

基于Django 框架搭建学习平台系统,实现KNN、ID3、C4.5、SVM、朴素贝叶斯、BP神经网络等算法及流程管理 附代码
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
完整代码https://download.csdn.net/download/qq_38735017/87425744
kNN 简介
kNN 原理 存在一个样本数据集合也称作训练集或者样本集并且样本集中每个数据都存在标签即样本集实际上是 每条数据 与 所属分类 的 对应关系。 核心思想 若输入的数据没有标签则新数据的每个特征与样本集中数据对应的特征进行比较该算法提取样本集中特征最相似数据最近邻的分类标签。 k 选自最相似的 k 个数据通常是不大于 20 的整数最后选择这 k 个数据中出现次数最多的分类作为新数据的分类。
k-近邻算法的一般流程
1.收集数据可以使用任何方法,
2.准备数据距离计算所需的数值,最好是结构化的数据格式。
3.分析数据可以使用任何方法。
4.训练算法此不走不适用于k-近邻算法。
5.测试算法计算错误率。
6.使用算法首先需要输入样本数据和结构化的输出结果然后运行k-近邻算法判定输入数据分别属于哪个分类最后应用对计算出的分类之行后续的处理。example1
python 导入数据
from numpy import *
import operator
def createDataSet():
group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group,labelspython 处理数据
# 计算已知类别数据集中的点与当前点之间的距离欧式距离
# 按照距离递增次序排序
# 选取与当前点距离最小的K个点
# 确定前K个点所在类别的出现频率
# 返回前k个点出现频率最高的类别最为当前点的预测分类
# inX输入向量训练集dataSet,标签向量labelsk表示用于选择最近邻的数目
def clissfy0(inX,dataSet,labels,k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX,(dataSetSize,1)) - dataSet
sqDiffMat = diffMat ** 0.5
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances ** 0.5
sortedDistIndicies = distances.argsort()
classCount = {}
for i in range(k):
voteLabel = labels[sortedDistIndicies[i]]
classCount[voteLabel] = classCount.get(voteLabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(),
key = operator.itemgetter(1),reverse = True)
return sortedClassCount[0][0]python 数据测试
import kNN
from numpy import *
dataSet,labels = createDataSet()
testX = array([1.2,1.1])
k = 3
outputLabelX = classify0(testX,dataSet,labels,k)
testY = array([0.1,0.3])
outputLabelY = classify0(testY,dataSet,labels,k)
print('input is :',testX,'output class is :',outputLabelX)
print('input is :',testY,'output class is :',outputLabelY)python 结果输出
('input is :', array([ 1.2, 1.1]), 'output class is :', 'A')
('input is :', array([ 0.1, 0.3]), 'output class is :', 'B')example2
使用 k-近邻算法改进约会网站的配对效果
处理步骤
1.收集数据提供文本文件
2.准备数据使用python解析文本文件
3.分析数据:使用matplotlib画二维扩散图
4.训练算法此步骤不适用与k-近邻算法
5.测试算法使用提供的部份数据作为测试样本
6:使用算法输入一些特征数据以判断对方是否为自己喜欢的类型python 整体实现
# coding:utf-8fromnumpyimport*importoperatorfromkNNimportclassify0importmatplotlib.pyplotaspltdeffile2matrmix(filename):fr=open(filename)arrayLines=fr.readlines()numberOfLines=len(arrayLines)returnMat=zeros((numberOfLines,3))classLabelVector=[]index=0forlineinarrayLines:line=line.strip()listFromLine=line.split('\t')returnMat[index,:]=listFromLine[0:3]classLabelVector.append(int(listFromLine[-1]))index+=1returnreturnMat,classLabelVectordefautoNorm(dataSet):minVals=dataSet.min(0)maxVals=dataSet.max(0)ranges=maxVals-minValsnormDataSet=zeros(shape(dataSet))m=dataSet.shape[0]normDataSet=dataSet-tile(minVals,(m,1))normDataSet=normDataSet/tile(ranges,(m,1))returnnormDataSet,ranges,minValsdefdatingClassTest():hoRatio=0.10datingDataMat,datingLabels=file2matrmix('datingTestSet2.txt')normMat,ranges,minVals=autoNorm(datingDataMat)m=normMat.shape[0]numTestVecs=int(m*hoRatio)errorCount=0.0foriinrange(numTestVecs):classifierResult=classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3)print('the classifier came back with: %d, the real answer is: %d'%(classifierResult,datingLabels[i]))if(classifierResult!=datingLabels[i]):errorCount+=1.0print('the total error rate is: %f'%(errorCount/float(numTestVecs)))defclassifyPerson():resultList=['not at all','in small doses','in large doses']percentTats=float(raw_input('percentage of time spent playing video games?'))ffMiles=float(raw_input('frequent flier miles earned per year?'))iceCream=float(raw_input('liters of ice cream consumed per year?'))datingDataMat,datingLabels=file2matrmix('datingTestSet2.txt')normMat,ranges,minVals=autoNorm(datingDataMat)inArr=array([ffMiles,percentTats,iceCream])classifierResult=classify0((inArr-minVals)/ranges,normMat,datingLabels,3)print('you will probably like this person:',resultList[classifierResult-1])datingDataMat,datingLabels=file2matrmix('datingTestSet2.txt')classifyPerson()fig=plt.figure()ax=fig.add_subplot(111)ax.scatter(datingDataMat[:,1],datingDataMat[:,2],15.0*array(datingLabels),15.0*array(datingLabels))plt.show()K-最近邻算法总结
k 近邻算法是最简单有效的分类算法必须全部保存全部数据集如果训练数据集很大必须使用大量的存储空间同时由于必须对数据集中的每个数据计算距离值实际使用可能非常耗时。 k 近邻算法无法给出任何数据的基础结构信息我们无法知晓平均实例样本和典型实例样本具有神秘特征。
决策树
决策树 流程图正方形代表判断模块椭圆形代表终止模块从判断模块引出的左右箭头称作分支它可以到达另一个判断模块活着终止模块。 决策树 [优点]:计算复杂度不高输出结果易于理解对于中间值的缺失不敏感可以处理不相关特征数据。 决策树[缺点]:可能会产生过度匹配的问题。 决策树[适用数据类型]数值型和标称型。
决策树的一般流程
(1)收集数据可以使用任何方法。
(2)准备数据树构造算法只适用于标称型数据因此数值型数据必须离散化。
(3)分析数据可以使用任何方法构造树完成之后我们需要检验图形是否符合预期。
(4)训练算法构造树的数据结构。
(5)测试算法使用经验树计算错误率。
(6)使用算法使用于任何监督学习算法。信息增益
划分数据集的最大原则:将无序的数据集变的有序。 判断数据集的有序程度:信息增益熵计算每个特征值划分数据集后获得的信息增益获得信息增益最高的特征就是最好的选择。 信息增益[公式]: $$ H = - \sum_{i=1}^np(x_i)log_2p(x_i) $$
其中 n 是分类的数目。
python 决策树
计算给定数据集的信息熵
frommathimportlogdefcalcShannonEnt(dataSet):numEntries=len(dataSet)labelCounts={}forfeatVecindataSet:currentLabel=featVec[-1]ifcurrentLabelnotinlabelCounts.keys():labelCounts[currentLabel]=0labelCounts[currentLabel]+=1shannonEnt=0.0forkeyinlabelCounts:prob=float(labelCounts[key])/numEntriesshannonEnt-=prob*log(prob,2)returnshannonEntdefcreateDataSet():dataSet=[[1,1,'yes'],[1,1,'yes'],[1,0,'no'],[0,1,'no'],[0,1,'no'],]labels=['no surfacing','flippers']returndataSet,labelsmyDat,labels=createDataSet()print(myDat)print(labels)shannonEnt=calcShannonEnt(myDat)print(shannonEnt)划分数据集
importdtreedefsplitDataset(dataSet,axis,value):retDataSet=[]forfeatVecindataSet:iffeatVec[axis]==value:reducedFeatVec=featVec[:axis]reducedFeatVec.extend(featVec[axis+1:])retDataSet.append(reducedFeatVec)returnretDataSetmyData,labels=dtree.createDataSet()print(myData)retDataSet=splitDataset(myData,0,1)print(retDataSet)retDataSet=splitDataset(myData,0,0)print(retDataSet)选择最好的数据划分方式
defchooseBestFeatureToSplit(dataSet):numFeatures=len(dataSet[0])-1baseEntropy=dtree.calcShannonEnt(dataSet)bestInfoGain=0.0bestFeature=-1foriinrange(numFeatures):featList=[example[i]forexampleindataSet]uniqueVals=set(featList)newEntropy=0.0forvalueinuniqueVals:subDataSet=splitDataset(dataSet,i,value)prob=len(subDataSet)/float(len(dataSet))newEntropy+=prob*dtree.calcShannonEnt(subDataSet)infoGain=baseEntropy-newEntropyif(infoGain>bestInfoGain):bestInfoGain=infoGainbestFeature=ireturnbestFeaturemyData,labels=dtree.createDataSet()print('myData:',myData)bestFeature=chooseBestFeatureToSplit(myData)print('bestFeature:',bestFeature)结果输出
('myData:', [[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']])
('bestFeature:', 0)结果分析
运行结果表明第0个特征是最好用于划分数据集的特征即数据集的的第一个参数比如在该数据集中以第一个参数特征划分数据时第一个分组中有3个其中有一个被划分为no第二个分组中全部属于no;当以第二个参数分组时第一个分组中2个为yes,2个为no,第二个分类中只有一个no类。递归构建决策树
工作原理得到原始数据集然后基于最好的属性值划分数据集由于特征值可能多于 2 个因此可能存在大于 2 个分支的数据集划分在第一次划分后数据将被传向树分支的下一个节点在这个节点上我们可以再次划分数据。 递归条件程序遍历完所有划分数据集的属性或者没个分支下的所有实例都具有相同的分类。
构建递归决策树
importdtreeimportoperatordefmajorityCnt(classList):classCount={}forvoteinclassList:ifvotenotinclassCount.keys():classCount[vote]=0classCount[vote]+=1sortedClassCount=sorted(classCount.iteritems(),key=operator.itemgetter(1),reverse=True)returnsortedClassCount[0][0]defcreateTree(dataSet,labels):classList=[example[-1]forexampleindataSet]ifclassList.count(classList[0])==len(classList):returnclassList[0]iflen(dataSet[0])==1:returnmajorityCnt(classlist)bestFeat=chooseBestFeatureToSplit(dataSet)bestFeatLabel=labels[bestFeat]myTree={bestFeatLabel:{}}del(labels[bestFeat])featValues=[example[bestFeat]forexampleindataSet]uniqueVals=set(featValues)forvalueinuniqueVals:subLabels=labels[:]myTree[bestFeatLabel][value]=createTree(splitDataset(dataSet,bestFeat,value),subLabels)returnmyTreemyData,labels=dtree.createDataSet()print('myData:',myData)myTree=createTree(myData,labels)print('myTree:',myTree)结果输出
('myData:', [[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']])
('myTree:', {'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}})结果分析
myTree 包含了树结构信息的前套字典第一个关键字no surfacing是第一个划分数据集的特征名称值为另一个数据字典第二个关键字是no surfacing特征划分的数据集是no surfacing的字节点如果值是类标签那么该节点为叶子节点如果值是另一个数据字典那么该节点是个判断节点如此递归。测试算法:使用决策树执行分类
使用决策树的分类函数
importtreeplotterimportdtreedefclassify(inputTree,featLabels,testVec):firstStr=inputTree.keys()[0]secondDict=inputTree[firstStr]featIndex=featLabels.index(firstStr)forkeyinsecondDict.keys():iftestVec[featIndex]==key:iftype(secondDict[key]).__name__=='dict':classLabel=classify(secondDict[key],featLabels,testVec)else:classLabel=secondDict[key]returnclassLabelmyDat,labels=dtree.createDataSet()print(labels)myTree=myTree=treeplotter.retrieveTree(0)print(myTree)print('classify(myTree,labels,[1,0]):',classify(myTree,labels,[1,0]))print('classify(myTree,labels,[1,1]):',classify(myTree,labels,[1,1]))结果输出
['no surfacing', 'flippers']
{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}, 3: 'maybe'}}
('classify(myTree,labels,[1,0]):', 'no')
('classify(myTree,labels,[1,1]):', 'yes')存储决策树
由于决策树的构造十分耗时所以用创建好的决策树解决分类问题可以极大的提高效率。因此需要使用 python 模块 pickle 序列化对象序列化对象可以在磁盘上保存对象并在需要的地方读取出来任何对象都可以执行序列化操作。
# 使用pickle模块存储决策树importpickledefstoreTree(inputTree,filename):fw=open(filename,'w')pickle.dump(inputTree,fw)fw.close()defgrabTree(filename):fr=open(filename)returnpickle.load(fr)决策树算法小结
决策树分类器就像带有终止块的流程图终止块表示分类结果。首先我们需要测量集合数据中的熵即不一致性然后寻求最优方案划分数据集直到数据集中的所有数据属于同一分类。决策树的构造算法有很多版本本文中用到的是 ID3 最流行的是 C4.5 和 CART。
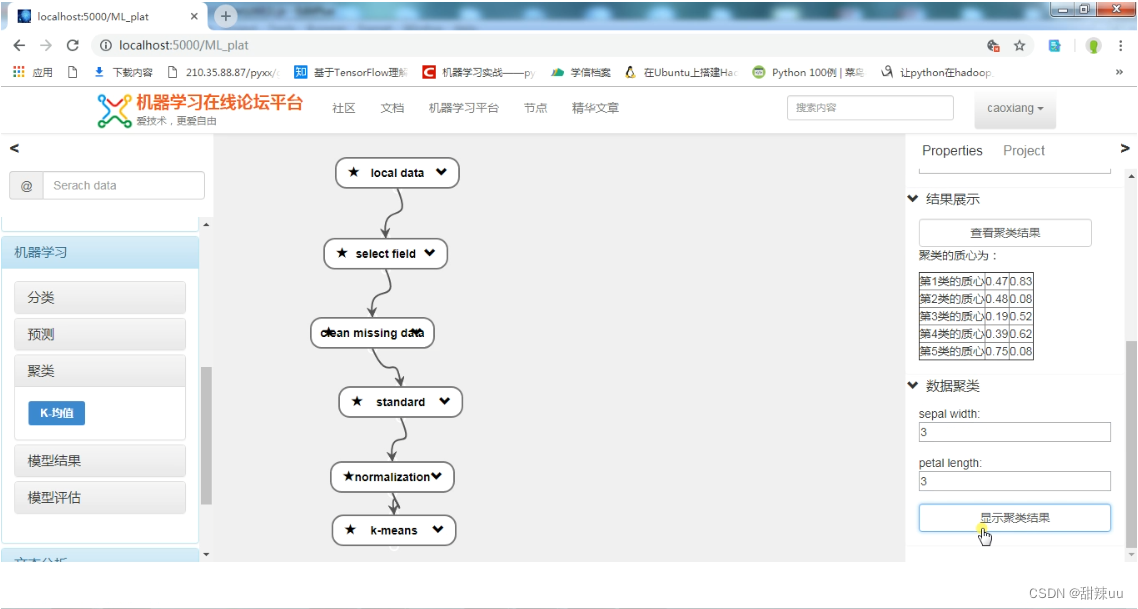
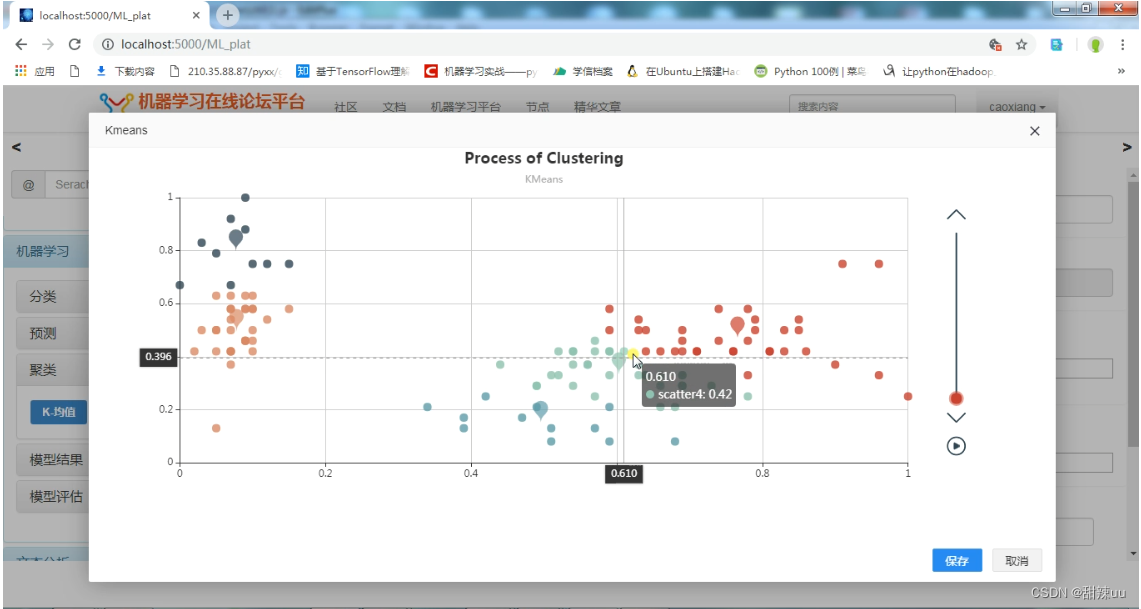
结果展示Kmeans