

Redis——Redis扩展应用限流解决方案原理
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
摘要
限流算法在分布式领域是一个经常被提起的话题,当系统的处理能力有限时,如何阻止计划外的请求继续对系统施压,这是一个需要重视的问题。在这里用 “断尾求生” 形容限流背后的思想,当然还有很多成语也表达了类似的意思,如弃卒保车、壮士断腕等等。除了控制流量,限流还有一个应用目的是用于控制用户行为,避免垃圾请求。如在UGC 社区,用户的发帖、回复、点赞等行为都要严格受控,一般要严格限定某行为在规定时间内允许的次数,超过次数那就是非法行为。对非法行为,业务必须规定适当的惩处策略。
一、限流算法原理
1.1 计数器算法
计数器算法是使用计数器在周期内累加访问次数,当达到设定的限流值时,触发限流策略。下一个周期开始时,进行清零,重新计数。此算法在单机还是分布式环境下实现都非常简单,使用redis的incr原子自增性和线程安全即可轻松实现。
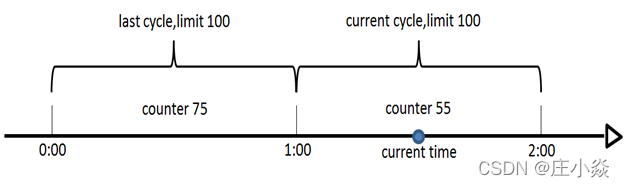
这个算法通常用于QPS限流和统计总访问量,对于秒级以上的时间周期来说,会存在一个非常严重的问题,那就是临界问题,如下图:
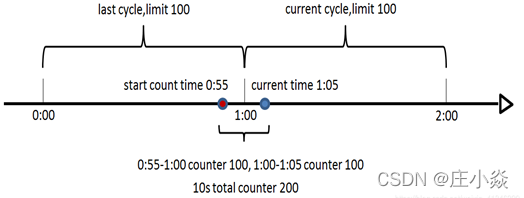
1.2 滑动窗口的算法
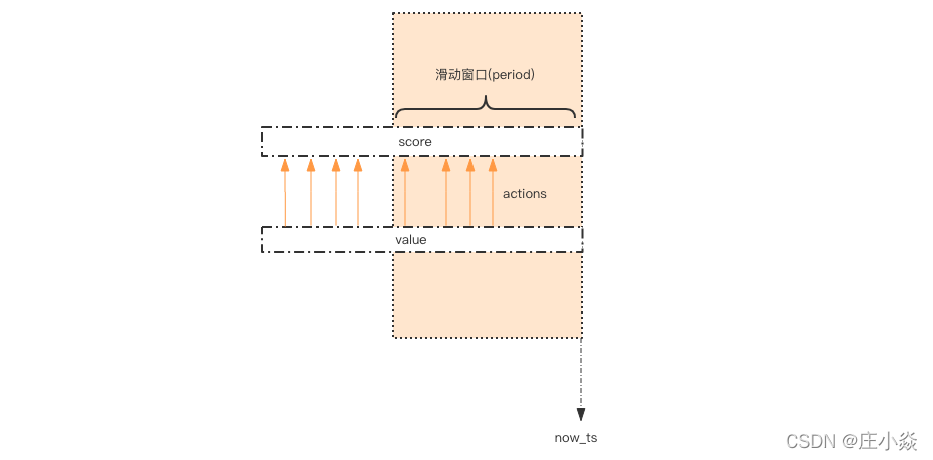
滑动窗口算法是将时间周期分为N个小周期,分别记录每个小周期内访问次数,并且根据时间滑动删除过期的小周期。如下图,假设时间周期为1min,将1min再分为2个小周期,统计每个小周期的访问数量,则可以看到,第一个时间周期内,访问数量为75,第二个时间周期内,访问数量为100,超过100的访问则被限流掉了
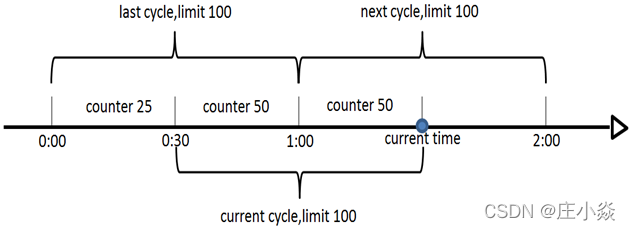
由此可见,当滑动窗口的格子划分的越多,那么滑动窗口的滚动就越平滑,限流的统计就会越精确。此算法可以很好的解决固定窗口算法的临界问题。
1.3 漏桶算法
漏桶算法是访问请求到达时直接放入漏桶,如当前容量已达到上限(限流值),则进行丢弃(触发限流策略)。漏桶以固定的速率进行释放访问请求(即请求通过),直到漏桶为空。
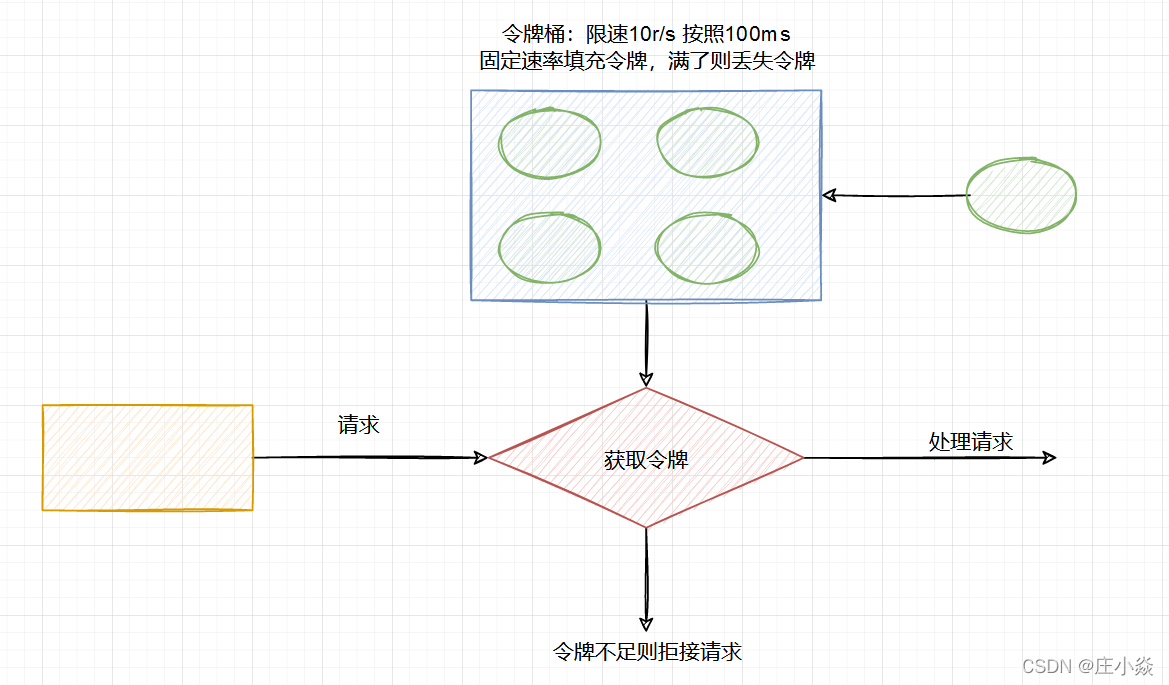
1.4 令牌桶算法
令牌桶算法是程序以r(r=时间周期/限流值)的速度向令牌桶中增加令牌,直到令牌桶满,请求到达时向令牌桶请求令牌,如获取到令牌则通过请求,否则触发限流策略
二、限流算法实现与实战
2.1 Redis的zset滑动时间窗口实战
这个限流需求中存在一个滑动时间窗口,想想zset 数据结构的 score 值,是不是可以通过 score 来圈出这个时间窗口来。而且我们只需要保留这个时间窗口,窗口之外的数据都可以砍掉。那这个 zset 的 value 填什么比较合适呢?它只需要保证唯一性即可,用 uuid 会比较浪费空间,那就改用毫秒时间戳吧。如图所示,用一个 zset 结构记录用户的行为历史,每一个行为都会作为 zset 中的一个key 保存下来。同一个用户同一种行为用一个 zset 记录。为节省内存,我们只需要保留时间窗口内的行为记录,同时如果用户是冷用户,滑动时间窗口内的行为是空记录,那么这个 zset 就可以从内存中移除,不再占用空间。zset 集合中只有 score 值非常重要, value 值没有特别的意义,只需要保证它是唯一的就可以了。因为这几个连续的 Redis 操作都是针对同一个 key 的,使用 pipeline 可以显著提升Redis 存取效率。但这种方案也有缺点,因为它要记录时间窗口内所有的行为记录,如果这个量很大,比如限定 60s 内操作不得超过 100w 次这样的参数,它是不适合做这样的限流的,因为会消耗大量的存储空间。
public class SimpleRateLimiter {
private Jedis jedis;
public SimpleRateLimiter(Jedis jedis) {
this.jedis = jedis;
}
public boolean isActionAllowed(String userId, String actionKey, int period, int maxCount) {
String key = String.format("hist:%s:%s", userId, actionKey);
long nowTs = System.currentTimeMillis();
Pipeline pipe = jedis.pipelined();
pipe.multi();
pipe.zadd(key, nowTs, "" + nowTs);
pipe.zremrangeByScore(key, 0, nowTs - period * 1000);
Response<Long> count = pipe.zcard(key);
pipe.expire(key, period + 1);
pipe.exec();
pipe.close();
return count.get() <= maxCount;
}
public static void main(String[] args) {
Jedis jedis = new Jedis();
SimpleRateLimiter limiter = new SimpleRateLimiter(jedis);
for(int i=0;i<20;i++) {
System.out.println(limiter.isActionAllowed("laoqian", "reply", 60, 5));
}
}
}整体思路就是:每一个行为到来时,都维护一次时间窗口。将时间窗口外的记录全部清理掉,只保留窗口内的记录。zset 集合中只有 score 值非常重要,value 值没有特别的意义,只需要保证它是唯一的就可以了。因为这几个连续的 Redis 操作都是针对同一个 key 的,使用 pipeline 可以显著提升 Redis 存取效率。但这种方案也有缺点,因为它要记录时间窗口内所有的行为记录,如果这个量很大,比如限定 60s 内操作不得超过 100w 次这样的参数,它是不适合做这样的限流的,因为会消耗大量的存储空间。
2.2 Redis令牌桶限流实现与实战
# coding: utf8
import time
class Funnel(object):
def __init__(self, capacity, leaking_rate):
self.capacity = capacity # 漏斗容量
self.leaking_rate = leaking_rate # 漏嘴流水速率
self.left_quota = capacity # 漏斗剩余空间
self.leaking_ts = time.time() # 上一次漏水时间
def make_space(self):
now_ts = time.time()
delta_ts = now_ts - self.leaking_ts # 距离上一次漏水过去了多久
delta_quota = delta_ts * self.leaking_rate # 又可以腾出不少空间了
if delta_quota < 1: # 腾的空间太少,那就等下次吧
return
self.left_quota += delta_quota # 增加剩余空间
self.leaking_ts = now_ts # 记录漏水时间
if self.left_quota > self.capacity: # 剩余空间不得高于容量
self.left_quota = self.capacity
def watering(self, quota):
self.make_space()
if self.left_quota >= quota: # 判断剩余空间是否足够
self.left_quota -= quota
return True
return False
funnels = {} # 所有的漏斗
# capacity 漏斗容量
# leaking_rate 漏嘴流水速率 quota/s
def is_action_allowed(user_id, action_key, capacity, leaking_rate):
key = '%s:%s' % (user_id, action_key)
funnel = funnels.get(key)
if not funnel:
funnel = Funnel(capacity, leaking_rate)
funnels[key] = funnel
return funnel.watering(1)
for i in range(20):
print(is_action_allowed('laoqian', 'reply', 15, 0.5))class FunnelRateLimiter {
static class Funnel {
int capacity;
float leakingRate;
int leftQuota;
long leakingTs;
public Funnel(int capacity, float leakingRate) {
this.capacity = capacity;
this.leakingRate = leakingRate;
this.leftQuota = capacity;
this.leakingTs = System.currentTimeMillis();
}
void makeSpace() {
long nowTs = System.currentTimeMillis();
long deltaTs = nowTs - leakingTs;
int deltaQuota = (int) (deltaTs * leakingRate);
if (deltaQuota < 0) { // 间隔时间太长,整数数字过大溢出
this.leftQuota = capacity;
this.leakingTs = nowTs;
return;
}
if (deltaQuota < 1) { // 腾出空间太小,最小单位是1
return;
}
this.leftQuota += deltaQuota;
this.leakingTs = nowTs;
if (this.leftQuota > this.capacity) {
this.leftQuota = this.capacity;
}
}
boolean watering(int quota) {
makeSpace();
if (this.leftQuota >= quota) {
this.leftQuota -= quota;
return true;
}
return false;
}
}
private Map<String, Funnel> funnels = new HashMap<>();
public boolean isActionAllowed(String userId, String actionKey, int capacity, float leakingRate) {
String key = String.format("%s:%s", userId, actionKey);
Funnel funnel = funnels.get(key);
if (funnel == null) {
funnel = new Funnel(capacity, leakingRate);
funnels.put(key, funnel);
}
return funnel.watering(1); // 需要1个quota
}
}Funnel 对象的 make_space 方法是漏斗算法的核心,其在每次灌水前都会被调用以触发漏水,给漏斗腾出空间来。能腾出多少空间取决于过去了多久以及流水的速率。Funnel 对象占据的空间大小不再和行为的频率成正比,它的空间占用是一个常量。
问题来了,分布式的漏斗算法该如何实现?能不能使用 Redis 的基础数据结构来搞定?我们观察 Funnel 对象的几个字段,我们发现可以将 Funnel 对象的内容按字段存储到一个 hash 结构中,灌水的时候将 hash 结构的字段取出来进行逻辑运算后,再将新值回填到 hash 结构中就完成了一次行为频度的检测。但是有个问题,我们无法保证整个过程的原子性。从 hash 结构中取值,然后在内存里运算,再回填到 hash 结构,这三个过程无法原子化,意味着需要进行适当的加锁控制。而一旦加锁,就意味着会有加锁失败,加锁失败就需要选择重试或者放弃。如果重试的话,就会导致性能下降。如果放弃的话,就会影响用户体验。同时,代码的复杂度也跟着升高很多。这真是个艰难的选择。
cl.throttle laoqian:reply 15 30 60
1) (integer) 0 # 0 表示允许,1表示拒绝
2) (integer) 15 # 漏斗容量capacity
3) (integer) 14 # 漏斗剩余空间left_quota
4) (integer) -1 # 如果拒绝了,需要多长时间后再试(漏斗有空间了,单位秒)
5) (integer) 2 # 多长时间后,漏斗完全空出来(left_quota==capacity,单位秒)在执行限流指令时,如果被拒绝了,就需要丢弃或重试。cl.throttle 指令考虑的非常周到,连重试时间都帮你算好了,直接取返回结果数组的第四个值进行 sleep 即可,如果不想阻塞线程,也可以异步定时任务来重试。
package com.zhuangxiaoyan.springbootredis.cell;
import com.fasterxml.jackson.annotation.JsonAutoDetect;
import com.fasterxml.jackson.annotation.JsonInclude;
import com.fasterxml.jackson.annotation.PropertyAccessor;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.jsontype.impl.LaissezFaireSubTypeValidator;
import com.fasterxml.jackson.datatype.jsr310.JavaTimeModule;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.data.redis.core.script.DefaultRedisScript;
import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;
import java.util.Arrays;
import java.util.List;
/**
* @Classname RedisCell
* @Description TODO
* @Date 2022/4/13 22:37
* @Created by xjl
*/
public class RedisCell {
/**
* redis 客户端
*/
@Autowired
private StringRedisTemplate redisTemplate;
/**
* 请求是否被允许
* @param key 限流的key
* @param maxBurst 最大请求
* @param tokens 令牌数量 每过seconds时间就往桶里放入tokens的令牌数量
* @param seconds 时间 每过seconds时间就往桶里放入tokens的令牌数量
* @param apply 本次获取几个令牌
* @return
*/
public boolean isActionAllowed(String key, int maxBurst, int tokens, int seconds, int apply){
DefaultRedisScript<List> script = new DefaultRedisScript<>("return redis.call('cl.throttle',KEYS[1],ARGV[1],ARGV[2],ARGV[3],ARGV[4])", List.class);
List<Long> rst = redisTemplate.execute(script, Arrays.asList(key), maxBurst, tokens, seconds, apply);
//响应结果
/**
* 1) (integer) 0 # 当前请求是否被允许,0表示允许,1表示不允许
* 2) (integer) 11 # 令牌桶的最大容量,令牌桶中令牌数的最大值
* 3) (integer) 10 # 令牌桶中当前的令牌数
* 4) (integer) -1 # 如果被拒绝,需要多长时间后在重试,如果当前被允许则为-1
* 5) (integer) 12 # 多长时间后令牌桶中的令牌会满
*/
return rst.get(0) == 0;
}
}三、 分布式限流解决方案
在高并发系统中常见的限流方式有很多种,但是总的来说限流的分类如下所示:
- 合法性验证限流:比如验证码、IP 黑名单等,这些手段可以有效的防止恶意攻击和爬虫采集;
- 容器限流:比如 Tomcat、Nginx 等限流手段,其中 Tomcat 可以设置最大线程数(maxThreads),当并发超过最大线程数会排队等待执行;而 Nginx 提供了两种限流手段:一是控制速率,二是控制并发连接数;
- 服务端限流:比如我们在服务器端通过限流算法实现限流,此项也是我们本文介绍的重点。
3.1 合法性验证限流
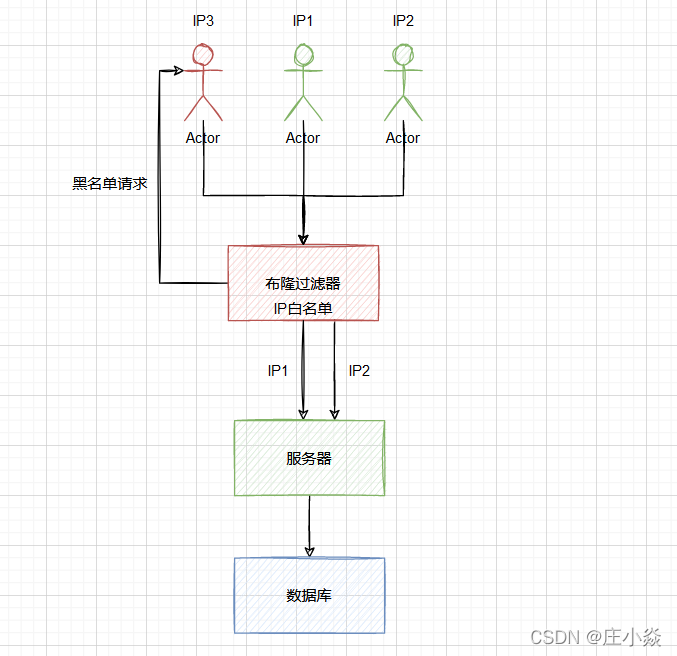
合法性验证限流为最常规的业务代码,就是普通的验证码和 IP 黑名单系统。可以利用的redis中布隆过滤器来实现的IP黑白名单。
3.2 容器限流设计
3.2.1 Tomcat 限流设置
<Connector port="8080" protocol="HTTP/1.1" connectionTimeout="20000" maxThreads="150" redirectPort="8443" />其中 maxThreads 就是 Tomcat 的最大线程数,当请求的并发大于此值(maxThreads)时,请求就会排队执行,这样就完成了限流的目的。 maxThreads 的值可以适当的调大一些,此值默认为 150(Tomcat 版本 8.5.42),但这个值也不是越大越好,要看具体的硬件配置,需要注意的是每开启一个线程需要耗用 1MB 的 JVM 内存空间用于作为线程栈之用,并且线程越多 GC 的负担也越重。需要注意一下,操作系统对于进程中的线程数有一定的限制,Windows 每个进程中的线程数不允许超过 2000,Linux 每个进程中的线程数不允许超过 1000。
3.2.2 Nginx 限流
Nginx 提供了两种限流手段:一是控制速率,二是控制并发连接数。
我们需要使用 limit_req_zone 用来限制单位时间内的请求数,即速率限制。
limit_req_zone $binary_remote_addr zone=mylimit:10m rate=2r/s;
server {
location / {
limit_req zone=mylimit;
}
}
以上配置表示,限制每个 IP 访问的速度为 2r/s,因为 Nginx 的限流统计是基于毫秒的,我们设置的速度是 2r/s,转换一下就是 500ms 内单个 IP 只允许通过 1 个请求,从 501ms 开始才允许通过第 2 个请求。limit_req_zone $binary_remote_addr zone=mylimit:10m rate=2r/s;
server {
location / {
limit_req zone=mylimit burst=4;
}
}
burst=4 表示每个 IP 最多允许4个突发请求, 利用 limit_conn_zone 和 limit_conn 两个指令即可控制并发数
limit_conn_zone $binary_remote_addr zone=perip:10m;
limit_conn_zone $server_name zone=perserver:10m;
server {
...
limit_conn perip 10;
limit_conn perserver 100;
}
其中 limit_conn perip 10 表示限制单个 IP 同时最多能持有 10 个连接;limit_conn perserver 100 表示 server 同时能处理并发连接的总数为 100 个。3.3 服务端限流
3.3.1 连接池、线程限流方案
可以使用池化技术来限制总资源数:连接池、线程池。比如分配给每个应用的数据库连接是 100,那么本应用最多可以使用 100 个资源,超出了可以 等待 或者 抛异常。
//获取当前机器的核数
public static final int cpuNum = Runtime.getRuntime().availableProcessors();
@Override
public Executor getAsyncExecutor() {
ThreadPoolTaskExecutor taskExecutor = new ThreadPoolTaskExecutor();
taskExecutor.setCorePoolSize(cpuNum);//核心线程大小
taskExecutor.setMaxPoolSize(cpuNum * 2);//最大线程大小
taskExecutor.setQueueCapacity(500);//队列最大容量
//当提交的任务个数大于QueueCapacity,就需要设置该参数,但spring提供的都不太满足业务场景,可以自定义一个,也可以注意不要超过QueueCapacity即可
taskExecutor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
taskExecutor.setWaitForTasksToCompleteOnShutdown(true);
taskExecutor.setAwaitTerminationSeconds(60);
taskExecutor.setThreadNamePrefix("BCarLogo-Thread-");
taskExecutor.initialize();
return taskExecutor;
}corePoolSize:核心线程数;maximunPoolSize:最大线程数
每当有新的任务到线程池时,
- 第一步:先判断线程池中当前线程数量是否达到了corePoolSize,若未达到,则新建线程运行此任务,且任务结束后将该线程保留在线程池中,不做销毁处理,若当前线程数量已达到corePoolSize,则进入下一步;
- 第二步:判断工作队列(workQueue)是否已满,未满则将新的任务提交到工作队列中,满了则进入下一步;
- 第三步:判断线程池中的线程数量是否达到了maxumunPoolSize,如果未达到,则新建一个工作线程来执行这个任务,如果达到了则使用饱和策略来处理这个任务。注意: 在线程池中的线程数量超过corePoolSize时,每当有线程的空闲时间超过了keepAliveTime,这个线程就会被终止。直到线程池中线程的数量不大于corePoolSize为止。
当工作队列满且线程个数达到maximunPoolSize后所采取的策略
AbortPolicy:默认策略;新任务提交时直接抛出未检查的异常RejectedExecutionException,该异常可由调用者捕获。CallerRunsPolicy:既不抛弃任务也不抛出异常,使用调用者所在线程运行新的任务。DiscardPolicy:丢弃新的任务,且不抛出异常。DiscardOldestPolicy:调用poll方法丢弃工作队列队头的任务,然后尝试提交新任务自定义策略:根据用户需要定制。
3.3.2 限流某个接口的总并发/请求数
使用 Java 中的 AtomicLong,示意代码:
try{
if(atomic.incrementAndGet() > 限流数) {
//拒绝请求
} else {
//处理请求
}
} finally {
atomic.decrementAndGet();
}LoadingCache counter = CacheBuilder.newBuilder()
.expireAfterWrite(2, TimeUnit.SECONDS)
.build(newCacheLoader() {
@Override
public AtomicLong load(Long seconds) throws Exception {
return newAtomicLong(0);
}
});
longlimit =1000;
while(true) {
// 得到当前秒
long currentSeconds = System.currentTimeMillis() /1000;
if(counter.get(currentSeconds).incrementAndGet() > limit) {
System.out.println("限流了: " + currentSeconds);
continue;
}
// 业务处理
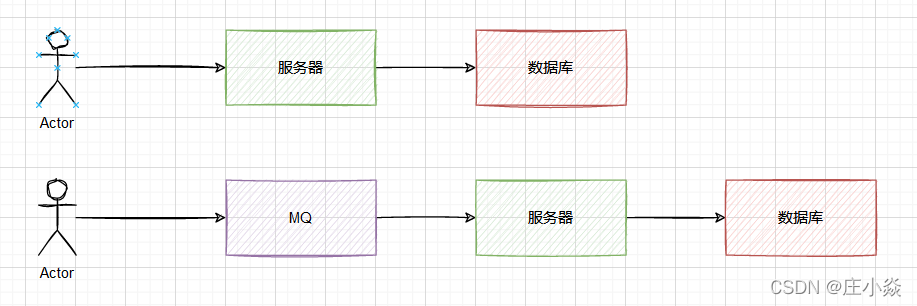
}3.3.3 利用的MQ来实现限流
博文参考
限流的一些解决方案_夜风_BLOG的博客
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |