

《收获,不止Oracle》表的设计之五朵金花
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
表设计主要强调什么场合该选择什么技术没有最高级的技术只有最适合的技术。

1.表的特性
普通堆表的不足之处
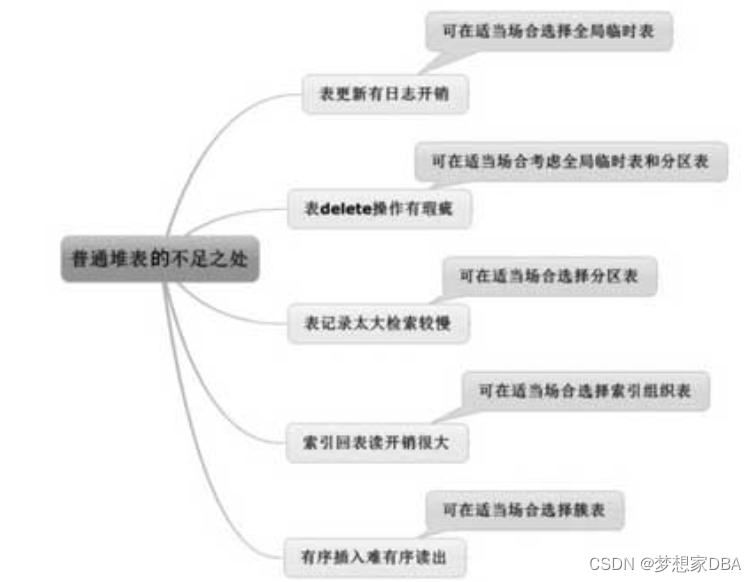
1.查看产生多少日志
[oracle@oracle-db-19c ~]$ sqlplus / as sysdba
SQL*Plus: Release 19.0.0.0.0 - Production on Wed Jan 4 14:27:13 2023
Version 19.3.0.0.0
Copyright (c) 1982, 2019, Oracle. All rights reserved.
Connected to:
Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production
Version 19.3.0.0.0
SQL> alter session set container=PDB1;
Session altered.
SQL> select a.name,b.value
2 from v$statname a,v$mystat b
3 where a.statistic#=b.statistic#
4 and a.name='redo size';
NAME
--------------------------------------------------------------------------------
VALUE
----------
redo size
0
SQL>[oracle@MaxwellDBA ~]$ sqlplus / as sysdba
SQL*Plus: Release 19.0.0.0.0 - Production on Wed Jan 4 15:25:31 2023
Version 19.3.0.0.0
Copyright (c) 1982, 2019, Oracle. All rights reserved.
Connected to:
Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production
Version 19.3.0.0.0
sys@cdb$root:orclcdb> alter session set container=ORCLPDB1;
Session altered.
sys@cdb$root:orclcdb> select a.name,b.value
2 from v$statname a,v$mystat b
3 where a.statistic#=b.statistic#
4 and a.name='redo size';
NAME VALUE
---------------------------------------------------------------- ----------
redo size 0
1 row selected.
sys@cdb$root:orclcdb>
实验准备工作创建观察redo的视图
[oracle@MaxwellDBA ~]$ sqlplus / as sysdba
SQL*Plus: Release 19.0.0.0.0 - Production on Wed Jan 4 15:25:31 2023
Version 19.3.0.0.0
Copyright (c) 1982, 2019, Oracle. All rights reserved.
Connected to:
Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production
Version 19.3.0.0.0
sys@cdb$root:orclcdb> alter session set container=ORCLPDB1;
Session altered.
sys@cdb$root:orclcdb> select a.name,b.value
2 from v$statname a,v$mystat b
3 where a.statistic#=b.statistic#
4 and a.name='redo size';
NAME VALUE
---------------------------------------------------------------- ----------
redo size 0
1 row selected.
sys@cdb$root:orclcdb>
观察删除记录产生了多少redo
SQL> select * from v_redo_size;
NAME
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
VALUE
----------
redo size
11871068
SQL> delete from t;
73262 rows deleted.
SQL> select * from v_redo_size;
NAME
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
VALUE
----------
redo size
22920220
SQL> select 22920220 - 11871068 from dual;
22920220-11871068
-----------------
11049152
SQL> 删除语句产生了差不多11M的日志量
观察插入记录产生了多少redo
SQL>
SQL> insert into t select * from dba_objects;
73264 rows created.
SQL> select * from v_redo_size;
NAME
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
VALUE
----------
redo size
34265784
SQL> select 34265784 - 22920220 from dual;
34265784-22920220
-----------------
11345564
SQL> 观察更新记录产生了多少redo
SQL>
SQL> update t set object_id=rownum;
73264 rows updated.
SQL> select * from v_redo_size;
NAME
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
VALUE
----------
redo size
47178732
SQL> select 47178732 - 34265784 from dual;
47178732-34265784
-----------------
12912948
SQL> 更新语句产生了差不多12M的redo
三个试验说明了对表的更新操作无论是删除、插入还是修改都会产生日志.
虽说安全第一不过在某些特定的场合某些表的记录只是作为中间结果临时运算而根本无须永久保留这些表无须写日志那就既高效又安全了
delete无法释放空间
实际上工作中不少性能问题都和delete操作有关。
原因是delete是最耗性能的操作产生的undo最多而且因为undo需要redo来保护的缘故delete产生的redo量也最大。所以不少性能问题都和delete操作有关。
观察未删除表时产生的逻辑读
SQL> show user;
USER is "MAXWELLPAN"
SQL> drop table t purge;
Table dropped.
SQL>
SQL> create table t as select * from dba_objects;
Table created.
SQL> set autotrace on
SQL> select count(*) from t;
COUNT(*)
----------
73263
Execution Plan
----------------------------------------------------------
Plan hash value: 2966233522
-------------------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)| Time |
-------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 397 (1)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | | |
| 2 | TABLE ACCESS FULL| T | 73263 | 397 (1)| 00:00:01 |
-------------------------------------------------------------------
Statistics
----------------------------------------------------------
75 recursive calls
0 db block gets
1546 consistent gets
1422 physical reads
0 redo size
552 bytes sent via SQL*Net to client
384 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
20 sorts (memory)
0 sorts (disk)
1 rows processed
SQL>用delete命令删除t所有记录后逻辑读发生了微小的变化
SQL>
SQL> set autotrace off
SQL> delete from t;
73263 rows deleted.
SQL> commit;
Commit complete.
SQL> set autotrace on
SQL> select count(*) from t;
COUNT(*)
----------
0
Execution Plan
----------------------------------------------------------
Plan hash value: 2966233522
-------------------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)| Time |
-------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 397 (1)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | | |
| 2 | TABLE ACCESS FULL| T | 73263 | 397 (1)| 00:00:01 |
-------------------------------------------------------------------
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
1426 consistent gets
0 physical reads
0 redo size
549 bytes sent via SQL*Net to client
384 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> 使用truncate命令清空表后逻辑读终于大幅度下降了。
SQL>
SQL> set autotrace off
SQL> truncate table t;
Table truncated.
SQL> set autotrace on
SQL> select count(*) from t;
COUNT(*)
----------
0
Execution Plan
----------------------------------------------------------
Plan hash value: 2966233522
-------------------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)| Time |
-------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 397 (1)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | | |
| 2 | TABLE ACCESS FULL| T | 73263 | 397 (1)| 00:00:01 |
-------------------------------------------------------------------
Statistics
----------------------------------------------------------
1 recursive calls
1 db block gets
3 consistent gets
0 physical reads
104 redo size
549 bytes sent via SQL*Net to client
384 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL>delete 删除并不能释放空间虽然delete将很多块的记录删除了但是空块依然保留Oracle在查询时依然会去查询这些空块。而truncate是一种释放高水平位的动作这些空块被回收空间也被释放了。
不过truncate显然不能替代delete因为truncate是一种DDL操作而非DML操作truncate后面是不能带条件的即truncate table t where…是不允许的。但是如果表中这些where条件能形成有效的分区Oracle是支持在分区表中做truncate分区的命令大致为 alter table t truncate partition '分区名'如果where 条件就是分区条件那等同于换个角度实现了 truncate table t where…的功能。
这就是分区表最实用的功能之一了高效地清理数据释放空间续章节中详细描述分区表的特性。
表记录太多检索较慢
有没有什么好方法能提升检索的速度呢主要思路就是缩短访问路径来完成同样的更新查询操作。简单地说完成同样的需求访问块的个数越少越好。Oracle 为了尽可能减少访问路径提供了两种主要技术一种是索引技术另一种则是分区技术。
首先说索引这是Oracle中最重要也最实用的技术之一。在本例中如果created>=xxx and created <=xxx返回的记录非常少或者说和T表的总记录相比非常少则在created列建索引能极大提升该语句的效率。比如我们创建了一个idx_t索引在用该SQL语句查询时首先会访问idx_t这个新建出来的索引段然后通过索引段和表段的映射关系迅速从表中获取行列的信息并返回结果。具体技术细节将会在后续的索引章节中做详细的描述大家要记得索引本身也是一把双刃剑既能给数据库开发应用带来极大的帮助也会给数据库带来不小的灾难。
减少访问路径的第二种技术就是分区。我们把普通表T改造为分区表以created 这个时间列为分区字段从2010年1月到2012年12月按月建36个分区。早先的T表就有一个T段现在情况发生了变化从1个大段分解成了36个小段分别存储了2010年1月到2012年12月的信息。此时假如created>=xxx and created <=xxx 这个时间跨度正好落在2012年11月那Oracle的检索只要完成一个小段的遍历即可假设这36个小段比较均匀我们可大致将其理解为访问量只有原来的三十六分之一大幅减少了访问路径从而高效地提升了性能。
索引本身也是一把双刃剑既能给数据库开发应用带来极大的帮助也会给数据库带来不小的灾难。
分区表除了之前描述的具有高效清理数据的功能外还有减少访问路径的神奇本领。
索引回表读开销很大
观察TABLE ACCESS BY INDEX ROWID 产生的开销
SQL>
SQL> show user;
USER is "MAXWELLPAN"
SQL> drop table t purge;
Table dropped.
SQL> create table t as select * from dba_objects where rownum<=200;
Table created.
SQL> create index idx_obj_id on t(object_id);
Index created.
SQL> set linesize 1000
SQL> set autotrace traceonly
SQL> select * from t where object_id<=10;
9 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 3784017797
--------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 9 | 927 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| T | 9 | 927 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_OBJ_ID | 9 | | 1 (0)| 00:00:01 |
--------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OBJECT_ID"<=10)
Statistics
----------------------------------------------------------
51 recursive calls
126 db block gets
54 consistent gets
3 physical reads
25504 redo size
3584 bytes sent via SQL*Net to client
397 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
9 rows processed
SQL>一般来说根据索引来检索记录会有一个先从索引中找到记录再根据索引列上的ROWID定位到表中从而返回索引列以外的其他列的动作这就是TABLE ACCESS BY INDEX ROWID。
观察消除TABLE ACCESS BY INDEX ROWID后的开销情况
SQL>
SQL> show user;
USER is "MAXWELLPAN"
SQL> select object_id from t where object_id <= 10;
9 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 188501954
-------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 9 | 36 | 1 (0)| 00:00:01 |
|* 1 | INDEX RANGE SCAN| IDX_OBJ_ID | 9 | 36 | 1 (0)| 00:00:01 |
-------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("OBJECT_ID"<=10)
Statistics
----------------------------------------------------------
219 recursive calls
0 db block gets
179 consistent gets
0 physical reads
0 redo size
661 bytes sent via SQL*Net to client
628 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
11 sorts (memory)
0 sorts (disk)
9 rows processed
SQL> 因为语句由 select * from t where object_id<=10改写为 select object_id from t where object_id<=10了不用从索引中回到表中获取索引列以外的其他列了。
有序插入却难有序读出
测试表记录顺序插入却难保证顺序读出
[oracle@oracle-db-19c ~]$ sqlplus / as sysdba
SQL*Plus: Release 19.0.0.0.0 - Production on Thu Jan 5 10:11:06 2023
Version 19.3.0.0.0
Copyright (c) 1982, 2019, Oracle. All rights reserved.
Connected to:
Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production
Version 19.3.0.0.0
SQL> connect maxwellpan/maxwellpan@PDB1;
Connected.
SQL>
SQL> show user
USER is "MAXWELLPAN"
SQL>
SQL> drop table t purge;
Table dropped.
SQL> create table t
2 (a int,
3 b varchar2(4000) default rpad('*',4000,'*'),
4 c varchar2(4000) default rpad('*',3000,'*'));
Table created.
SQL> insert into t(a) values(1);
insert into t(a) values(2);
1 row created.
SQL> SQL>
1 row created.
SQL> SQL> SQL> insert into t(a) values(3);
1 row created.
SQL> select A from t;
A
----------
1
2
3
SQL> delete from t where a=2;
1 row deleted.
SQL> insert into t(a) values(4);
1 row created.
SQL> commit;
Commit complete.
SQL> select A from t;
A
----------
1
4
3
SQL> 比较有无order by 语句在执行计划、开销上的差异
可以观察到有排序的操作的统计信息模块有一个1 sortsmemory表示发生了排序执行计划中也有SORT ORDER BY关键字不过最重要的是没排序的操作代价为3有排序的操作代价为4性能上是有差异的这在数量大的时候将会非常明显。
关于order by 避免排序的方法有两种思路。第一种思路是在order by 的排序列建索引为什么可以消除排序呢这就当成一个悬念在后续介绍索引的章节中给大家揭秘。第二种方法就是将普通表改造为有序散列聚簇表这样可以保证顺序插入order by 展现时无须再有排序动作
SQL>
SQL> show user;
USER is "MAXWELLPAN"
SQL> set linesize 1000
SQL> set autotrace traceonly
SQL> select A from t;
Execution Plan
----------------------------------------------------------
Plan hash value: 1601196873
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 3 | 39 | 3 (0)| 00:00:01 |
| 1 | TABLE ACCESS FULL| T | 3 | 39 | 3 (0)| 00:00:01 |
--------------------------------------------------------------------------
Note
-----
- dynamic statistics used: dynamic sampling (level=2)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
7 consistent gets
0 physical reads
0 redo size
605 bytes sent via SQL*Net to client
377 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
3 rows processed
SQL>
SQL> select A from t order by A;
Execution Plan
----------------------------------------------------------
Plan hash value: 961378228
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 3 | 39 | 4 (25)| 00:00:01 |
| 1 | SORT ORDER BY | | 3 | 39 | 4 (25)| 00:00:01 |
| 2 | TABLE ACCESS FULL| T | 3 | 39 | 3 (0)| 00:00:01 |
---------------------------------------------------------------------------
Note
-----
- dynamic statistics used: dynamic sampling (level=2)
Statistics
----------------------------------------------------------
26 recursive calls
0 db block gets
10 consistent gets
0 physical reads
0 redo size
605 bytes sent via SQL*Net to client
609 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
1 sorts (memory)
0 sorts (disk)
3 rows processed
SQL> 3.奇特的全局临时表

1.分析全局临时表的类型
全局临时表分为两种类型一种是基于会话的全局临时表on commit preserve rows一种是基于事务的全局临时表on commit delete rows
创建基于事务和会话的全局临时表
SQL>
SQL> show user
USER is "MAXWELLPAN"
SQL>
SQL> drop table t_tmp_session purge;
drop table t_tmp_session purge
*
ERROR at line 1:
ORA-00942: table or view does not exist
SQL> drop table t_tmp_transaction purge;
drop table t_tmp_transaction purge
*
ERROR at line 1:
ORA-00942: table or view does not exist
SQL> create global temporary table t_tmp_session on commit preserve rows as select * from dba_objects where 1=2;
Table created.
SQL>
SQL> col table_name format a50
SQL> col tem format a50
SQL> col duration format a50
SQL> select table_name,temporary,duration from user_tables where table_name='T_TMP_SESSION';
TABLE_NAME TEM DURATION
-------------------------------------------------- --- --------------------------------------------------
T_TMP_SESSION Y SYS$SESSION
SQL> create global temporary table t_tmp_transaction on commit delete rows as select * from dba_objects where 1=2;
Table created.
SQL> select table_name,temporary,duration from user_tables where table_name='T_TMP_TRANSACTION';
TABLE_NAME TEM DURATION
-------------------------------------------------- --- --------------------------------------------------
T_TMP_TRANSACTION Y SYS$TRANSACTION
SQL> 上述命令完成了基于会话的全局临时表 T_TMP_SESSION 和基于事务的全局临时表T_TMP_TRANSACTION。接下来大家肯定想知道DML操作针对全局临时表产生的日志和针对普通表有什么不同.
2.观察各类DML的redo量
分别观察两种全局临时表针对各类DML语句产生的redo量
create or replace view v_redo_size as
select a.name,b.value
from v$statname a,v$mystat b
where a.statistic#=b.statistic#
and a.name='redo size';SQL>
SQL> show user;
USER is "MAXWELLPAN"
SQL> select * from v_redo_size;
NAME VALUE
-------------------- ----------
redo size 240504
SQL> insert into t_tmp_transaction select * from dba_objects;
73266 rows created.
SQL> select * from v_redo_size;
NAME VALUE
-------------------- ----------
redo size 774580
SQL> select 774580-240504 from dual;
774580-240504
-------------
534076
SQL> insert into t_tmp_session select * from dba_objects;
73266 rows created.
SQL> select * from v_redo_size;
NAME VALUE
-------------------- ----------
redo size 1308488
SQL> select 1308488 - 774580 from dual;
1308488-774580
--------------
533908
SQL> update t_tmp_transaction set object_id=rownum;
73266 rows updated.
SQL> select * from v_redo_size;
NAME VALUE
-------------------- ----------
redo size 7788968
SQL> select 7788968 - 1308488 from dual;
7788968-1308488
---------------
6480480
SQL> update t_tmp_session set object_id=rownum;
73266 rows updated.
SQL> select * from v_redo_size;
NAME VALUE
-------------------- ----------
redo size 12430324
SQL> select 12430324 - 7788968 from dual;
12430324-7788968
----------------
4641356
SQL> delete from t_tmp_session;
73266 rows deleted.
SQL> select * from v_redo_size;
NAME VALUE
-------------------- ----------
redo size 23330180
SQL> select 23330180 - 12430324 from dual;
23330180-12430324
-----------------
10899856
SQL> delete from t_tmp_transaction;
73266 rows deleted.
SQL> select * from v_redo_size;
NAME VALUE
-------------------- ----------
redo size 34230036
SQL> select 34230036 - 23330180 from dual;
34230036-23330180
-----------------
10899856
SQL> 全局临时表和普通表产生日志情况的比较
SQL>
SQL> drop table t purge;
Table dropped.
SQL> show user;
USER is "MAXWELLPAN"
SQL> create table t as select * from dba_objects where 1=2;
Table created.
SQL> select * from v_redo_size;
NAME VALUE
-------------------- ----------
redo size 34301144
SQL> insert into t select * from dba_objects;
73266 rows created.
SQL> select * from v_redo_size;
NAME VALUE
-------------------- ----------
redo size 45974392
SQL> select 45974392 - 34301144 from dual;
45974392-34301144
-----------------
11673248
SQL> update t set object_id=rownum;
73266 rows updated.
SQL> select * from v_redo_size;
NAME VALUE
-------------------- ----------
redo size 57139632
SQL> select 57139632 - 45974392 from dual;
57139632-45974392
-----------------
11165240
SQL> delete from t;
73266 rows deleted.
SQL> select * from v_redo_size;
NAME VALUE
-------------------- ----------
redo size 68186560
SQL> select 68186560 - 57139632 from dual;
68186560-57139632
-----------------
11046928
SQL> 通过简单的比较我们即可得出结论无论插入、更新还是删除操作普通表产生的日志都比全局临时表要多。
DML操作针对全局临时表来说只是产生的日志要少得多而不是不会产生。
3.全局临时表的两大重要特性
1.高效删除记录
全局临时表有两个重要的特点。一是高效删除记录基于事务的全局临时表 COMMIT 或者 SESSION 连接退出后临时表记录自动删除基于会话的全局临时表则是SESSION连接退出后临时表记录自动删除都无须我们手动去操作。二是针对不同会话数据独立不同的SESSION访问全局临时表看到的结果不同。
基于事务的全局临时表的高效删除
SQL>
SQL> select count(*) from t_tmp_transaction;
COUNT(*)
----------
0
SQL> select * from v_redo_size;
NAME VALUE
-------------------- ----------
redo size 68186560
SQL> insert into t_tmp_transaction select * from dba_objects;
73266 rows created.
SQL> select * from v_redo_size;
NAME VALUE
-------------------- ----------
redo size 68720580
SQL> select 68720580 - 68186560 from dual;
68720580-68186560
-----------------
534020
SQL> commit;
Commit complete.
SQL> select * from v_redo_size;
NAME VALUE
-------------------- ----------
redo size 68720756
SQL> select count(*) from t_tmp_transaction;
COUNT(*)
----------
0
SQL>
SQL> select 68720756 - 68720580 from dual;
68720756-68720580
-----------------
176
SQL> ---commit 方式删除全局临时表记录所产生的日志量是176B
SQL>基于会话的全局临时表COMMIT并不清空记录
SQL>
SQL> show user;
USER is "MAXWELLPAN"
SQL> select * from v_redo_size;
NAME VALUE
-------------------- ----------
redo size 68720756
SQL> insert into t_tmp_session select * from dba_objects;
73266 rows created.
SQL> select * from v_redo_size;
NAME VALUE
-------------------- ----------
redo size 69268792
SQL> select 69268792 - 68720756 from dual;
69268792-68720756
-----------------
548036
SQL> commit;
Commit complete.
SQL> select count(*) from t_tmp_session;
COUNT(*)
----------
73266
SQL> select * from v_redo_size;
NAME VALUE
-------------------- ----------
redo size 69268940
SQL> select 69268940 - 69268792 from dual;
69268940-69268792
-----------------
148
SQL> 退出基于事务的全局临时表后再登入观察记录情况
SQL> exit
Disconnected from Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production
Version 19.3.0.0.0
[oracle@oracle-db-19c ~]$ sqlplus / as sysdba
SQL*Plus: Release 19.0.0.0.0 - Production on Thu Jan 5 11:22:30 2023
Version 19.3.0.0.0
Copyright (c) 1982, 2019, Oracle. All rights reserved.
Connected to:
Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production
Version 19.3.0.0.0
SQL> connect maxwellpan/maxwellpan@PDB1;
Connected.
SQL> show user;
USER is "MAXWELLPAN"
SQL> select count(*) from t_tmp_session;
COUNT(*)
----------
0
SQL> 如果全局临时表在程序的一次调用执行过程中需要多次清空记录再插入记录就要考虑用基于事务的这时COMMIT可以把结果快速清理了否则用delete效率低下。如果不存在这种情况就用基于会话的更简单连COMMIT的动作都省了。
一般来说基于会话的全局临时表的应用会更多一些少数比较复杂的应用涉及一次调用中需要清空记录再插入等复杂动作时才考虑用基于事务的全局临时表。
2.不同会话独立
基于全局临时表的会话独立性的观察——第1个会话
SQL> show user;
USER is "MAXWELLPAN"
SQL> select * from v$mystat where rownum=1;
SID STATISTIC# VALUE CON_ID
---------- ---------- ---------- ----------
18 0 0 3
SQL> select * from t_tmp_session;
no rows selected
SQL> insert into t_tmp_session select * from dba_objects;
73266 rows created.
SQL> commit;
Commit complete.
SQL> select count(*) from t_tmp_session;
COUNT(*)
----------
73266
SQL> 基于全局临时表的会话独立性的观察——第2个会话
[root@oracle-db-19c ~]# su - oracle
[oracle@oracle-db-19c ~]$
[oracle@oracle-db-19c ~]$ sqlplus / as sysdba
SQL*Plus: Release 19.0.0.0.0 - Production on Thu Jan 5 11:30:28 2023
Version 19.3.0.0.0
Copyright (c) 1982, 2019, Oracle. All rights reserved.
Connected to:
Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production
Version 19.3.0.0.0
SQL> connect maxwellpan/maxwellpan@PDB1;
Connected.
SQL> show user;
USER is "MAXWELLPAN"
SQL> select * from v$mystat where rownum=1;
SID STATISTIC# VALUE CON_ID
---------- ---------- ---------- ----------
143 0 0 3
SQL> select count(*) from t_tmp_session;
COUNT(*)
----------
0
SQL> insert into t_tmp_session select * from dba_objects where rownum=1;
1 row created.
SQL> commit;
Commit complete.
SQL> select count(*) from t_tmp_session;
COUNT(*)
----------
1
SQL>
这是一个神奇的特性结合高效删除灵活应用这两个特性将会给相关工作带来巨大的帮助。大家将会在后续的课程中感受到。
4.神通广大的分区表
学习表设计过程中极其重要的一项技术分区表设计

表记录太大检索慢和delete 删除有瑕疵这两个缺点正好可以被分区表的分区消除和高效清理分区数据这两大特点给弥补了
“全民搜索”的时代语法和知识点都不是问题搜不到的是体系是重点是思想。
4.1分区表的类型及原理
分区表的类型有范围分区、列表分区、HASH分区及组合分区4种其中范围分区应用最为广泛需要重点学习和掌握。而列表分区次之在某些场合下也可以考虑使用组合分区在Oracle 11g以前组合分区的组合方式比较有限。相对而言HASH分区在应用中适用的场景并不广泛使用的频率比较低.
技术其实并不难最难的是如何选择。
分区表的使用先了解分区表的建立方法
1.范围分区
记住范围分区最常见的是按时间列进行分区。
SQL>
SQL> show user;
USER is "MAXWELLPAN"
SQL> drop table range_part_tab purge;
drop table range_part_tab purge
*
ERROR at line 1:
ORA-00942: table or view does not exist
SQL> create table range_part_tab (id number, deal_date date, area_code number,contents varchar2(4000))
2 partition by range(deal_date)
3 (
4 partition p1 values less than (TO_DATE('2023-02-01','YYYY-MM-DD')),
5 partition p2 values less than (TO_DATE('2023-03-01','YYYY-MM-DD')),
6 partition p3 values less than (TO_DATE('2023-04-01','YYYY-MM-DD')),
7 partition p4 values less than (TO_DATE('2023-05-01','YYYY-MM-DD')),
8 partition p5 values less than (TO_DATE('2023-06-01','YYYY-MM-DD')),
9 partition p6 values less than (TO_DATE('2023-07-01','YYYY-MM-DD')),
10 partition p7 values less than (TO_DATE('2023-08-01','YYYY-MM-DD')),
11 partition p8 values less than (TO_DATE('2023-09-01','YYYY-MM-DD')),
12 partition p9 values less than (TO_DATE('2023-10-01','YYYY-MM-DD')),
13 partition p10 values less than (TO_DATE('2023-11-01','YYYY-MM-DD')),
14 partition p11 values less than (TO_DATE('2023-12-01','YYYY-MM-DD')),
15 partition p12 values less than (TO_DATE('2024-01-01','YYYY-MM-DD')),
16 partition p_max values less than (maxvalue)
17 );
Table created.
SQL> --以下是插入2023年一整年日期随机数和表示福建地区号含义591到599的随机数记录并有10万条如下
SQL> insert into range_part_tab
2 (id, deal_date, area_code, contents)
3 select rownum,
4 to_date(to_char(sysdate - 365, 'J') +
5 TRUNC(DBMS_RANDOM.value(0, 365)),
6 'J'),
7 ceil(dbms_random.value(590, 599)),
8 rpad('*', 400, '*')
9 from dual
10 connect by rownum <= 100000;
100000 rows created.
SQL> commit;
Commit complete.
SQL> 以上操作完成了范围分区的分区表创建并且构造出10万条记录并插入到分区表中注意如下5点
① 范围分区的关键字为partition by range即这三个关键字表示该分区为范围分区。
② values less than是范围分区特定的语法用于指明具体的范围比如partition p2 values less thanTO_DATE'2023-03-01','YYYY-MM-DD'表示小于3月份的记录。
③ partition p1 到partition p_max表示总共建立了13个分区。
④ 最后还要注意partition p_max values less thanmaxvalue的部分表示超出这些范围的记录全部落在这个分区中免得出错。
⑤ 分区表中的分区可分别指定在不同的表空间里如果不写即为都在同一默认表空间里。
2.列表分区
列表分区最常见的分区列就是以地区列作为分区
列表分区示例如下
SQL>
SQL> show user
USER is "MAXWELLPAN"
SQL> drop table list_part_tab purge;
drop table list_part_tab purge
*
ERROR at line 1:
ORA-00942: table or view does not exist
SQL> -- Note: 此分区为列表分区
SQL> create table list_part_tab (id number, deal_date date, area_code number,contents varchar2(4000))
2 partition by list(area_code)
3 (
partition p_591 values (591),
5 partition p_592 values (592),
6 partition p_593 values (593),
7 partition p_594 values (594),
8 partition p_595 values (595),
9 partition p_596 values (596),
10 partition p_597 values (597),
11 partition p_598 values (598),
12 partition p_599 values (599),
13 partition p_other values (DEFAULT)
14 );
Table created.
SQL>
SQL> -- 以下是插入2023年一整年日期随机数和表示福建地区号含义591到599的随机数记录共有10万条如下
SQL>
SQL>
SQL> insert into list_part_tab
2 (id, deal_date, area_code, contents)
3 select rownum,
4 to_date(to_char(sysdate - 365, 'J') +
5 TRUNC(DBMS_RANDOM.value(0, 365)),
6 'J'),
7 ceil(dbms_random.value(590, 599)),
8 rpad('*', 400, '*')
9 from dual
10 connect by rownum <= 100000;
100000 rows created.
SQL> commit;
Commit complete.
SQL> 需要注意
① 列表分区的关键字为partition by list即这三个关键字表示该分区为列表分区。
② 不同于之前范围分区的values less than列表分区仅需values 即可确定范围。值得注意的是partition p_592 values592并不是说明取值只能写一个也可写为多个比如partition p_union values592,593,594。
③ partition p_591 到partition p_other表示总共建立了10个分区。
④ 最后还要注意partition p_other valuesDEFAULT部分表示不在刚才591到599范围的记录全部落在这个默认分区中避免应用出错。
⑤ 分区表的分区可分别指定在不同的表空间里如果不写即为都在同一默认表空间里
3.散列分区Hash分区
建散列分区时所取的列故意是和之前范围分区相同的列都是时间列。
散列分区示例如下
SQL>
SQL> show user;
USER is "MAXWELLPAN"
SQL> drop table has_part_tab purge;
drop table has_part_tab purge
*
ERROR at line 1:
ORA-00942: table or view does not exist
SQL> --注意此分区为散列分区
SQL>
SQL> create table hash_part_tab (id number, deal_date date, area_code number,contents varchar2(4000))
2 partition by hash(deal_date)
3 partitions 12
4 ;
Table created.
SQL> -- 以下是插入2023年一整年日期随机数和表示福建地区号含义591到599的随机数记录共有10万条如下
SQL> insert into hash_part_tab
2 (id, deal_date, area_code, contents)
3 select rownum,
4 to_date(to_char(sysdate - 365, 'J') +
5 TRUNC(DBMS_RANDOM.value(0, 365)),
6 'J'),
7 ceil(dbms_random.value(590, 599)),
8 rpad('*', 400, '*')
9 from dual
10 connect by rownum <= 100000;
100000 rows created.
SQL> commit;
Commit complete.
SQL>Note:
① 散列分区的关键字为partition by hash出现这三个关键字即表示当前分区为散列分区。
② 散列分区与之前两种分区的明显差别在于没有指定分区名而仅仅是指定了分区个数如PARTITIONS 12。
③ 散列分区的分区个数尽量设置为偶数个比如本例中是12个如果是11个或者13个就不妥了具体原因和Oracle内部架构有关.
④ 可以指定散列分区的分区表空间比如增加如下一小段STORE INts1,ts2,ts3,ts4,t5,t6,t7,t8,t9,t10,t11,t12表示分别存放在12个不同的表空间里当然不写出表空间就是都存放在同一默认表空间里。
4.组合分区
在 Oracle 11g 以前主要支持 range-list 和range-hash这两种组合在实际应用中最常用的组合是范围-列表range-list的组合。
组合分区示例
SQL>
SQL> show user;
USER is "MAXWELLPAN"
SQL> drop table range_list_part_tab purge;
drop table range_list_part_tab purge
*
ERROR at line 1:
ORA-00942: table or view does not exist
SQL> --注意此分区为范围分区
SQL> create table range_list_part_tab(id number, deal_date date, area_code number,contents varchar2(4000))
2 partition by range(deal_date)
3 subpartition by list(area_code)
4 subpartition template
5 (subpartition p_591 values (591),
6 subpartition p_592 values (592),
7 subpartition p_593 values (593),
8 subpartition p_594 values (594),
9 subpartition p_595 values (595),
10 subpartition p_596 values (596),
11 subpartition p_597 values (597),
12 subpartition p_598 values (598),
13 subpartition p_599 values (599),
14 subpartition p_other values (DEFAULT))
15 (
16 partition p1 values less than (TO_DATE('2023-02-01','YYYY-MM-DD')),
17 partition p2 values less than (TO_DATE('2023-03-01','YYYY-MM-DD')),
18 partition p3 values less than (TO_DATE('2023-04-01','YYYY-MM-DD')),
19 partition p4 values less than (TO_DATE('2023-05-01','YYYY-MM-DD')),
20 partition p5 values less than (TO_DATE('2023-06-01','YYYY-MM-DD')),
21 partition p6 values less than (TO_DATE('2023-07-01','YYYY-MM-DD')),
22 partition p7 values less than (TO_DATE('2023-08-01','YYYY-MM-DD')),
23 partition p8 values less than (TO_DATE('2023-09-01','YYYY-MM-DD')),
24 partition p9 values less than (TO_DATE('2023-10-01','YYYY-MM-DD')),
25 partition p10 values less than (TO_DATE('2023-11-01','YYYY-MM-DD')),
partition p11 values less than (TO_DATE('2023-12-01','YYYY-MM-DD')),
27 partition p12 values less than (TO_DATE('2024-01-01','YYYY-MM-DD')),
28 partition p_max values less than (maxvalue)
29 );
Table created.
SQL> -- 以下是插入2023年一整年日期随机数和表示福建地区号含义591到599的随机数记录共有10万条如下
SQL> insert into range_list_part_tab
2 (id, deal_date, area_code, contents)
3 select rownum,
4 to_date(to_char(sysdate - 365, 'J') +
5 TRUNC(DBMS_RANDOM.value(0, 365)),
6 'J'),
7 ceil(dbms_random.value(590, 599)),
8 rpad('*', 400, '*')
9 from dual
10 connect by rownum <= 100000;
100000 rows created.
SQL> commit;
Commit complete.
SQL>主要就是增加了subpartition by listarea_code这个模块其他部分和原先的范围分区没什么差异。
Note:
① 组合分区是由主分区和从分区组成的比如范围-列表分区主分区是范围分区而从分区是列表分区从分区的关键字为subpartition如本例中的subpartition by listarea_code。
② 为了避免在每个主分区中都写相同的从分区可以考虑用模板的方式比如本例中的subpartition TEMPLATE关键字。
③ 只要涉及子分区模块都需要有subpartition关键字。
④ 关于表空间和之前的没有差别依然是可以指定也可以不指定。
Oracle 11g以前除了上述范围-列表这个最常见的组合分区外还有range-hash组合。在Oracle 11g后还提供了range-range、list-range、list-hash和list-list这4种组合本次课程我就主要介绍range-list分区其他的适用场合相对比较少使用频率较低。
5.分区原理
4种不同类型的分区表并依次插入了相同的10万条记录现在我们再建一张普通表也插入相同的10万条记录。
分区原理分析之普通表插入
SQL>
SQL> drop table norm_tab_purge;
drop table norm_tab_purge
*
ERROR at line 1:
ORA-00942: table or view does not exist
SQL> create table norm_tab (id number, deal_date date, area_code number,contents varchar2(4000));
Table created.
SQL>
SQL> insert into norm_tab
2 (id, deal_date, area_code, contents)
3 select rownum,
4 to_date(to_char(sysdate - 365, 'J') +
5 TRUNC(DBMS_RANDOM.value(0, 365)),
6 'J'),
7 ceil(dbms_random.value(590, 599)),
8 rpad('*', 400, '*')
9 from dual
10 connect by rownum <= 100000;
100000 rows created.
SQL> commit;
Commit complete.
SQL>分区原理分析之普通表与分区表在段分配上的差异
SQL>
SQL>
SQL> show user;
USER is "MAXWELLPAN"
SQL> set linesize 666
SQL> set pagesize 5000
SQL> column segment_name format a20
SQL> column partition_name format a20
SQL> column segement_type format a20
SQL> select segment_name,
2 partition_name,
3 segment_type,
4 bytes/1024/1024 "字节数(M)",
5 tablespace_name
6 from user_segments
7 where segment_name in ('RANGE_PART_TAB','NORM_TAB');
SEGMENT_NAME PARTITION_NAME SEGMENT_TYPE 字节数(M) TABLESPACE_NAME
-------------------- -------------------- ------------------------------------------------------ ---------- ------------------------------------------------------------------------------------------
NORM_TAB TABLE 47 TBS_MAXWELL
RANGE_PART_TAB P1 TABLE PARTITION 48 TBS_MAXWELL
SQL> 观察HASH分区的段分配情况
SQL>
SQL> show user;
USER is "MAXWELLPAN"
SQL> set linesize 666
SQL> set pagesize 5000
SQL> column segment_name format a20
SQL> column partition_name format a20
SQL> column segement_type format a20
SQL> select segment_name,
2 partition_name,
3 segment_type,
4 bytes/1024/1024 "字节数(M)",
5 tablespace_name
6 from user_segments
7 where segment_name in ('HASH_PART_TAB');
SEGMENT_NAME PARTITION_NAME SEGMENT_TYPE 字节数(M) TABLESPACE_NAME
-------------------- -------------------- ------------------------------------------------------ ---------- ------------------------------------------------------------------------------------------
HASH_PART_TAB SYS_P741 TABLE PARTITION 8 TBS_MAXWELL
HASH_PART_TAB SYS_P742 TABLE PARTITION 8 TBS_MAXWELL
HASH_PART_TAB SYS_P743 TABLE PARTITION 8 TBS_MAXWELL
HASH_PART_TAB SYS_P744 TABLE PARTITION 8 TBS_MAXWELL
HASH_PART_TAB SYS_P745 TABLE PARTITION 8 TBS_MAXWELL
HASH_PART_TAB SYS_P746 TABLE PARTITION 8 TBS_MAXWELL
HASH_PART_TAB SYS_P747 TABLE PARTITION 8 TBS_MAXWELL
HASH_PART_TAB SYS_P748 TABLE PARTITION 8 TBS_MAXWELL
HASH_PART_TAB SYS_P749 TABLE PARTITION 8 TBS_MAXWELL
HASH_PART_TAB SYS_P750 TABLE PARTITION 8 TBS_MAXWELL
HASH_PART_TAB SYS_P751 TABLE PARTITION 8 TBS_MAXWELL
HASH_PART_TAB SYS_P752 TABLE PARTITION 8 TBS_MAXWELL
12 rows selected.
SQL> 其实HASH分区最大的好处在于它可将数据根据一定的HASH算法均匀分布到不同的分区中去避免查询数据时集中在某一个地方从而避免热点块的竞争改善IO此处在时间列建HASH分区一般是不妥当的因为我们经常都是指定具体的时间来完成数据检索或者是指定具体的时间来完成数据清理这对HASH分区来说就很不适合了。此外大家还要注意一点HASH可以精确匹配无法范围扫描。
观察组合分区的段分配的个数
SQL>
SQL> select count(*)
2 from user_segments
3 where segment_name='RANGE_LIST_PART_TAB';
COUNT(*)
----------
9
SQL> 大家记住分区表也是有额外开销的如果分区数量过多Oracle 就需要管理过多的段在操作分区表时也容易引发Oracle内部大量的递归调用此外本身的语法也有一定的复杂度。所以一般来说只有大表才建议建分区记录数在100万以下的表基本不建议建分区。
4.2.4 分区表最实用的特性
1.高效的分区消除
“分区表存在的最大意义在于可以有效地做到分区消除比如你对地区号做了分区查询福州就只会在福州的分区中查找数据而不会到厦门、漳州、泉州等其他分区中查找这就是分区消除消除了福州以外的所有其他分区。
观察范围分区表的分区消除带来的性能优势
[oracle@oracle-db-19c ~]$ sqlplus / as sysdba
SQL*Plus: Release 19.0.0.0.0 - Production on Sat Jan 7 14:23:42 2023
Version 19.3.0.0.0
Copyright (c) 1982, 2019, Oracle. All rights reserved.
Connected to:
Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production
Version 19.3.0.0.0
SQL> conn maxwellpan/maxwellpan@PDB1
Connected.
SQL>
SQL> set linesize 1000
SQL> set autotrace traceonly
SQL> set timing on
SQL> select *
2 from range_part_tab
3 where deal_date >= TO_DATE('2023-09-04','YYYY-MM-DD')
4 and deal_date <= TO_DATE('2023-09-07','YYYY-MM-DD');
no rows selected
Elapsed: 00:00:00.06
Execution Plan
----------------------------------------------------------
Plan hash value: 16125146
---------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop |
---------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 274 | 111K| 128 (0)| 00:00:01 | | |
| 1 | PARTITION RANGE SINGLE| | 274 | 111K| 128 (0)| 00:00:01 | 9 | 9 |
|* 2 | TABLE ACCESS FULL | RANGE_PART_TAB | 274 | 111K| 128 (0)| 00:00:01 | 9 | 9 |
---------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("DEAL_DATE">=TO_DATE(' 2023-09-04 00:00:00', 'syyyy-mm-dd hh24:mi:ss') AND
"DEAL_DATE"<=TO_DATE(' 2023-09-07 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
Statistics
----------------------------------------------------------
259 recursive calls
22 db block gets
312 consistent gets
5 physical reads
4276 redo size
582 bytes sent via SQL*Net to client
489 bytes received via SQL*Net from client
1 SQL*Net roundtrips to/from client
16 sorts (memory)
0 sorts (disk)
0 rows processed
SQL>
普通表无法用deal_date条件进行分区消除
SQL>
SQL> select *
2 from norm_tab
3 where deal_date >= TO_DATE('2023-09-04','YYYY-MM-DD')
4 and deal_date <= TO_DATE('2023-09-07','YYYY-MM-DD');
no rows selected
Elapsed: 00:00:00.21
Execution Plan
----------------------------------------------------------
Plan hash value: 278673677
------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 274 | 111K| 1606 (1)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| NORM_TAB | 274 | 111K| 1606 (1)| 00:00:01 |
------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("DEAL_DATE">=TO_DATE(' 2023-09-04 00:00:00', 'syyyy-mm-dd
hh24:mi:ss') AND "DEAL_DATE"<=TO_DATE(' 2023-09-07 00:00:00',
'syyyy-mm-dd hh24:mi:ss'))
Statistics
----------------------------------------------------------
52 recursive calls
21 db block gets
5976 consistent gets
5915 physical reads
3980 redo size
582 bytes sent via SQL*Net to client
483 bytes received via SQL*Net from client
1 SQL*Net roundtrips to/from client
5 sorts (memory)
0 sorts (disk)
0 rows processed
SQL> 同样的语句查询有相同记录的表分区表的查询代价仅为128逻辑读仅为312而普通表的代价却为1606逻辑读为5976性能方面有着天壤之别。
差别如此之大应该是和分区表查询只遍历了13个分区中的一个有关。在分区表查询的执行计划中我看到p_start和p_stop都标记上9表示只遍历了第9个分区。这样避开了对其余12个分区的查询这就是所谓的分区消除。
观察范围-列表分区表的分区条件的分区消除
SQL> set autotrace traceonly
SQL> set linesize 1000
SQL> select *
2 from range_list_part_tab
3 where deal_date >= TO_DATE('2023-09-04','YYYY-MM-DD')
4 and deal_date <= TO_DATE('2023-09-07','YYYY-MM-DD')
5 and area_code=591;
no rows selected
Elapsed: 00:00:00.00
Execution Plan
----------------------------------------------------------
Plan hash value: 406789865
--------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop |
--------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 30 | 12540 | 2457 (1)| 00:00:01 | | |
| 1 | PARTITION RANGE SINGLE| | 30 | 12540 | 2457 (1)| 00:00:01 | 9 | 9 |
| 2 | PARTITION LIST SINGLE| | 30 | 12540 | 2457 (1)| 00:00:01 | KEY | KEY |
|* 3 | TABLE ACCESS FULL | RANGE_LIST_PART_TAB | 30 | 12540 | 2457 (1)| 00:00:01 | 81 | 81 |
--------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter("DEAL_DATE">=TO_DATE(' 2023-09-04 00:00:00', 'syyyy-mm-dd hh24:mi:ss') AND
"DEAL_DATE"<=TO_DATE(' 2023-09-07 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
0 consistent gets
0 physical reads
0 redo size
582 bytes sent via SQL*Net to client
512 bytes received via SQL*Net from client
1 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
0 rows processed
SQL>普通表无法用area_code条件进行分区消除
SQL>
SQL> select *
2 from norm_tab
3 where deal_date >= TO_DATE('2023-09-04','YYYY-MM-DD')
4 and deal_date <= TO_DATE('2023-09-07','YYYY-MM-DD')
5 and area_code=591;
no rows selected
Elapsed: 00:00:00.02
Execution Plan
----------------------------------------------------------
Plan hash value: 278673677
------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 30 | 12540 | 1606 (1)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| NORM_TAB | 30 | 12540 | 1606 (1)| 00:00:01 |
------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("DEAL_DATE">=TO_DATE(' 2023-09-04 00:00:00', 'syyyy-mm-dd
hh24:mi:ss') AND "AREA_CODE"=591 AND "DEAL_DATE"<=TO_DATE(' 2023-09-07
00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
Statistics
----------------------------------------------------------
18 recursive calls
0 db block gets
5954 consistent gets
5914 physical reads
0 redo size
582 bytes sent via SQL*Net to client
722 bytes received via SQL*Net from client
1 SQL*Net roundtrips to/from client
4 sorts (memory)
0 sorts (disk)
0 rows processed
SQL>组合分区导致范围定位得更小了产生了0个逻辑读比之前的312个逻辑读还要少。至于普通表的查询因为始终是全表扫描所以逻辑读依然和之前差不多达到5954个。
总得来说 分区表应用在大表上更合适至少要大于100万条记录的表方可考虑。
2.强大的分区操作
1分区truncate好快捷
“大家还记得在描述普通堆表时老师说过delete 无法释放空间而truncate却有效地释放了空间。但可惜的是针对普通表而言truncate往往不能轻易使用因为delete往往可针对某些条件进行局部记录删除而truncate显然不能带上条件无法做到局部删除。这时分区表就能发挥作用了。Oracle可以实现只truncate某个分区这就等同于实现了局部删除。
分区清除的例子
SQL>
SQL> show user;
USER is "MAXWELLPAN"
SQL> delete from norm_tab
2 where deal_date >= TO_DATE('2022-09-01','YYYY-MM-DD')
3 and deal_date <= TO_DATE('2022-09-30','YYYY-MM-DD');
8297 rows deleted.
Elapsed: 00:00:00.44
SQL> rollback;
Rollback complete.
Elapsed: 00:00:00.07
SQL>
SQL> alter table range_part_tab truncate partition p9;
Table truncated.
Elapsed: 00:00:00.32
SQL> select count(*) from range_part_tab
2 where deal_date >= TO_DATE('2022-09-01','YYYY-MM-DD')
3 and deal_date <= TO_DATE('2022-09-30','YYYY-MM-DD');
COUNT(*)
----------
8268
Elapsed: 00:00:00.21
SQL> 说明针对普通表我们只能delete而针对分区表需求等同于要删除p9的分区然后直接alter table range_part_tab truncate partition p9就完成了。关于truncate 可以释放表空间之前已经证明过了现在无须再次证明。
分区清理的方法在有大量历史数据需要清理的时候发挥着极其重要的作用。很多历史表、日志表都被设计为分区表正是由于这个特性使得清理数据极其方便迅速而且能有效释放空间。
2分区数据转移很神奇
“关于分区表的历史记录的处理其实是可以分成删除和转移两部分的关于转移备份的方案Oracle 提供了一个非常棒的工具就是分区交换可以实现普通表和分区表的某个分区之间数据的相互交换它们之间的交换非常快基本上瞬间就可以完成实际上只是Oracle在内部数据字典中做的一些小改动而已。命令很简单类似alter table 分区表 exchange partition 分区名 with table中间表。其中的关键字为exchange和with table 等。
分区交换的神奇例子
SQL>
SQL> show user;
USER is "MAXWELLPAN"
SQL> drop table mid_tab_purge;
drop table mid_tab_purge
*
ERROR at line 1:
ORA-00942: table or view does not exist
Elapsed: 00:00:00.04
SQL> create table mid_table(id number,deal_date date,area_code number,contents varchar2(4000));
Table created.
Elapsed: 00:00:00.10
SQL> select count(*) from mid_table;
COUNT(*)
----------
0
Elapsed: 00:00:00.00
SQL>
QL> select count(*) from range_part_tab
2 where deal_date >= TO_DATE('2022-08-01','YYYY-MM-DD')
3 and deal_date <= TO_DATE('2022-08-31','YYYY-MM-DD');
COUNT(*)
----------
8478
Elapsed: 00:00:00.03
SQL>
SQL> select count(*) from range_part_tab partition(p8);
COUNT(*)
----------
0
Elapsed: 00:00:00.00
SQL> alter table range_part_tab exchange partition p8 with table mid_table;
Table altered.
Elapsed: 00:00:00.90
SQL> select count(*) from range_part_tab partition(p8);
COUNT(*)
----------
0
Elapsed: 00:00:00.00
SQL> select count(*) from mid_table;
COUNT(*)
----------
0
Elapsed: 00:00:00.00
SQL> alter table range_part_tab exchange partition p1 with table mid_table;
Table altered.
Elapsed: 00:00:00.05
SQL> select count(*) from range_part_tab partition(p1);
COUNT(*)
----------
0
Elapsed: 00:00:00.01
SQL> select count(*) from mid_table;
COUNT(*)
----------
100000
Elapsed: 00:00:00.02
SQL> 由于数据的问题当前使用p1分区与普通表mid_table进行交换。实现相同的结果如上所示
分区交换能否从普通表交换到分区表
分区交换从普通表交换到分区表
SQL>
SQL> show user;
USER is "MAXWELLPAN"
SQL>
SQL> alter table range_part_tab exchange partition p1 with table mid_table;
Table altered.
Elapsed: 00:00:00.12
SQL> select count(*) from range_part_tab partition(p1);
COUNT(*)
----------
100000
Elapsed: 00:00:00.02
SQL> select count(*) from mid_table;
COUNT(*)
----------
0
Elapsed: 00:00:00.00
SQL> 不过这里还要注意exchange是交换的含义试验中mid_table表开始没有记录所以交换过程中总有一边记录为0。如果mid_table表初始有记录比如有1条那exchange的结果就是一边是100000条另一边是1条的交替变换了
3分区切割你想分就分
分区切割
SQL>
SQL> show user
USER is "MAXWELLPAN"
SQL>
SQL> drop table range_part_tab purge;
Table dropped.
Elapsed: 00:00:00.80
SQL>
SQL> create table range_part_tab (id number, deal_date date, area_code number,contents varchar2(4000))
2 partition by range(deal_date)
3 (
4 partition p1 values less than (TO_DATE('2022-02-01','YYYY-MM-DD')),
5 partition p2 values less than (TO_DATE('2022-03-01','YYYY-MM-DD')),
6 partition p3 values less than (TO_DATE('2022-04-01','YYYY-MM-DD')),
7 partition p4 values less than (TO_DATE('2022-05-01','YYYY-MM-DD')),
8 partition p5 values less than (TO_DATE('2022-06-01','YYYY-MM-DD')),
9 partition p6 values less than (TO_DATE('2022-07-01','YYYY-MM-DD')),
10 partition p7 values less than (TO_DATE('2022-08-01','YYYY-MM-DD')),
11 partition p8 values less than (TO_DATE('2022-09-01','YYYY-MM-DD')),
12 partition p9 values less than (TO_DATE('2022-10-01','YYYY-MM-DD')),
13 partition p10 values less than (TO_DATE('2022-11-01','YYYY-MM-DD')),
14 partition p11 values less than (TO_DATE('2022-12-01','YYYY-MM-DD')),
15 partition p12 values less than (TO_DATE('2023-01-01','YYYY-MM-DD')),
16 partition p_max values less than (maxvalue)
17 );
Table created.
Elapsed: 00:00:00.03
SQL> --以下是插入2022年一整年日期随机数和表示福建地区号含义591到599的随机数记录并有10万条如下
SQL> insert into range_part_tab
2 (id, deal_date, area_code, contents)
3 select rownum,
4 to_date(to_char(sysdate - 365, 'J') +
5 TRUNC(DBMS_RANDOM.value(0, 365)),
6 'J'),
7 ceil(dbms_random.value(590, 599)),
8 rpad('*', 400, '*')
9 from dual
10 connect by rownum <= 100000;
100000 rows created.
Elapsed: 00:00:02.15
SQL> commit;
Commit complete.
Elapsed: 00:00:00.01
SQL>
SQL>
SQL>
SQL> alter table range_part_tab split partition p_max at (TO_DATE('2023-02-01','YYYY-MM-DD')) into (PARTITION p2023_01,PARTITION p_max);
Table altered.
Elapsed: 00:00:00.39
SQL> alter table range_part_tab split partition p_max at (TO_DATE('2023-03-01','YYYY-MM-DD')) into (PARTITION p2023_02,PARTITION p_max);
Table altered.
Elapsed: 00:00:00.05
SQL> 可以通过以下实验来查看分区切割是否成功
SQL> set pagesize 200
SQL> set linesize 200
SQL> column segment_name format a20
SQL> column partition_name format a20
SQL> column segment_type format a20
SQL> select segment_name,
2 partition_name,
3 segment_type,
4 bytes/1024/1024 "MB",
5 tablespace_name
6 from user_segments
7 where segment_name in ('RANGE_PART_TAB');
SEGMENT_NAME PARTITION_NAME SEGMENT_TYPE MB TABLESPACE_NAME
-------------------- -------------------- -------------------- ---------- ------------------------------------------------------------------------------------------
RANGE_PART_TAB P1 TABLE PARTITION 8 TBS_MAXWELL
RANGE_PART_TAB P10 TABLE PARTITION 8 TBS_MAXWELL
RANGE_PART_TAB P11 TABLE PARTITION 8 TBS_MAXWELL
RANGE_PART_TAB P12 TABLE PARTITION 8 TBS_MAXWELL
RANGE_PART_TAB P2 TABLE PARTITION 8 TBS_MAXWELL
RANGE_PART_TAB P2023_01 TABLE PARTITION 8 TBS_MAXWELL
RANGE_PART_TAB P2023_02 TABLE PARTITION 8 TBS_MAXWELL
RANGE_PART_TAB P3 TABLE PARTITION 8 TBS_MAXWELL
RANGE_PART_TAB P4 TABLE PARTITION 8 TBS_MAXWELL
RANGE_PART_TAB P5 TABLE PARTITION 8 TBS_MAXWELL
RANGE_PART_TAB P6 TABLE PARTITION 8 TBS_MAXWELL
RANGE_PART_TAB P7 TABLE PARTITION 8 TBS_MAXWELL
RANGE_PART_TAB P8 TABLE PARTITION 8 TBS_MAXWELL
RANGE_PART_TAB P9 TABLE PARTITION 8 TBS_MAXWELL
RANGE_PART_TAB P_MAX TABLE PARTITION 8 TBS_MAXWELL
15 rows selected.
Elapsed: 00:00:00.04
SQL>Note:
① 分区切割的三个关键字是split、at 和into。
② at部分在此处说明了具体的范围小于某个指定的值。
③ into部分说明分区被切割成两个分区比如intoPARTITION p2023_01,PARTITION P_MAX表示将P_MAX切割成PARTITION p2023_01和PARTITION P_MAX两部分其中括号里的P_MAX可以改为新的名字也可以保留原来的名字。
4分区合并你想合就合
SQL> alter table range_part_tab merge partitions p2023_02,p_max INTO PARTITION p_max;
Table altered.
Elapsed: 00:00:00.13
SQL> alter table range_part_tab merge partitions p2023_01,p_max INTO PARTITION p_max;
Table altered.
Elapsed: 00:00:00.06
SQL> column segment_name format a20
SQL> column partition_name format a20
SQL> column segment_type format a20
SQL> select segment_name,
2 partition_name,
3 segment_type,
4 bytes/1024/1024 "MB",
5 tablespace_name
6 from user_segments
7 where segment_name in ('RANGE_PART_TAB');
SEGMENT_NAME PARTITION_NAME SEGMENT_TYPE MB TABLESPACE_NAME
-------------------- -------------------- -------------------- ---------- ------------------------------------------------------------------------------------------
RANGE_PART_TAB P1 TABLE PARTITION 8 TBS_MAXWELL
RANGE_PART_TAB P10 TABLE PARTITION 8 TBS_MAXWELL
RANGE_PART_TAB P11 TABLE PARTITION 8 TBS_MAXWELL
RANGE_PART_TAB P12 TABLE PARTITION 8 TBS_MAXWELL
RANGE_PART_TAB P2 TABLE PARTITION 8 TBS_MAXWELL
RANGE_PART_TAB P3 TABLE PARTITION 8 TBS_MAXWELL
RANGE_PART_TAB P4 TABLE PARTITION 8 TBS_MAXWELL
RANGE_PART_TAB P5 TABLE PARTITION 8 TBS_MAXWELL
RANGE_PART_TAB P6 TABLE PARTITION 8 TBS_MAXWELL
RANGE_PART_TAB P7 TABLE PARTITION 8 TBS_MAXWELL
RANGE_PART_TAB P8 TABLE PARTITION 8 TBS_MAXWELL
RANGE_PART_TAB P9 TABLE PARTITION 8 TBS_MAXWELL
RANGE_PART_TAB P_MAX TABLE PARTITION 8 TBS_MAXWELL
13 rows selected.
Elapsed: 00:00:00.04
SQL>Note:
① 分区合并的关键字是merge和into。
② merge后面跟着的是需要合并的两个分区名。
③ into部分为合并后的分区名可以是新的分区名也可以沿用已存在的分区名。
5分区增与删非常简单
最后一个分区是maxvalue不允许追加只允许分割
SQL> show user
USER is "MAXWELLPAN"
SQL> alter table range_part_tab add partition p2023_01 values less than (TO_DATE('2023-02-01','YYYY-MM-DD'));
alter table range_part_tab add partition p2023_01 values less than (TO_DATE('2023-02-01','YYYY-MM-DD'))
*
ERROR at line 1:
ORA-14074: partition bound must collate higher than that of the last partition
Elapsed: 00:00:00.00
SQL> 不过我们倒是可以改成先试验分区删除把 p_max 删除了然后追加自然就没问题了继续试验
可以删除maxvalue后再进行分区追加
SQL>
SQL> alter table range_part_tab drop partition p_max;
Table altered.
Elapsed: 00:00:00.06
SQL> alter table range_part_tab add partition p2023_01 values less than (TO_DATE('2023-02-01','YYYY-MM-DD'));
Table altered.
Elapsed: 00:00:00.01
SQL> alter table range_part_tab add partition p2023_02 values less than (TO_DATE('2023-03-01','YYYY-MM-DD'));
Table altered.
Elapsed: 00:00:00.01
SQL> 关于分区增删的操作
要注意如下几点
“① 增加分区的关键字是add partition而删除分区的关键字是drop partition。
“② 由于maxvalue分区的存在无法追加新的分区必须删除了才可以追加。
4.2.4 分区索引类型简述
1.全局索引
说到分区表其实还有一个不得不提的重要知识点那就是分区索引。不少分区表设计中正是由于相关索引的错误设计导致分区表遇到诸多问题。不过由于在下一章中老师会非常详尽地给大家全面讲解索引的知识所以本章暂且不会对分区索引做特别详尽的描述只是抓住一些重点向大家说明一下.
分区表的索引一般可以分成两类一类是全局索引另一类是局部索引。其中全局索引和普通的创建索引的方式无异而局部索引需要增加local关键字。
SQL>
SQL> show user;
USER is "MAXWELLPAN"
SQL> ----以下是对deal_date 列建全局索引
SQL> create index idx_part_tab_date on range_part_tab(deal_date);
Index created.
Elapsed: 00:00:00.11
SQL> ----以下是对area_code列建局部索引
SQL> create index idx_part_tab_area on range_part_tab(area_code) local;
Index created.
Elapsed: 00:00:00.12
SQL>其实全局索引基本上可以理解为普通索引。
全局索引的段分配情况
SQL>
SQL> set linesize 666
SQL> set pagesize 5000
SQL> column segment_name format a20
SQL> column partition_name format a20
SQL> column segment_type format a20
SQL> select segment_name,
2 partition_name,
3 segment_type,
4 bytes/1024/1024 "MB",
5 tablespace_name
6 from user_segments
7 where segment_name in ('IDX_PART_TAB_DATE');
SEGMENT_NAME PARTITION_NAME SEGMENT_TYPE MB TABLESPACE_NAME
-------------------- -------------------- -------------------- ---------- ------------------------------------------------------------------------------------------
IDX_PART_TAB_DATE INDEX 3 TBS_MAXWELL
Elapsed: 00:00:00.05
SQL> 2.局部索引
而局部索引就有差异了。如下
局部索引的段分配情况
SQL>
SQL> set linesize 666
SQL> set pagesize 5000
SQL> column segment_name format a20
SQL> column partition_name format a20
SQL> column segment_type format a20
SQL> select segment_name,
2 partition_name,
3 segment_type,
4 bytes/1024/1024 "MB",
5 tablespace_name
6 from user_segments
7 where segment_name in ('IDX_PART_TAB_AREA');
SEGMENT_NAME PARTITION_NAME SEGMENT_TYPE MB TABLESPACE_NAME
-------------------- -------------------- -------------------- ---------- ------------------------------------------------------------------------------------------
IDX_PART_TAB_AREA P1 INDEX PARTITION .1875 TBS_MAXWELL
IDX_PART_TAB_AREA P10 INDEX PARTITION .1875 TBS_MAXWELL
IDX_PART_TAB_AREA P11 INDEX PARTITION .1875 TBS_MAXWELL
IDX_PART_TAB_AREA P12 INDEX PARTITION .1875 TBS_MAXWELL
IDX_PART_TAB_AREA P2 INDEX PARTITION .1875 TBS_MAXWELL
IDX_PART_TAB_AREA P3 INDEX PARTITION .1875 TBS_MAXWELL
IDX_PART_TAB_AREA P4 INDEX PARTITION .1875 TBS_MAXWELL
IDX_PART_TAB_AREA P5 INDEX PARTITION .1875 TBS_MAXWELL
IDX_PART_TAB_AREA P6 INDEX PARTITION .1875 TBS_MAXWELL
IDX_PART_TAB_AREA P7 INDEX PARTITION .1875 TBS_MAXWELL
IDX_PART_TAB_AREA P8 INDEX PARTITION .1875 TBS_MAXWELL
IDX_PART_TAB_AREA P9 INDEX PARTITION .1875 TBS_MAXWELL
IDX_PART_TAB_AREA P_MAX INDEX PARTITION .0625 TBS_MAXWELL
13 rows selected.
Elapsed: 00:00:00.04
SQL>局部索引其实就是针对各个分区所建的索引。在本例中可以看出和局部索引相比全局索引好比一个大索引而局部索引好比13个小索引。”
4.2.5 分区表之相关陷阱
1.索引缘何频频失效
其中最容易出问题的当属分区表的不当操作导致分区索引失效这些操作就是前面讲解分区操作那一部分描述的系列动作这些动作全部都会导致分区索引中的全局索引失效。
观察全局索引和局部索引的状态
SQL>
SQL> select index_name,status
2 from user_indexes
3 where index_name in ('IDX_PART_TAB_DATE','IDX_PART_TAB_AREA');
INDEX_NAME STATUS
------------------------------ ------------------------
IDX_PART_TAB_AREA N/A
IDX_PART_TAB_DATE VALID
Elapsed: 00:00:00.00
SQL>
SQL>
SQL> select index_name,partition_name,status
2 from user_ind_partitions
3 where index_name='IDX_PART_TAB_AREA';
INDEX_NAME PARTITION_NAME STATUS
------------------------------ -------------------- ------------------------
IDX_PART_TAB_AREA P1 USABLE
IDX_PART_TAB_AREA P10 USABLE
IDX_PART_TAB_AREA P11 USABLE
IDX_PART_TAB_AREA P12 USABLE
IDX_PART_TAB_AREA P2 USABLE
IDX_PART_TAB_AREA P3 USABLE
IDX_PART_TAB_AREA P4 USABLE
IDX_PART_TAB_AREA P5 USABLE
IDX_PART_TAB_AREA P6 USABLE
IDX_PART_TAB_AREA P7 USABLE
IDX_PART_TAB_AREA P8 USABLE
IDX_PART_TAB_AREA P9 USABLE
IDX_PART_TAB_AREA P_MAX USABLE
13 rows selected.
Elapsed: 00:00:00.10
SQL> 现在来看索引的状态都非常正常我们先来进行一个分区表的分区truncate操作看看索引是否会失效
SQL>
SQL>
SQL> select count(*) from range_part_tab partition(p1);
COUNT(*)
----------
6906
Elapsed: 00:00:00.06
SQL> alter table range_part_tab truncate partition p1;
Table truncated.
Elapsed: 00:00:00.19
SQL>
SQL> select count(*) from range_part_tab partition(p1);
COUNT(*)
----------
0
Elapsed: 00:00:00.04
SQL> select index_name,status
2 from user_indexes
3 where index_name in ('IDX_PART_TAB_DATE','IDX_PART_TAB_AREA');
INDEX_NAME STATUS
------------------------------ ------------------------
IDX_PART_TAB_AREA N/A
IDX_PART_TAB_DATE UNUSABLE
Elapsed: 00:00:00.02
SQL> select index_name,partition_name,status
2 from user_ind_partitions
3 where index_name='IDX_PART_TAB_AREA';
INDEX_NAME PARTITION_NAME STATUS
------------------------------ -------------------- ------------------------
IDX_PART_TAB_AREA P1 USABLE
IDX_PART_TAB_AREA P10 USABLE
IDX_PART_TAB_AREA P11 USABLE
IDX_PART_TAB_AREA P12 USABLE
IDX_PART_TAB_AREA P2 USABLE
IDX_PART_TAB_AREA P3 USABLE
IDX_PART_TAB_AREA P4 USABLE
IDX_PART_TAB_AREA P5 USABLE
IDX_PART_TAB_AREA P6 USABLE
IDX_PART_TAB_AREA P7 USABLE
IDX_PART_TAB_AREA P8 USABLE
IDX_PART_TAB_AREA P9 USABLE
IDX_PART_TAB_AREA P_MAX USABLE
13 rows selected.
Elapsed: 00:00:00.00
SQL> 可以发现全局索引失效了而局部索引没有失效。
对失效的全局索引进行重建
SQL>
SQL> alter index IDX_PART_TAB_DATE rebuild;
Index altered.
Elapsed: 00:00:00.10
SQL>
SQL>
SQL> select index_name,status
2 from user_indexes
3 where index_name in ('IDX_PART_TAB_DATE');
INDEX_NAME STATUS
------------------------------ ------------------------
IDX_PART_TAB_DATE VALID
Elapsed: 00:00:00.02
SQL> 其实分区表的分区操作对局部索引一般都没有影响但是对全局索引影响比较大。Oracle在提供这些分区操作时提供了一个很有用的参数update global indexes可以有效地避免全局索引失效。
update global indexes关键字可避免全局索引失效
SQL>
SQL>
SQL> select count(*) from range_part_tab partition(p2);
COUNT(*)
----------
7652
Elapsed: 00:00:00.01
SQL> alter table range_part_tab truncate partition p2 update global indexes;
Table truncated.
Elapsed: 00:00:00.10
SQL> select count(*) from range_part_tab partition(p2);
COUNT(*)
----------
0
Elapsed: 00:00:00.00
SQL> select index_name,status
2 from user_indexes
3 where index_name in ('IDX_PART_TAB_DATE');
INDEX_NAME STATUS
------------------------------ ------------------------
IDX_PART_TAB_DATE VALID
Elapsed: 00:00:00.00
SQL> 其他分区操作比如分区转移、切割、合并、增删等也和这个分区 truncate 是类似的都允许增加update global indexes关键字从而避免全局索引失效这里就不一一罗列了。
2.有索引效率反而更低
应用分区表的局部索引产生的逻辑读很大。
SQL>
SQL> show user;
USER is "MAXWELLPAN"
SQL> create index idx_range_list_tab_date on range_list_part_tab(id) local;
Index created.
Elapsed: 00:00:00.41
SQL> set autotrace traceonly
SQL> set linesize 1000
SQL> select *
2 from range_list_part_tab
3 where id=100000;
Elapsed: 00:00:00.02
Execution Plan
----------------------------------------------------------
Plan hash value: 1576670538
---------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop |
---------------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 418 | 132 (0)| 00:00:01 | | |
| 1 | PARTITION RANGE ALL | | 1 | 418 | 132 (0)| 00:00:01 | 1 | 13 |
| 2 | PARTITION LIST ALL | | 1 | 418 | 132 (0)| 00:00:01 | 1 | 10 |
| 3 | TABLE ACCESS BY LOCAL INDEX ROWID BATCHED| RANGE_LIST_PART_TAB | 1 | 418 | 132 (0)| 00:00:01 | 1 | 130 |
|* 4 | INDEX RANGE SCAN | IDX_RANGE_LIST_TAB_DATE | 1 | | 131 (0)| 00:00:01 | 1 | 130 |
---------------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("ID"=100000)
Statistics
----------------------------------------------------------
10 recursive calls
0 db block gets
37 consistent gets
11 physical reads
0 redo size
1201 bytes sent via SQL*Net to client
413 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> 接下来是普通表的查询情况
应用普通表的普通索引产生的逻辑读很小
SQL>
SQL> create index idx_norm_tab_date on norm_tab(id);
Index created.
Elapsed: 00:00:00.12
SQL> set autotrace traceonly
SQL> set linesize 1000
SQL> select *
2 from norm_tab
3 where id=100000;
Elapsed: 00:00:00.06
Execution Plan
----------------------------------------------------------
Plan hash value: 3445789223
---------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 418 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| NORM_TAB | 1 | 418 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_NORM_TAB_DATE | 1 | | 1 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("ID"=100000)
Statistics
----------------------------------------------------------
7 recursive calls
0 db block gets
21 consistent gets
1 physical reads
0 redo size
1207 bytes sent via SQL*Net to client
402 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> 这个问题其实涉及索引的一个特点就是索引的高度一般比较低理解了这个道理你们就能明白为什么性能差别会如此之大了。
3.无法应用分区条件
分区表设计要考虑在语句中有效用到分区条件有无分区条件差别巨大
SQL>
SQL>
SQL> select *
2 from range_list_part_tab
3 where id=100000
4 and deal_date >= sysdate-1
5 and area_code=591;
no rows selected
Elapsed: 00:00:00.05
Execution Plan
----------------------------------------------------------
Plan hash value: 644683147
---------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop |
---------------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 418 | 14 (0)| 00:00:01 | | |
| 1 | PARTITION RANGE ITERATOR | | 1 | 418 | 14 (0)| 00:00:01 | KEY | 13 |
| 2 | PARTITION LIST SINGLE | | 1 | 418 | 14 (0)| 00:00:01 | KEY | KEY |
|* 3 | TABLE ACCESS BY LOCAL INDEX ROWID BATCHED| RANGE_LIST_PART_TAB | 1 | 418 | 14 (0)| 00:00:01 | KEY | KEY |
|* 4 | INDEX RANGE SCAN | IDX_RANGE_LIST_TAB_DATE | 1 | | 13 (0)| 00:00:01 | KEY | KEY |
---------------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter("DEAL_DATE">=SYSDATE@!-1)
4 - access("ID"=100000)
Statistics
----------------------------------------------------------
111 recursive calls
5 db block gets
112 consistent gets
7 physical reads
884 redo size
582 bytes sent via SQL*Net to client
668 bytes received via SQL*Net from client
1 SQL*Net roundtrips to/from client
10 sorts (memory)
0 sorts (disk)
0 rows processed
SQL> 4.2.6 有趣的索引组织表
大家还记得之前说过普通堆表操作的不足之处吗比如select * from t where id=1 之类的查询id 列有索引如果是普通的表需要先从索引中获取 rowid然后定位到表中获取 id以外的其他列的动作这就是回表。
分别建索引组织表和普通表进行试验


分别比较索引组织表和普通表的查询性能


4.2.7 簇表的介绍及应用


簇表和索引组织表一样由于结构的特殊性导致更新操作开销非常大所以也需要谨慎使用.