

Hive任务实施(航空公司客户价值数据)
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
实训目的
- 了解Hive 数据预处理与分析
- 熟悉Hive 的查询语句
- 掌握tez 和Spark 引擎的使用方法
- 具有使用Hive知识完成航空公司客户价值数据预处理与分析的能力。
1.任务描述
飞机被认为是迄今为止最安全、高效的交通工具。如何在给顾客提供优质服务的同时保障利益最大化这个间题时刻困扰着航空公司。为了解决这一问题 可以
-
使用Hive 对客户进行分群如重要保持客户、重要发展客户、重要挽留客户、一般客户和低价值客户
-
再针对不同的客户群体制定相应的优惠政策来实现利益最大化。
-
本任务通过对Hive数据分析知识的学习 最终实现基于Hive 的航空公司客户价值数据预处理与分析。
2.功能描述
- 加裁数据
- 数据统计清洗
- 建立 LRFMC模型。
3.任务背景
精准化运营的基础是客户关系管理与维护客户关系管理的核心是客户分类对不同的客户群体开展不同的个性化服务将有限的资源合理地分配给不同价值的客户从而实现效益最大化。
本教程使用的数据集包含 68 828 条数据有44个字段。主要字段如下表所示
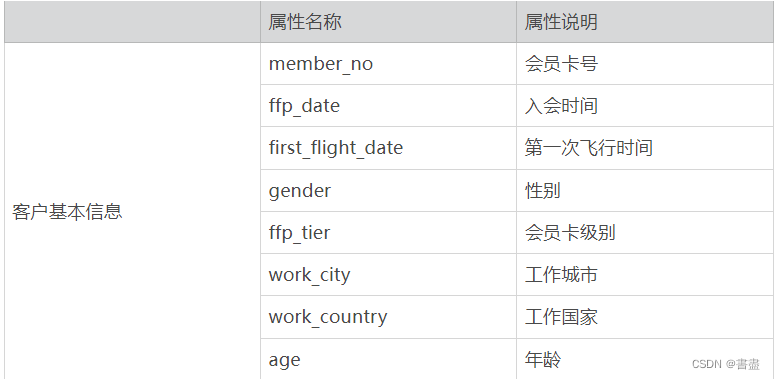
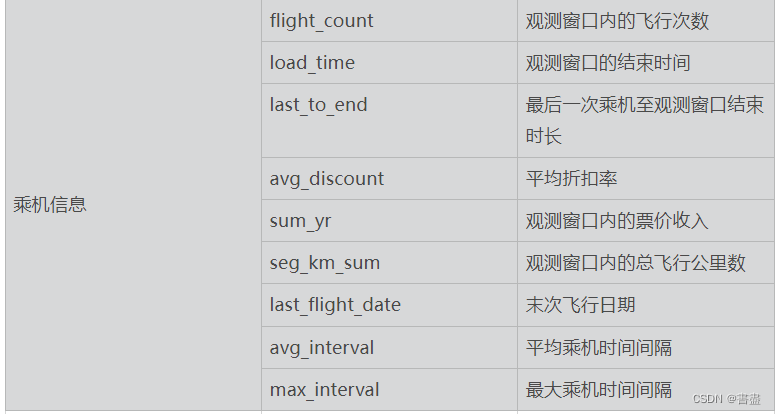
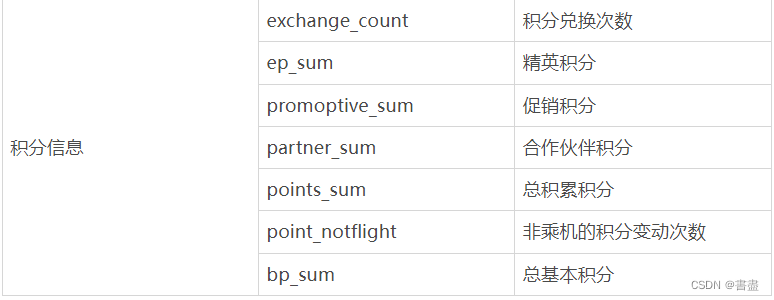
实训内容
1.创建数据库和数据表
- 在Hive中创建名为air_data的数据库并在数据库中创建名为air_table的表
