

机器学习-基于KNN和LMKNN的心脏病预测
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
一、简介和环境准备
knn一般指邻近算法。 邻近算法或者说K最邻近KNNK-NearestNeighbor分类算法是数据挖掘分类技术中最简单的方法之一。而lmknn是局部均值k最近邻分类算法。
本次实验环境需要用的是Google Colab和Google Drive文件后缀是.ipynb可以直接用。非常轻量不用安装配置啥的前者是像notebooks的网页编辑器后者是谷歌云盘用来存储数据大家自行搜索登录即可让colab绑定上云盘。colab一段时间不操作就断连了。

先点击左边的文件图标再点上面第三个图标绑定谷歌云盘。
from google.colab import drive
drive.mount('/content/drive')然后运行该代码第一次会弹出个框进行确认之后就会发现文件列表多了一个drive文件夹这下面就是你Google Drive的文件内容
然后就可以用里面的文件了我准备了心脏故障分析的表格heartfailure_clinical_……csv用于此次实验。存放位置见上图。

同时引入基本库
from sklearn.preprocessing import MinMaxScaler
import pandas as pd二、算法解析
2.1 KNN算法
import scipy.spatial
from collections import Counter
class KNN:
def __init__(self, k):
self.k = k
def fit(self, X, y):
self.X_train = X
self.y_train = y
def distance(self, X1, X2):
return scipy.spatial.distance.euclidean(X1, X2)
def predict(self, X_test):
final_output = []
for i in range(len(X_test)):
d = []
votes = []
for j in range(len(X_train)):
dist = scipy.spatial.distance.euclidean(X_train[j] , X_test[i])
d.append([dist, j])
d.sort()
d = d[0:self.k]
for d, j in d:
votes.append(self.y_train[j])
ans = Counter(votes).most_common(1)[0][0]
final_output.append(ans)
return final_output
def score(self, X_test, y_test):
predictions = self.predict(X_test)
value = 0
for i in range(len(y_test)):
if(predictions[i] == y_test[i]):
value += 1
return value / len(y_test)2.2LMKNN算法
import scipy.spatial
import numpy as np
from operator import itemgetter
from collections import Counter
class LMKNN:
def __init__(self, k):
self.k = k
def fit(self, X, y):
self.X_train = X
self.y_train = y
def distance(self, X1, X2):
return scipy.spatial.distance.euclidean(X1, X2)
def predict(self, X_test):
final_output = []
myclass = list(set(self.y_train))
for i in range(len(X_test)):
eucDist = []
votes = []
for j in range(len(X_train)):
dist = scipy.spatial.distance.euclidean(X_train[j] , X_test[i])
eucDist.append([dist, j, self.y_train[j]])
eucDist.sort()
minimum_dist_per_class = []
for c in myclass:
minimum_class = []
for di in range(len(eucDist)):
if(len(minimum_class) != self.k):
if(eucDist[di][2] == c):
minimum_class.append(eucDist[di])
else:
break
minimum_dist_per_class.append(minimum_class)
indexData = []
for a in range(len(minimum_dist_per_class)):
temp_index = []
for j in range(len(minimum_dist_per_class[a])):
temp_index.append(minimum_dist_per_class[a][j][1])
indexData.append(temp_index)
centroid = []
for a in range(len(indexData)):
transposeData = X_train[indexData[a]].T
tempCentroid = []
for j in range(len(transposeData)):
tempCentroid.append(np.mean(transposeData[j]))
centroid.append(tempCentroid)
centroid = np.array(centroid)
eucDist_final = []
for b in range(len(centroid)):
dist = scipy.spatial.distance.euclidean(centroid[b] , X_test[i])
eucDist_final.append([dist, myclass[b]])
sorted_eucDist_final = sorted(eucDist_final, key=itemgetter(0))
final_output.append(sorted_eucDist_final[0][1])
return final_output
def score(self, X_test, y_test):
predictions = self.predict(X_test)
value = 0
for i in range(len(y_test)):
if(predictions[i] == y_test[i]):
value += 1
return value / len(y_test)2.2.1两种算法代码比对
两者唯一不同在于预测函数predict的不同LMKNN的基本原理是在进行分类决策时利用每个类中k个最近邻的局部平均向量对查询模式进行分类。可以看到加强局部模型的计算。最后处理结果的异同优异结尾有写。
2.3数据处理
2.3.1导入数据
train_path = r'drive/My Drive/Colab Notebooks/Dataset/heart_failure_clinical_records_dataset.csv'
data_train = pd.read_csv(train_path)
data_train.head()
检查有没有缺失的数据查了下没有都为0%
for col in data_train.columns:
print(col, str(round(100* data_train[col].isnull().sum() / len(data_train), 2)) + '%')2.3.2数据预处理
data_train.drop('time',axis=1, inplace=True)
print(data_train.columns.tolist())
['age', 'anaemia', 'creatinine_phosphokinase', 'diabetes', 'ejection_fraction', 'high_blood_pressure', 'platelets', 'serum_creatinine', 'serum_sodium', 'sex', 'smoking', 'DEATH_EVENT']
得到所有标签放到后面的data_train 中
label_train = data_train['DEATH_EVENT'].to_numpy()
fitur_train = data_train[[ 'anaemia', 'creatinine_phosphokinase', 'diabetes', 'ejection_fraction', 'high_blood_pressure', 'platelets', 'serum_creatinine', 'serum_sodium']].to_numpy()
scaler = MinMaxScaler(feature_range=(0, 1))
scaler.fit(fitur_train)
fitur_train_normalize = scaler.transform(fitur_train)
print(fitur_train_normalize[0])[0. 0.07131921 0. 0.09090909 1. 0.29082313 0.15730337 0.48571429]
2.4分类令3K=3时
分别调用knn和lmknn训练并输出准确率
from sklearn.model_selection import StratifiedKFold
kf = StratifiedKFold(n_splits=10, random_state=None, shuffle=True)
kf.get_n_splits(fitur_train_normalize)
acc_LMKNN_heart = []
acc_KNN_heart = []
for train_index, test_index in kf.split(fitur_train_normalize,label_train):
knn = KNN(3)
lmknn = LMKNN(3)
X_train, X_test = fitur_train_normalize[train_index], fitur_train_normalize[test_index]
y_train, y_test = label_train[train_index], label_train[test_index]
knn.fit(X_train,y_train)
prediction = knn.score(X_test, y_test)
acc_KNN_heart.append(prediction)
lmknn.fit(X_train, y_train)
result = lmknn.score(X_test, y_test)
acc_LMKNN_heart.append(result)
print(np.mean(acc_KNN_heart))
print(np.mean(acc_LMKNN_heart))
0.7157471264367816
0.7022988505747125
2.5对邻域大小K的敏感性结果
令k处于2-15调用看看并输出所有结果。好像没有成功调用gpu花了20s左右。
from sklearn.model_selection import StratifiedKFold
kf = StratifiedKFold(n_splits=10, random_state=None, shuffle=True)
kf.get_n_splits(fitur_train_normalize)
K = range(2,15)
result_KNN_HR = []
result_LMKNN_HR = []
for k in K :
acc_LMKNN_heart = []
acc_KNN_heart = []
for train_index, test_index in kf.split(fitur_train_normalize,label_train):
knn = KNN(k)
lmknn = LMKNN(k)
X_train, X_test = fitur_train_normalize[train_index], fitur_train_normalize[test_index]
y_train, y_test = label_train[train_index], label_train[test_index]
knn.fit(X_train,y_train)
prediction = knn.score(X_test, y_test)
acc_KNN_heart.append(prediction)
lmknn.fit(X_train, y_train)
result = lmknn.score(X_test, y_test)
acc_LMKNN_heart.append(result)
result_KNN_HR.append(np.mean(acc_KNN_heart))
result_LMKNN_HR.append(np.mean(acc_LMKNN_heart))
print('KNN : ',result_KNN_HR)
print('LMKNN : ',result_LMKNN_HR)
KNN : [0.6624137931034483, 0.7127586206896551, 0.7088505747126437, 0.7057471264367816, 0.689080459770115, 0.6886206896551724, 0.682528735632184, 0.6826436781609195, 0.69183908045977, 0.6791954022988506, 0.6722988505747127, 0.669080459770115, 0.6588505747126436]
LMKNN : [0.6922988505747126, 0.695977011494253, 0.6885057471264368, 0.6722988505747127, 0.6889655172413793, 0.6652873563218391, 0.6924137931034483, 0.6926436781609195, 0.7051724137931035, 0.6691954022988506, 0.689080459770115, 0.6857471264367816, 0.682528735632184]
生成图像蓝色是knn绿色是lmknn
import matplotlib.pyplot as plt
plt.plot(range(2,15), result_KNN_HR)
plt.plot(range(2,15), result_LMKNN_HR, color="green")
plt.ylabel('Accuracy')
plt.xlabel('K')
plt.show()

也可以调用鸢尾花等机器学习数据集这里不再演示。
三、总结
除了心脏病这个原文做了四个实验。最后结果图如下knn蓝lmknn黄
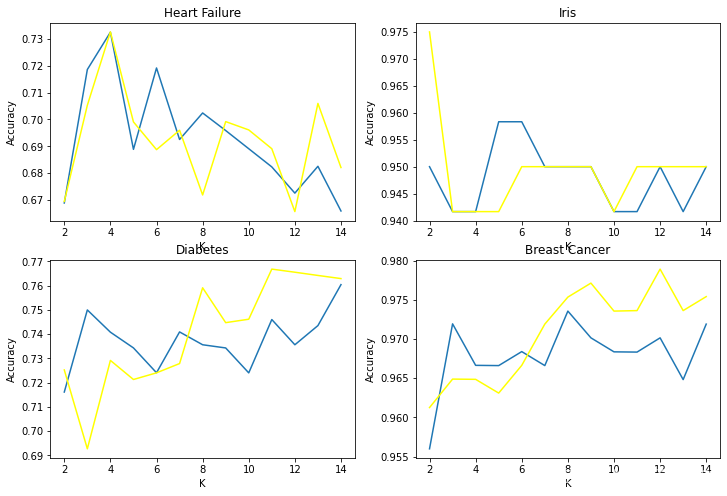
可以简单分析得到分类的种类k越大时lmknn具有更高的准确性。
来源GitHub - baguspurnama98/lmknn-python: Local Mean K Nearest Neighbor with Python