

CVPR2022 多目标跟踪(MOT)汇总
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
一、《DanceTrack: Multi-Object Tracking in Uniform Appearance and Diverse Motion》
作者: Peize Sun, Jinkun Cao, Yi Jiang, Zehuan Yuan, Song Bai, Kris Kitani, Ping Luo
The University of Hong Kong, Carnegie Mellon University, ByteDance Inc
论文链接https://arxiv.org/pdf/2111.14690.pdf
Githubhttps://github.com/DanceTrack/DanceTrack
1、摘要
当前的多目标跟踪采用检测器来进行目标定位并用ReID模型来实现数据关联。然而在现在的MOT Challenge数据集中目标的外观是具有足够的区分性的而这种区分性使得ReID模型很容易区分目标实现数据关联。此外当前的数据集中目标的运动模式比较简单目标运动都可以被近似为匀速线性运动。而这种目标与现实场景中的数据关联是存在一些bias的我们实际中通常跟踪的目标具有相同的外观表征同时其运动姿态也会更多样。为此本文作者提出了一个“DanceTrack”的数据集希望其能提供一个更好的平台来开发更多的MOT算法更少地依赖于视觉辨别更多地依赖于运动分析。
2、方法
在上述中已经提到了DanceTrack的提出动机下图也是数据集中的一些示例。

以下是DanceTrack与MOT Challenge数据集的比较。
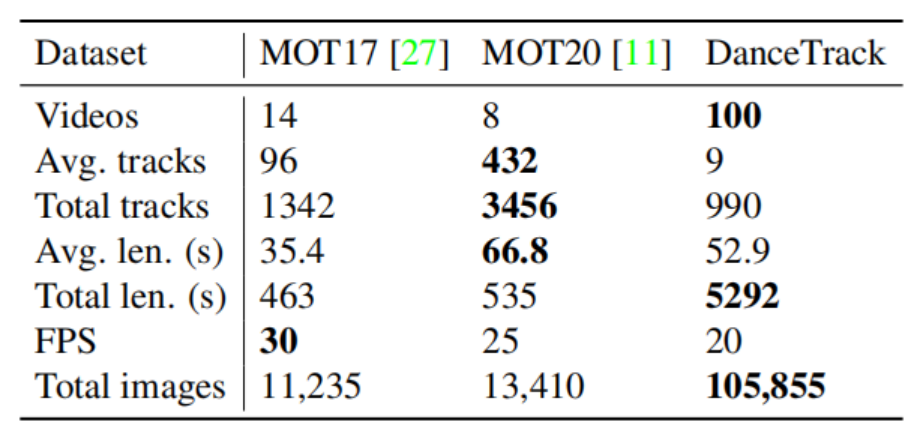
在论文中也给出了很详细地分析这个数据集的提出也说明了未来多目标跟踪研究的一个趋势会去关注运动更加复杂目标外观更相似的场景后续的SoccerNet也有相似的Motivation。
二、《SoccerNet-Tracking: Multiple Object Tracking Dataset and Benchmark in Soccer Videos》
作者: Anthony Cioppa, Silvio Giancola, Adrien Deliege, Le Kang, Xin Zhou, Zhiyu Cheng, Bernard Ghanem, Marc Van Droogenbroeck
University of Li`ege, KAUST, Baidu Research
论文链接https://arxiv.org/pdf/2204.06918.pdf
Githubwww.soccer-net.org
1、摘要
在足球视频中跟踪物体对于收集球员和球队的统计数据非常重要无论是估计总距离、控球还是队形。视频处理可以帮助自动提取这些信息而不需要任何携带型传感器因此适用于任何体育场上的任何球队。然而当前的数据集来测评这个问题是比较困难的。因此在本项工作中我们提出了一个新的多目标跟踪数据集由200个序列组成每个序列30秒代表具有挑战性的足球场景和一个完整的45分钟的半场用于测评长期跟踪。该数据集完成了目标框和轨迹ID的完成标注允许各种方法在各基准上做测评。该数据集也验证了当前MOT方法在这种快速运动和严重遮挡的领域中并没有很好的解决。因此作者也希望通过该数据集的提出来促进该部分研究的进行。
2、方法
SoccerNet的数据集示例如图所示。
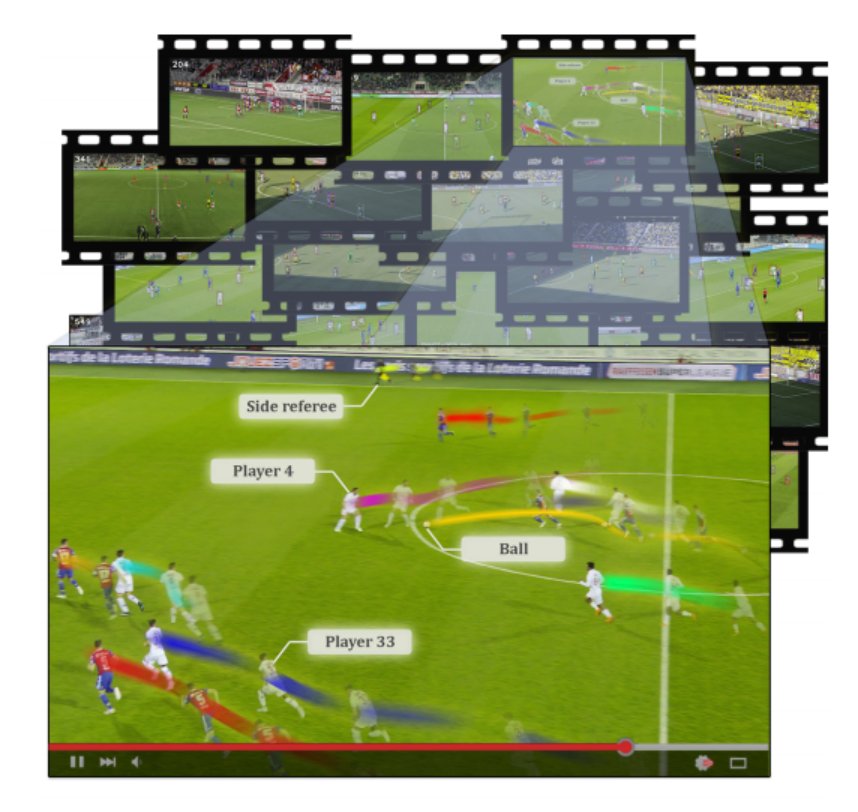
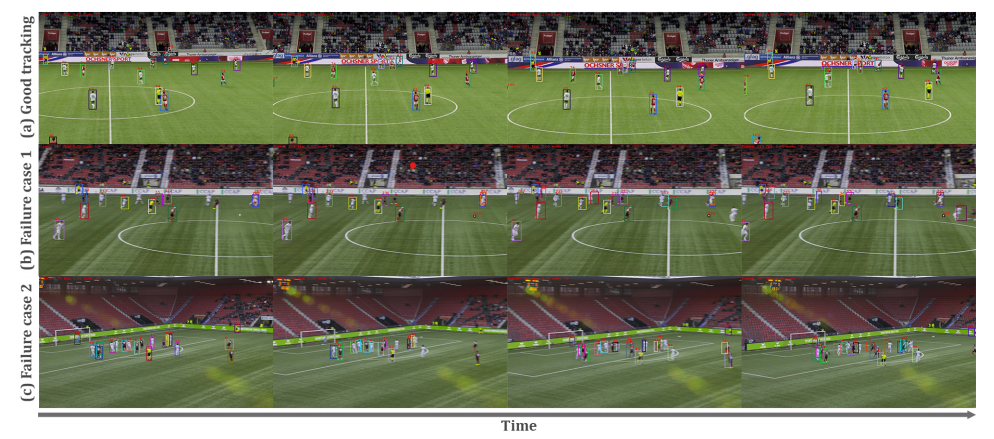
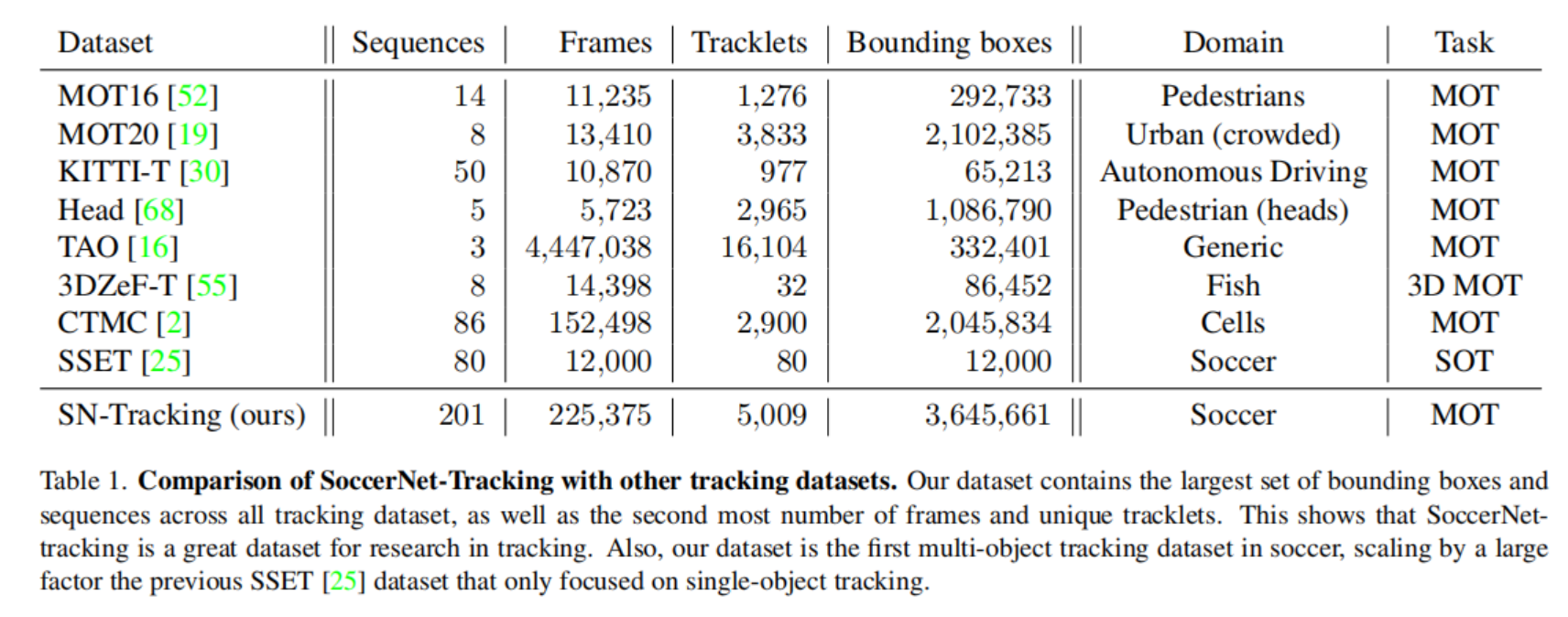
以下是SoccerNet与MOT数据集的比较。
三、《MeMOT: Multi-Object Tracking with Memory》
作者: Jiarui CaiMingze Xu Wei Li Yuanjun Xiong Wei Xia Zhuowen Tu Stefano Soatto
University of WashingtonAWS AI Labs
论文链接https://arxiv.org/pdf/2203.16761.pdf
1、摘要
我们提出了一种在线跟踪算法在一个公共框架下执行对象检测和数据关联能够在长时间跨度后链接对象。这是通过保留一个大的时空内存来存储被跟踪对象的ID Embeddings并根据需要自适应地从内存中引用和聚合有用的信息来实现关联。该模型称为MeMOT由三个主要模块组成它们都是基于Transformer的1)、假设生成Hypothesis Generation在当前视频帧中生成目标proposals2)、内存编码Memory Encoding从每个被跟踪对象的内存中提取核心信息3)、内存解码Memory Decoding同时解决目标检测和数据关联任务进行多目标跟踪。当在广泛采用的MOT基准数据集上进行评估时MeMOT观察到非常具有竞争性的性能。
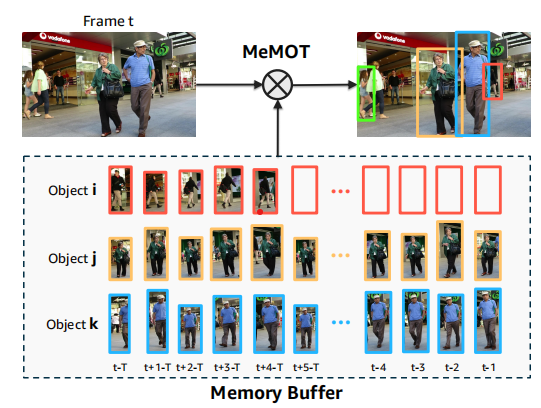
2、方法
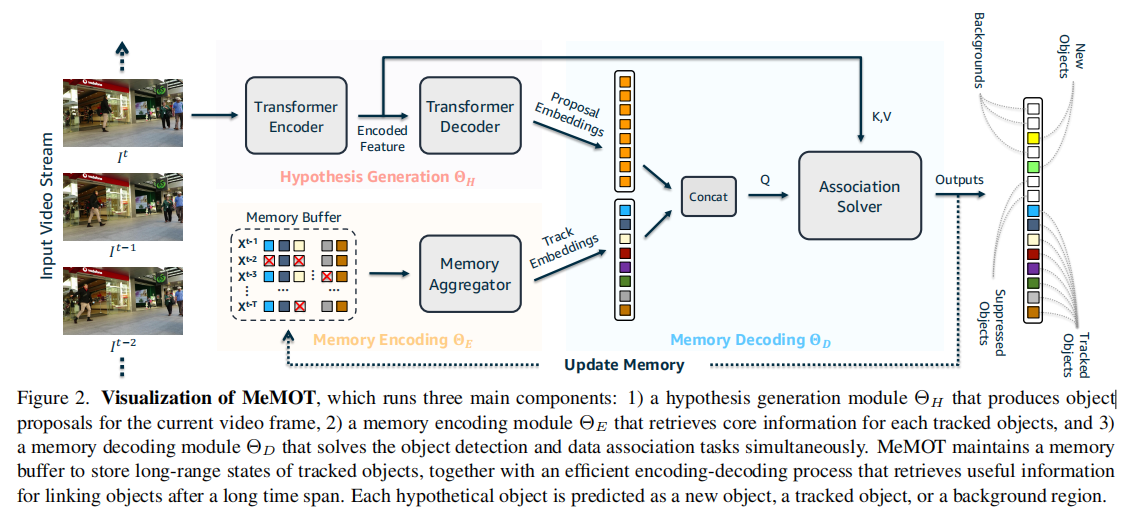
这篇文章的特点是通过Transformer的结构搭建了一个端到端的MOT框架不需要后处理性能和当前的SOTA比不是很高但是具有一定的竞争力。作者在文中没有提到推理速度感觉这个框架速度应该是一弱项。
要理解这个框架主要是了解作者提出的三个模块。
1假设生成Hypothesis Generation该模块通过Transformer的Encoder和Decoder生成一组proposal embeddings。这组embeddings有两个作用一个是表示当前帧新出现的一些目标另一个是为已经在跟踪状态的目标提供新的位置信息和外观信息。
2内存编码Memory Encoding这个模块通过Cross-Attn Module来维护每一个instance的两个特征一个关注短时信息一个关注长时信息最后把他们concat在一起去提取每一个instance的特征。长时特征是做了动态更新的但是作者在文中没有说明更新的方式。
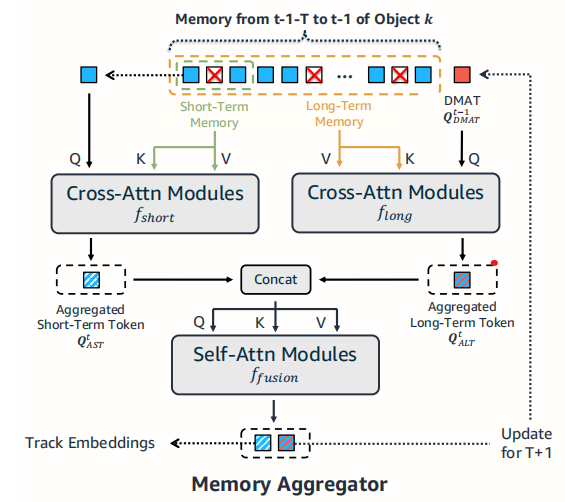
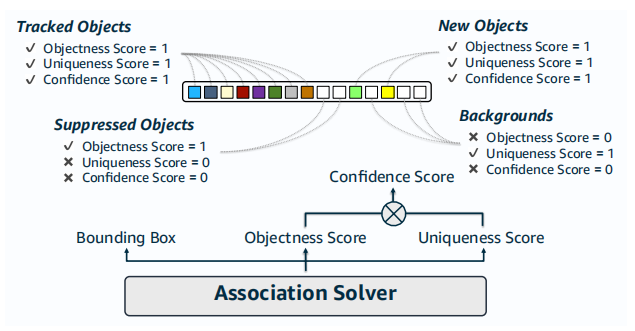
3内存解码Memory Decoding将track的embedding和embedding proposal拼接起来作为Q并用当前帧的特征做K和V通过一个Solver直接预测出Bounding BoxObjectness Score和Uniqueness Score。并通过这些值的组合直接获得最后的检测和数据关联结果。
四、《Learning of Global Objective for Network Flow in Multi-Object Tracking》
作者: Shuai LiYu KongHamid Rezatofighi
Rochester Institute of TechnologyMonash University
论文链接https://arxiv.org/pdf/2203.16210.pdf
1、摘要
这篇工作研究了基于最小代价流公式MCF的多目标跟踪问题并将其视为一个线性规划的实例进行研究。根据给出的计算性推理MCF的成果跟踪极大地依赖于底层线性的可学习代价函数。以往的研究大多数聚焦于如何在训练过程中考虑两帧信息来学习代价函数因此学习到的代价函数对于MCF来说是次优的。在推理过程中必须在多帧上考虑进行数据关联。为了解决这一问题本文提出了一种新的可微框架通过解决一个双层优化问题将训练和推理相关联。其中底层解决了一个线性程序关联的问题上层为一个包含全局跟踪结果的损失函数。可微层通过梯度下降进行反向传播明确地学习和正则化全局参数化代价函数。通过这种方法我们能够学习一个更好的全局MCF目标跟踪器。在MOT16、MOT17和MOT20上与目前最先进的方法相比本文的跟踪器取得了具有竞争力的性能。
2、方法
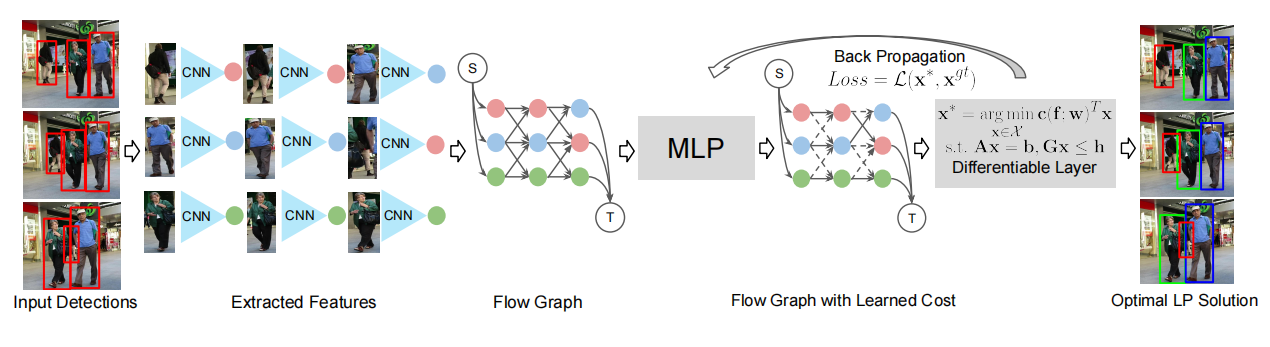
在这个方法中作者先通过已有的网络提取目标定位信息和每一个目标的外观特征。这些外观的特征会构建一个有向的图方向和时序方向相同。一个MLP层用于回归不同目标之间的连接概率。在训练过程中通过全局最优化的方法来构建损失优化MLP的参数而在推理过程中可以通过训练好的MLP网络直接预测结果进行tracking。
全文的推理部分比较多但是全是涉及怎么通过全局最小代价的方法来训练MLP的。需要细致了解该工作可以去看原文。本博客较关心的是作者用了MLP做了什么输入是什么最后怎么推理。
MLP主要用于预测两个detection结果之间是否可以关联如果可以关联会预测出一个概率其式子如下
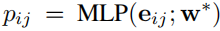
其中eij表示的是两个detection之间的边是如何构建的包括尺度、中心距离、框的IOU、embedding的距离等如下式
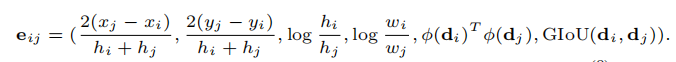
在推理的时候文中提到会利用基于一个长度为50帧~150帧的批次进行跟踪预测连接概率算最小代价流。并用了Gurobi求解器来获得最后的数据关联结果。由于每一个批次都覆盖了重复帧所以可以把短轨关联成长轨。
在后处理中作者还用了单目标跟踪器。
五、《Global Tracking Transformers》
作者: Xingyi ZhouTianwei YinVladlen KoltunPhillip Kr¨ahenb¨uhl
The University of Texas at AustinApple
论文链接https://arxiv.org/abs/2203.13250
代码链接https://github.com/xingyizhou/GTR
1、摘要
我们提出一种新的基于Transfomer的结构用于全局多目标跟踪。我们的网络把一段短的视频序列作为输入并预测所有对象的运行轨迹。其核心部分是一个全局tracking transformer用于操作序列中所有帧中的目标。Transfomer网络对所有帧中的对象特征进行编码并使用queries将它们分组为轨迹。轨迹的queries是来自单个帧的对象特征并自然地产生独特的轨迹。我们的全局tracking transformer不需要中间的成对分组或组合关联并且可以与目标检测器联合训练。它在流行的MOT17基准测试上取得了具有竞争力的性能有75.3MOTA和59.1HOTA。更重要的是我们的框架无缝地集成到最先进的大型vocabulary检测器中以跟踪任何对象。在具有挑战性的TAO数据集上进行的实验表明我们的框架改进了基于成对关联的方法。
本文的Motivation是搭建个网络可以直接从32帧的图像中学习一种匹配结果而不是逐帧做一个匹配。
2、方法
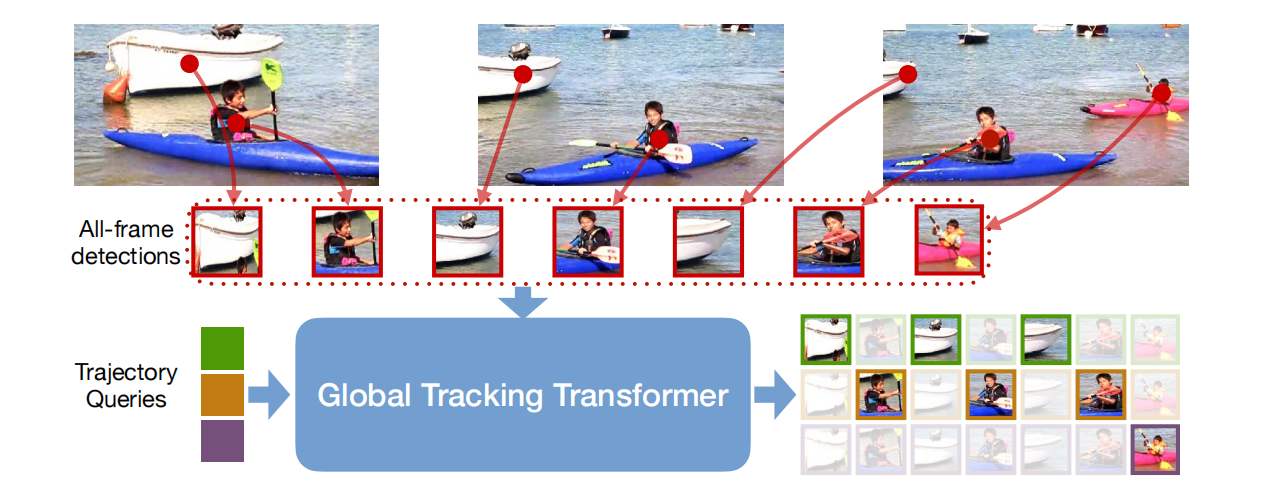

图中所示的是所提出的Global Tracking Transformer。其中F表示的是多帧的detection结果所提取的特征其中N表示数量D表示维度Q表示用来检索的tracklet的特征其中M表示数量D表示维度。通过Transformer的方式直接预测获得一个匹配结果G其中的数值预测每一个轨迹和每一个目标的关联关系即 git(qk, F) ∈ R表示第t帧第i个目标与该轨迹的关联关系该值为0表示这个目标与该轨迹没有关联关系。
在获得了G矩阵之后在每一帧中单独对同一个轨迹的匹配分数做一次Softmax得到
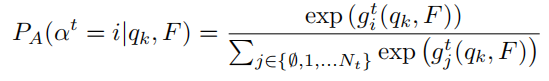
通过找最大的概率可以直接获得一条轨迹。在训练过程中作者通过最大化PA来让网络学会这种能力。
而在测试过程中感觉和DeepSort的过程依然比较像不同的是Deepsort直接用了embedding的距离来构建匹配矩阵而这个是通过transformer网络所预测出来的PA之后用Hungarian来保持唯一的匹配结果。
六、《Unified Transformer Tracker for Object Tracking》
作者: Fan MaMike Zheng ShouLinchao ZhuHaoqi FanYilei Xu Yi Yang Zhicheng Yan
ReLER Lab, AAII, University of Technology SydneyNational University of SingaporeMeta AIZhejiang University
论文链接https://arxiv.org/pdf/2203.15175v1.pdf
1、摘要
目标跟踪作为计算机视觉中的一个重要领域已经形成了两个独立的社区分别研究单目标跟踪(SOT)和多目标跟踪(MOT)。然而由于两种任务的训练数据集和跟踪对象的不同目前的一种跟踪场景的方法不容易适应另一种跟踪场景。虽然UniTrack[45]证明了可以使用具有多个头部的共享外观模型来处理单个跟踪任务但它没有利用大规模跟踪数据集进行训练并且在单目标跟踪上表现较差。在这项工作中我们提出了Unified Transformer Tracker (UTT) 以解决不同场景下的跟踪问题。我们在UTT中构架了一个Transformer Tracker在SOT和MOT中跟踪目标利用目标特征和跟踪帧特征之间的相关性来定位目标。我们证明了SOT和MOT任务都可以在这个框架内得到解决并且该模型可以通过在单个任务的数据集上交替优化SOT和MOT目标来同时进行端到端训练。在SOT和MOT数据集上训练了一个统一的模型在几个基准测试上进行了广泛的实验。
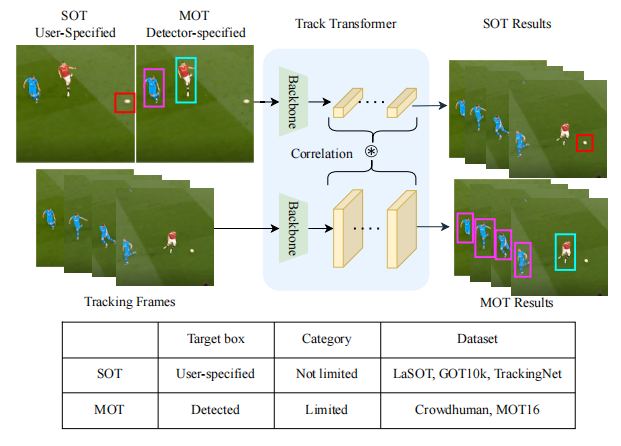
相比于UniTrack这篇工作解决了在SOT和MOT两个数据集上训练的问题在SOT任务上提点明显而MOT上还有一些差距可能是未来Unit类方法可以继续完善的地方。
2、方法
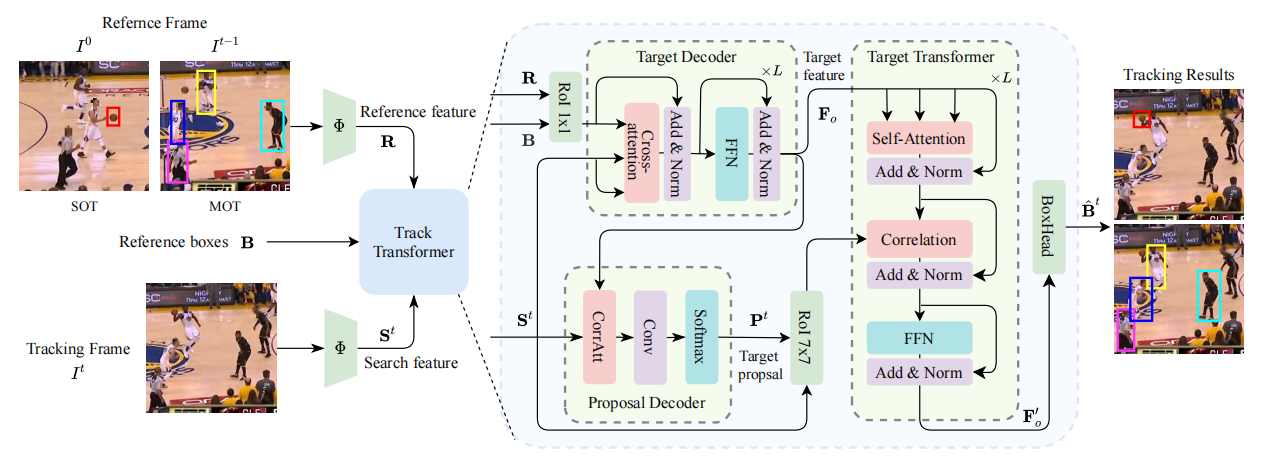
我们首先使用主干Φ来提取帧特征。 Transformer Tracker 有三个输入包括参考帧和跟踪帧当前帧以及参考帧中的目标框。Transformer Tracker的目标是预测当前帧中的目标定位。首先使用Transformer Tracker中的Target Decoder提取目标特征Proposal Decoder在跟踪帧中产生候选搜索区域。目标特征和搜索特征都被输入Target Tansformer以预测目标定位。
该方法在MOT中还是需要一个额外的detector来完成目标的定位。
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |