

6D目标检测简述
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
6D目标检测简述
文章目录
本文参考了ITAIC的文章 A Review of 6D Object Pose Estimation
介绍
6D目标检测和传统的目标检测类似都是从图像包括点云中去识别物体的位置。
传统的2D目标检测像是SSD、YOLO等识别的结果是一个边界框bounding box
而3D目标检测的结果则是一个3D的边界框。
6D目标检测的输出结果包括两个部分
- 物体的空间坐标x, y, z
- 物体的三个旋转角: pitch, yaw, roll
传统的6D目标检测可以被分类成以下几种
- 基于模版匹配
- 基于点
- 基于描述子
- 基于特征
| 方法 | 优点 | 缺点 |
|---|---|---|
| 基于模版匹配 | 擅长针对无纹理或者弱纹理的物体 | 对遮挡比较敏感 |
| 基于点 | 抗遮挡 | 依赖纹理细节 |
| 基于描述子 | 抗遮挡 | 依赖纹理细节 |
| 基于特征 | 擅长弱纹理同时抗遮挡 | 较难处理对称物体 |
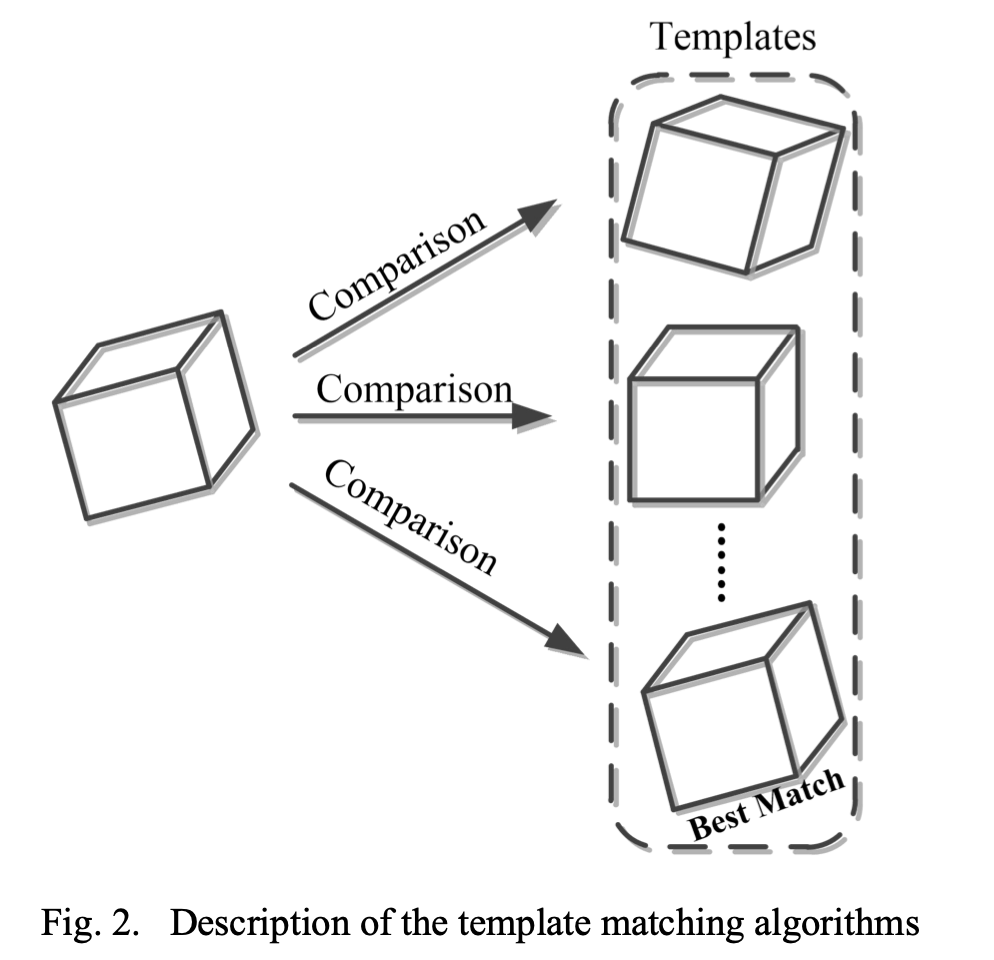
基于模版匹配的算法
基于模版匹配的算法其思路就是 生成尽可能多的模版每一个模版表示不同的旋转姿态同原图进行相似度的计算
由于实际环境会受到光照、遮挡的影响这类算法在这种情况下表现较差。
