

【MPP数据库】StarRocks分区、分桶探索与实践
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
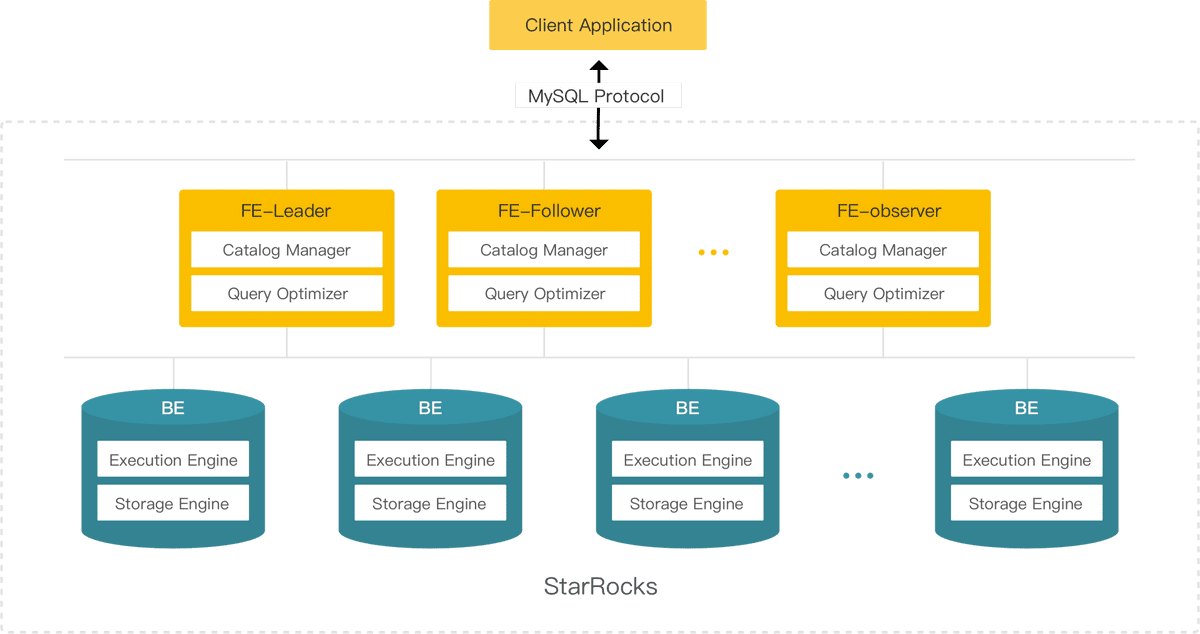
1.先学习一下StarRocks的架构图
2.基本概念
2.1 Row & Column
一张表包括行Row和列Column。Row 即用户的一行数据。Column 用于描述一行数据中不同的字段。
Column 可以分为两大类Key 和 Value。从业务角度看Key 和 Value 可以分别对应维度列和指标列。从聚合模型的角度来说Key 列相同的行会聚合成一行。其中 Value 列的聚合方式由用户在建表时指定。
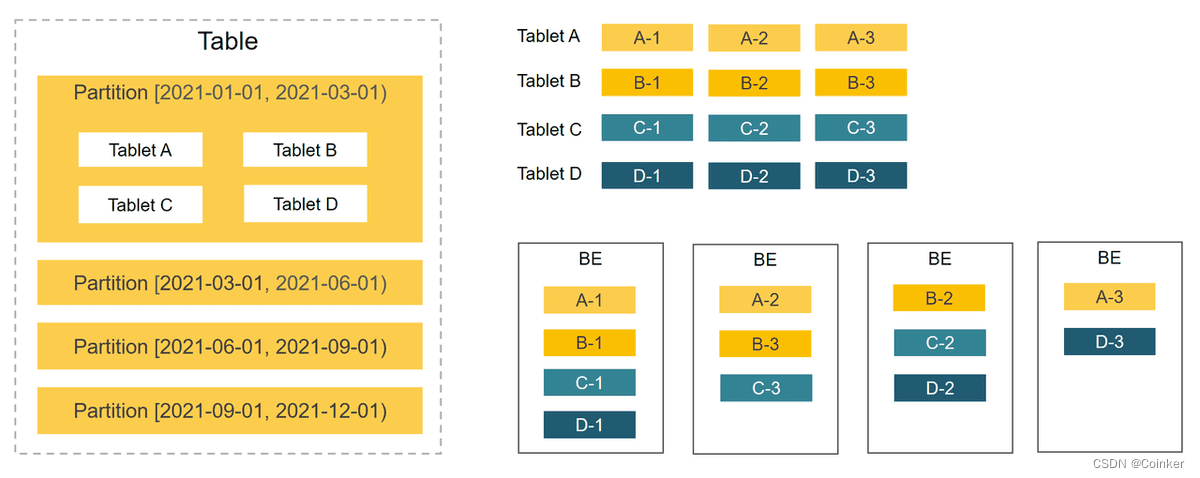
2.2 Tablet & Partition
在 StarRocks 的存储引擎中用户数据被水平划分为若干个数据分片Tablet也称作数据分桶。每个 Tablet 包含若干数据行各个 Tablet 之间的数据没有交集并且在物理上是独立存储的。
多个 Tablet 在逻辑上归属于不同的分区Partition。一个 Tablet 只属于一个 Partition而一个 Partition 包含若干个 Tablet。因为 Tablet 在物理上是独立存储的所以可以视为 Partition 在物理上也是独立。Tablet 是数据移动、复制等操作的最小物理存储单元。
若干个 Partition 组成一个 Table。Partition 可以视为是逻辑上最小的管理单元数据的导入与删除都可以或仅能针对一个 Partition 进行。
3.数据模型如何选择
3.1 DUPLICATE KEY 模型
DUPLICATE KEY 只用于排序相同 DUPLICATE KEY 的记录会同时存在。DUPLICATE KEY 模型适用于数据无需提前聚合的分析业务。
3.2 小时数据目前是否需要聚合是否需要采用AGGREGATE KEY 模型
目前数仓已经聚合了一层我们这边暂不聚合看看查询效率后期在考虑是否需要优化。
4. 分区如何选择
4.1 按天分区还是按月分区
以菜品日表为例子每天4000w数据量8g, 一个月12亿数据量240g一年144亿数据量2.8T因此要按天分区。
4.2 如何动态分区
由于天数在一直增加所以分区也是不断增加因此应该选择动态分区一年365个分区。
需要2+x年数据因此一个表大概是730 ~ 1095个分区。
关于动态分区字段的含义可以参考StarRocks动态分区
5. 分桶如何选择
5.1 要分多少个桶
官方建议压缩后磁盘上每个分桶数据文件大小在 100 MB 至 1 GB 左右。
LZ4压缩比大概4:1
举例子
方案一8g数据、分3个桶 、每个桶2.7g 、压缩后700m
方案二8g数据、分5个桶、每个桶1.6g、压缩后400m
方案三8g数据、分13个桶、每个桶600m、压缩后150m。
上面三种方案均可满足官方要求的压缩后数据大小由于每个桶StarRocks会用一个线程去计算因此分13个桶理论上可以发挥StarRocks的计算分布式计算能力充分压榨CPU核心。
5.2 对哪些字段进行分桶Hash同时要保证数据的离散性
方案一只对groupID进行hash分桶离散性较差
方案二对groupID和shopID进行hash分桶数据相对离散
方案三对groupID、brandID、shopID进行hash分桶数据也相对离散
6 总结
分区和分桶不是绝对的要根据具体业务和场景来规划。