

零代码编程:用ChatGPT批量自动下载archive.org上的音频书-CSDN博客
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
http://archive.org 是一个神奇的网站可以下载各种古旧的软件、书籍、音频、视频还可以搜索各个网站的历史网页。
比如说一些儿童故事音频就可以在http://archive.org下载到可以用来做英语听力启蒙用。
举个例子要下载https://archive.org/details/107frogandtoadallyear_202004这个网页上的所有音频内容该怎么办呢
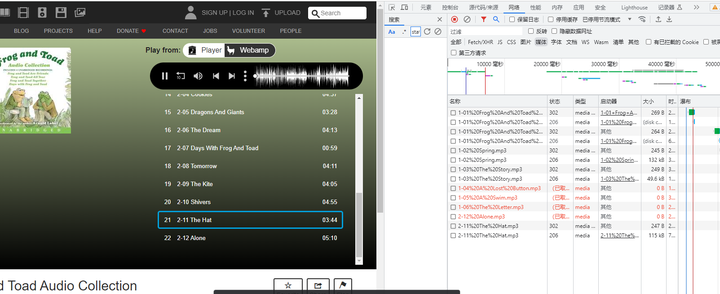
右击检查网页点击网络然后选择媒体然后可以看到正在播放的音频文件右击复制链接如下
https://archive.org/details/107frogandtoadallyear_202004/2-12+Alone.mp3
查看网页源代码搜索某一个音频文件标题Alone.mp3

找到了音频文件的地址
<button type="button" data-event-click-tracking="TrackList|Item" class="track selected" data-track-number="21">
<!--?lit$3345567357$--><span class="track-number"><!--?lit$3345567357$-->22</span>
<span class="track-title"><!--?lit$3345567357$-->2-12 Alone
<!--?lit$3345567357$-->
</span>
<span class="track-length">
<!--?lit$3345567357$-->
<!--?lit$3345567357$-->05:10
</span>
</button>
接下来就好办了在ChatGPT中输入提示词
你是一个Python编程专家现在要完成一个下载网页中音频的任务具体步骤如下
打开网站https://archive.org/details/107frogandtoadallyear_202004
解析源代码找出所有itemprop="hasPart"的div元素定位其中itemprop="associatedMedia" 的link元素
提取link元素的href值作为音频下载的URL地址
多线程下载这个音频文件保存到电脑D盘的文件夹Frog and Toad Audio Collection
注意每一步都要输出信息
要有反爬虫措施比如下载一个音频文件后暂停3秒

音频下载的Python源代码
import requests
from bs4 import BeautifulSoup
import os
import time
import threading
class Downloader(threading.Thread):
def __init__(self, url, path):
threading.Thread.__init__(self)
self.url = url
self.path = path
def run(self):
print(f'Starting download {self.path}')
r = requests.get(self.url, stream=True)
with open(self.path, 'wb') as f:
for chunk in r.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
print(f'Finished download {self.path}')
time.sleep(3) # pause for 3 seconds
def get_audio_links(url):
r = requests.get(url)
soup = BeautifulSoup(r.text, 'html.parser')
audio_links = []
for div in soup.find_all('div', itemprop='hasPart'):
link = div.find('link', itemprop='associatedMedia')
if link:
audio_links.append(link['href'])
return audio_links
def download_audios(url, directory):
if not os.path.exists(directory):
os.makedirs(directory)
audio_links = get_audio_links(url)
downloaders = []
for i, audio_link in enumerate(audio_links):
path = os.path.join(directory, f'audio{i}.mp3')
downloader = Downloader(audio_link, path)
downloader.start()
downloaders.append(downloader)
for downloader in downloaders:
downloader.join()
url = 'https://archive.org/details/107frogandtoadallyear_202004'
directory = 'D:\\Frog and Toad Audio Collection'
download_audios(url, directory)
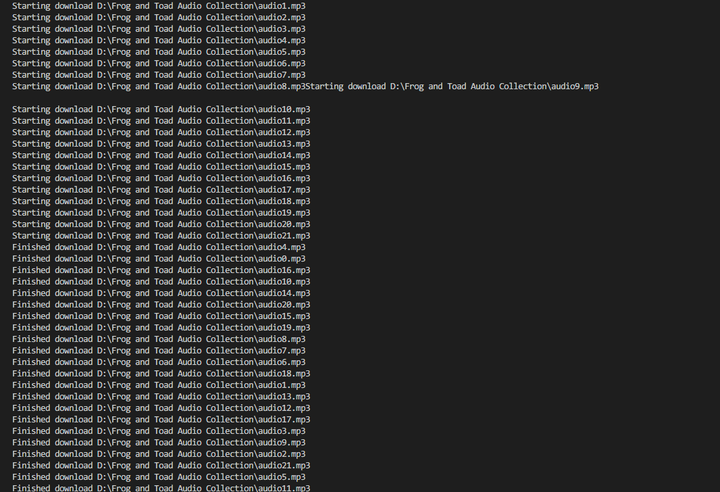
程序运行很快就把网页中的音频下载完了。