

(初学者强烈推荐)Ubuntu 配置hadoop 超详细教程(全过程)
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
引言
本文的教程仅为个人的操作经验所写每个人下载的版本不一样所以会出现不同的情况异常等如有问题可询问博主或百度查找解决方法。
本机的配置环境如下
hadoop(3.3.1)
jdk版本jdk-8
Linux(64位)
1、安装jdk
在Ubuntu中用压缩包安装jdk较为麻烦需要配置系统环境变量和配置文件一步出错可能无法使用。所以本文在Ubuntu中使用命令安装jdk。其他方法安装jdk也可。
打开终端
执行以下命令
sudo apt-get install openjdk-8-jdk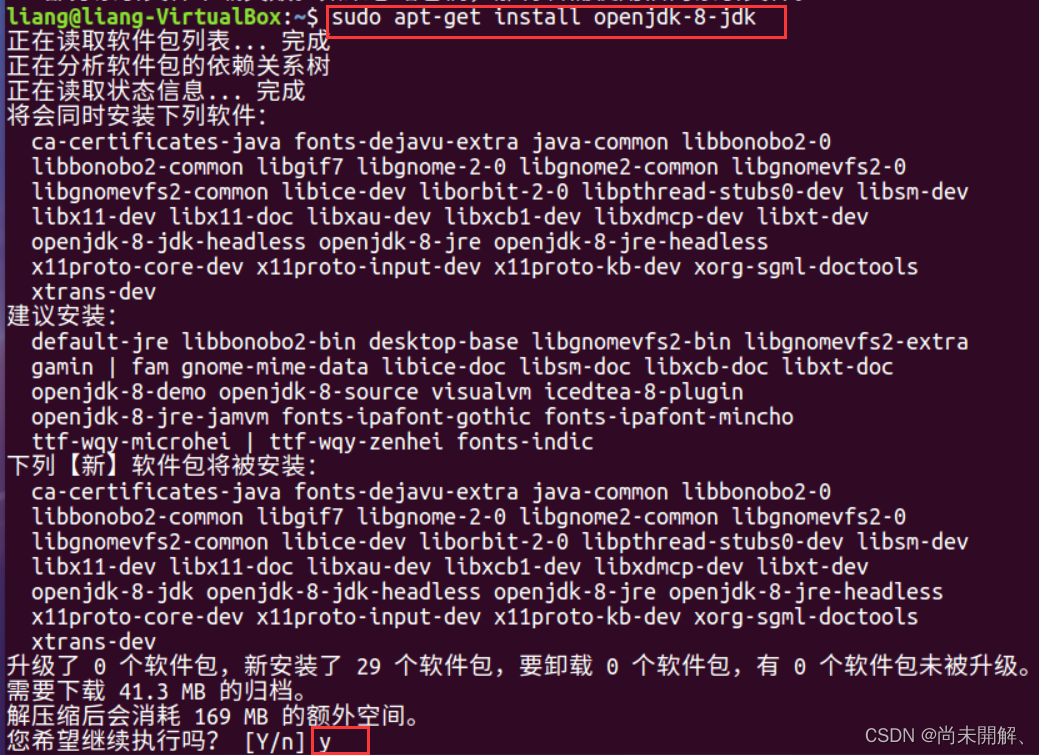
输入y回车等待安装完成
java -version安装完成后用 java -version 检验是否安装成功如果如下图则安装成功
当想要卸载jdk则使用以下命令sudo apt remove openjdk*

打开环境文件
sudo gedit ~/.bashrc
文件顶部加入以下语句并保存
sudo apt-get install openjdk-8-jdk 命令安装的jdk默认路径为 /usr/lib/jvm/java-8-openjdk-amd64
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 #目录要换成自己jdk所在目录
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH 使环境生效
source ~/.bashrc 使用 echo $JAVA_HOME 显示JAVA_HOME即为成功
2、安装ssh免密码登录
sudo apt-get install ssh openssh-server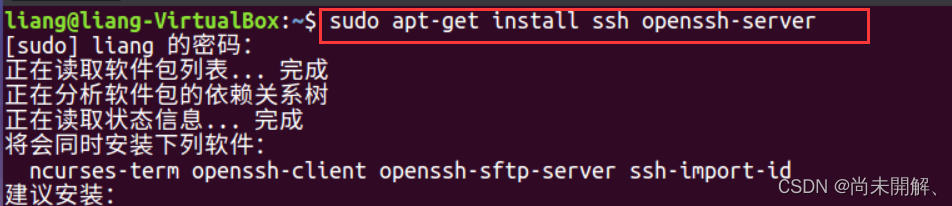
安装完毕后在终端中依次进行继以下命令操作
cd ~/.ssh/生成密钥
ssh-keygen -t rsa 将秘钥加入到授权中
cat id_rsa.pub >> authorized_keys再验证ssh localhost 如下图不用密码登录即为成功。
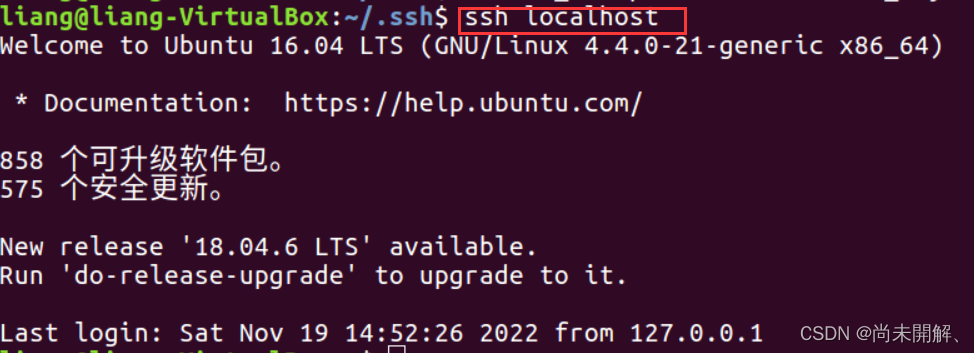
3、安装hadoop
1安装hadoop并解压
镜像下载链接https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.3.1/
下载好的压缩包传到 /usr/local/目录下
使用如下命令解压缩Hadoop安装包
tar -zxvf hadoop-3.1.1.tar.gz
解压完成之后进入hadoop-3.1.1文件内容如下

2) 配置相关文件
core-site.xml
打开/etc中的core-site.xml 文件加入如下语句并保存
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop-3.3.1/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
注意其中路径要修改为自己的

hdfs-site.xml
和上面一样打开/etc中的hdfs-site.xml 文件加入如下语句并保存
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop-3.3.1/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop-3.3.1/tmp/dfs/data</value>
</property>
hadoop-env.sh
查看你的 jdk安装目录
echo $JAVA_HOME
打开 hadoop-env.sh 文件配置如下并保存
export JAVA_HOME="/usr/lib/jvm/java-8-openjdk-amd64" # 根据自己的路径写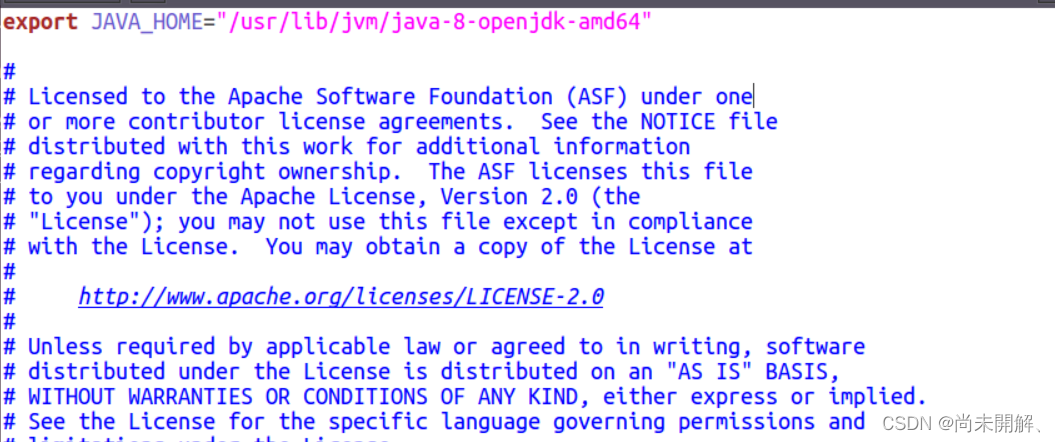
4、运行hadoop
1首先初始化HDFS系统
在hadop3.3.0目录下使用如下命令进行初始化
bin/hdfs namenode -format成功后如下图

2开启NameNode和DataNode守护进程
继续运行如下命令开启hadoop
sbin/start-dfs.sh成功如下图

3查看jps进程信息
jps
如下图即为成功

关闭hadoop使用命令 sbin/stop-dfs.sh
打开浏览器输入http://localhost:9870成功打开

4创建hadoop用户组
使用/bin/bash作为shell sudo useradd -m hadoop -s /bin/bash
设置密码 sudo passwd hadoop
添加hadoop至管理员权限 sudo adduser hadoop sudo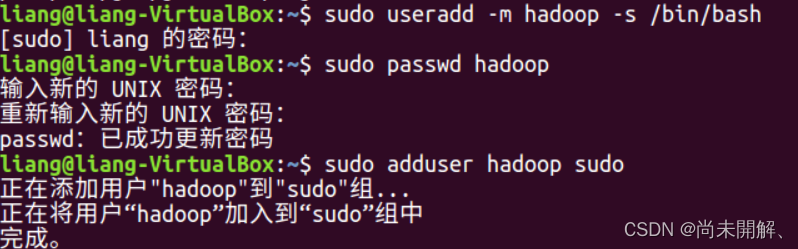
5、配置yarn
搭建前请保证已经搭建好了HDFS的环境即配置好所上内容。
1终端输入hostname查看主机名
hostname2打开/etc下yarn-site.xml在在configuration标签中加入如下注意主机名要修改为自己的
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--Resource Manager-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>liang-VirtualBox</value><!--你的hostname的主机名-->
</property>3打开mapred-site.xml 文件配置如下在configuration标签中间加入
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
4输入命令启动yarn
sbin/start-yarn.sh
jps查看进程信息多了两个东西
成功启动如下图

在浏览器输入主机名8088 打开成功

6、配置JobHistory可不配
JobHistory用来记录已经finished的mapreduce运行日志日志信息存放于HDFS目录中默认情况下没有开启此功能需要在mapred-site.xml、yarn-site.xml配置并手动启动
mapred-site.xml添加如下配置在configuration标签中间加入
<property>
<name>mapreduce.jobhistory.address</name>
<value>主机名:10020</value>
<description>MapReduce JobHistory Server IPC host:port</description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>主机名:19888</value>
<description>MapReduce JobHistory Server Web UI host:port</description>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/history/done</value>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/history/done_intermediate</value></property>
yarn-site.xml添加如下配置在configuration标签中间加入
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
hadoop fs -ls /history查看历史记录

开启history进程
mapred --daemon start historyserver通过浏览器访问 主机名:19888
成功如下图
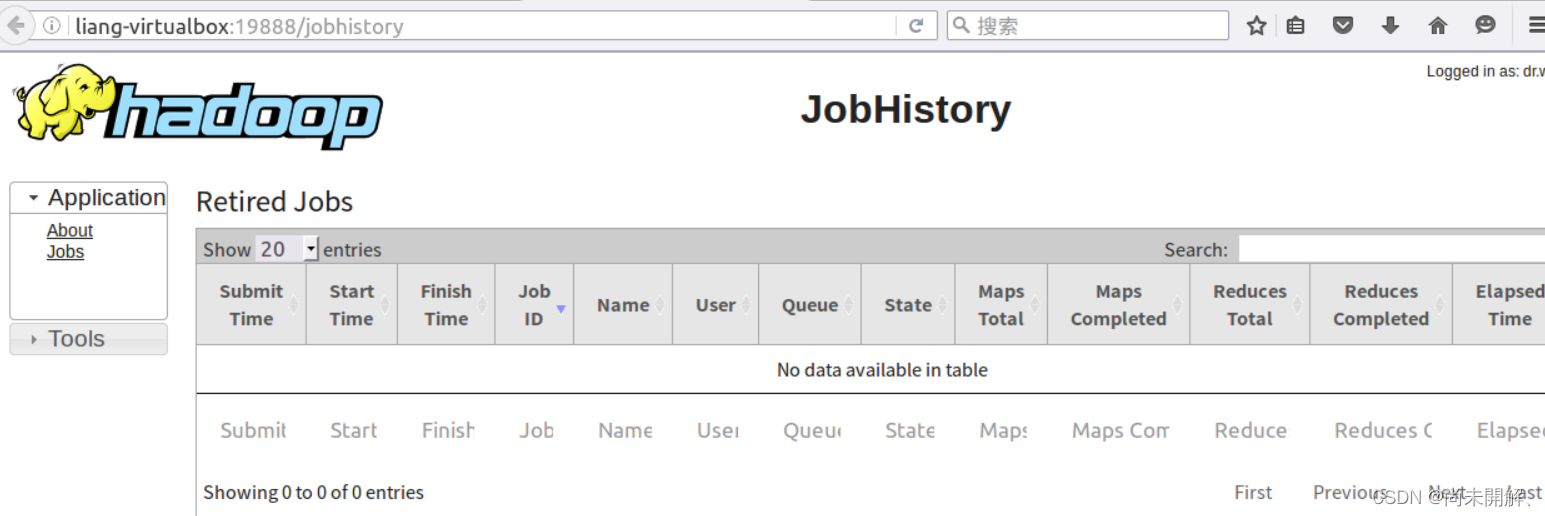
至此hadoop全部配置完成可下载eclipse进行wordcount等运算实验。
如有任何疑问请留言尽仅有所学帮助。