

Linux安装单机版Hadoop和windows配置Hadoop环境
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
文章目录
一、Linux安装Hadoop
1.1、下载安装文件
链接https://pan.baidu.com/s/19s19t-yDcxRuj0AnnDOSkQ
提取码n7km
linux安装hadoop需要下方两个文件剩下两个文件是windows配置环境使用
1.2、创建虚拟机
详情请查看创建linux虚拟机
1.3、配置网络
详情请查看配置linux网络
1.4、设置免密登录
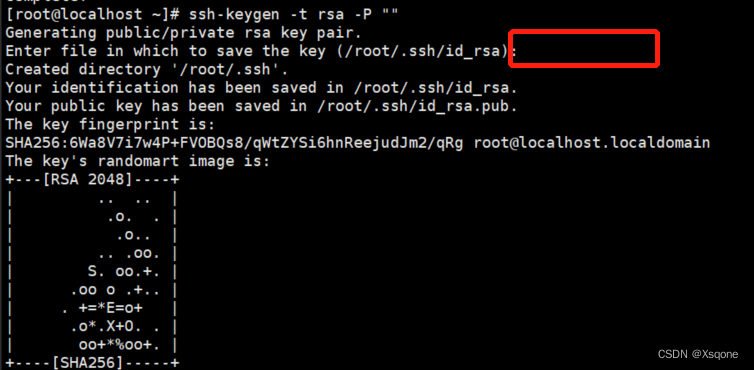
[root@localhost ~]# ssh-keygen -t rsa -P ""
此处直接回车
[root@localhost ~]# cd .ssh/
[root@localhost .ssh]# ls
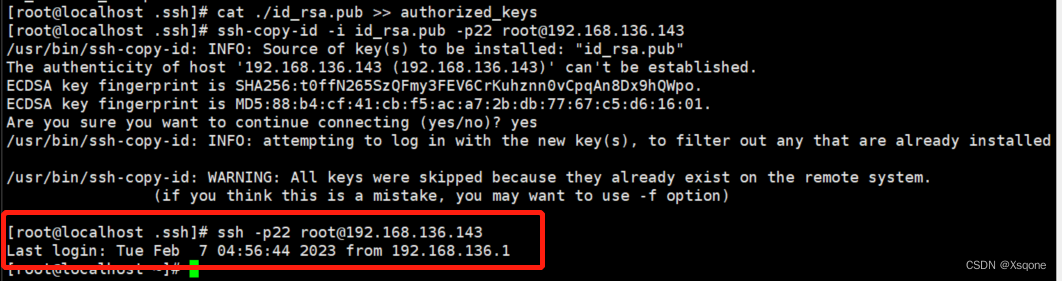
[root@localhost .ssh]# cat ./id_rsa.pub >> authorized_keys
# 开启远程免密登录配置
[root@localhost .ssh]# ssh-copy-id -i ./id_rsa.pub -p22 root@192.168.136.143
# 远程登录
[root@localhost .ssh]# ssh -p22 root@192.168.136.143
# 退出远程登录
[root@localhost .ssh]# exit
完成使用ssh -p22 root@192.168.136.143命令会直接连上不需要输入密码
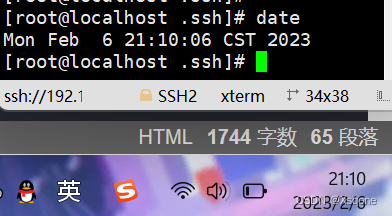
1.5、同步时间
在创建下虚拟机后会与北京时间差8个小时需要将其同步
# 同步时间
[root@localhost .ssh]# yum install -y ntpdate
[root@localhost .ssh]# ntpdate time.windows.com
[root@localhost .ssh]# date
# 定时同步时间
[root@localhost .ssh]# crontab -e
# 每5小时更新时间
* */5 * * * /usr/sbin/ntpdate -u time.windows.com
# 启动定时任务
[root@localhost .ssh]# service crond start
更改时区后
1.6、设置计算机名称
# 修改计算机名称有两种方式
# 在配置文件中修改
[root@localhost .ssh]# vim /etc/hostname
# 通过命令修改
[root@localhost .ssh]# hostnamectl set-hostname xsqone143
# 配置hosts文件
[root@localhost .ssh]# vim /etc/hosts
xsqone143 192.168.136.143
1.7、安装JDK
hadoop依赖于JAVA环境需要按照JDK
# 解压文件到指定目录
[root@localhost opt]# mkdir /opt/install
[root@localhost opt]# mkdir /opt/soft
再使用xftp将文件传入到/opt/install目录下
[root@localhost install]# pwd
/opt/install
# 将文件解压到/opt/soft目录下
[root@localhost install]# tar -zxvf jdk-8u321-linux-x64.tar.gz -C ../soft/
[root@localhost soft]# mv jdk1.8.0_321/ jdk180
# 加入jdk的环境变量
[root@localhost soft]# vim /etc/profile
# JAVA_HOME
export JAVA_HOME=/opt/soft/jdk180
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
[root@localhost soft]# source /etc/profile
使用java命令或javac命令 出现提示或使用java -version命令会显示jdk版本则安装成功
1.8、安装Hadoop
[root@localhost install]# tar -zxvf hadoop-3.1.3.tar.gz -C ../soft/
[root@localhost soft]# mv hadoop-3.1.3/ hadoop313
# 修改hadoop文件所属
[root@xsqone143 soft]# chown -R root:root hadoop313/
# 修改hadoop配置文件
[root@xsqone143 hadoop]# pwd
/opt/soft/hadoop313/etc/hadoop
1.8.1、core-site.xml
[root@xsqone143 hadoop]# vim core-site.xml
<configuration>
# 路径
<property>
<name>fs.defaultFS</name>
<value>hdfs://xsqone143:9000</value>
</property>
# 存放数据临时目录
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/soft/hadoop313/data</value>
</property>
# http请求的静态用户
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
# 读写序列缓存
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
<description>读写序列缓存为128KB</description>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
1.8.2、hadoop-env.sh
# 设置hadoop所使用的的jdk
[root@xsqone143 hadoop]# vim hadoop-env.sh
54 export JAVA_HOME=/opt/soft/jdk180
1.8.3、hdfs-site.xml
[root@xsqone143 hadoop]# vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>hadoop中每一个block文件的备份数量</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/soft/hadoop313/data/dfs/name</value>
<description>namenode上存储hdfs名字空间元数据的目录</description>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>/opt/soft/hadoop313/data/dfs/data</value>
<description>datanode上数据块的物理存储位置目录</description>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
<description>关闭权限验证</description>
</property>
</configuration>
1.8.4、mapred-site.xml
[root@xsqone143 hadoop]# vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>job执行框架local,classic or yarn</description>
<final>true</final>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>/opt/soft/hadoop313/etc/hadoop:/opt/soft/hadoop313/share/hadoop/common/lib/*:/opt/soft/hadoop313/share/hadoop/common/*:/opt/soft/hadoop313/share/hadoop/hdfs/*:/opt/soft/hadoop313/share/hadoop/hdfs/lib/*:/opt/soft/hadoop313/share/hadoop/mapreduce/*:/opt/soft/hadoop313/share/hadoop/mapreduce/lib/*:/opt/soft/hadoop313/share/hadoop/yarn/*:/opt/soft/hadoop313/share/hadoop/yarn/lib/*</value>
<description>job执行框架local,classic or yarn</description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>xsqone143:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>xsqone143:19888</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>2048</value>
</property>
</configuration>
1.8.4、yarn-site.xml
[root@xsqone143 hadoop]# vim yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>20000</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<property>
<name>yarn.nodemanager.localizer.address</name>
<value>xsqone143:8040</value>
</property>
<property>
<name>yarn.nodemanager.address</name>
<value>xsqone143:8050</value>
</property>
<property>
<name>yarn.nodemanager.webapp.address</name>
<value>xsqone143:8042</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/opt/soft/hadoop313/yarndata/yarn</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/opt/soft/hadoop313/yarndata</value>
</property>
</configuration>
1.8.4、设置hadoop环境变量
export HADOOP_HOME=/opt/soft/hadoop313
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/lib
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_LIBEXEC_DIR=$HADOOP_HOME/libexec
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
1.9、配置完成进行启动测试
# 格式化
[root@xsqone143 hadoop]# hdfs namenode -format
# 运行
[root@xsqone143 hadoop]# start-all.sh
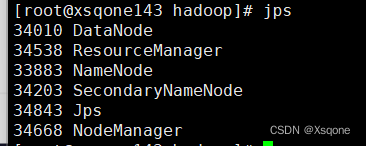
# 查看是否启动成功(一共会有6个线程)
[root@xsqone143 hadoop]# jps
二、windows配置Hadoop环境
将hadoop-3.1.3.tar.gz解压然后配置环境变量
2.1、配置环境变量
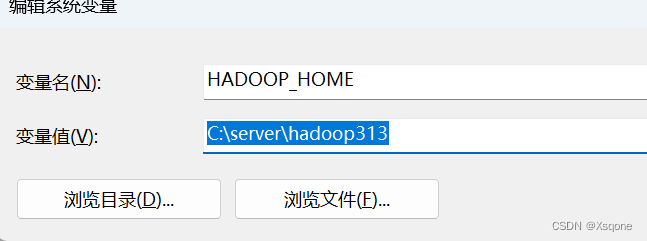
2.1.1、HADOOP_HOME
变量名HADOOP_HOME
变量值存放hadoop的位置
2.1.2、PATH
%HADOOP_HOME%\bin
%HADOOP_HOME%\sbin
%HADOOP_HOME%\lib
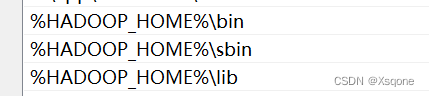
2.2、放入window所需文件
- 将下方文文件解压两个文件hadoop.cmd,hadoop.dll都放入hadoop目录下的bin目录
- 再将hadoop.dll文件放入C:\Windows\System32目录下

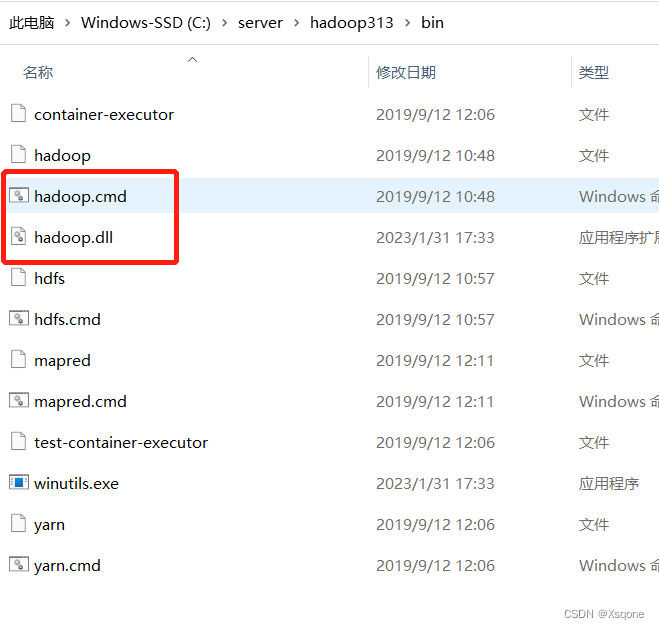
- 测试打开命令提示窗口输入hadoop -version出现hadoop版本号即可
- 再双击hadoop.cmd文件若是闪一下即配置成功若是报错 没有msvcr120.dll文件则使用下方文件给windows系统打上补丁