create database air_data;
use air_data;
create table air_table(
member_no string,
ffp_date string,
first_flight_date string,
gender string,
ffp_tier int,
work_city string,
work_province string,
work_country string,
age int,
load_time string,
flight_count int,
bp_sum bigint,
ep_sum_yr_1 int,
ep_sum_yr_2 bigint,
sum_yr_1 bigint,
sum_yr_2 bigint,
seg_km_sum bigint,
weighted_seg_km double,
last_flight_date string,
avg_flight_count double,
avg_bp_sum double,
begin_to_first int,
last_to_end int,
avg_interval float,
max_interval int,
add_points_sum_yr_1 bigint,
add_points_sum_yr_2 bigint,
exchange_count int,
avg_discount float,
p1y_flight_count int,
l1y_flight_count int,
p1y_bp_sum bigint,
1y_bp_sum bigint,
ep_sum bigint,
add_point_sum bigint,
eli_add_point_sum bigint,
l1y_eli_add_points bigint,
points_sum bigint,
l1y_points_sum float,
ration_l1y_flight_count float,
ration_p1y_flight_count float,
ration_p1y_bps float,
ration_l1y_bps float,
point_notflight int )
row format delimited fields terminated by ',';
2.导入数据
- 文件中导入air_table表中并查看是否导入成功命令如下。
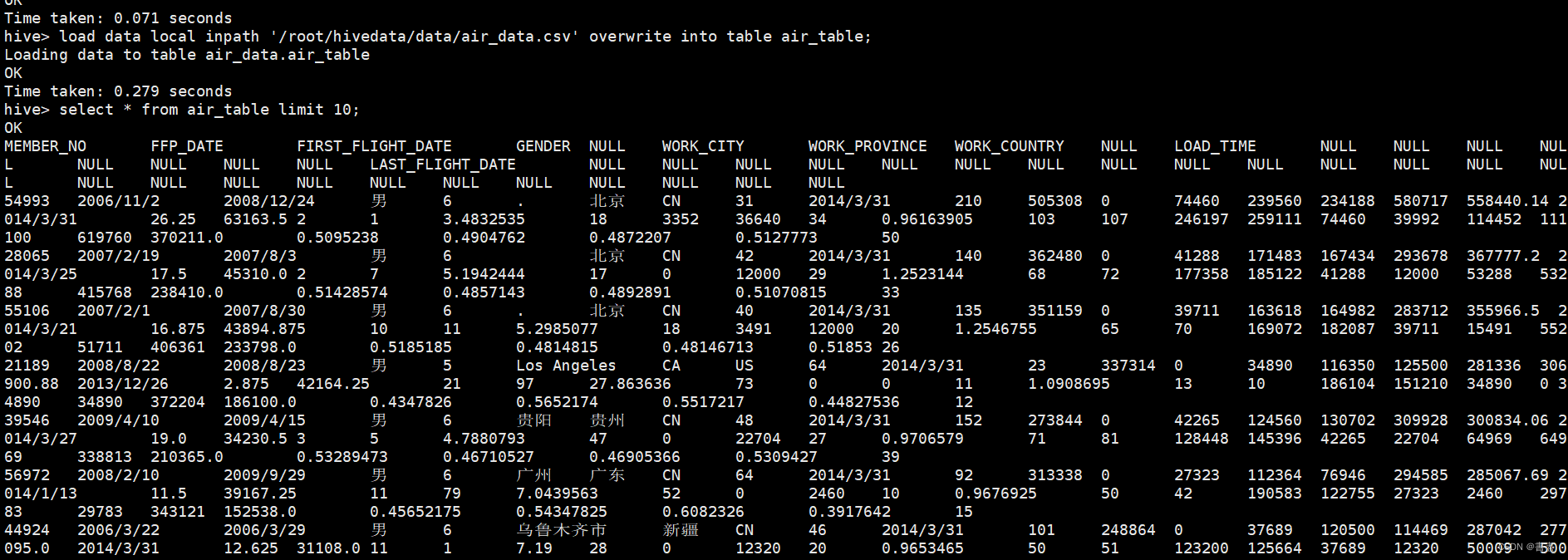
load data local inpath '/root/hivedata/data/air_data.csv' overwrite into table air_table;
select * from air_table limit 10;
3. 统计空记录
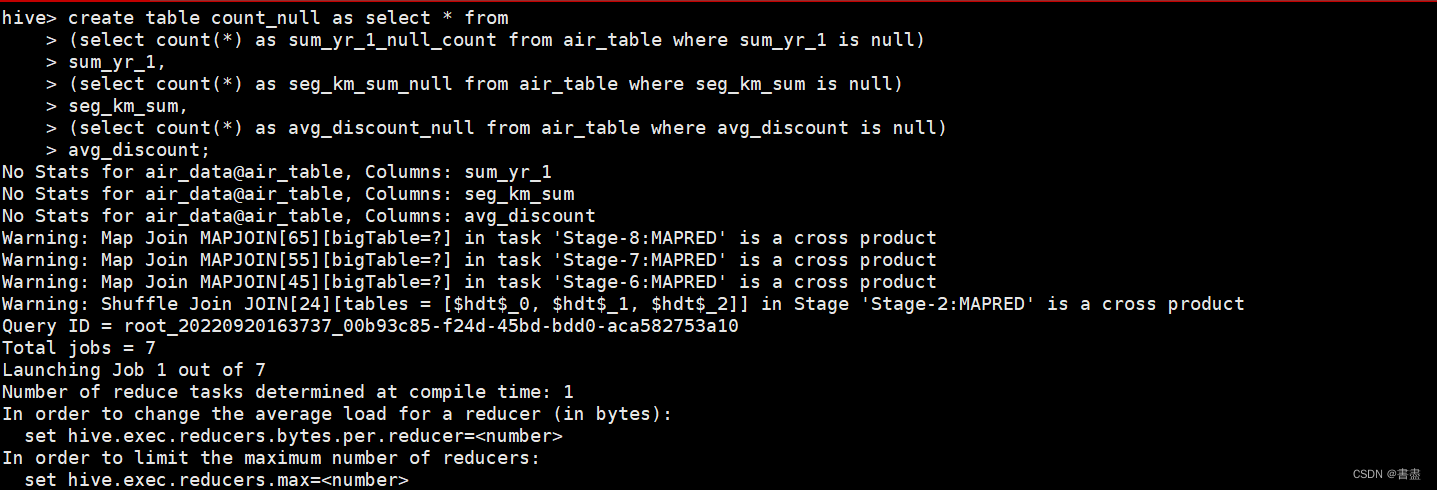
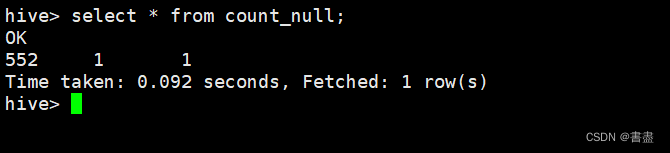
统计观测窗口内的票价收入(sum_yr_l)、观测窗口内的总飞行公里数seg_km_sum)和平均折扣率avg_discount三个字段的空记录并将结果保存到名为count_null的表中命令如下。
create table count_null as select * from
(select count(*) as sum_yr_1_null_count from air_table where sum_yr_1 is null)
sum_yr_1,
(select count(*) as seg_km_sum_null from air_table where seg_km_sum is null)
seg_km_sum,
(select count(*) as avg_discount_null from air_table where avg_discount is null)
avg_discount;
select * from count_null;
4. 统计最小值
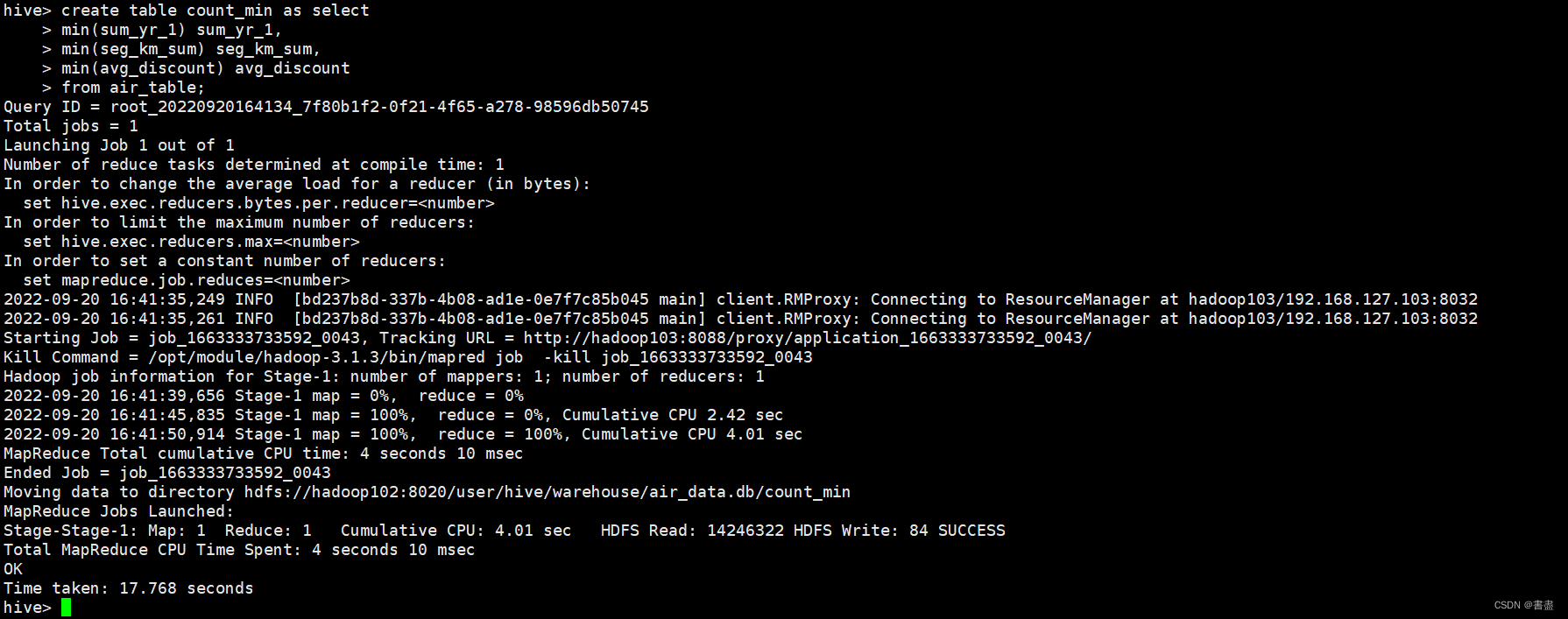
统计出观测窗口内的票价收入sum_yr_l)、观测窗口内的总飞行公里数seg_km_sum)和平均折扣率(avg_discount)三个字段的最小值并保存到count_min表中命令如下。
create table count_min as select
min(sum_yr_1) sum_yr_1,
min(seg_km_sum) seg_km_sum,
min(avg_discount) avg_discount
from air_table;
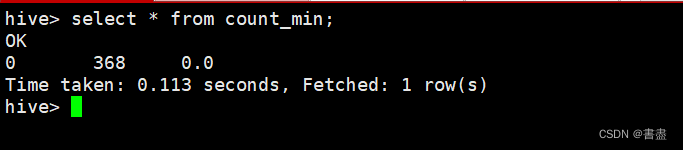
select * from count_min;
5. 数据清洗
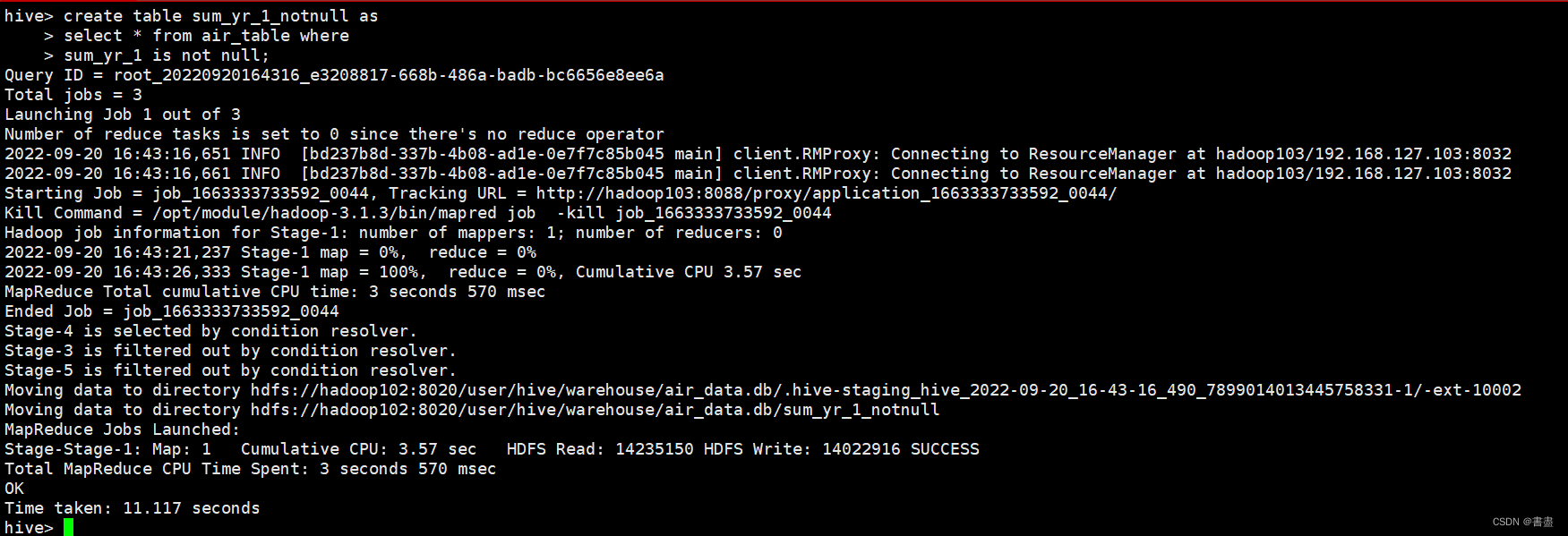
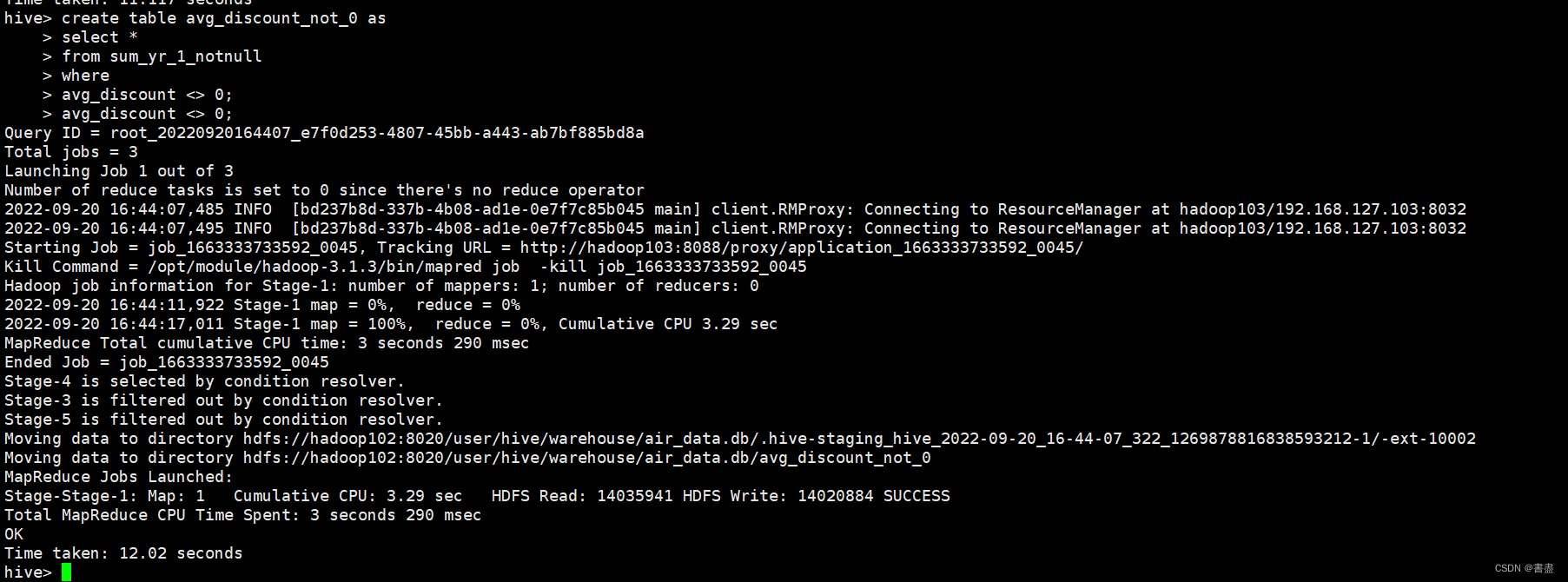
通过对数据的分析可以发现数据中存在缺失值但缺失值占总体数据的比例较小所以直接将缺失值过滤掉分别过滤掉票价为空的记录平均折扣率为0 的记录票价为0、平均折扣率不为0、总飞行公里数大于0 的记录。
create table sum_yr_1_notnull as
select * from air_table where
sum_yr_1 is not null;
create table avg_discount_not_0 as
select *
from sum_yr_1_notnull
where
avg_discount <> 0;
create table sas_not_0 as
select * from avg_discount_not_0
where !(sum_yr_1=0 and avg_discount <> 0
and seg_km_sum > 0);
6. 属性筛选
为了建立LRFMC模型从清洗后的数据中集中选择与指标相关的六个属性ffp_date、load_time、flight_count、seg_km_sum、 avg_discount、 last_to_end
create table flfasl as
select
ffp_date,
load_time,
flight_count,
avg_discount,
seg_km_sum,
last_to_end
from sas_not_0;
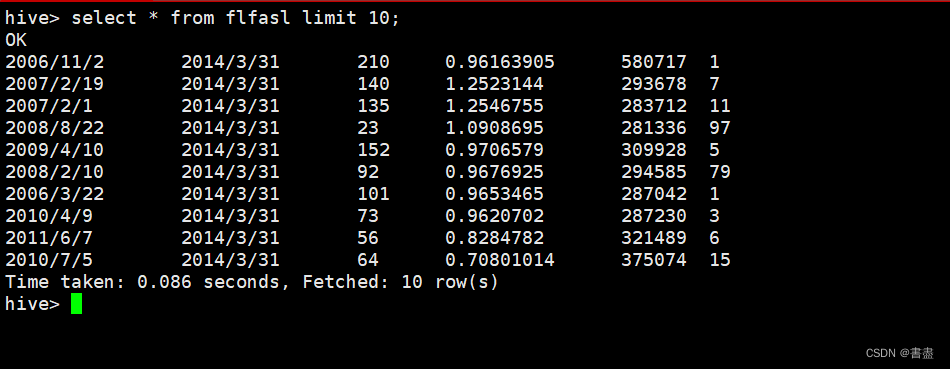
select * from flfasl limit 10;
7. 数据转换
将数据转换为适当的格式使其能够满足挖掘任务和算法的需要构造LRFMC的五个指标
- L的构造
会员入会距离观测窗口结束的月数=观测窗口的结束时间-入会时间 【单位月】L = load_time-ffp_date
- R 的构造
会员最近一次乘坐飞机的时间距离观测窗口结束的月数=最后一次乘机至观测窗口结束时长
R=last_to_end
- F的构造
会员在观测窗口内乘坐飞机的次数=观测窗口内的飞行次数【单位次】
F = flight_count
- M 的构造
会员在观测窗口内累积的飞行距离里程=观测窗口内的总飞行公里数【单位公里】
M=seg_km_sum
- C的构造
会员在观测窗口内乘坐的舱位所对应的折扣系数的平均值=平均折扣率【单位无】
C = avg_discount
根据以上公式对规约后的数据进行计算得到LRFMC
create table lrfmc as select
round((unix_timestamp(LOAD_TIME,'yyyy/MM/dd')-unix_timestamp(FFP_DATE,'yyyy/MM/dd'))/(30*24*60*60),2) as l,
round(last_to_end/30,2) as r,
FLIGHT_COUNT as f,
SEG_KM_SUM as m,
round(AVG_DISCOUNT,2) as c
from flfasl;
8. 标准化
对数据进行标准化操作公式为 标准化值=x-min(x))/(max(x)-min(x)) 将标准化后的数据保存到名为 standardlrfmc的表中
create table standardlrfmc as
select (lrfmc.l-minlrfmc.l)/(maxlrfmc.l-minlrfmc.l) as l,
(lrfmc.r-minlrfmc.r)/(maxlrfmc.r-minlrfmc.r) as r,
(lrfmc.f-minlrfmc.f)/(maxlrfmc.f-minlrfmc.f) as f,
(lrfmc.m-minlrfmc.m)/(maxlrfmc.m-minlrfmc.m) as m,
(lrfmc.c-minlrfmc.c)/(maxlrfmc.c-minlrfmc.c) as c
from lrfmc,
(select max(l) as l,
max(r) as r,
max(f) as f,
max(m) as m,
max(c) as c from lrfmc) as maxlrfmc,
(select min(l) as l,
min(r) as r,
min(f) as f,
min(m) as m,
min(c) as c from lrfmc) as minlrfmc;
- 导出数据
将标准化后的数据导出到本地的standardlrfmc.csv中并使用逗号作为分隔符
hive -e "insert overwrite local directory '/root/hivedata/data/standardlrfmc' row format delimited fields terminated by ',' select * from air_data.standardlrfmc;"
- 保存成功
- 客户分类
- 根据业务模型将客户大致分为五类通过k=5以及标准化后的数据利用Kmeans模型计算出这五类客户群体的聚类中心。
- 由于虚拟机环境下python库文件安装不完整可以先把虚拟机中的standardlrfmc.csv文件下载到宿主机的桌面上然后在宿主机系统中ananconda包含的Spyder中完成编译。
- 使用任意python编辑器编写如下代码然后运行。注意数据文件standardlrfmc.csv的保存路径
import pandas as pd
from sklearn.cluster import KMeans
dt=pd.read_csv("standardlrfmc.csv",encoding='UTF-8')
dt.columns=['L','R','F','M','C']
model=KMeans(n_clusters=5)
model.fit(dt)
r1=pd.Series(model.labels_).value_counts()
r2=pd.DataFrame(model.cluster_centers_)
r=pd.concat([r2,r1],axis=1)
r.columns=list(dt.columns)+['Clustercategory']
print(r)
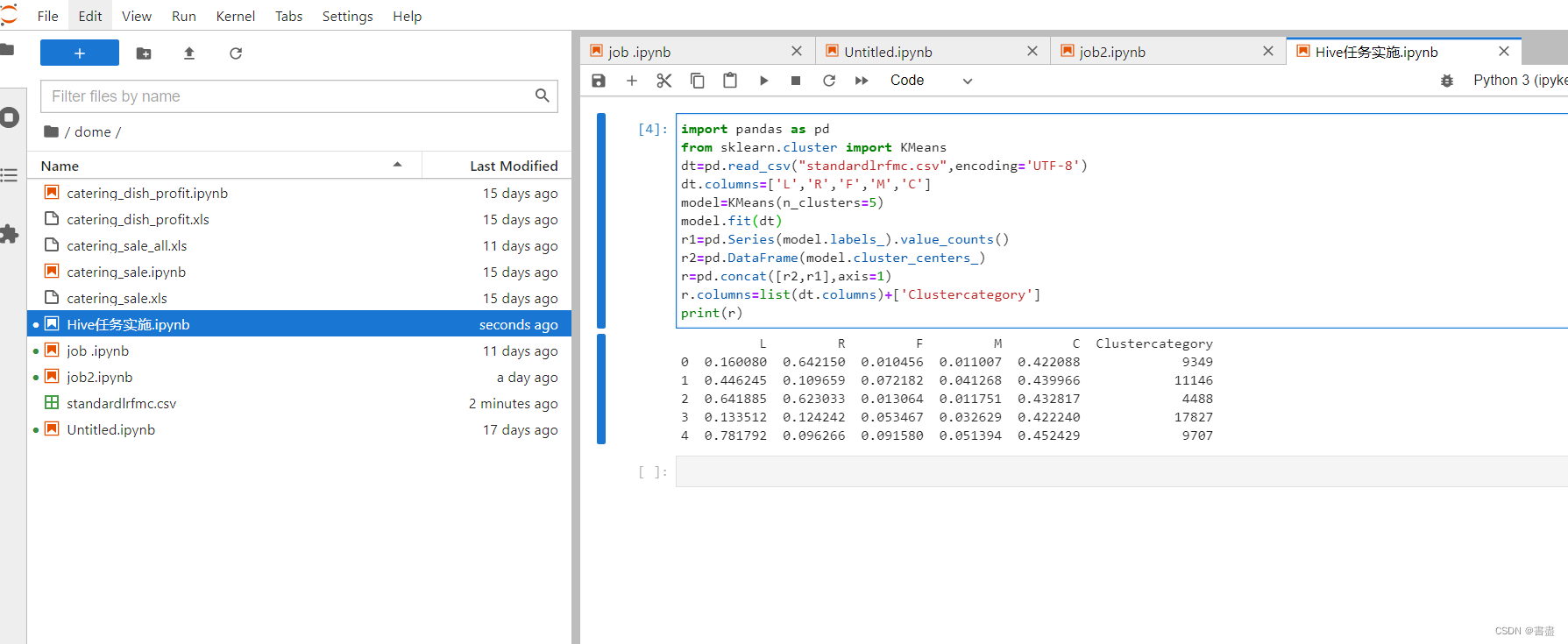
- 根据聚类中心结果再结合航空公司的业务逻辑可得到如下结果
- 客户群体1 C属性最大可定义为重要挽留客户
- 客户群体2 L属性最大可定义为重要发展客户
- 客户群体3 F、M属性较小可定义为低价值客户
- 客户群体4 L、C属性较大可定义为一般客户
- 客户群体5 F、M属性最小可定义为低价值客户
实训总结
注意
命令的使用与输入
文件路径的引用
建表字段的顺序
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |