堆的实现及应用
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
下面用C语言介绍堆的实现以及应用
文章目录
1. 堆的简介
堆是一颗完全二叉树。这里所说的堆是一种非连续的数据结构与操作系统内存分布的堆是两回事它们没有任何联系。
堆有以下特点
- 堆中某个结点的值总是不大于或不小于其父结点的值
- 堆是一颗完全二叉树
- 堆的逻辑结构是一颗完全二叉树但是物理结构是顺序表
小堆 任何一个结点的值都大于或者等于孩子结点的值
小堆 任何一个结点的值都小于或者等于孩子结点的值
数据下标计算父子关系公式
2. 堆的实现
这些介绍堆的以下接口
HeapInit
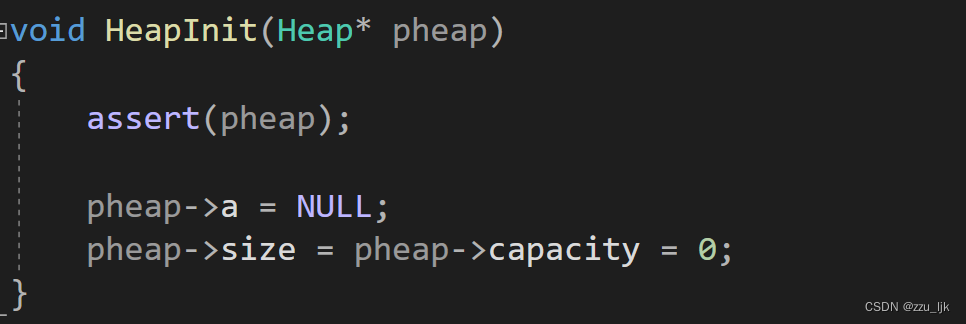
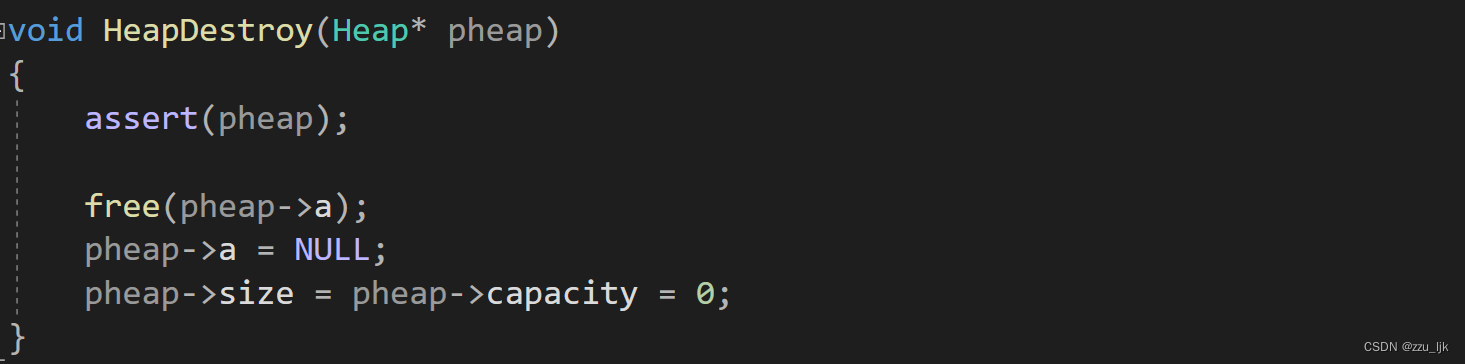
HeapDestroy
HeapPush
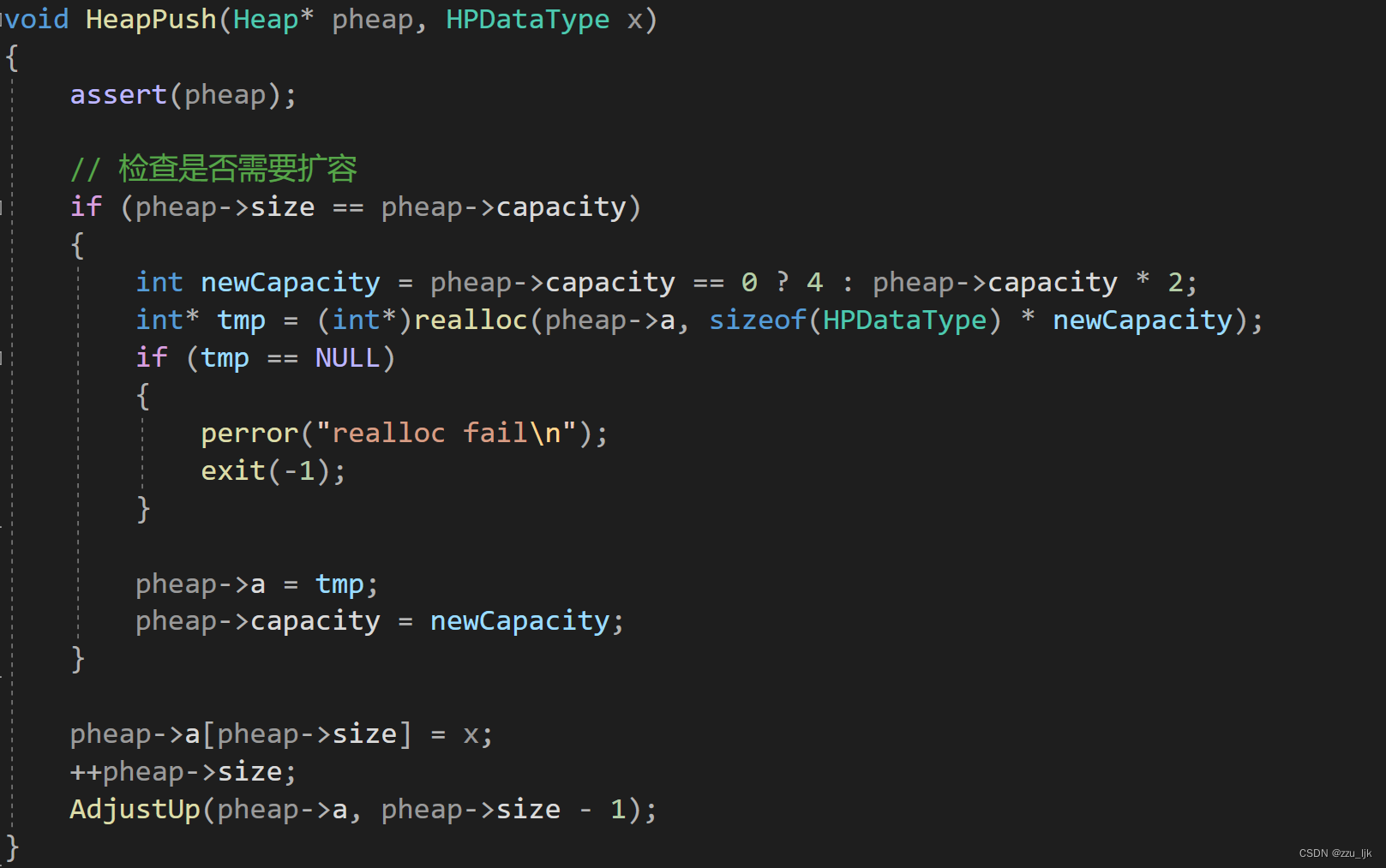
这里使用了向上调整算法
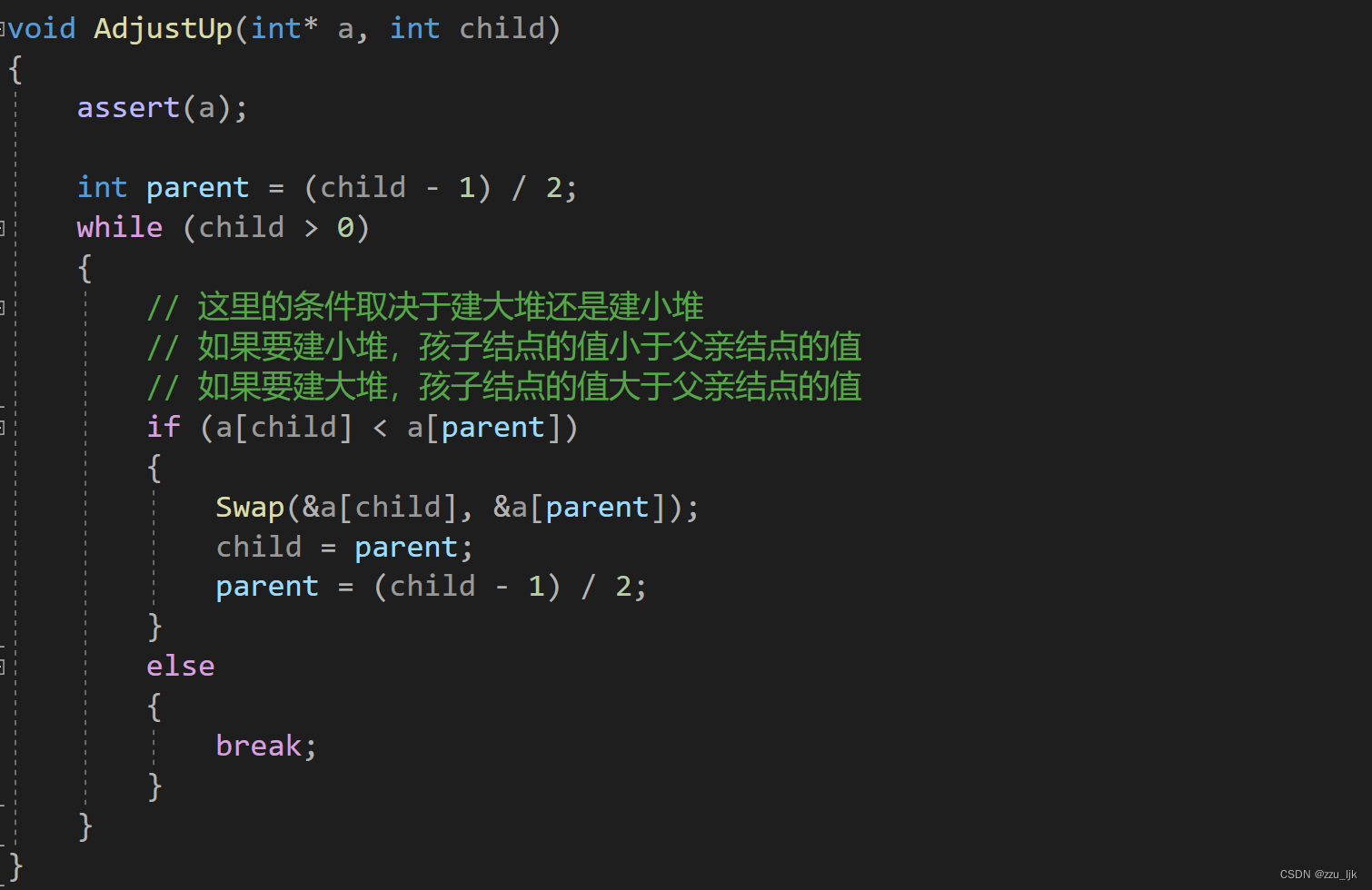
HeapPop

这里使用了向下调整算法
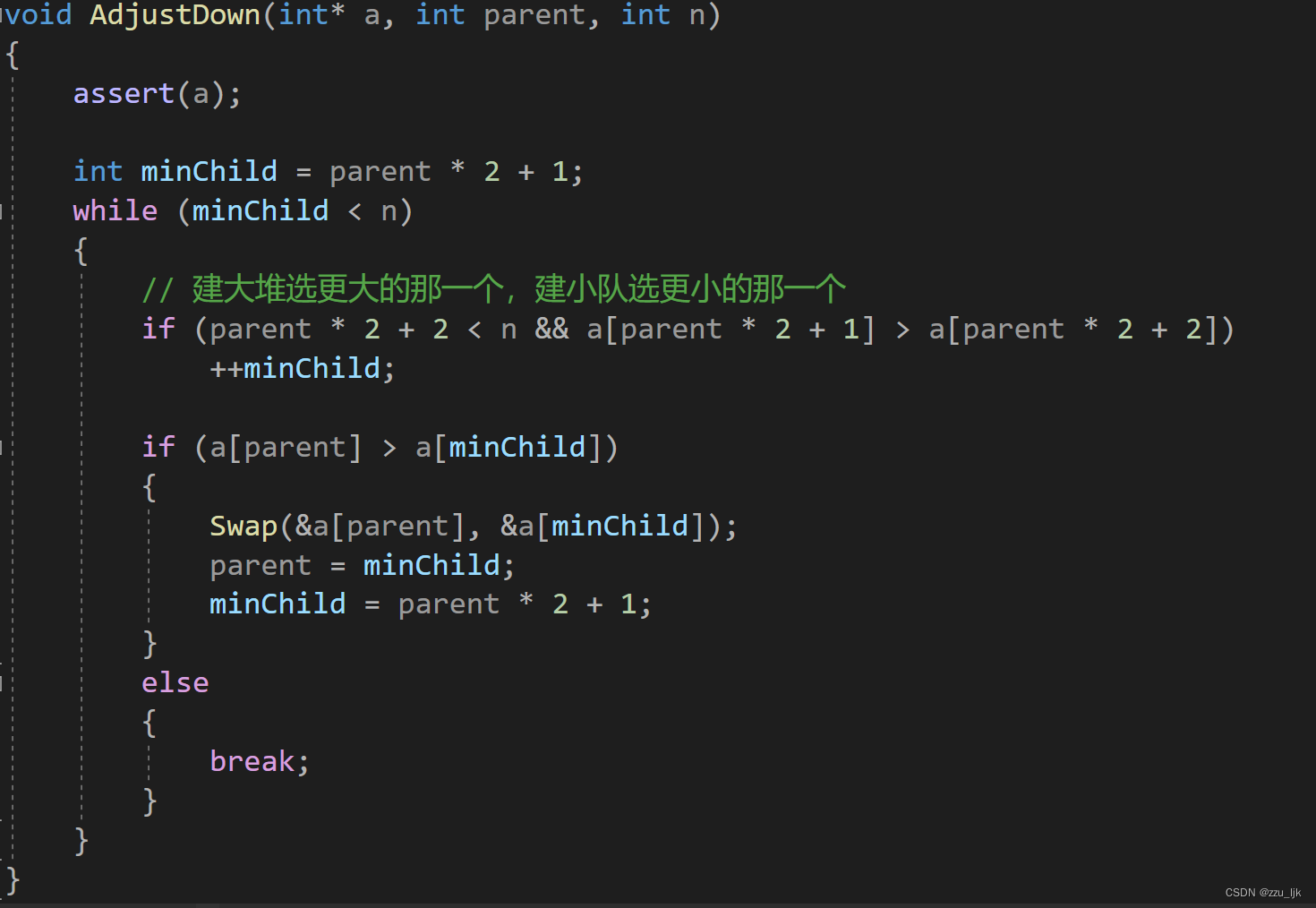
3. 堆的应用
堆排序
升序建大堆降序建小堆
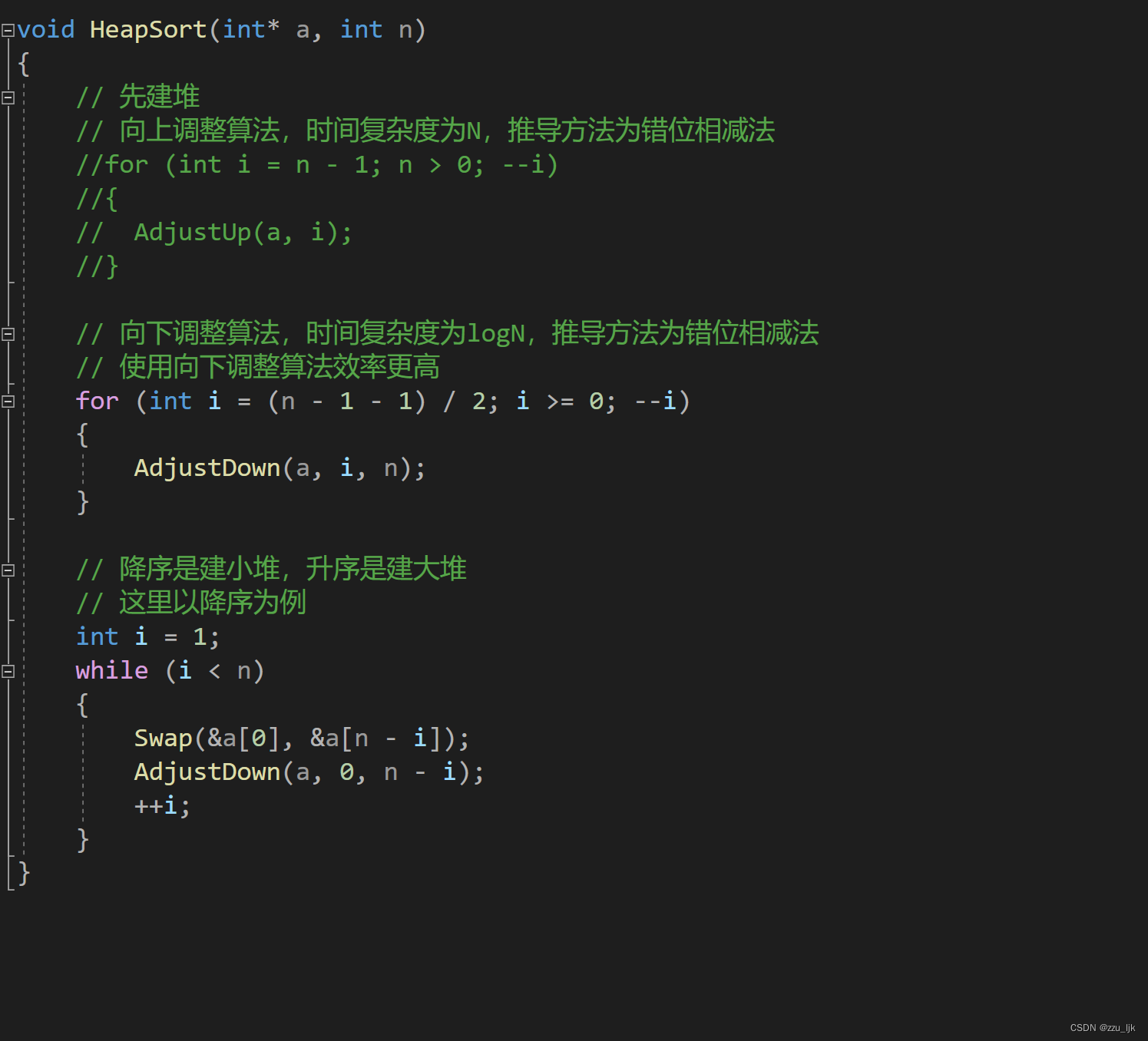
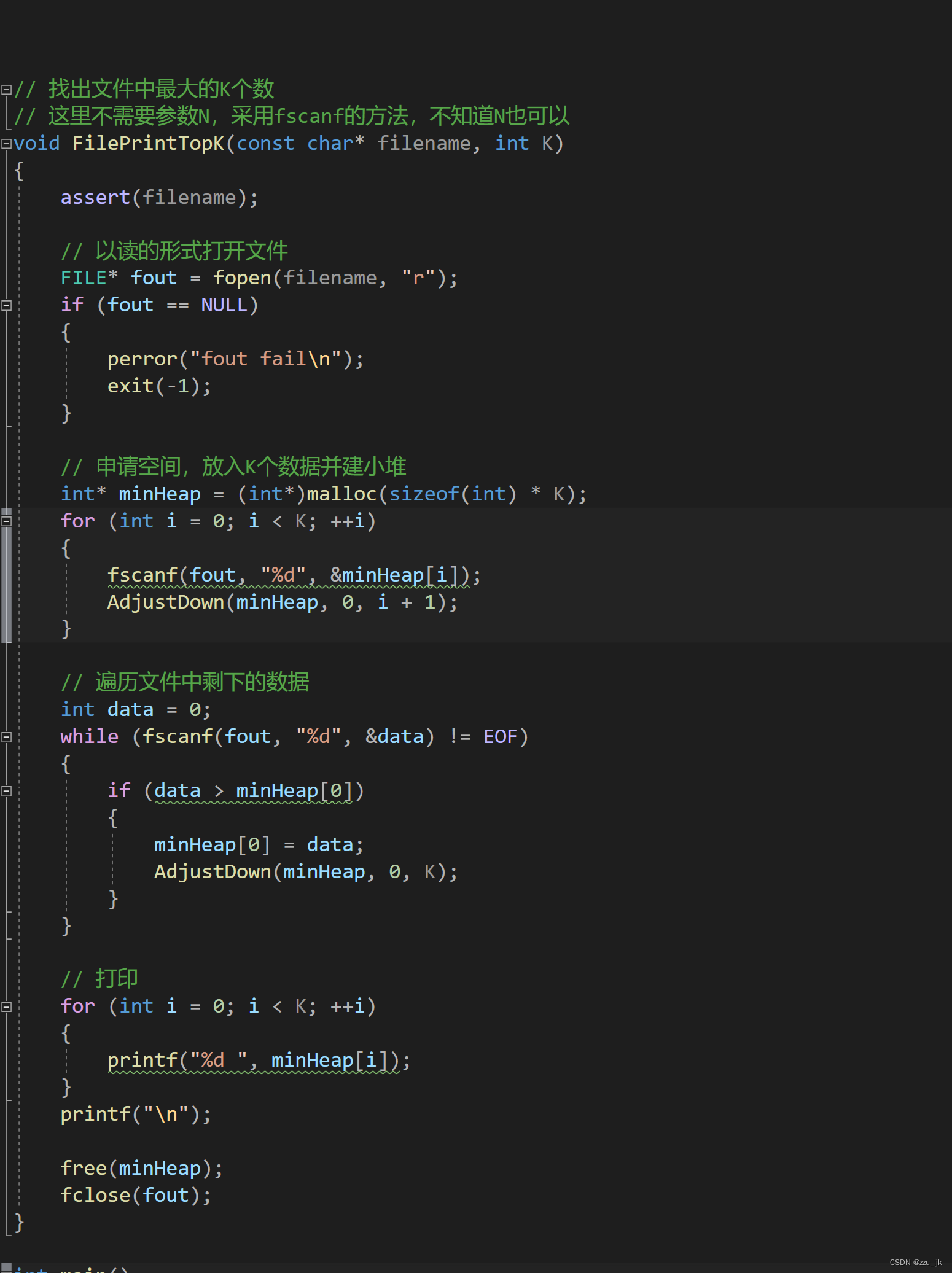
TopK问题
TopK问题即在N个数中N非常大选出前K个最大或者最小的数
这里以选出前K个最大的数为例
选出最大的前K个数可以建大堆也可以建小堆
如果建大堆思路就和堆排序的思路一样都是需要先建堆然后进行选数即可不同的是这样选数只需要选K次。时间复杂度为N + logK。但是这个方法有一定的弊端。我们不妨设想当数据非常大的时候也就是不能全部放在内存的时候比如10亿个整数需要40个G的空间来存储这个时候这40个G就只能放在磁盘中了。我们建堆的话就只能分批次在磁盘中拿数据然后分部分地建堆最后再将每部分最大的数据放在一起。这样的话效率就减慢了但是也不能说太慢也在我们可以接受的范围之内。
如果建小堆用小堆来选出最大的K个数小堆的第一个数是最小的那个数然后再便利剩下N - K个 数当有数比小堆中最小的那个数更大时就将最小的那个数的值赋给堆顶的数然后使用向下调整算法。时间复杂度为
logK + (N - K)* logK。数据较少时和建大堆的时间复杂度相差不大但是当数据较大它的优势就很明显了。
结论是选最大K个数建小堆更好选最小K个数建大堆更好
下面给出选最大K个数建小堆的代码

这里再尝试使用堆来选出磁盘数据中最大的K个数
首先创建文件并在文件中写入大量的随机数。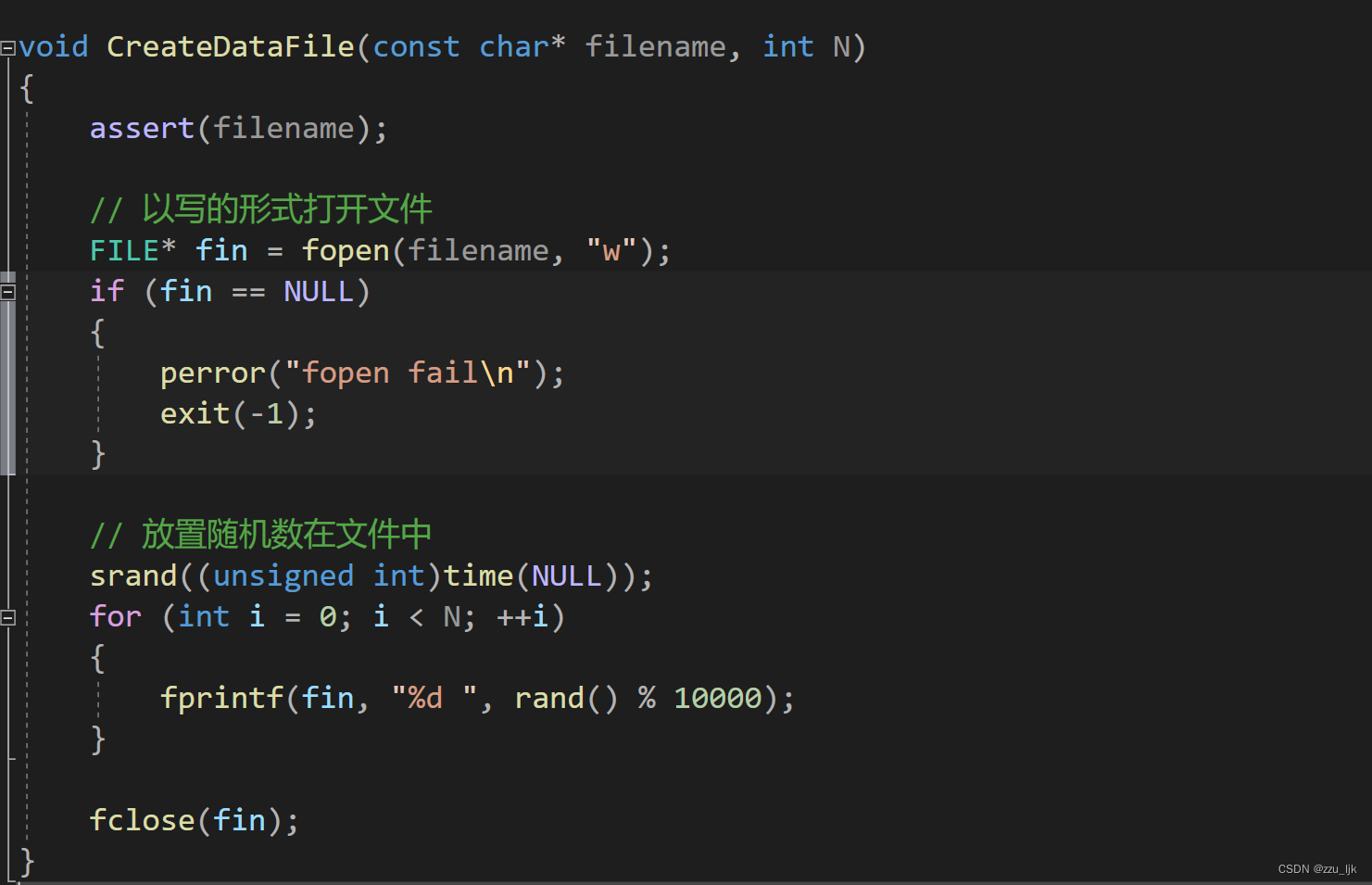
再随便放入几个比更大的数在文件中这样做的目的是验证我们最终选出的数是否是最大的数。