

数据库 设计规范数据库设计样例
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
目录
5 数据库
5.1 数据库命名规范
- 采用26个英文字母(区分大小写)和0-9的自然数(经常不需要)加上下划线’‘组成命名简洁明确多个单词用下划线’'分隔,一个项目一个数据库多个项目慎用同一个数据库
- 全部小写命名禁止出现大写
- 禁止使用数据库关键字如nametime datetimepassword等
- 表名称不应该取得太长一般不超过三个英文单词
- 表的名称一般使用名词或者动宾短语
- 用单数形式表示名称例如使用 employee而不是 employees
- 表必须填写描述信息使用SQL语句建表时
- 数据库创建 字符集utf8mb4、排序规则utf8mb4_general_ci
示例档案管理 数据库 就是 bip_archives 表名 就 archives_xxx
5.2 数据库字段命名
5.2.1 字段命名规范
-
采用26个英文字母(区分大小写)和0-9的自然数(经常不需要)加上下划线’‘组成命名简洁明确多个单词用下划线’'分隔
-
全部小写命名禁止出现大写
-
字段必须填写描述信息
-
禁止使用数据库关键字如nametime datetime password 等
-
字段名称一般采用名词或动宾短语
-
采用字段的名称必须是易于理解一般不超过三个英文单词
-
在命名表的列时不要重复表的名称。例如在名employe的表中避免使用名为employee_lastname的字段
-
不要在列的名称中包含数据类型
-
字段命名使用完整名称禁止缩写
-
表中字段是另外一张表的主键则为表名+id 体现关联关系 示例user_id
5.2.2 命名规范
名词 示例user_id user_name sex
动宾短语 示例is_friend is_good
5.2.3 待优化命名示例
大小写规则不统一
错误示例user_id houseID
说明使用统一规则修改为”user_id””house_id”
加下划线规则不统一
错误示例username userid isfriend isgood
说明使用下划线进行分类提升可性方便管理修改为”user_name””user_id””is_friend””is_good”
字段表示不明确
错误示例uid pid
说明使用完整名称提高可读性修改为”user_id””person_id”
5.2.4 字段类型规范
- 所有字段在设计时除以下数据类型timestamp、image、datetime、smalldatetime、uniqueidentifier、binary、sql_variant、binary 、varbinary外必须有默认值字符型的默认值为一个空字符值串’’数值型的默认值为数值0逻辑型的默认值为数值0
- 系统中所有逻辑型中数值0表示为“假”数值1表示为“真”datetime、smalldatetime类型的字段没有默认值必须为NULL
- 用尽量少的存储空间来存储一个字段的数据
使用int就不要使用varchar、char
用varchar(16)就不要使varchar(256)
IP地址使用int类型
固定长度的类型最好使用char例如邮编(postcode)
能使用tinyint就不要使用smallintint
最好给每个字段一个默认值最好不能为null
字符转化为数字(能转化的最好转化同样节约空间、提高查询性能)
避免使用NULL字段(NULL字段很难查询优化、NULL字段的索引需要额外空间、NULL字段的复合索引无效)
少用text类型(尽量使用varchar代替text字段)
5.2.5数据库中每个字段的规范描述
- 尽量遵守第三范式的标准3NF
表内的每一个值只能被表达一次
表内的每一行都应当被唯一的标示
表内不应该存储依赖于其他键的非键信息
- 如果字段事实上是与其它表的关键字相关联而未设计为外键引用需建索引大数据需要分库分表除外
- 如果字段与其它表的字段相关联需建索引
- 如果字段需做模糊查询之外的条件查询需建索引
- 除了主关键字允许建立簇索引外其它字段所建索引必须为非簇索引
5.3表设计
- 表必须定义主键默认为ID整型自增如果不采用默认设计必须咨询DBA进行设计评估。
- ID字段作为自增主键。一般所有表都要有id, id必为主键类型为bigint unsigned单表时自增、步长为1。一般情况下主键id和业务没关系的。
- 强烈建议不使用外键, 数据的完整性靠程序来保证。
- 多表中的相同列必须保证列定义一致。
- 使用InnoDB字符集utf8mb4、排序规则utf8mb4_general_ci。
- 一般情况下每张表都有着五个字段追踪数据的来源和修改并且只能逻辑删除不能物理删除重要
- 单表一到两年内数据量超过500w或数据容量超过10G考虑分表且需要提前考虑历史数据迁移或应用自行删除历史数据。
- 单条记录大小禁止超过8k 一方面字段不要太多有的都能上百甚至几百个另一方面字段的内容不易过大像文章内容等这种超长内容的需要单独存到另一张表。
- 日志类数据不建议存储在MySQL上优先考虑Hbase或OB如需要存储请找DBA评估使用压缩表存储。
- 为了提高查询效率可以适当的数据冗余注意是适当。
- 字符串为主键很难做查询优化
- 禁止使用float、double类型建议使用decimal或者int替代。
- 禁止使用blob、text类型保留大文本、文件、图片建议使用其他方式存储MySQL只保存指针信息。
————————————————
版权声明本文为CSDN博主「码农书生」的原创文章遵循CC 4.0 BY-SA版权协议转载请附上原文出处链接及本声明。
原文链接https://blog.csdn.net/lijinzhou2017/article/details/108533932
5.4 参考设计
5.4.1 应用场景
实现功能 根据综合类型地区年份演员等多级筛选。
一部电影对应多个类型


如上图所示红框中的视频筛选标签应该怎么设计数据库表结构?除了前台筛选还想支持在管理后台灵活配置这些筛选标签。
实体类表
类型表、地区表、年份表、演员表、片名表
关系类表
片名表对应 实体类关系表
5.4.2 需求分析
1 可以根据红框的标签筛选视频
2 其中综合标签比较特殊和类型、地区、年份、演员等不一样
- 综合是根据业务逻辑取值并不需要入库
- 类型、地区、年份、演员等需要入库
3 设计表结构时要考虑到
- 方便获取标签信息方便把标签信息缓存处理方便
- 根据标签筛选视频方便我们写后续的业务逻辑
5.4.3 设计思路
1.综合标签(最热,好评最新即将上线)可以写到配置文件中 (威者写在前端)这些信息不需要灵活配置所以不需要保存到数据库中
2.类型、地区、年份、演员都设计单独的表
3.视频表中设计标签表的外键方便视频列表筛选取值
4.标签信息写入缓存提高接口响应速度
5.类型、地区、年份、演员表也要支持对数据排序方便后期管理维护
5.4.4 表结构设计
视频表
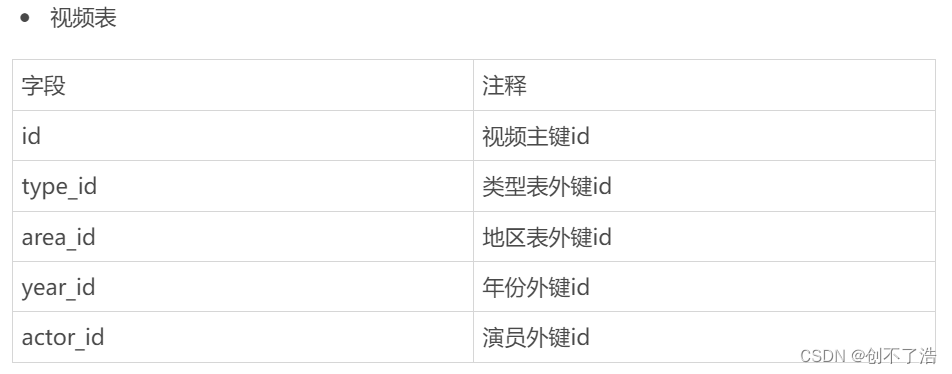
其他和视频直接相关的字段比如名称省略不写
类型表
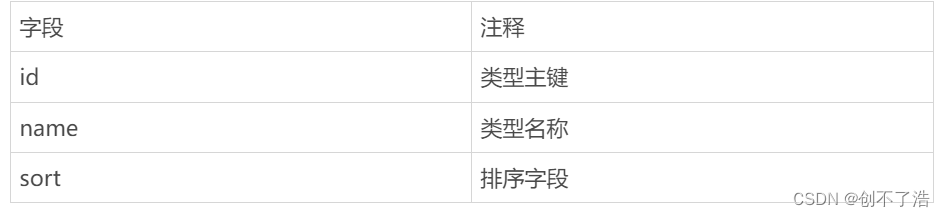
sort用来决定类型排序顺序
年份表
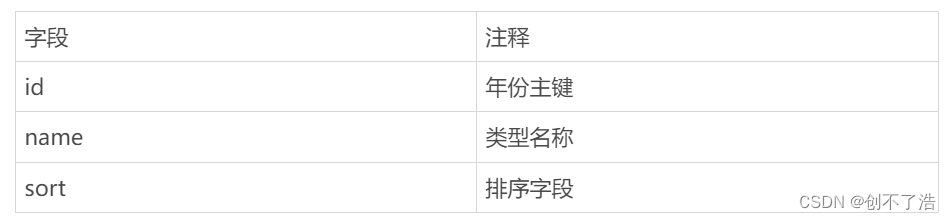
年份表有一个10年代所以需要排序字段灵活配置
演员表
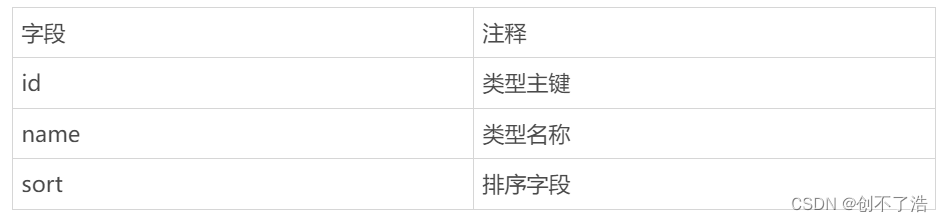
表结构设计完了还需要考虑缓存
5.4.5 缓存策略
首先这些不会频繁更新的筛选条件建议使用缓存

1.比较常用的就是redis缓存。
2.再进阶一点如果你使用docker可以把这些配置信息写入docker容器所在物理机的内存中而不用请求其他节点的redis进一步降低网络传输带来的耗时损耗。
3.筛选条件这类配置信息客户端和服务端可以约定一个更新缓存的机制客户端直接缓存配置信息进一步提高性能。
列表数据自动缓存
很多框架都是支持自动缓存处理的比如goframe和go-zero
Q1 冗余设计和一致性问题
提问:
一个表里做了这么多外键如果我要查各自的名称势必要关联4张表对于这种存在多外键关联的这种表要不要做几余呢(直接在主表里几余各自的名称字段)?
要是保证一致性的话就势必会影响性能如果做几余的话又无法保证一致
回答
目前我们解决的是视频列表筛选问题。 你提到的这个场景是在视频详情信息中如果要展示这些外键的名称怎么设计更好 我的建议是这样的:
1.根据需求可以做适当几余比如你的主表信息量不大百万级别以下配置信息修改后同步修改冗余字段的成本并不高。
2.或者像我文章中写的不做几余设计但是会把外键信息缓存业务查询从缓存中取值。 3或者将视频详情的查询结果整体进行缓存
还是看具体需求如果这些筛选信息不变化或者不需要手工管理甚至不需要设计表直接写死在代码的配置文件中也可以。进一步降低DB压力提高性能
Q2 为什么设计外键
提问:
为什么要设计外键关联? 直接写到视频表中不就行了? 这么设计的意义在哪里?
回答:
1.关键问题是想解决管理后台灵活配置
2.如果没有这个需求我们可以直接把筛选条件以配置文件的方式写死在程序中降低复杂度。
3.站在我的角度:这个功能的筛选条件变化并不会很大所以很懂你的意思。也建议像我2.中的方案去做去和产品经理拉扯喽~
总结
这篇文章介绍了设计数据库表结构应该考虑的几个方面还有优雅设计的个原则举了一个例子分享了我的设计思路为了提高性能我们也要从多方面考虑缓存问题。
收获最大的还是和大家的交流讨论总结一下
1.首先一定要先搞清楚业务需求。比如我的例子中如果不需要灵活设置完全可以写到配置文件中并不需要单独设计外键。主表中直接保存各种筛选标签名称(注意维护的问题要考虑到数据一致性)
2.数据库表结构设评一定考虑数据量和并发量我的例子中如果数量量小可以适当做冗余设计降低业务复杂度
参考
https://www.cnblogs.com/cszjc/p/14200597.html
基于学生选课系统的软件系统设计方案
【「有问必答」初学后端如何做好表结构设计?】 https://www.bilibili.com/video/BV1xk4y1t7Pj/?share_source=copy_web&vd_source=fe6c23f6f1353ed1eff5d5e866171572
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |