

【微服务】mysql + elasticsearch数据双写设计与实现-CSDN博客
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
目录
一、前言
在很多电商网站中对商品的搜索要求很高主要体现在页面快速响应搜索结果。这就对服务端接口响应速度提出了很高的要求。而商品数据存储离不开mysql在高并发场景下尤其是数据规模达到一定量级mysql的性能瓶颈一定会出现为了满足极致的搜索速度往往需要借助第三方存储比如nosql数据库当然主流的搭配还是使用搜索引擎来完成于是在很多场景下会选择mysql+elasticsearch来满足这个场景下对搜索的要求。

如下是一个典型的使用mysql+es实现数据双写的应用场景。
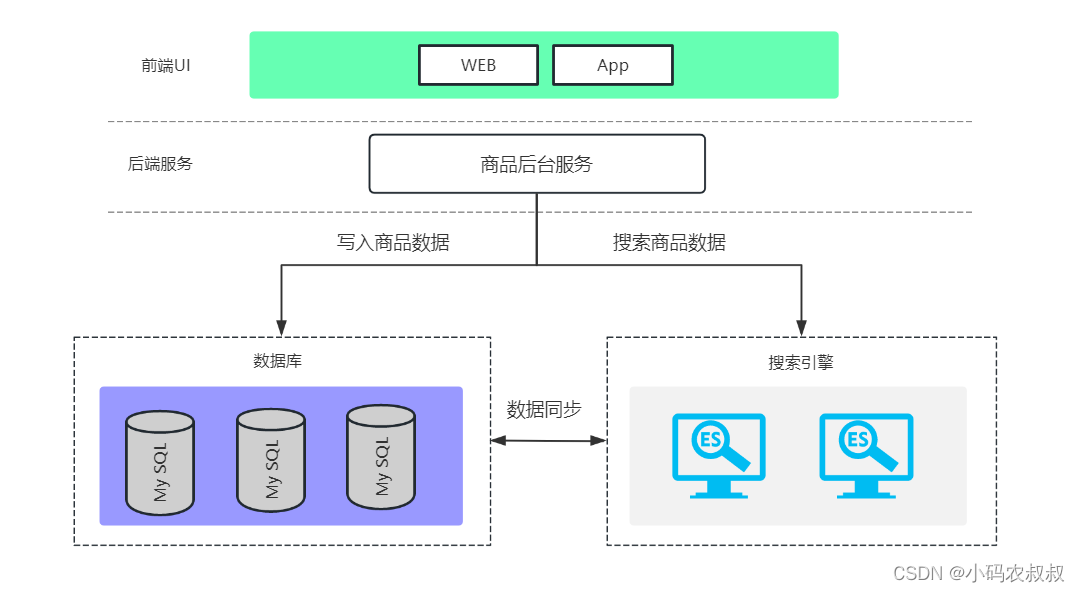
二、为什么使用mysql+es双写
2.1 单用mysql的问题
在很多互联网项目中mysql数据库仍然是主流毕竟关系型数据库可以处理现实场景中很多复杂的业务模型但是mysql随着数据规模的增长一旦单表数据量达到了千万级性能将下降的很快于是不得不进行数据库的扩展这样也带来了架构上的复杂性综合来说在类似某宝某东等这样的电商场景下单表存储数据带来的问题主要如下
-
单表数据承载有限当数据规模超过千万就要考虑分库或分表从而给数据库架构设计提出新的挑战
-
mysql不适合全文检索经管mysql从某个版本支持了全文检索但是在实际使用中性能很弱
-
mysql的模糊匹配无法满足多场景下的复杂的搜索要求比如电商场景下多维度任意组合搜索是很常用得而复杂的搜索将会使得mysql性能急剧下降
2.2 为什么不直接使用es
到这里也会有人提出疑问既然es搜索速度如此高效并且也可以存储数据直接使用es存储mysql表中的数据不就行了。对于这个问题主要从下面几点进行考虑
2.2.1 非关系型表达
使用mysql进行数据库设计的一个好处就是不同的表之间可以通过某个字段进行关联关联关系的存在让现实中复杂的业务模型通过表关联进行实现而es则不支持不同索引之间的关联搜索。
2.2.2 不支持事务
mysql事务的存在让数的写入完整性得到保障而es是不支持事务的这就导致在往es写数据时数据的一致性需要通过其他的手段来保障。
2.2.3 多字段将造成性能低下
上面谈到由于es不支持关联查询实际业务中一个页面展现的数据往往来自多张表的关联聚合查询结果es为了达到与mysql同样的效果只好尽可能在一个索引中冗余更多的字段从es存储的角度来说es是基于字段的大行超多字段将会大大降低性能同时也会导致后续数据的维护困难和复杂性。
三、mysql+es双写方案设计要点
在很多开发者看来使用mysql+es双写的方案就是把某个高频搜索的表的数据存储一份到es就可以了这么理解倒也不错不过还缺少很多深入的考虑。在正式开始设计方案之前需要重点考虑下面几点这也将是本文后续探讨的重点以及在实际开发中需要关注的。
3.1 全新设计 VS 中途调整架构
这是一个很现实的摆在很多架构设计者面前的问题为什么这么说呢在很多企业的项目中经历了从单体架构到微服务的改造从简单的http调用webservice调用到使用dubbo等服务治理的技术改造。
如果现在的你正在经历一个全新的项目那么恭喜你你可以拥有更多的技术选型空间但是如果你正则经历项目的服务化改造这个过程可能比较痛苦不仅要考虑引入新技术的成本更要考虑新技术的实现会给未来技术的演进带来何种影响包括团队学习、维护成本上线后的运维成本与其他技术的融合成本等。
回到上面的问题在使用mysql+es双写方案来说同样会面临相同的难题如果是全新的设计主要考虑的是如何实现mysql与es双写数据的一致性及如何基于团队成员现有的技术、业务上对双写数据实时性等方面评估出以最低成本的实现方案即可。
而如果是中途更换设计方案比如线上的数据规模已经达到千万量级顶不住客户的压力到了不得不调整架构的阶段来考虑这个问题这个过程将会拉得很长。此时你考虑的点会更多了包括
-
如何设计es索引
-
如何基于现有的代码实现数据双写并且尽可能降低对现有逻辑的侵入性
-
如何保障双写数据的一致性
-
针对历史数据如何迁移
-
如何减少生产上线后的实施成本和运维成本
-
...
3.2 全表映射 VS 关键字段存储
使用过mysql的同学应该不陌生mysql是行式存储数据而es中数据则以准json的结构存储两者之间经管能够通过字段进行对应但在检索的时候原理是不一样的如下图所示。

在实际使用mysql+es进行双写方案设计时很多人直接就认为将mysql的表字段进行一份全量的拷贝到es的索引中即可这样从实现上固然没有差别最终也能达到效果但这样做真的合理吗在进行方案设计的时候从实际经验来说功能的实现固然重要但如何做到既能满足功能又能让设计显得合理才是更需要深入思考的。就这个问题来说如何才算合理呢可以从下面几点展开思考。
3.2.1 最大程度发挥es性能
不管是mysql还是es不管是hbase还是clickhouse...所有的数据存储介质都有自己的优势和不足因此在选择某种存储引擎时一定是利用其优势同时规避其不足。就es来说选择它的原因就是因为在海量的数据且复杂的检索场景下仍然能够保持高性能。
在上文也谈到单纯使用es带来的不足其中值得注意的一点就是es是基于字段存储的对一行数据来说字段数量越多当一个待检索的请求发来时其计算耗费的成本必然越高这不仅是针对es甚至mysql等很多关系型数据库对于单表过多字段的冗余设计也不推荐所以对es来说也不建议存储mysql表的所有字段而是关键的具有重要业务意义的字段数据。
3.2.2 选择mysql还是es作为数据托底
这是一个架构设计中容易被忽略的问题。文章开始谈到一个基本的业务场景是主业务数据写入到mysql同时将数据同步写入es检索从es获取数据。那么问题来了实际业务中究竟以哪个数据为准呢我们以下面一个简单的同步写入场景的业务逻辑为例来说明相信就能理解了。
@Transactional
public boolean save(){
//数据组装
try{
//写入mysql
//写入es
}catch(Exception e){
//es数据回滚
}
}这是一段同步双写的伪代码从这段代码不难看出mysql的写入由事务机制保障但是es的数据写入与回滚就比较麻烦了而且这样的实现对业务逻辑的侵入性强维护性差但可以发现我们首要保障的是mysql数据的完整性因为只有数据成功写入界面上展示的数据才是正确的。
从这个分析结合实际的业务实现以一个电商或类似的场景从产品列表到具体的详情页面为例进行说明参考下面的流程
-
用户浏览列表页
-
用户从列表页通过关键字搜索目标数据
-
从搜到的结果中选择某个具体的产品
-
进入具体产品的页展示与当前产品完整的数据

从上面的业务流程分析不难看出实际要展示某个产品字段数据是非常多的以某大型电商网站上面展现的某个产品为例展现在用户面前的商品包括了非常多的数据这些数据是多个源表经过服务端聚合以后再经过复杂的处理得到的所以如果将这么多的字段放在es的某个索引中这明显是不合适的总结来说两者搭配使用时可以遵循下面的思路
-
es存放核心业务表的核心字段比如产品ID产品的详情描述SKU等信息
-
列表搜索走es索引通过es的检索返回业务主键等关键信息
-
将第二步es得到的数据给到mysql的业务表返回最终的数据给到页面
从上面的分析来看在实际业务中应该酌情考虑是否应该将核心业务表的全量数据存于es一般建议业务表的核心字段比如业务主键 + 高频搜索的字段存放es中
3.3 数据一致性保障
使用双写方案在实际操作中基于双写方案如何保障mysql与es的数据一致性是设计与开发过程中需要重点关注的。
我们知道mysql有事务机制保障数据的一致性而es没有事务在上文的伪代码中仅仅是使用了一种非常简单的逻辑来保障这样是远远不够的。一旦发生了mysql与es数据的不一致带来的问题是很严重的。关于如何保障数据的一致性结合实际操作经验给出下面的几点建议
3.3.1 同步双写
同步双写是保障数据一致性最简单的方式也是实际操作中比较简单的操作方式只需要将数据写到 MySQL 时同时将数据写到 ES即可通过mysql自身的事务机制间接保障两者数据一致性其优缺点如下。

优点
-
这种方式简单粗暴实时写入能做到秒级。
缺点
-
业务耦合代码侵入性强即在代码中需要写入mysql表的位置都需要加写入es的代码
-
性能影响同步写入两个存储响应时间变长
-
可能存在丢数据的风险
3.3.2 异步双写
异步双写即在数据写入mysql的同时异步写入到es中具体在实践过程中也有多种方式可以选择下面提供几种方案。
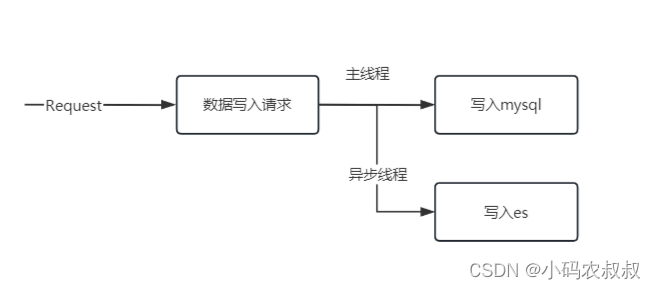
异步线程
利用异步线程的方式写入mysql的时候开启多线程写入es
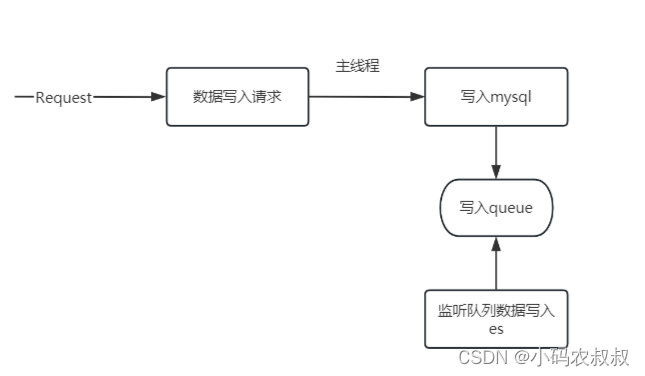
内存队列
可以利用Java中提供的内存队列写入mysql的同时向内存队列比如BlockingQueue另有一个线程消费内存队列中的数据写入es
事件监听
主业务流程写入mysql的同时发布事件另有一个事件订阅者订阅mysql写入事件从而做到与主业务逻辑的解耦。
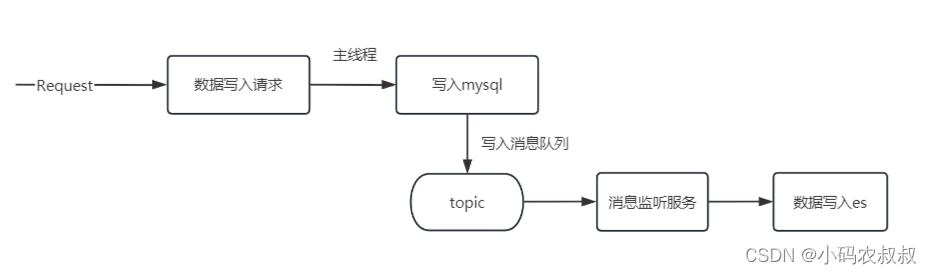
引入消息中间件
也可以考虑引入消息中间件做到与主业务逻辑的彻底解耦写入mysql的同时向消息队列发送消息另有服务消费者订阅消息消费异步写入es
上述各种方式均可以在实践中使用需要结合团队的技术储备以及服务器资源后续的运维成本等综合考虑。
3.3.3 定期同步
定期同步适合对搜索场景不那么敏感的业务在这种场景下可以考虑每隔一段时间或每天的某些时间点进行同步将数据批量从mysql写入到es中。定期同步的优缺点如下。
优点
-
实现简单系统资源占用少
缺点
-
实时性难以保证
-
瞬时存储压力较大
3.3.4 数据订阅
既要提高实时性又要低入侵, 可以考虑利用 MySQL 的 Binlog 来进行同步。在很多数据同步工具中都采用了类似的思想简单来说订阅mysql的binglog日志然后通过回放binlog日志变化解析出变化的数据从而进行数据同步。比如大家熟悉的canal就是很好的利用了这一点。
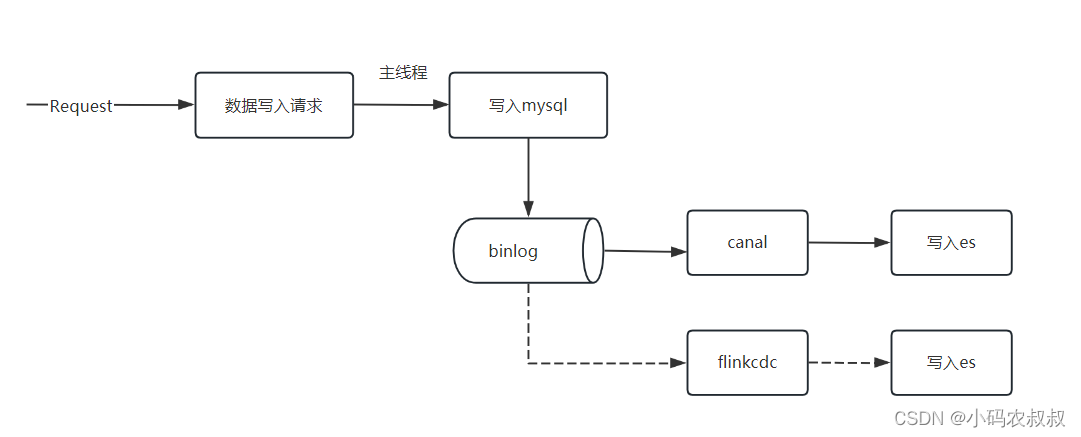
这种方式可以很好的与核心业务解耦从而实现异步总结来说优点如下
-
降低对主业务逻辑的代码侵入性
-
数据的实时性好
缺点
-
对第三方组件存在一定的依赖性
-
同步很难做到灵活性很难对同步的数据做进一步的处理比如同步时那些明显有问题的数据
四、mysql+es双写方案数据迁移
对于一个全新的系统结合上面考虑的要点设计出一个相对完善的方案并落地实施不算难事但是据个人经验比较难的是中途引入es来补充和完善mysql的搜索能力上的短板。为什么这么说呢
试想你的生产系统已经运行了很久了mysql核心业务表也产生了相当量级的数据了。引入es之后即便是双写es中的存储的数据也是从某个时间点开始搜索出来的数据也只有那个时间点之后的。那么之前的数据怎么办呢肯定不能扔掉的。这时候就需考虑如何将之前mysql中老数据无损的迁入到es索引中。
这时候可能有人说这也不是什么难事吧找个业务不繁忙的时间段将mysql中的老数据一次性迁移到es不就解决问题了吗?如果真是这么简单就不会有那么多的麻烦事了下面结合实践经验从迁移的方案和迁移注意事项两方面进行说明。
4.1 数据迁移整体方案
以一个对数据搜索场景不是那么敏感的场景为例进行说明。整体业务流程如下
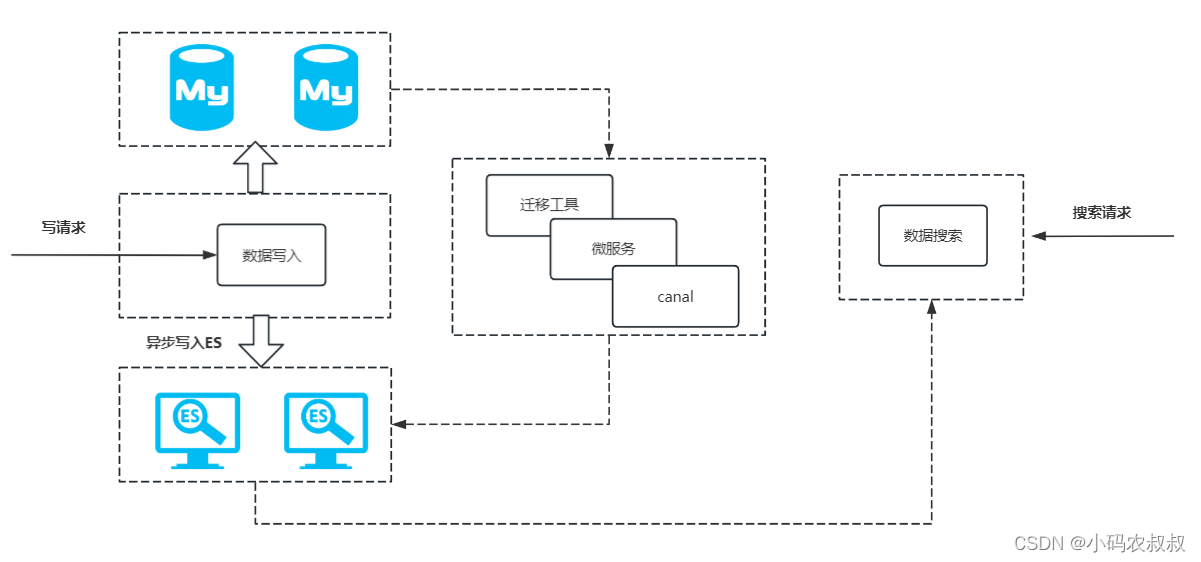
结合上面的流程完整的数据迁移思路如下
-
创建索引
-
双写方案V1版生产上线不包括es搜索业务数据实现mysql+es双写考虑使用消息中间件记录时间点为T1
-
在完成数据迁移之前搜索业务逻辑仍然走mysql此时es索引中存储的是T1时间点开始之后的mysql数据
-
业务低峰期利用数据同步工具或FlinkCDC等方案第一次完成全量迁移针对T1之前的
-
双写方案V2版生产上线数据搜索走es
4.1.1 创建索引
建议自定义创建索引控制索引中的字段信息结合上面谈到的要点es索引存储的字段信息为mysql核心业务表中的核心业务字段比如业务主键用于搜索的高频字段信息。
4.1.2 双写改造
稳妥起见在第一个改造发布的版本中代码逻辑层面先支持双写比如通过异步线程将数据写入es此时es索引中就存储了某个时间点T1之后的数据。
4.1.3 数据迁移
使用数据迁移工具或自己开发一个微服务在业务低峰期凌晨2点完成一次全量数据的迁移迁移完成后ES中的数据基本与mysql表数据同步了。
4.1.4 搜索服务上线
上线搜索服务此时数据的搜索将走es具体的实现逻辑结合自身的业务场景酌情改造。比如上文谈到的如果产品的详情页面是多个表的聚合结果首先需要通过搜索得到核心的业务字段信息然后代入到后面的逻辑中进行数据的组装。
4.2 数据迁移补充说明
以上结合实际场景给出了一个相对通用的数据迁移方案在实际操作中遇到的情况可能比这个更复杂比如你可能遇到下面的这些情况
-
你要迁移的数据表经过了分库分表即业务表的数据存储在多个库或多张表中这种情况下如何迁移
-
你要迁移的数据表数据量非常大而且可以预计每月的增长量为几百万如何保障保证es的存储容量如何规划es的后续扩容
-
迁移的数据量巨大需要很久怎么办
-
迁移数据量巨大迁移过程中发生异常怎么办
-
...
五、方案实施
下面通过实际代码演示一下完整的业务流程。
5.1 前置准备
5.1.1 搭建环境
这里假设你已经提前搭建好es、mysql的环境。
es的搭建可以参考文章es脚本编程使用mysql可以使用下面的docker命令快速开启mysql服务
docker run -p 3307:3306 --name mysql57 \
-v /usr/local/docker/mysql/data:/var/lib/mysql \
-v /usr/local/docker/mysql/conf:/etc/mysql/conf.d \
-v /usr/local/docker/mysql/log:/var/log/mysql \
-e MYSQL_ROOT_PASSWORD=你的root密码\
-d mysql:5.75.1.2 创建数据表
使用下面的sql语句创建一张数据表其中desc字段会被作为高频字段搜索使用
CREATE TABLE `product` (
`id` int(12) NOT NULL,
`pro_name` varchar(64) DEFAULT NULL,
`pro_no` varchar(32) DEFAULT NULL,
`price` int(10) DEFAULT NULL,
`category` varchar(32) DEFAULT NULL,
`stock` int(32) DEFAULT NULL,
`desc` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;5.1.3 插入初始化数据
为上述的表插入一些数据
INSERT INTO `pt_res`.`product`(`id`, `pro_name`, `pro_no`, `price`, `category`, `stock`, `desc`) VALUES (1, '小米14', 'A100', 3999, 'phone', 32, 'xiao mi phone');
INSERT INTO `pt_res`.`product`(`id`, `pro_name`, `pro_no`, `price`, `category`, `stock`, `desc`) VALUES (2, 'Java入门到精通', 'B100', 56, 'book', 12, 'Java technology');
INSERT INTO `pt_res`.`product`(`id`, `pro_name`, `pro_no`, `price`, `category`, `stock`, `desc`) VALUES (3, '精品男鞋', 'X100', 325, 'shoe', 82, 'Man shoe');

5.1.4 创建一个索引
创建一个名为product的索引并指定desc字段分词里面的字段与mysql表对应但不是所有字段
PUT product
{
"mappings": {
"properties": {
"id":{
"type": "long"
},
"pro_name": {
"type": "keyword"
},
"desc": {
"type": "text"
}
}
}
}测试创建一条数据
PUT /product/_doc/11
{
"pro_name":"汪汪队纪念品",
"desc":"for children play"
}查询这条数据
GET /product/_doc/11

到这里我们的准备工作就完成了接下来将在代码中完成剩下的操作。
5.2 搭建springboot工程
本工程要做的事情如下
- 整合mybatis与es
- 利用mybatis实现增删改查功能
- 利用异步线程写入es
- 实现mysql历史数据的迁移
5.2.1 引入基础依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.4</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.6.2</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.6.2</version>
</dependency>
<!--<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.6.2</version>
</dependency>-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>${boot-web.version}</version>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.15</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lomok.version}</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.83</version>
</dependency>
</dependencies>5.2.2 核心配置文件
主要配置mysqlmybatis以及es相关的连接信息
server:
port: 8082
spring:
datasource:
username: root
password: root
url: jdbc:mysql://IP:3307/pt_res?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=false
driver-class-name : com.mysql.jdbc.Driver
elasticsearch:
rest:
uris: [IP:9200]
host: IP
port: 9200
mybatis:
mapper-locations: classpath:mybatis/*.xml
type-aliases-package: com.congge.entity
5.2.3 es客户端连接配置
自定义一个类自定义一个RestHighLevelClient 的bean配置es连接信息
import lombok.extern.slf4j.Slf4j;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
@Slf4j
public class EsConfig {
@Value("${spring.elasticsearch.host}")
private String host;
@Value("${spring.elasticsearch.port}")
private int port;
@Bean(name = "restHighLevelClient")
public RestHighLevelClient restHighLevelClient() {
return new RestHighLevelClient(RestClient.builder(
new HttpHost(host, port, "http")
));
}
}5.2.3 mybatis文件
在resources目录下创建mybatis目录在里面编写与mysql操作的文件这里创建一个操作product表的xml文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.congge.dao.ProductDao">
<resultMap id="BaseResultMap" type="com.congge.entity.Product">
<id column="id" property="id" jdbcType="VARCHAR" />
<result column="pro_name" property="proName" jdbcType="VARCHAR" />
<result column="pro_no" property="proNo" jdbcType="VARCHAR" />
<result column="price" property="price" jdbcType="INTEGER" />
<result column="category" property="category" jdbcType="VARCHAR" />
<result column="stock" property="stock" jdbcType="INTEGER" />
<result column="desc" property="desc" jdbcType="VARCHAR" />
</resultMap>
<select id="getAll" resultMap="BaseResultMap">
select * from product
</select>
</mapper>
注意启动类上面添加dao包的扫描
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
@MapperScan("com.congge.dao")
public class SyncApp {
public static void main(String[] args) {
SpringApplication.run(SyncApp.class,args);
}
}5.2.4 业务实现类
@Service
public class ProductServiceImpl implements ProductService {
@Autowired
private ProductDao productDao;
@Override
public List<Product> getAll() {
return productDao.getAll();
}
}5.2.4 相关测试
框架整合完毕之后及时通过单元测试验证是否整合成功下面给出了一些关于mysql操作以及索引操作的单元测试用例
import com.alibaba.fastjson.JSONObject;
import com.congge.SyncApp;
import com.congge.entity.Product;
import com.congge.entity.es.ProductInfo;
import com.congge.service.ProductService;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.IndicesClient;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.client.indices.GetIndexResponse;
import org.elasticsearch.cluster.metadata.MappingMetaData;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.List;
import java.util.Map;
//@RunWith(SpringRunner.class)
@SpringBootTest(classes = {SyncApp.class})
public class EsTest {
@Autowired
private RestHighLevelClient restHighLevelClient;
@Autowired
private ProductService productService;
@Test
public void testFindAll(){
List<Product> all = productService.getAll();
System.out.println(all);
}
@org.junit.jupiter.api.Test
void contextLoads() {
System.out.println(restHighLevelClient);
}
/**
* 判断索引是否存在
*/
@Test
public void getIndex() throws Exception {
IndicesClient indices = restHighLevelClient.indices();
GetIndexRequest student0517 = new GetIndexRequest("product");
boolean exists = indices.exists(student0517, RequestOptions.DEFAULT);
if(exists){
GetIndexResponse indexResponse = indices.get(student0517, RequestOptions.DEFAULT);
Map<String, MappingMetaData> mappings = indexResponse.getMappings();
System.out.println(mappings);
}else{
System.out.println("索引不存在");
}
}
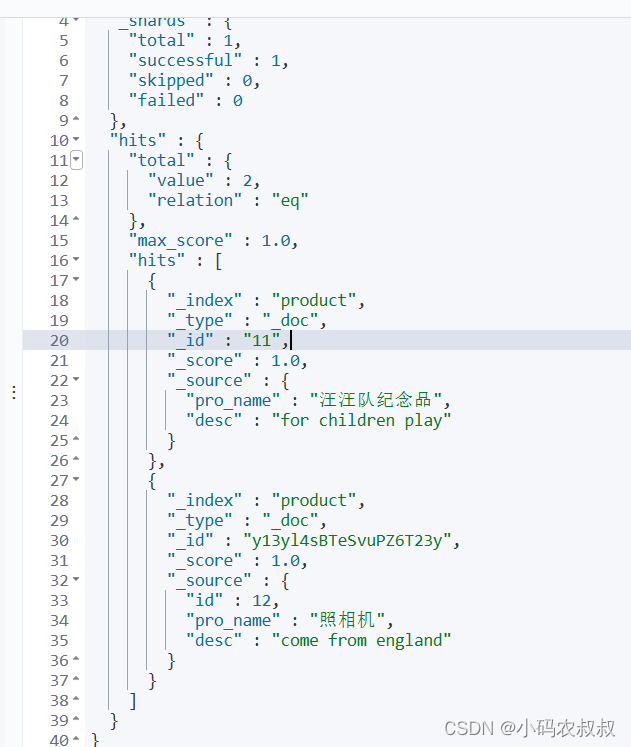
@Test
public void getDocById() throws Exception {
GetRequest getRequest = new GetRequest("product").id("11");
GetResponse documentFields = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);
//集合方式
Map<String, Object> source = documentFields.getSource();
for (String key : source.keySet()) {
System.out.println(source.get(key));
}
//字符串 -----JSON
String sourceAsString = documentFields.getSourceAsString();
System.out.println(sourceAsString);
//把JSON转换为 stuent
//JSON字符串-->JSON对象
JSONObject jsonObject = JSONObject.parseObject(sourceAsString);
System.out.println(jsonObject);
}
@Test
public void getDocByIdV2() throws Exception {
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices("product");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchRequest.source(searchSourceBuilder.query(QueryBuilders.termQuery("_id", 11)));
searchSourceBuilder.size(1);
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = search.getHits();
for (SearchHit searchHit : searchHits) {
Map<String, Object> sourceMap = searchHit.getSourceAsMap();
System.out.println(sourceMap);
}
}
@Test
public void insertDoc() throws Exception {
com.fasterxml.jackson.databind.ObjectMapper objectMapper = new com.fasterxml.jackson.databind.ObjectMapper();
IndexRequest indexRequest = new IndexRequest("product");
ProductInfo pro = new ProductInfo();
pro.setId(13);
pro.setPro_name("MP3");
pro.setDesc("music player");
String proData = objectMapper.writeValueAsString(user);
indexRequest.source(proData,XContentType.JSON);
//插入数据
IndexResponse response = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
System.out.println(response.status());
System.out.println(response.getResult());
}
}
5.3 双写业务实现
按照上文的业务实现流程向mysql表插入一条数据同时写入一条数据到es
@Override
@Transactional
public Object save(Product product) {
productDao.save(product);
saveEs(product)
//CompletableFuture.runAsync(() -> saveEs(product), newCachedThreadPool());
return product.getId();
}
public void saveEs(Product product){
com.fasterxml.jackson.databind.ObjectMapper objectMapper = new com.fasterxml.jackson.databind.ObjectMapper();
IndexRequest indexRequest = new IndexRequest("product");
ProductInfo pro = new ProductInfo();
pro.setId(product.getId());
pro.setPro_name(product.getProName());
pro.setDesc(product.getDesc());
String productData = null;
try {
productData = objectMapper.writeValueAsString(pro);
} catch (JsonProcessingException e) {
e.printStackTrace();
}
indexRequest.source(productData,XContentType.JSON);
//插入数据
IndexResponse response = null;
try {
response = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
log.error("save to es error,error : 【{}】",e.getMessage());
e.printStackTrace();
}
System.out.println(response.status());
System.out.println(response.getResult());
}
/**
* 带有缓存功能线程池
*
* @return
*/
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}使用单元测试测试一下方法
@Test
public void testSave(){
Product product = new Product();
product.setId(6);
product.setProName("可比克薯片");
product.setProNo("F003");
product.setPrice(7);
product.setCategory("food");
product.setStock(33);
product.setDesc("classics food");
Object save = productService.save(product);
System.out.println(save);
}
跑通之后检查mysql与es的数据是否正常写入
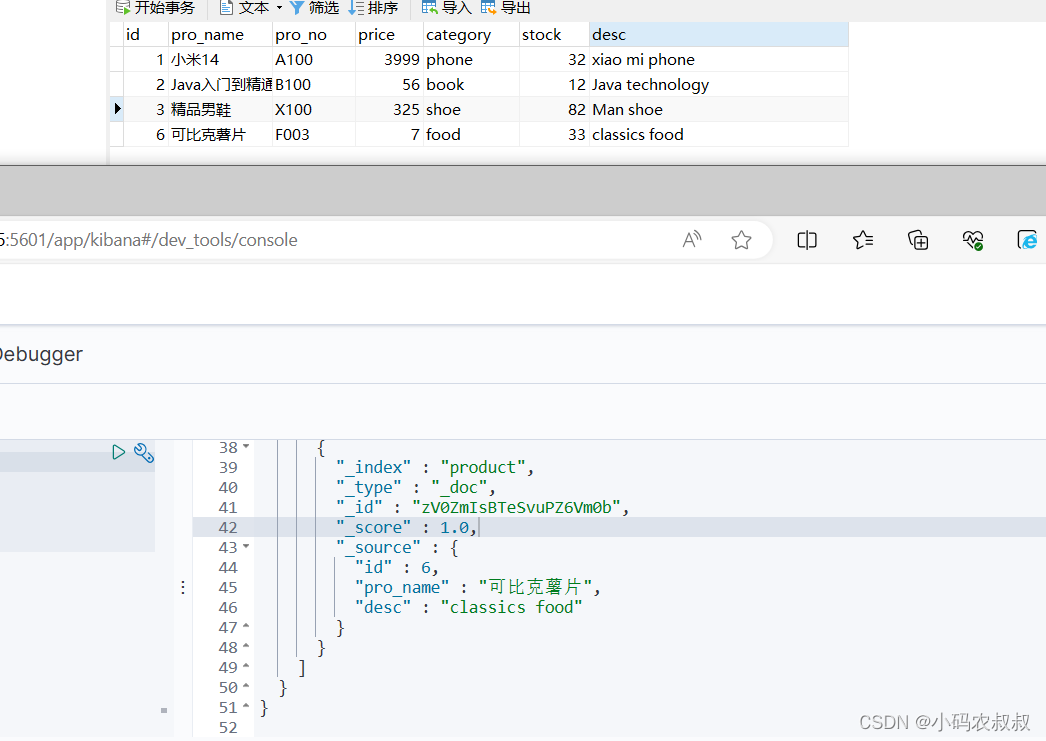
5.4 数据搜索
我们假设用户输入关键字进行搜索首先通过es的检索得到表的基本关键字段比如id然后去mysql中查询完整的信息核心业务实现逻辑如下。
@Override
public List<Product> query(String key) {
List<Integer> result = queryFromEs(key);
List<Product> queryRes = null;
if(!CollectionUtils.isEmpty(result)){
queryRes = productDao.getProductIn(result);
}
return queryRes;
}
private List<Integer> queryFromEs(String key) {
SearchRequest request = new SearchRequest();
request.indices("product");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
FuzzyQueryBuilder fuzzyQueryBuilder =
QueryBuilders.fuzzyQuery("desc", key)
.fuzziness(Fuzziness.ONE);
sourceBuilder.query(fuzzyQueryBuilder);
request.source(sourceBuilder);
SearchResponse response = null;
try {
response = restHighLevelClient.search(request, RequestOptions.DEFAULT);
} catch (IOException e) {
e.printStackTrace();
}
System.out.println(response.getHits().getHits());
System.out.println(response.getHits().getTotalHits());
SearchHits hits = response.getHits();
List<Integer> ids = new ArrayList<>();
for (SearchHit searchHit : hits){
Map<String, Object> sourceAsMap = searchHit.getSourceAsMap();
System.out.println(sourceAsMap);
ids.add(Integer.valueOf(sourceAsMap.get("id").toString()));
}
return ids;
}编写单元测试用例
@Test
public void query(){
List<Product> res = productService.query("food");
System.out.println(res);
}
事实上实际业务中从es中查出了id等信息之后需要通过id字段去mysql中进行多表关联的查询才能聚合结果但是走es的搜索之后可以大大提升获取id的性能
5.5 数据迁移
简单起见这里直接使用定时任务做数据同步可以考虑凌晨的时候来做这件事核心迁移方法
public void doSync() {
//设置一个时间点的条件作为同步数据的边界
List<Product> syncDatas = productDao.getSyncDatas();
for(Product product :syncDatas ){
ObjectMapper objectMapper = new ObjectMapper();
IndexRequest indexRequest = new IndexRequest("product");
ProductInfo productInfo = new ProductInfo();
productInfo.setId(product.getId());
productInfo.setPro_name(product.getProName());
productInfo.setDesc(product.getDesc());
String proData = null;
try {
proData = objectMapper.writeValueAsString(productInfo);
} catch (JsonProcessingException e) {
e.printStackTrace();
}
indexRequest.source(proData,XContentType.JSON);
//插入数据
try {
IndexResponse response = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
e.printStackTrace();
}
}
log.info("同步完成");
}最后增加一个定时任务的类将上述的方法添加进去
import com.congge.service.ProductService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.annotation.EnableScheduling;
import org.springframework.scheduling.annotation.Scheduled;
@Configuration
@EnableScheduling
public class SyncTask {
@Autowired
private ProductService productService;
@Scheduled(cron = "0/2 * * * * ?")
private void configureTasks(){
System.out.println("开始执行数据同步");
productService.doSync();
System.out.println("数据同步完成");
}
}六、写在文末
本文通过较大的篇幅详细讨论了mysql与es实现双写的设计以及实现过程当然在实际操作过程中还有很多值得探讨和细节希望为看到的小伙伴提供一个思路本篇到此结束感谢观看。