

阿里云安全恶意程序检测(速通二)-CSDN博客
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
阿里云安全恶意程序检测
高阶数据探索
变量分析
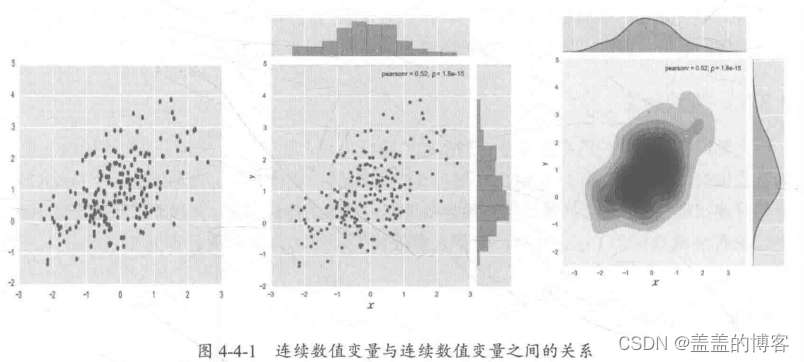
连续数值变量与连续数值变量
分析连续数值变量和连续数值变量之间的关系是为了探索变量之间的全局线性、局部
线性的关系等常用方法: plt.scatter, sns.joinplot (kind= A), A = kde。
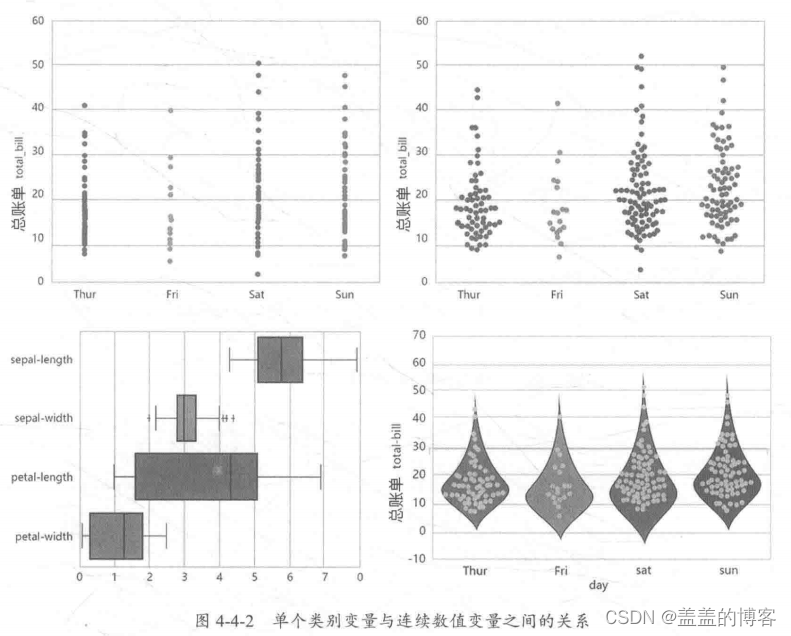
单个类别变量与连续数值变量
分析单个类别变量和连续数值变量之间的关系主要是用于观察不同类别下的连续变量
(常见于回归问题)的分布如图4-4-2所示。
常用方法: sns.stripplot, sns.swarmplot, sns.boxplot, sns.violinplot。
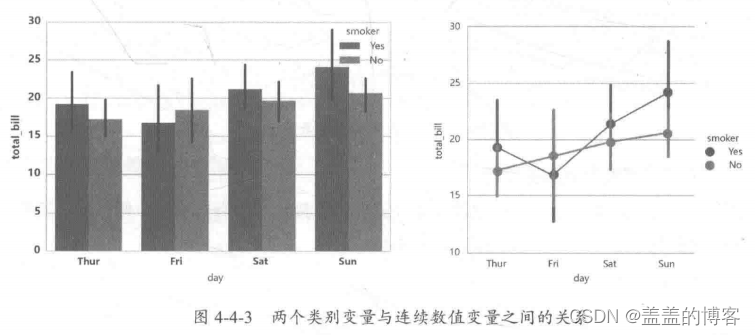
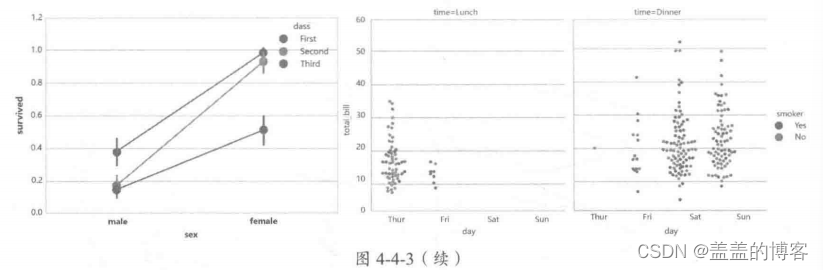
两个类别变量与连续数值变量
分析两个类别变量和连续数值变量之间的关系是上述单个类别变量与连续数值变量组
合分析的扩展用于更深层次的分析如图4-4-3。常用方法: sns.countplot, sns.barplot, sns. factorplot, sns.pointplot。
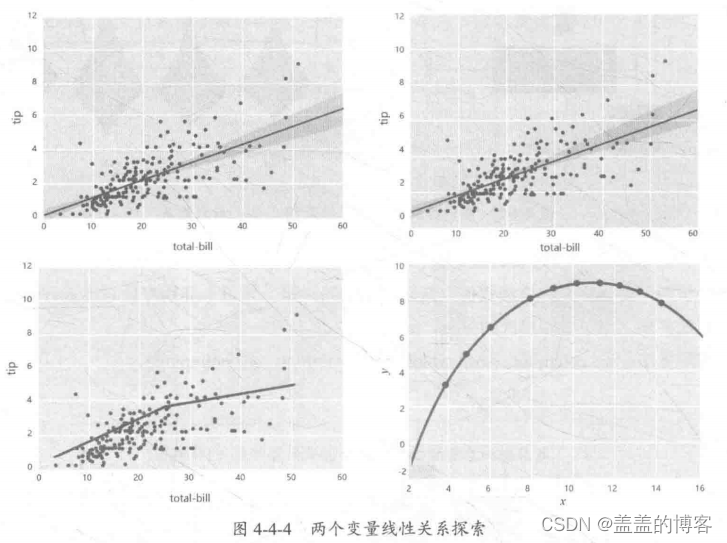
两个变量线性关系探索
两个变量线性关系的探索主要用于分析变量的全局线性、局部线性、其他非线性的关
系如图4-4-4所示。
常用方法: sns.regplot, sns.mplot, sns.residplot.
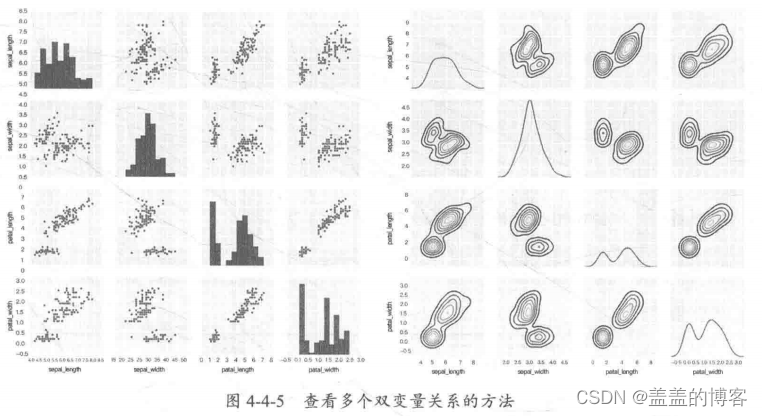
查看多个双变量关系的技巧
上面介绍的方法都适用于单独检测如果我们想直接绘制所有的情况则在一 一检查时可以考虑查看多个双变量关系的方法如图4-4-5所示。
常用方法: sns.pairplot, sns. PairGrid.
高阶数据探索
多变量交叉探索
1、通过统计特征file_id_cnt分析file_id变量和api变量之间的关系
train_analysis = train[['file_id','label']].drop_duplicates(subset = ['file_id','label'],keep = 'last')
dic_=train['file_id'].value_counts().to_dict()
train_analysis['file_id_cnt'] = train_analysis['file_id'].map(dic_).values
train_analysis['file_id_cnt'].value_counts()
sns.displot(train_analysis['file_id_cnt'])
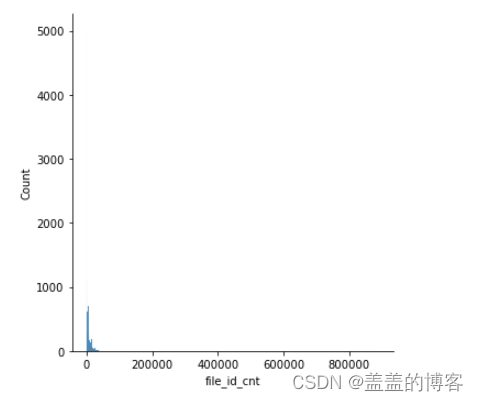
我们发现API 调用次数的基本上都集中在10 000次以下
2、为了便于分析file_id_cnt变量和label变量之间的关系首先将数据按file_id_cnt变量也就是API的调用次数取值划分为16个区间
def file_id_cnt_cut(x):
if x < 15000:
return x // 1e3
else:
return 15
train_analysis['file_id_cnt_cut'] = train_analysis['file_id_cnt'].map(file_id_cnt_cut).values
#随机选取4个区间进行查看
plt.figure(figsize = [16,20])
plt.subplot(321)
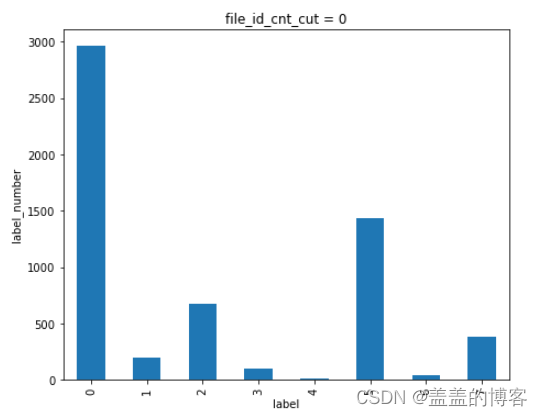
train_analysis[train_analysis['file_id_cnt_cut'] == 0]['label'].value_counts().sort_index().plot(kind = 'bar')
plt.title('file_id_cnt_cut = 0')
plt.xlabel('label')
plt.ylabel('label_number')
plt.figure(figsize = [16,20])
plt.subplot(321)
train_analysis[train_analysis['file_id_cnt_cut'] == 1]['label'].value_counts().sort_index().plot(kind = 'bar')
plt.title('file_id_cnt_cut = 0')
plt.xlabel('label')
plt.ylabel('label_number')
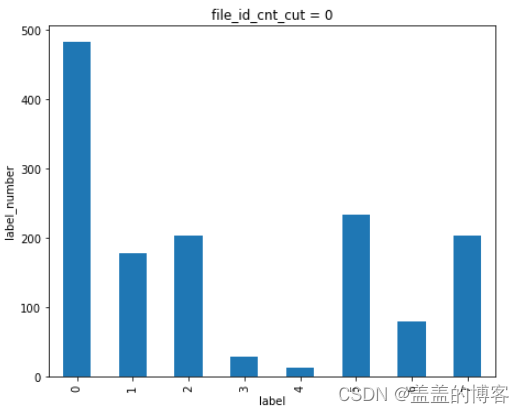
plt.figure(figsize = [16,20])
plt.subplot(321)
train_analysis[train_analysis['file_id_cnt_cut'] == 14]['label'].value_counts().sort_index().plot(kind = 'bar')
plt.title('file_id_cnt_cut = 0')
plt.xlabel('label')
plt.ylabel('label_number')
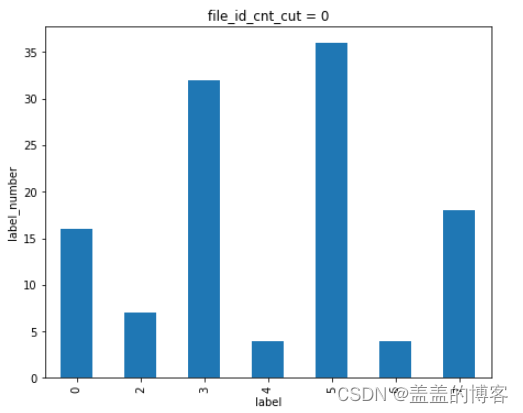
plt.figure(figsize = [16,20])
plt.subplot(321)
train_analysis[train_analysis['file_id_cnt_cut'] == 15]['label'].value_counts().sort_index().plot(kind = 'bar')
plt.title('file_id_cnt_cut = 0')
plt.xlabel('label')
plt.ylabel('label_number')
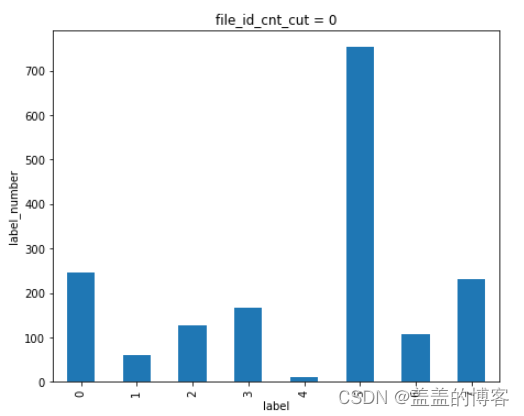
从图中可以看到:当API调用次数越多时该API是第五类病毒( 感染型病毒)的可能性就越大。
用分簇散点图查看label下file_id_cnt的分布由于绘制分簇散点图比较耗时因此采用1000个样本点(2000个所用时间比1000用时多很多)
plt.figure(figsize = [16,10])
sns.swarmplot(x = train_analysis.iloc[:2000]['label'],
y = train_analysis.iloc[:2000]['file_id_cnt'])
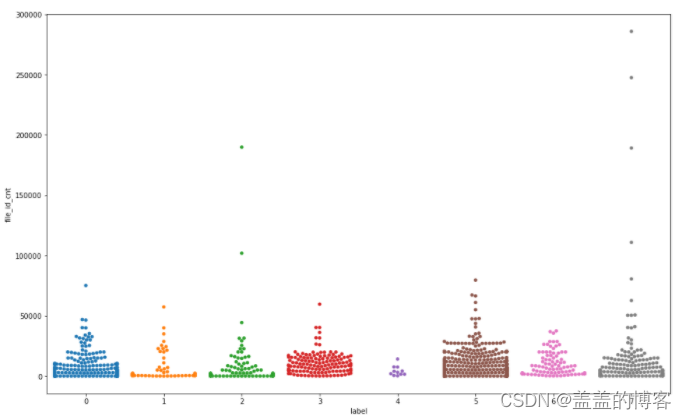
从图中得到以下结论:从频次上看第5类病毒调用API的次数最多;从调用峰值上看第2类和7类病毒有时能调用150000次的API。
3、首先通过文件调用API的类别数file_id_api_nunique,分析变量file_id和API的关系
dic_=train.groupby('file_id')['api'].nunique().to_dict()
train_analysis['file_id_api_nunique'] = train_analysis['file_id'].map(dic_).values
sns.distplot(train_analysis['file_id_api_nunique'])
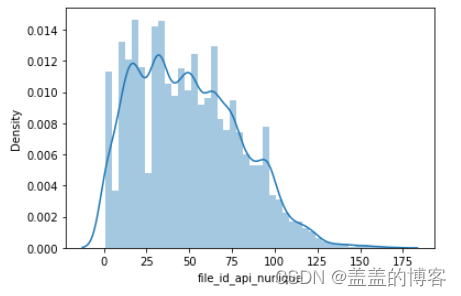
train_analysis['file_id_api_nunique'].describe()
文件调用API的类别数绝大部分都在100以内最少的是1个最多的是170个。
然后分析file_ id_ api _nunique 和标签label 变量的关系。
train_analysis.loc[train_analysis.file_id_api_nunique >= 100]['label'].value_counts().sort_index().plot(kind='bar')
plt.title('File with api nunique >= 100')
plt.xlabel('label')
plt.ylabel('label_number')
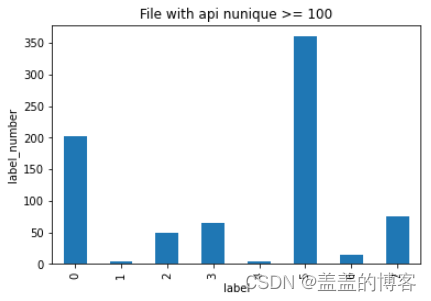
从图中可以发现第5类病毒调用不同API的次数是最多的。在上面的分析中我们也发现第5类病毒调用API的次数最多调用不同API的次数多也是可以理解的。
plt.figure(figsize = [16,10])
sns.boxplot(x=train_analysis['label'],y = train_analysis['file_id_api_nunique'])
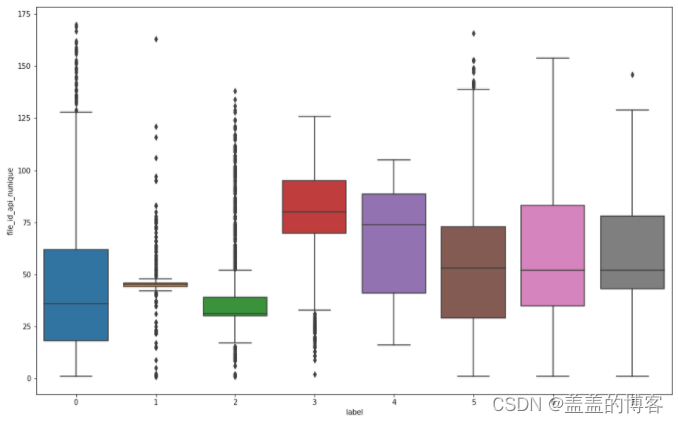
从图中得到以下结论:第3类病毒调用不同API的次数相对较多第2类病毒调用不同API的次数最少;第46, 7类病毒的离群点较少第1类病毒的离群点最多第3类病毒的离群点主要在下方:第0类和第5类的离群点则集中在上方。
4、首先,通过file_ jid_ index_ nunique 和file_ jid_ index_ max 两个统计特征分析变量file _id和index之间的关系。有个奇怪的现象我们发现调用API顺序编号的两个边缘(0 和5001)的样本数是最多的因此可以单独看一下这两个点的label分布。
#单独看一下API序号为0和5001两个点的label分布
dic_=train.groupby('file_id')['index'].nunique().to_dict()
train_analysis['file_id_index_nunique'] = train_analysis['file_id'].map(dic_).values
train_analysis['file_id_index_nunique'].describe()
dic_=train.groupby('file_id')['index'].max().to_dict()
train_analysis['file_id_index_max'] = train_analysis['file_id'].map(dic_).values
sns.distplot(train_analysis['file_id_index_max'])
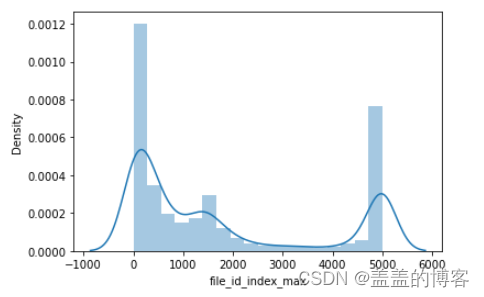
从图中可以看出文件调用index有两个极端:一个是在1附近另一个是在5000附近。
分析file_id_index_nunique和file_id_index_max与label变量的关系
plt.figure(figsize=[16,8])
plt.subplot(121)
train_analysis.loc[train_analysis.file_id_index_nunique == 1]['label'].value_counts().sort_index().plot(kind = 'bar')
plt.title('File with index nunique = 1')
plt.xlabel('label')
plt.ylabel('label_number')
plt.subplot(122)
train_analysis.loc[train_analysis.file_id_index_nunique == 5001]['label'].value_counts().sort_index().plot(kind = 'bar')
plt.title('File with index nunique = 5001')
plt.xlabel('label')
plt.ylabel('label_number')
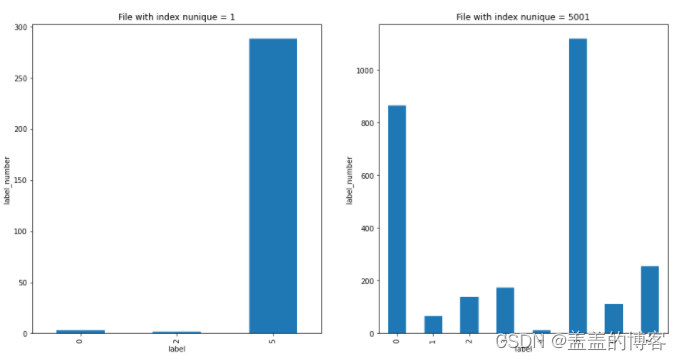
从图中可以发现在文件顺序编号只有一个时文件的标签只会是0 (正常)、2 (挖矿程序)或5 (感染型病毒)而不会是其他病毒而且最大概率可能是5;对于顺序次数大于5000个的文件其和上面调用API次数很大时类似。
还可以通过绘制小提琴图、分类散点图分析代码和结果如下:
plt.figure(figsize = [16,10])
sns.violinplot(x = train_analysis['label'],
y = train_analysis['file_id_api_nunique'])
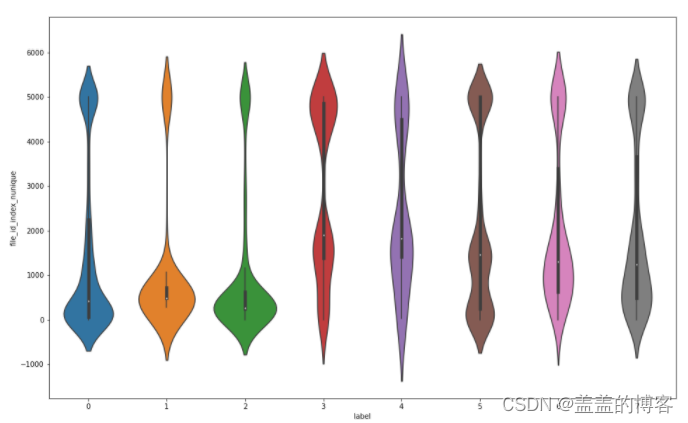
plt.figure(figsize = [16,10])
sns.stripplot(x = train_analysis['label'],
y = train_analysis['file_id_index_max'])
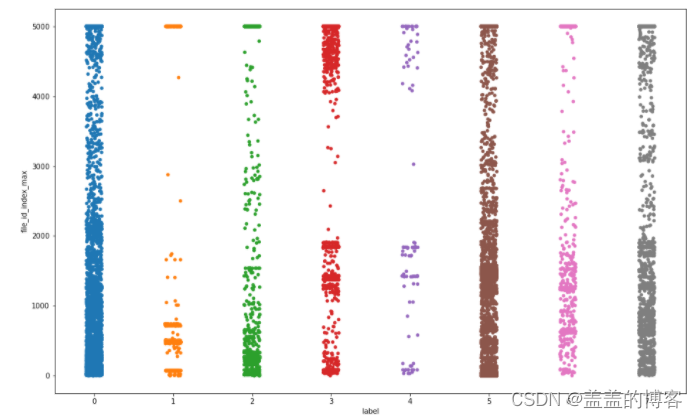
从图中得到的结论:第3类病毒调用不同index次数的平均值最大;第2类病毒调用不同index次数的平均值最小:第56, 7类病毒调用不同index次数的平均值相似。
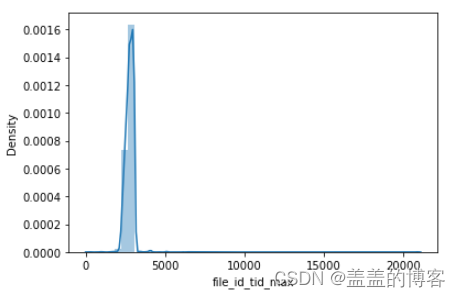
5、首先通过file_ id_ tid_ nunique和file id_ tid max两个统计特征分析变量file_ id和tid
之间的关系。
dic_= train.groupby('file_id')['tid'].nunique().to_dict()
train_analysis['file_id_tid_nunique'] = train_analysis['file_id'].map(dic_).values
train_analysis['file_id_tid_nunique'].describe()
sns.distplot(train_analysis['file_id_tid_nunique'])
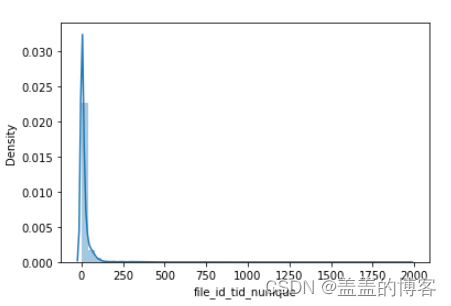
dic_= train.groupby('file_id')['tid'].max().to_dict()
train_analysis['file_id_tid_max'] = train_analysis['file_id'].map(dic_).values
train_analysis['file_id_tid_max'].describe()
sns.distplot(train_analysis['file_id_tid_max'])
#分析file_id_tid_nunique和file_id_tid_max与label变量的关系
plt.figure(figsize=[16,8])
plt.subplot(121)
train_analysis.loc[train_analysis.file_id_tid_nunique < 5]['label'].value_counts().sort_index().plot(kind = 'bar')
plt.title('File with tid nunique < 5')
plt.xlabel('label')
plt.ylabel('label_number')
plt.subplot(122)
train_analysis.loc[train_analysis.file_id_tid_nunique >= 20]['label'].value_counts().sort_index().plot(kind = 'bar')
plt.title('File with tid nunique >= 20')
plt.xlabel('label')
plt.ylabel('label_number')
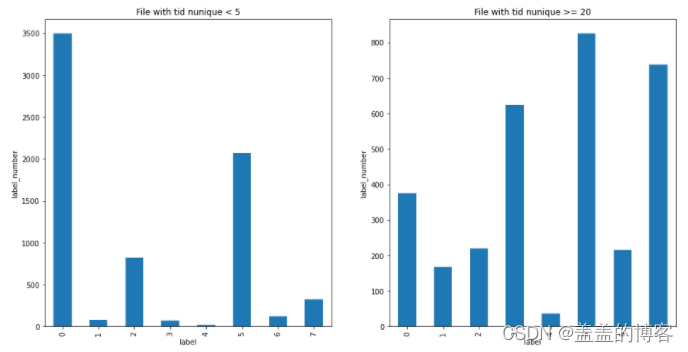
其中0:正常文件; 1:勒索病毒; 2:挖矿程序; 3: DDoS木马; 4:蠕虫病毒; 5:感
染型病毒; 6:后门程序; 7:木马程序。
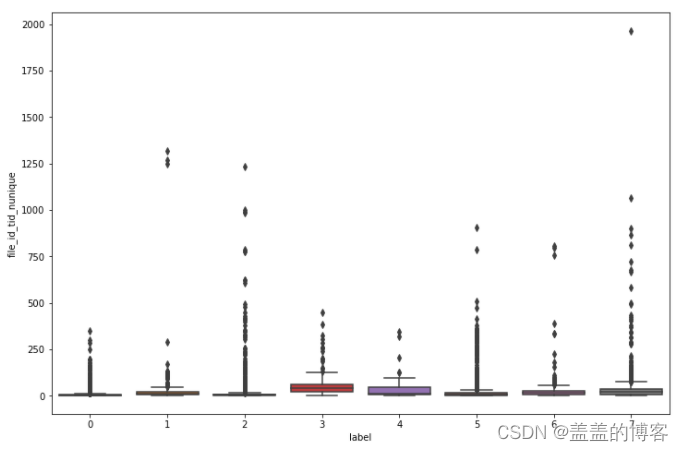
还可以通过箱线图和小提琴图进一一步 分析。
plt.figure(figsize = [12,8])
sns.boxplot(x = train_analysis['label'],
y = train_analysis['file_id_tid_nunique'])
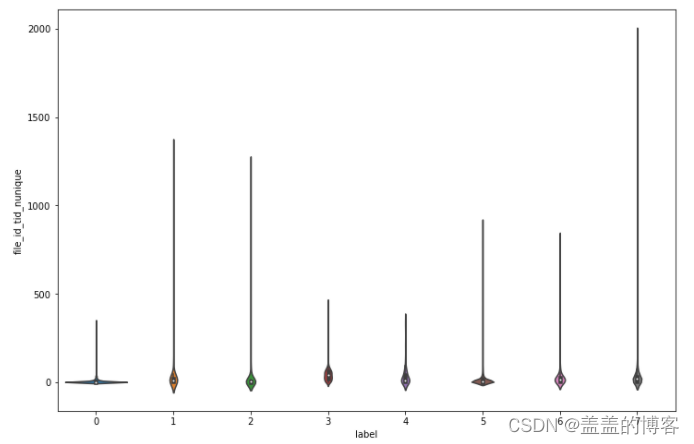
plt.figure(figsize = [12,8])
sns.violinplot(x = train_analysis['label'],
y = train_analysis['file_id_tid_nunique'])
分析file_id和tid的max特征我们将tid最大值大于3000的数据和整体作比较发现差异不是很大
plt.figure(figsize=[16,8])
plt.subplot(121)
train_analysis.loc[train_analysis.file_id_tid_max >= 3000]['label'].value_counts().sort_index().plot(kind = 'bar')
plt.title('File with tid max >= 3000')
plt.xlabel('label')
plt.ylabel('label_number')
plt.subplot(122)
train_analysis['label'].value_counts().sort_index().plot(kind = 'bar')
plt.title('All Data')
plt.xlabel('label')
plt.ylabel('label_number')
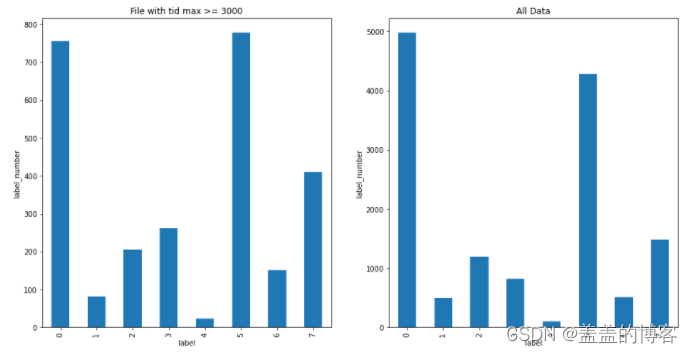
从图中得出的结论:所有文件调用的线程都相对较少;第7类病毒调用的线程数的范围最大;第0类3类和4类调用的不同线程数类似。
7、分析API变量与label变量的关系代码及运行结果如下:
train['api_label'] = train['api'] + '_' + train['label'].astype(str)
dic_ = train['api_label'].value_counts().to_dict()
df_api_label = pd.DataFrame.from_dict(dic_,orient = 'index').reset_index()
df_api_label.columns = ['api_label','api_label_count']
df_api_label['label'] = df_api_label['api_label'].apply(
lambda x:int(x.split('_')[-1]))
labels = df_api_label['label'].unique()
for label in range(8):
print('*' * 50,label,'*' * 50)
print(df_api_label.loc[df_api_label.label == label].sort_values(
'api_label_count').iloc[-5:][['api_label','api_label_count']])
print('*' * 103)
从结果可以得到以下结论: LdrGetProcedureAddress, 所有病毒和正常文件都是调用比较多的;第5类病毒: Thread32Next调用得较多;第6类和7类病毒: NtDelayExecution 调用得较多;第2类和7类病毒: Process32NextW 调用得较多。
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |