈希地址。除留余数法存在哈希冲突重点解决哈希冲突。- 平方取中法了解
假设关键字为 1234对它平方就是 1522756抽取中间的 3 位 227 作为哈希地址再比如关键字为 4321对它平方就是 18671041抽取中间的 3 位 671 (或710)作为哈希地址。平方取中法比较适合不知道关键字的分布而位数又不是很大的情况。- 折叠法是将关键字从左到右分割成位数相等的几部分(最后一部分位数可以短些)然后将这几部分叠加求和并按散列表表长取后几位作为散列地址。折叠法适合事先不需要知道关键字的分布适合关键字位数比较多的情况只适用于整数。
5. 随机数法了解
选择一个随机函数取关键字的随机函数值为它的哈希地址即 H(key) = random(key)其中 random 为随机数函数。通常应用于关键字长度不等时采用此法。
6. 数学分析法了解
设有 n 个 d 位数每一位可能有 r 种不同的符号这 r 种不同的符号在各位上出现的频率不一定相同可能在某些位上分布比较均匀每种符号出现的机会均等在某些位上分布不均匀只有某几种符号经常出现。可根据散列表的大小选择其中各种符号分布均匀的若干位作为散列地址。数字分析法通常适合处理关键字位数比较大的情况如果事先知道关键字的分布且关键字的若干位分布较均匀的情况。例如
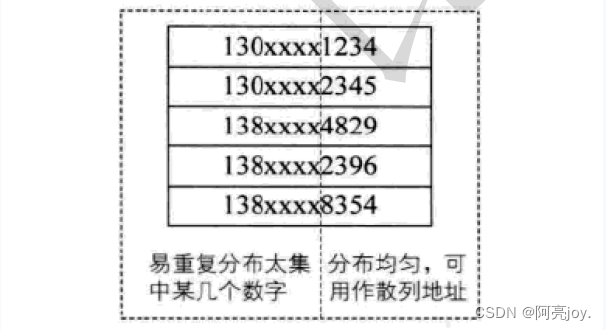
假设要存储某家公司员工登记表如果用手机号作为关键字那么极有可能前 7 位都是相同的那么我们可以选择后面的四位作为散列地址如果这样的抽取工作还容易出现 冲突还可以对抽取出来的数字进行反转(如 1234 改成 4321 )、右环位移(如 1234 改成 4123 )、左环移位、前两数与后两数叠加(如 1234 改成 12+34=46 )等方法。
注意哈希函数设计的越精妙产生哈希冲突的可能性就越低但是无法避免哈希冲突。
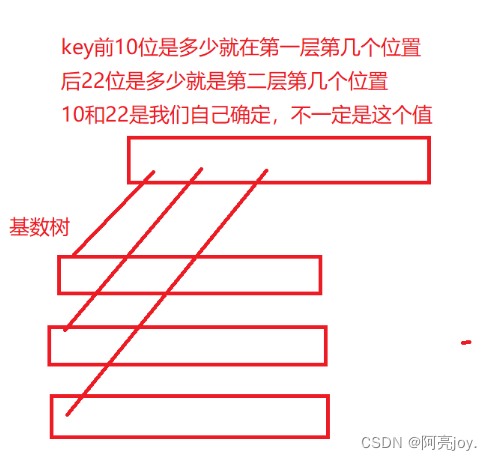
👉位图👈
位图概念
- 面试题
给 40 亿个不重复的无符号整数没排过序。给一个无符号整数如何快速判断一个数是否在这 40 亿个数中。
- 遍历时间复杂度O(N)
- 排序(O(NlogN))利用二分查找: logN
- 位图解决
数据是否在给定的整形数据中结果是在或者不在刚好是两种状态。那么可以使用一个二进制比特位来代表数据是否存在的信息如果二进制比特位为 1代表存在为 0代表不存在。比如
2. 位图概念
所谓位图就是用每一位来存放某种状态适用于海量数据数据无重复的场景。通常是用来判断某个数据存不存在的。注意位图所开空间要大于或等于整型的范围因为有可能有些数字数有些数字小。
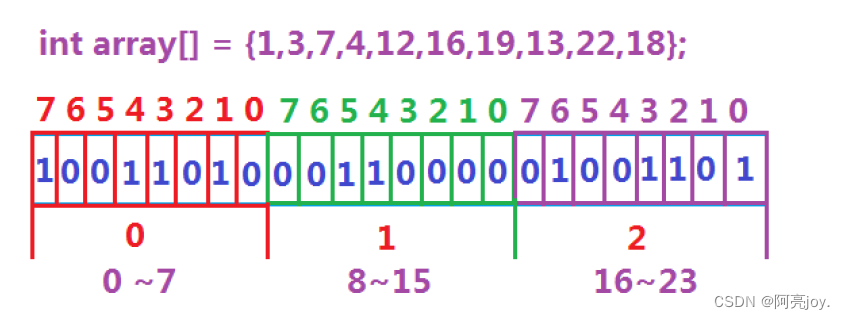

位图的实现
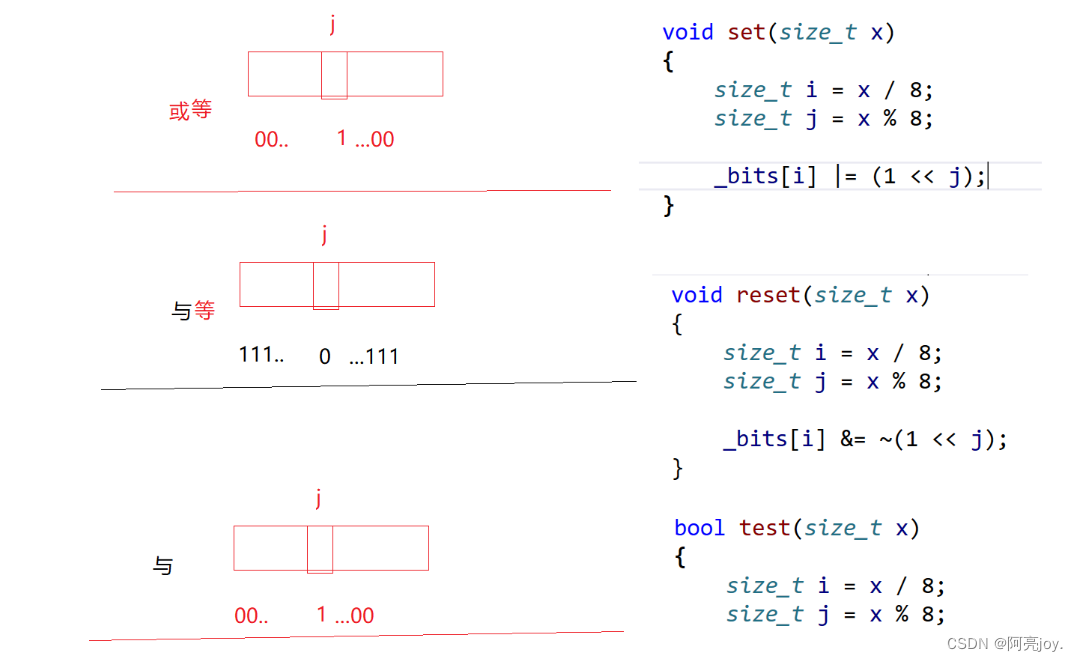
位图最核心的三个节点是set、reset和testset是将 x 对应的比特位设置为 1reset是将 x 对应的比特位设置为 0test是查看 x 在不在。
#pragma once
namespace Joy
{
template<size_t N>
class bitset
{
public:
bitset()
{
_bits.resize(N / 8 + 1, 0); // 多开一个字节,防止越界
}
// 将比特位设置为1
void set(size_t x)
{
size_t i = x / 8;
size_t j = x % 8;
_bits[i] |= (1 << j);
}
// 将比特位设置为0
void reset(size_t x)
{
size_t i = x / 8;
size_t j = x % 8;
_bits[i] &= ~(1 << j);
}
// 查x在不在
bool test(size_t x)
{
size_t i = x / 8;
size_t j = x % 8;
return (_bits[i] & (1 << j));
}
private:
vector<char> _bits;
};
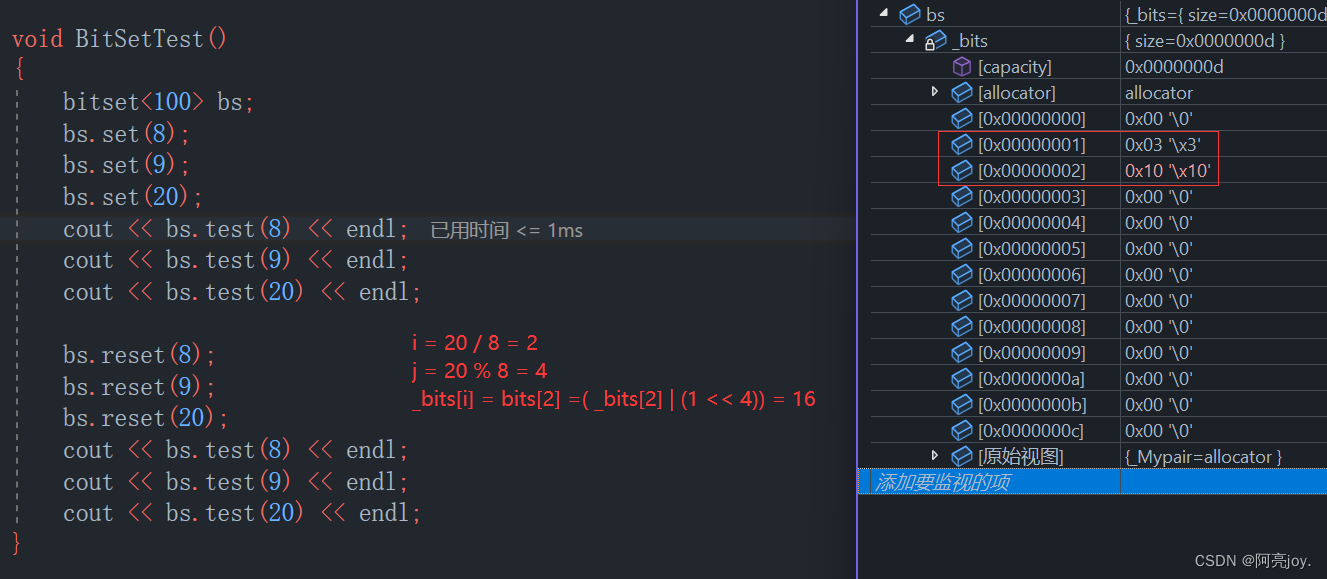
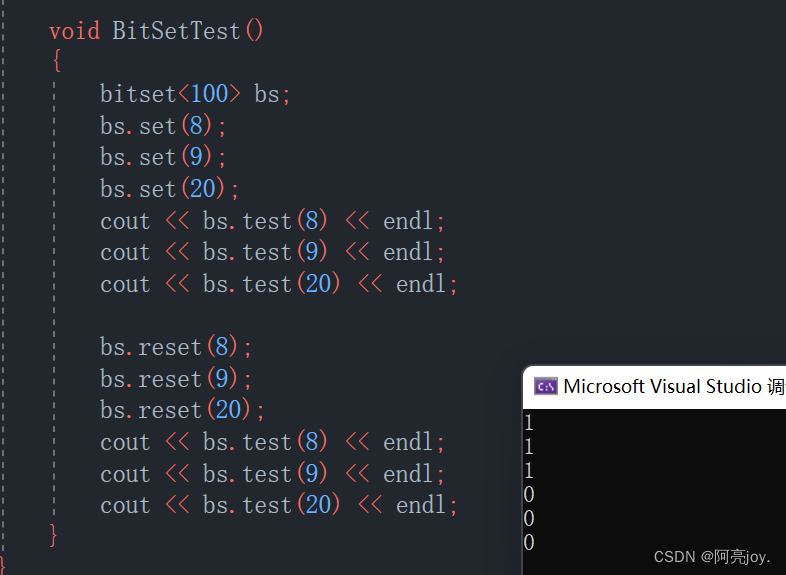
void BitSetTest()
{
bitset<100> bs;
bs.set(8);
bs.set(9);
bs.set(20);
cout << bs.test(8) << endl;
cout << bs.test(9) << endl;
cout << bs.test(20) << endl;
bs.reset(8);
bs.reset(9);
bs.reset(20);
cout << bs.test(8) << endl;
cout << bs.test(9) << endl;
cout << bs.test(20) << endl;
}
void BitSetTest2()
{
// 开出42亿9千万个比特位
bitset<-1> bs1;
bitset<0xffffffff> bs2;
}
}
位图的应用
- 快速查找某个数据是否在一个集合中
- 排序 + 去重
- 求两个集合的交集、并集等
- 操作系统中磁盘块标记
题目一给定 100 亿个整数设计算法找到只出现一次的整数 这种题目是 KV 的统计次数搜索模型一个数字出现次数有三种情况出现零次、出现一次以及出现两次及以上这三种情况只需要用两个比特位就可以表示。
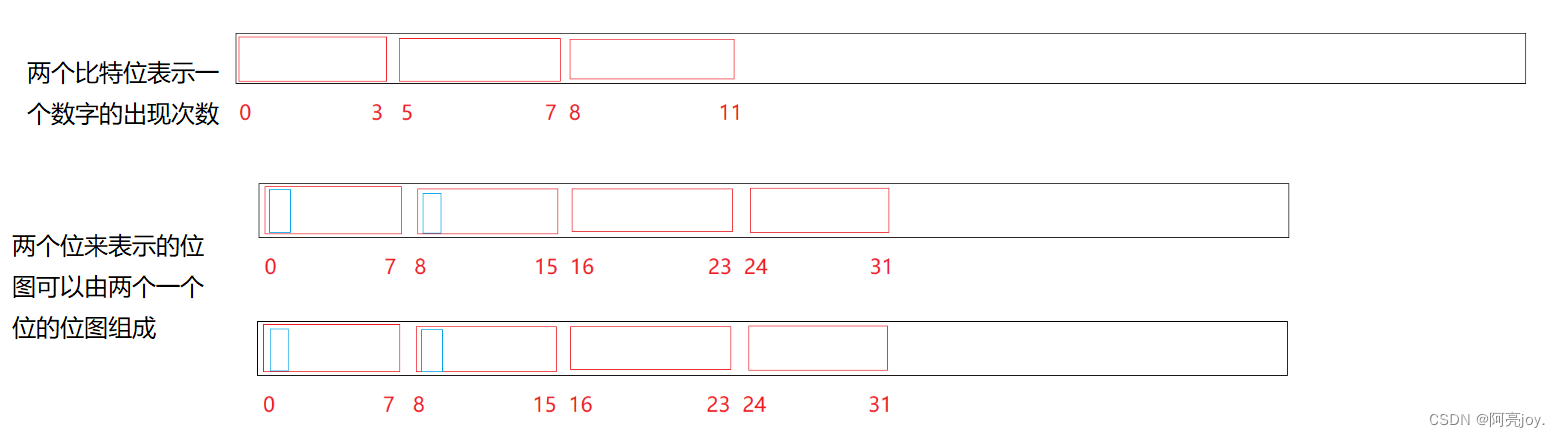
template <size_t N>
class twobitset
{
public:
void set(size_t x)
{
bool inset1 = _bs1.test(x);
bool inset2 = _bs2.test(x);
// 00
if(inset1 == false && inset2 == false)
{
// -> 01
_bs2.set(x);
}
else if (inset1 == false && inset2 == true) // 01
{
// -> 10
_bs1.set(x);
_bs2.reset(x);
}
else if (inset1 == true && inset2 == false)
{
// -> 11
_bs2.set(x);
}
// else是x出现三次及三次以上
}
void print_once_num()
{
for (size_t i = 0; i < N; ++i)
{
if (_bs1.test(i) == false && _bs2.test(i) == true)
cout << i << " ";
}
cout << endl;
}
private:
bitset<N> _bs1;
bitset<N> _bs2;
};
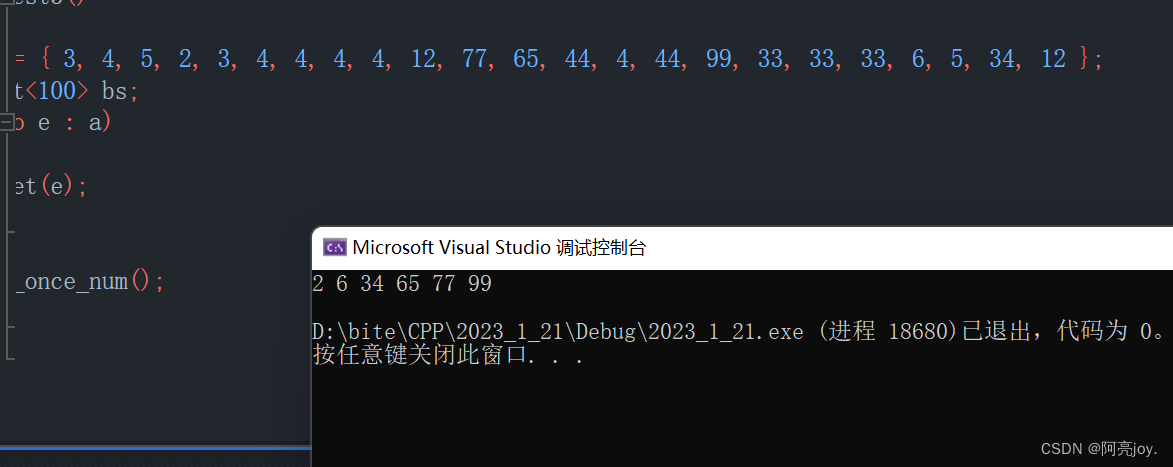
void BitSetTest3()
{
int a[] = { 3, 4, 5, 2, 3, 4, 4, 4, 4, 12, 77, 65, 44, 4, 44, 99, 33, 33, 33, 6, 5, 34, 12 };
twobitset<100> bs;
for (auto e : a)
{
bs.set(e);
}
bs.print_once_num();
}
题目二给两个文件分别有100亿个整数我们只有1G内存如何找到两个文件交集
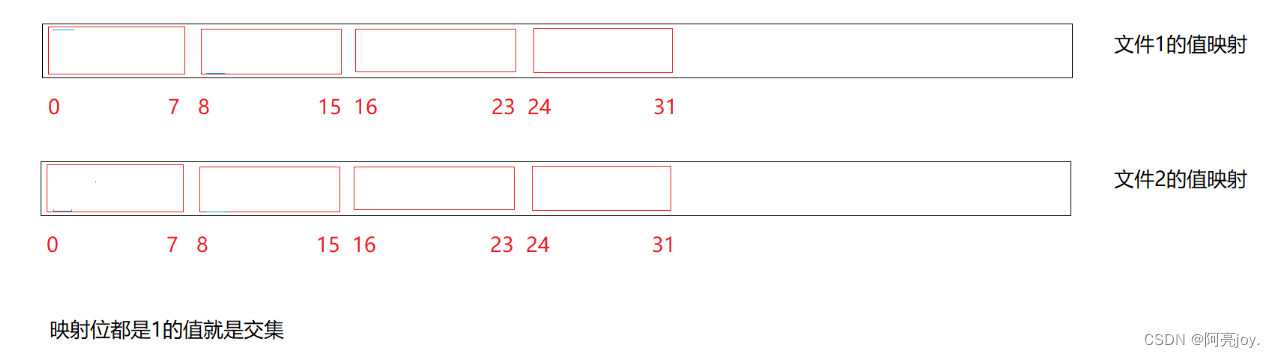
题目三1 个文件有 100 亿个 int1G内存设计算法找到出现次数不超过2次的所有整数

注位图只能处理整形。采用位图标记字符串时必须先将字符串转化为整形的数字找到位图中对应的比特 位但是在字符串转整形的过程中可能会出现不同字符串转化为同一个整形数字即冲突因此一般不会直接用位图处理字符串。
👉布隆过滤器👈
布隆过滤器的提出
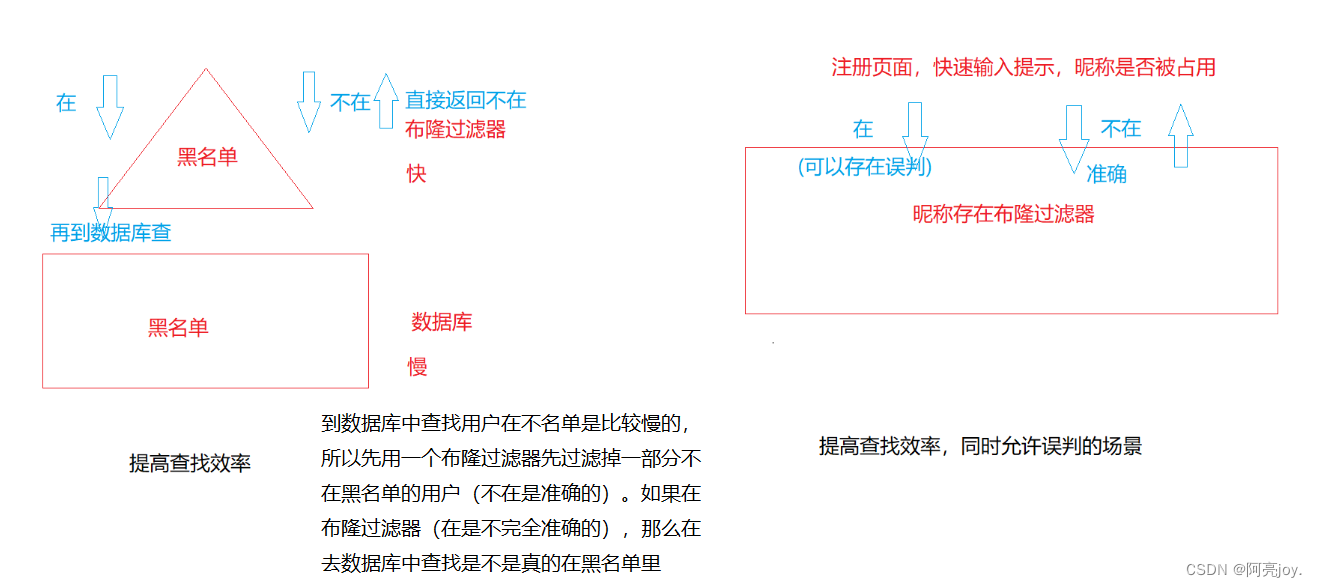
我们在使用新闻客户端看新闻时它会给我们不停地推荐新的内容它每次推荐时要去重去掉那些已经看过的内容。问题来了新闻客户端推荐系统如何实现推送去重的 用服务器记录了用户看过的所有历史记录当推荐系统推荐新闻时会从每个用户的历史记录里进行筛选过滤掉那些已经存在的记录。 如何快速查找呢
- 用哈希表存储用户记录缺点浪费空间。
- 用位图存储用户记录缺点位图一般只能处理整形如果内容编号是字符串就无法处理了。
- 将哈希与位图结合即布隆过滤器。
布隆过滤器概念
布隆过滤器是由布隆Burton Howard Bloom在1970年提出的 一种紧凑型的、比较巧妙的概率型数据结构特点是高效地插入和查询可以用来告诉你 “某样东西一定不存在或者可能存在”它是用多个哈希函数将一个数据映射到位图结构中。此种方式不仅可以提升查询效率也可以节省大量的内存空间。
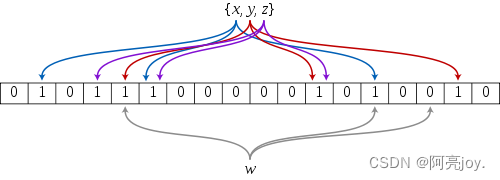
布隆过滤器的实现
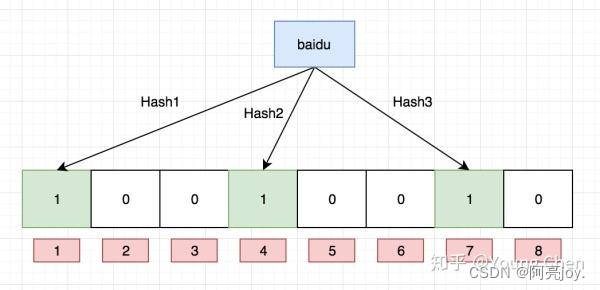
1. 查找
布隆过滤器的思想是将一个元素用多个哈希函数映射到一个位图中因此被映射到的位置的比特位一定为 1。所以可以按照以下方式进行查找分别计算每个哈希值对应的比特位置存储的是否为零只要有一个为零代表该元素一定不在哈希表中否则可能在哈希表中。注意布隆过滤器如果说某个元素不存在时该元素一定不存在如果该元素存在时该元素可能存在因为有些哈希函数存在一定的误判。
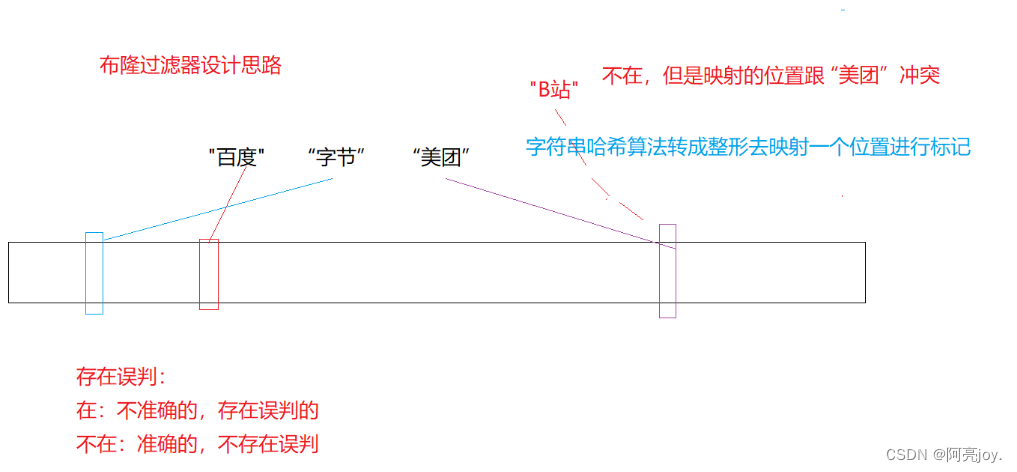
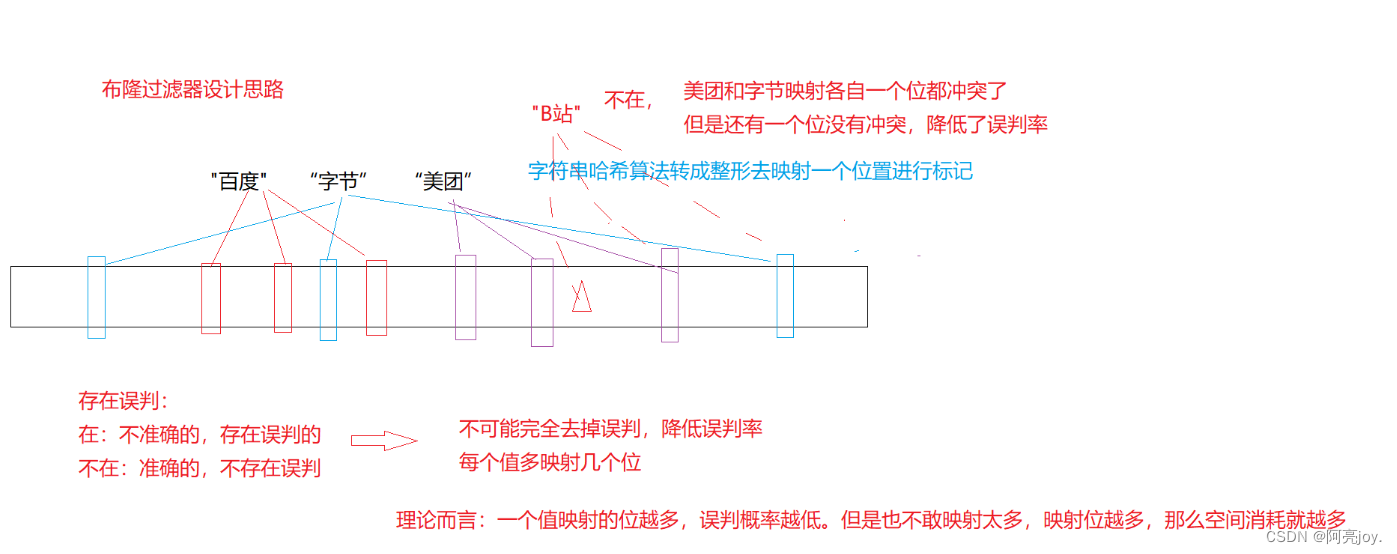
布隆过滤器的应用场景
布隆过滤器的公式

#pragma once
#include "BitSet.h"
namespace Joy
{
// 哈希函数
struct HashBKDR
{
// BKDR
size_t operator()(const string& key)
{
size_t val = 0;
for (auto ch : key)
{
val *= 131;
val += ch;
}
return val;
}
};
struct HashAP
{
// AP
size_t operator()(const string& key)
{
size_t hash = 0;
for (size_t i = 0; i < key.size(); i++)
{
if ((i & 1) == 0)
{
hash ^= ((hash << 7) ^ key[i] ^ (hash >> 3));
}
else
{
hash ^= (~((hash << 11) ^ key[i] ^ (hash >> 5)));
}
}
return hash;
}
};
struct HashDJB
{
// DJB
size_t operator()(const string& key)
{
size_t hash = 5381;
for (auto ch : key)
{
hash += (hash << 5) + ch;
}
return hash;
}
};
// N表示准备要映射N个值,布隆过滤器处理的类型通常是字符串
template<size_t N,
class K = string, class Hash1 = HashBKDR, class Hash2 = HashAP, class Hash3 = HashDJB>
class BloomFilter
{
public:
void set(const K& key)
{
size_t hash1 = Hash1()(key) % (_ratio * N);
_bits.set(hash1);
size_t hash2 = Hash2()(key) % (_ratio * N);
_bits.set(hash2);
size_t hash3 = Hash3()(key) % (_ratio * N);
_bits.set(hash3);
}
bool test(const K& key)
{
size_t hash1 = Hash1()(key) % (_ratio * N);
if (!_bits.test(hash1))
return false; // 准确的
size_t hash2 = Hash2()(key) % (_ratio * N);
if (!_bits.test(hash2))
return false; // 准确的
size_t hash3 = Hash3()(key) % (_ratio * N);
if (!_bits.test(hash3))
return false; // 准确的
return true; // 可能存在误判
}
// 能否支持删除? ->布隆过滤器一般不支持删除,如果要
// 删除的话,可以加上映射位置的引用计数。
void reset(const K& key);
private:
const static size_t _ratio = 5; // _ratio为倍率
bitset<_ratio* N> _bits; // 使用自己实现的bitset
};
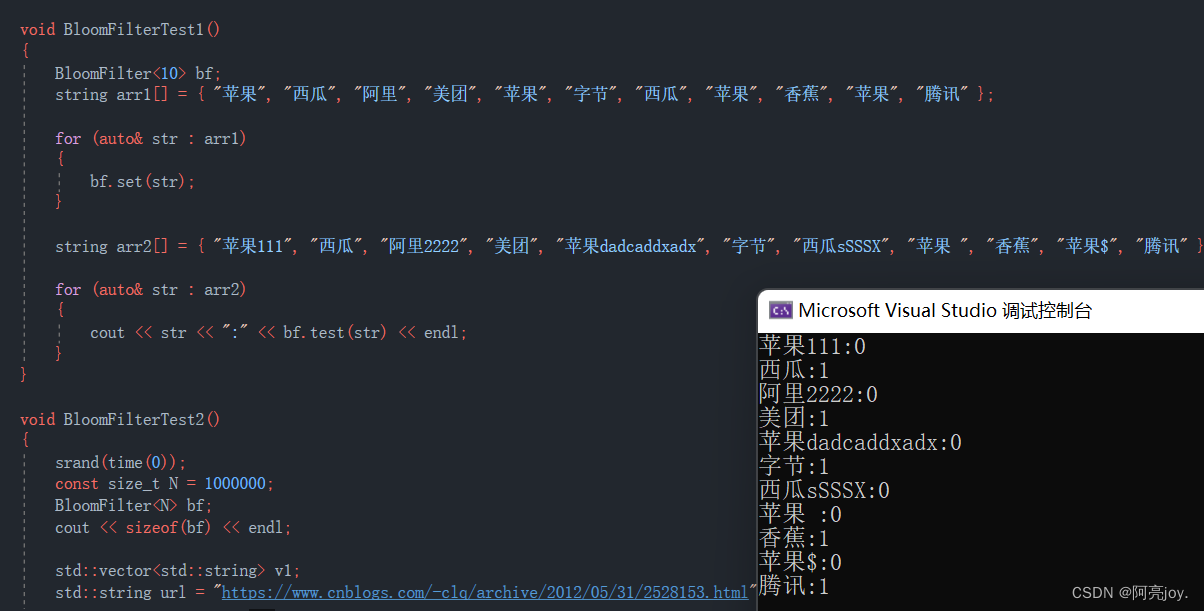
void BloomFilterTest1()
{
BloomFilter<10> bf;
string arr1[] = { "苹果", "西瓜", "阿里", "美团", "苹果", "字节", "西瓜", "苹果", "香蕉", "苹果", "腾讯" };
for (auto& str : arr1)
{
bf.set(str);
}
string arr2[] = { "苹果111", "西瓜", "阿里2222", "美团", "苹果dadcaddxadx", "字节", "西瓜sSSSX", "苹果 ", "香蕉", "苹果$", "腾讯" };
for (auto& str : arr2)
{
cout << str << ":" << bf.test(str) << endl;
}
}
void BloomFilterTest2()
{
srand(time(0));
const size_t N = 1000000;
BloomFilter<N> bf;
cout << sizeof(bf) << endl;
std::vector<std::string> v1;
std::string url = "https://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html";
for (size_t i = 0; i < N; ++i)
{
v1.push_back(url + std::to_string(1234 + i));
}
for (auto& str : v1)
{
bf.set(str);
}
// 相似
std::vector<std::string> v2;
for (size_t i = 0; i < N; ++i)
{
std::string url = "http://www.cnblogs.com/-clq/archive/2021/05/31/2528153.html";
url += std::to_string(rand() + i);
v2.push_back(url);
}
size_t n2 = 0;
for (auto& str : v2)
{
if (bf.test(str))
{
++n2;
}
}
cout << "相似字符串误判率:" << (double)n2 / (double)N << endl;
std::vector<std::string> v3;
for (size_t i = 0; i < N; ++i)
{
string url = "zhihu.com";
url += std::to_string(rand() + i);
v3.push_back(url);
}
size_t n3 = 0;
for (auto& str : v3)
{
if (bf.test(str))
{
++n3;
}
}
cout << "不相似字符串误判率:" << (double)n3 / (double)N << endl;
}
}

存储空间越大布隆过滤器的误判率就会越低。注库里的 bitset 是静态数组空间太大容易栈溢出可以在堆上开空间。
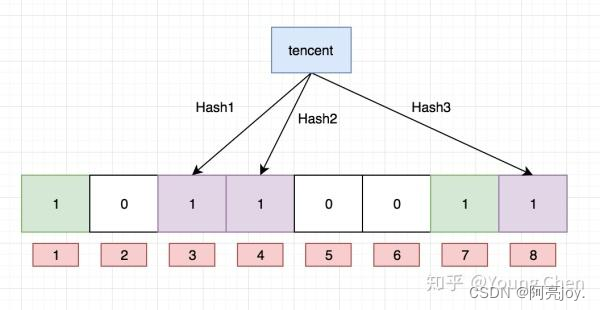
2. 删除
布隆过滤器不能直接支持删除工作因为在删除一个元素时可能会影响其他元素。
比如删除上图中"tencent"元素如果直接将该元素所对应的二进制比特位置0“baidu”元素也被删除了因为这两个元素在多个哈希函数计算出的比特位上刚好有重叠。
一种支持删除的方法将布隆过滤器中的每个比特位扩展成一个小的计数器插入元素时给 k 个计数器(k 个哈希函数计算出的哈希地址)加一删除元素时给 k 个计数器减一通过多占用几倍存储空间的代价来增加删除操作。
布隆过滤器优点和缺点
优点
- 增加和查询元素的时间复杂度为O(K), (K 为哈希函数的个数一般比较小)与数据量大小无关
- 哈希函数相互之间没有关系方便硬件并行运算
- 布隆过滤器不需要存储元素本身在某些对保密要求比较严格的场合有很大优势
- 在能够承受一定的误判时布隆过滤器比其他数据结构有这很大的空间优势
- 数据量很大时布隆过滤器可以表示全集其他数据结构不能
- 使用同一组散列函数的布隆过滤器可以进行交、并、差运算
缺点
- 有误判率即存在假阳性(False Position)即不能准确判断元素是否在集合中(补救方法再建立一个白名单存储可能会误判的数据)
- 不能获取元素本身
- 一般情况下不能从布隆过滤器中删除元素
- 如果采用计数方式删除可能会存在计数回绕问题
布隆过滤器的题目
题目一给两个文件分别有 100 亿个 query我们只有 1G 内存如何找到两个文件交集分别给出精确算法和近似算法。 query 是查询常见的查询有网络请求、SQL 语句等它们都是字符串。近似算法允许一些误判那么我们可以先将一个文件的 query 放入布隆过滤器中再去查另一个文件的 query 在不在布隆过滤器中就可以找到两个文件的交集了还需要去重。精确算法如下图所示
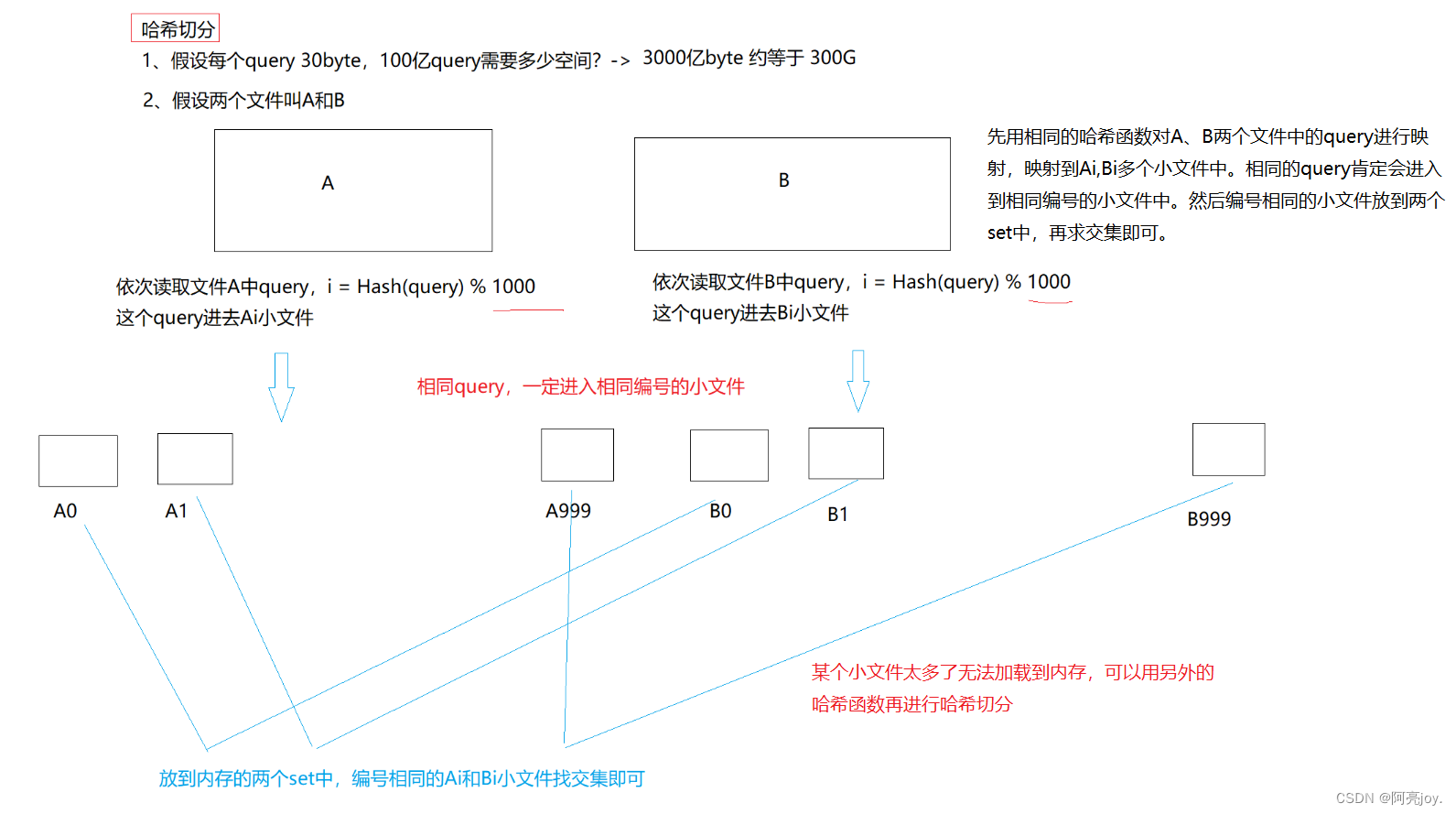
题目二如何扩展BloomFilter使得它支持删除元素的操作布隆过滤器一般是不支持删除的支持删除可能会影响其他值的查询。如果想要支持删除可以添加引用计数。但是支持了删除空间消耗就更多优势就变小了。
哈希切分题目给一个超过100G大小的log file, log中存着IP地址, 设计算法找到出现次数最多的IP地址与上题条件相同如何找到top K的IP如何直接用Linux系统命令实现
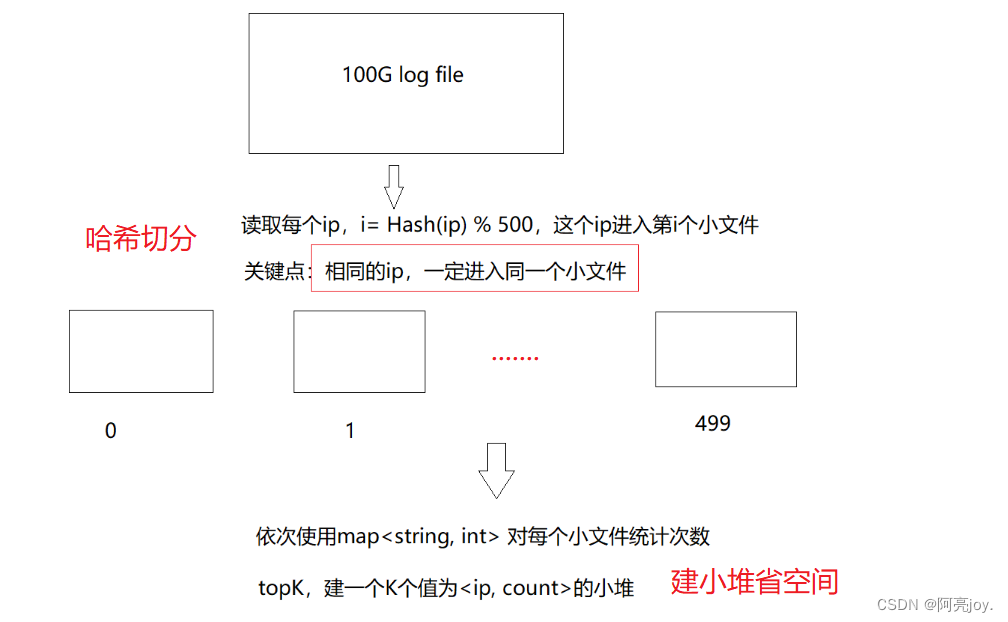
Linux 系统命令实现

注哈希切分并不是平均切分而是相同的哈希值的字符串等进入到相同的位置。
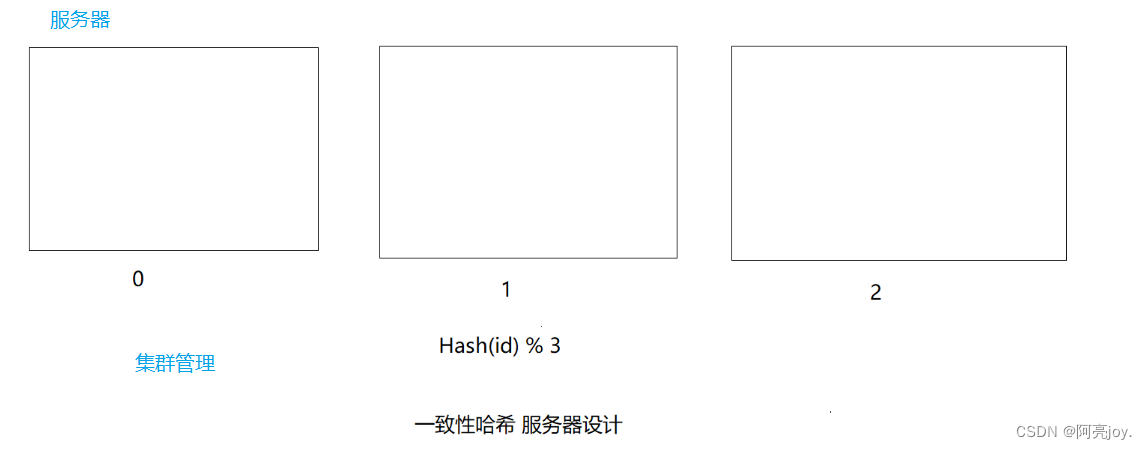
哈希的应用非常地广泛服务器存储中也使用到了哈希。
👉总结👈
本篇博客主要讲解了常见的哈希函数什么是位图、位图的实现和应用、什么是布隆过滤器、布隆过滤器的实现和优缺点以及哈希切分等等。那么以上就是本篇博客的全部内容了如果大家觉得有收获的话可以点个三连支持一下谢谢大家💖💝❣️