【nvidia CUDA 高级编程】NVSHMEM 直方图——复制式方法
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
博主未授权任何人或组织机构转载博主任何原创文章感谢各位对原创的支持
博主链接
本人就职于国际知名终端厂商负责modem芯片研发。
在5G早期负责终端数据业务层、核心网相关的开发工作目前牵头6G算力网络技术标准研究。
博客内容主要围绕
5G/6G协议讲解
算力网络讲解云计算边缘计算端计算
高级C语言讲解
Rust语言讲解
NVSHMEM 直方图——复制式方法

PE处理单元process entity
直方图简介
我们来了解一个与之前的问题有些相似但却稍显复杂的问题构造直方图。也就是说给定一个具有 𝑁 个整数的数组和 𝑀 个取值范围计算数组中有多少元素属于 𝑀 个范围中的某一个。不失一般性我们将指定整数是 [0,𝐾−1] 区间内的正数范围或桶是均匀的线性间隔为了简单起见 𝐾 可以被 𝑀 整除从而第一个桶可以覆盖 [0,𝐾/𝑀−1] 区间内的数第二个可以覆盖 [𝐾/𝑀,2𝐾/𝑀−1] 区间内的数以此类推。
在我们开始为多个 GPU 重构代码之前我们将从使用单 GPU 的代码示例入手。解决这个问题最简单的方法还是使用原子操作。我们将对数组进行循环计算数组中的每个元素应落入哪个桶给定一个整数 𝑛 其所属的直方图数组的索引为 (𝑛𝑀)/𝐾 。然后以原子操作增加该桶的计数器。检查代码然后运行代码看看会得到什么样的输出。您可按需随意调整参数但要避免数字过大注意 32 位整数溢出。
#include <iostream>
#include <cstdlib>
inline void CUDA_CHECK (cudaError_t err) {
if (err != cudaSuccess) {
fprintf(stderr, "CUDA error: %s\n", cudaGetErrorString(err));
exit(-1);
}
}
#define NUM_BUCKETS 16
#define MAX_VALUE 1048576
#define NUM_INPUTS 65536
__global__ void histogram_kernel(const int* input, int* histogram, int N)
{
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < N) {
int value = input[idx];
int histogram_index = (value * NUM_BUCKETS) / MAX_VALUE;
atomicAdd(&histogram[histogram_index], 1);
}
}
int main(int argc, char** argv) {
const int N = NUM_INPUTS;
// 在主机上构建直方图输入数据
int* input = (int*) malloc(N * sizeof(int));
// 输入数据范围从 0 至 MAX_VALUE - 1 不等
for (int i = 0; i < N; ++i) {
input[i] = rand() % MAX_VALUE;
}
// 复制到设备
int* d_input;
CUDA_CHECK(cudaMalloc((void**) &d_input, N * sizeof(int)));
CUDA_CHECK(cudaMemcpy(d_input, input, N * sizeof(int), cudaMemcpyHostToDevice));
// 分配直方图数组
int* histogram = (int*) malloc(NUM_BUCKETS * sizeof(int));
memset(histogram, 0, NUM_BUCKETS * sizeof(int));
int* d_histogram;
CUDA_CHECK(cudaMalloc((void**) &d_histogram, NUM_BUCKETS * sizeof(int)));
CUDA_CHECK(cudaMemset(d_histogram, 0, NUM_BUCKETS * sizeof(int)));
// 执行直方图
int threads_per_block = 256;
int blocks = (NUM_INPUTS + threads_per_block - 1) / threads_per_block;
histogram_kernel<<<blocks, threads_per_block>>>(d_input, d_histogram, N);
CUDA_CHECK(cudaDeviceSynchronize());
// 将数据复制回主机并检查一些值
CUDA_CHECK(cudaMemcpy(histogram, d_histogram, NUM_BUCKETS * sizeof(int), cudaMemcpyDeviceToHost));
std::cout << "Histogram counters:" << std::endl << std::endl;
int num_buckets_to_print = 4;
for (int i = 0; i < NUM_BUCKETS; i += NUM_BUCKETS / num_buckets_to_print) {
std::cout << "Bucket [" << i * (MAX_VALUE / NUM_BUCKETS) << ", " << (i + 1) * (MAX_VALUE / NUM_BUCKETS) - 1 << "]: " << histogram[i];
std::cout << std::endl;
if (i < NUM_BUCKETS - NUM_BUCKETS / num_buckets_to_print - 1) {
std::cout << "..." << std::endl;
}
}
free(input);
free(histogram);
CUDA_CHECK(cudaFree(d_input));
CUDA_CHECK(cudaFree(d_histogram));
return 0;
}
编译运行指令如下
nvcc -x cu -arch=sm_70 -o histogram histogram.cpp
./histogram
运行结果如下
Histogram counters:
Bucket [0, 65535]: 4083
...
Bucket [262144, 327679]: 4107
...
Bucket [524288, 589823]: 4015
...
Bucket [786432, 851967]: 4045
复制式方法的 NVSHMEM 实现
在多个 GPU 上分配工作量的一种方法与我们在 𝜋 估算器上使用的方法相同给定 𝑁 个整数我们即可把它们均匀地分配到所有 GPU 上然后可以对所有 PE 进行归约。我们将此称为**“复制式”方法**因为在所有 GPU 上都存在完整的直方图副本。我们将第一步即增加每个直方图桶内的计数值命名为“列表”步骤将合并所有 PE 上的结果的第二步命名为“结合”步骤并分别计算时间以便与下一个方法进行比较。
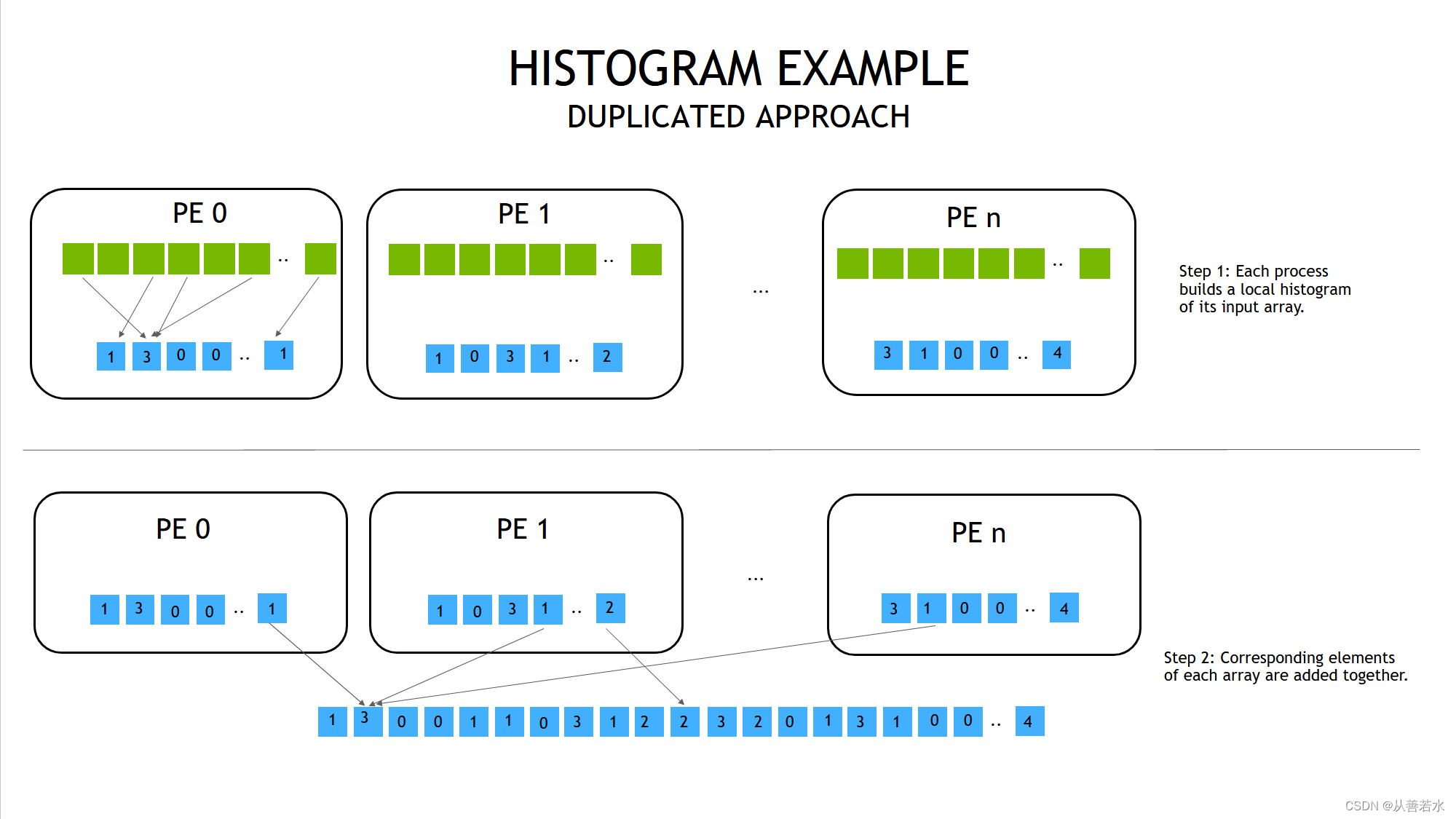
我们将使用归约 API nvshmem_int_sum_reduce() 来归约直方图的所有桶
nvshmem_int_sum_reduce(team, destination, source, nelems);
如果 destination == source那么这就变成了就地归约是 NVSHMEM 中的合理做法这样做的好处在于与创建临时目标缓冲区相比其代码更加干净所以我们建议在此练习中这样做。
练习
代码如下file namehistogram_step1.cpp
#include <iostream>
#include <cstdlib>
#include <chrono>
#include <nvshmem.h>
#include <nvshmemx.h>
inline void CUDA_CHECK (cudaError_t err) {
if (err != cudaSuccess) {
fprintf(stderr, "CUDA error: %s\n", cudaGetErrorString(err));
exit(-1);
}
}
#define NUM_BUCKETS 16
#define MAX_VALUE 1048576
#define NUM_INPUTS 65536
__global__ void histogram_kernel(const int* input, int* histogram, int N)
{
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < N) {
int value = input[idx];
int histogram_index = ((size_t) value * NUM_BUCKETS) / MAX_VALUE;
atomicAdd(&histogram[histogram_index], 1);
}
}
int main(int argc, char** argv) {
// 初始化 NVSHMEM
nvshmem_init();
// 获取 NVSHMEM 处理元素 ID 和 PE 数量
int my_pe = nvshmem_my_pe();
int n_pes = nvshmem_n_pes();
// 每个 PE任意选择与其 ID 对应的 GPU
int device = my_pe;
CUDA_CHECK(cudaSetDevice(device));
// 每台设备处理 1 / n_pes 的部分工作。
const int N = NUM_INPUTS / n_pes;
// 在主机上构建直方图输入数据
int* input = (int*) malloc(N * sizeof(int));
// 为每个 PE 初始化一个不同的随机数种子。
srand(my_pe);
// 输入数据范围从 0 至 MAX_VALUE - 1 不等
for (int i = 0; i < N; ++i) {
input[i] = rand() % MAX_VALUE;
}
// 复制到设备
int* d_input;
d_input = (int*) nvshmem_malloc(N * sizeof(int));
CUDA_CHECK(cudaMemcpy(d_input, input, N * sizeof(int), cudaMemcpyHostToDevice));
// 分配直方图数组
int* histogram = (int*) malloc(NUM_BUCKETS * sizeof(int));
memset(histogram, 0, NUM_BUCKETS * sizeof(int));
int* d_histogram;
d_histogram = (int*) nvshmem_malloc(NUM_BUCKETS * sizeof(int));
CUDA_CHECK(cudaMemset(d_histogram, 0, NUM_BUCKETS * sizeof(int)));
// 为合理准确的计时执行一次同步
nvshmem_barrier_all();
using namespace std::chrono;
high_resolution_clock::time_point tabulation_start = high_resolution_clock::now();
// 执行直方图
int threads_per_block = 256;
int blocks = (NUM_INPUTS / n_pes + threads_per_block - 1) / threads_per_block;
histogram_kernel<<<blocks, threads_per_block>>>(d_input, d_histogram, N);
CUDA_CHECK(cudaDeviceSynchronize());
nvshmem_barrier_all();
high_resolution_clock::time_point tabulation_end = high_resolution_clock::now();
high_resolution_clock::time_point combination_start = high_resolution_clock::now();
// 在所有 PE 上执行归约
nvshmem_int_sum_reduce(NVSHMEM_TEAM_WORLD, d_histogram, d_histogram, NUM_BUCKETS);
high_resolution_clock::time_point combination_end = high_resolution_clock::now();
// 打印 PE 0 上的结果
if (my_pe == 0) {
duration<double> tabulation_time = duration_cast<duration<double>>(tabulation_end - tabulation_start);
std::cout << "Tabulation time = " << tabulation_time.count() * 1000 << " ms" << std::endl << std::endl;
duration<double> combination_time = duration_cast<duration<double>>(combination_end - combination_start);
std::cout << "Combination time = " << combination_time.count() * 1000 << " ms" << std::endl << std::endl;
// 将数据复制回主机
CUDA_CHECK(cudaMemcpy(histogram, d_histogram, NUM_BUCKETS * sizeof(int), cudaMemcpyDeviceToHost));
std::cout << "Histogram counters:" << std::endl << std::endl;
int num_buckets_to_print = 4;
for (int i = 0; i < NUM_BUCKETS; i += NUM_BUCKETS / num_buckets_to_print) {
std::cout << "Bucket [" << i * (MAX_VALUE / NUM_BUCKETS) << ", " << (i + 1) * (MAX_VALUE / NUM_BUCKETS) - 1 << "]: " << histogram[i];
std::cout << std::endl;
if (i < NUM_BUCKETS - NUM_BUCKETS / num_buckets_to_print - 1) {
std::cout << "..." << std::endl;
}
}
}
free(input);
free(histogram);
nvshmem_free(d_input);
nvshmem_free(d_histogram);
// 最终确定 nvshmem
nvshmem_finalize();
return 0;
}
编译和运行命令
nvcc -x cu -arch=sm_70 -rdc=true -I $NVSHMEM_HOME/include -L $NVSHMEM_HOME/lib -lnvshmem -lcuda -o histogram_step1 exercises/histogram_step1.cpp
nvshmrun -np $NUM_DEVICES ./histogram_step1
运行结果如下
Tabulation time = 0.033777 ms
Combination time = 0.042937 ms
Histogram counters:
Bucket [0, 65535]: 4135
...
Bucket [262144, 327679]: 4028
...
Bucket [524288, 589823]: 4088
...
Bucket [786432, 851967]: 4100