同时由于需要生成多的模版所以算法的计算代价也较高。
较为经典的模版匹配算法比如 linemod
ICCV-2011: Multimodal templates for real-time detection of texture-less objects in heavily cluttered scenes
使用了图像的色彩梯度(Color Gradient) 来抵抗光照和噪声等影响同时引入了深度信息来构建数个表面垂直向量来作为特征
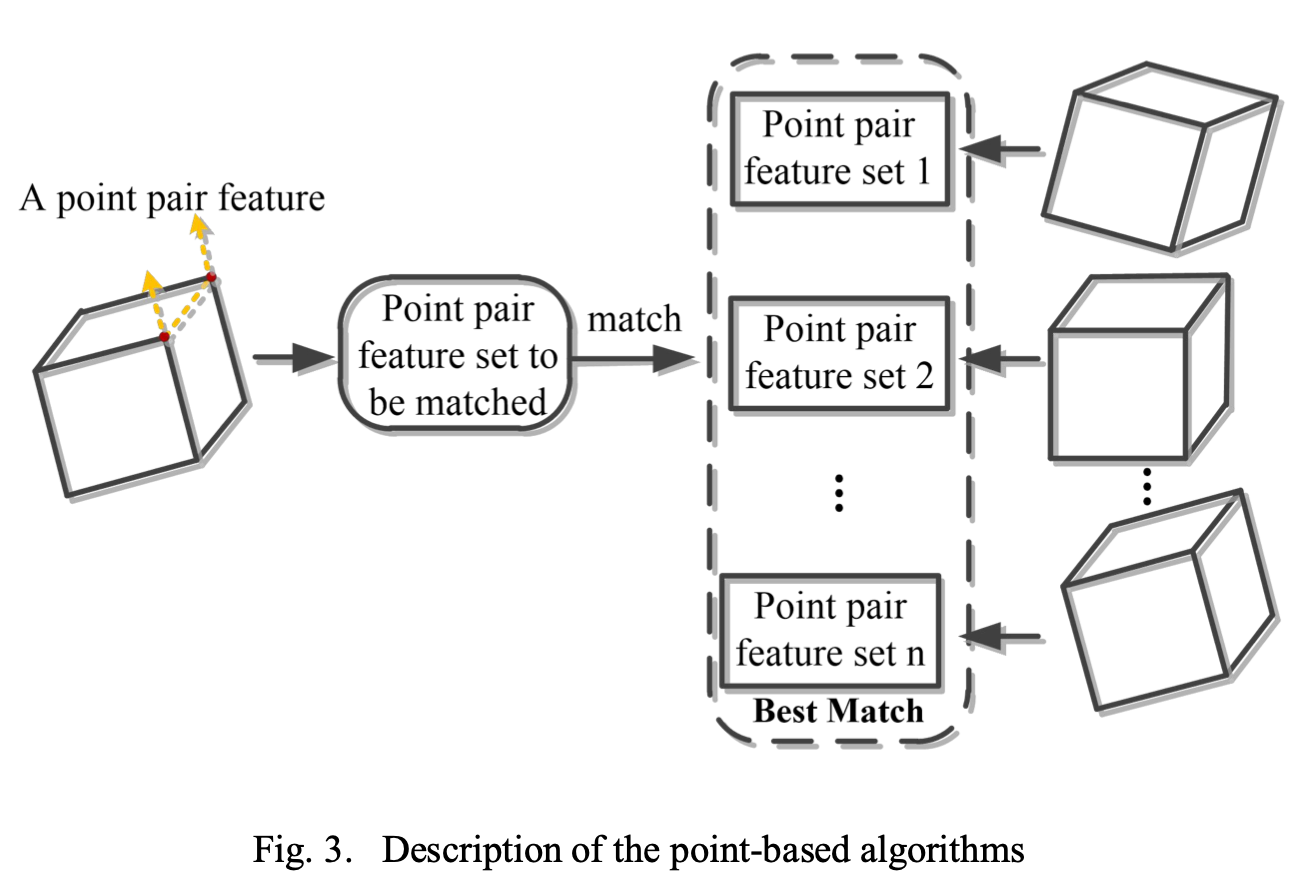
基于点的算法
这里所说的点其实是空间中的点。基于点的算法其本质是 利用点云之间的匹配来实现姿态估计
和模版匹配类似通过构造一些点的特征边的特征然后生成不同姿态下的特征集合通过特征匹配进而实现点云的匹配。
这里给出一些相关文献供大家参考
CVPR-2010: Model globally, match locally: Efficient and robust 3D object recognition
IROS-2012: 3D pose estimation of daily objects using an RGB-D camera
基于描述子的算法
描述子通常是用来刻画点周围的一些几何特征比如说点坐标的特点法向量或者是曲线
该方法和基于点的方法类似都对纹理特征依赖比较严重
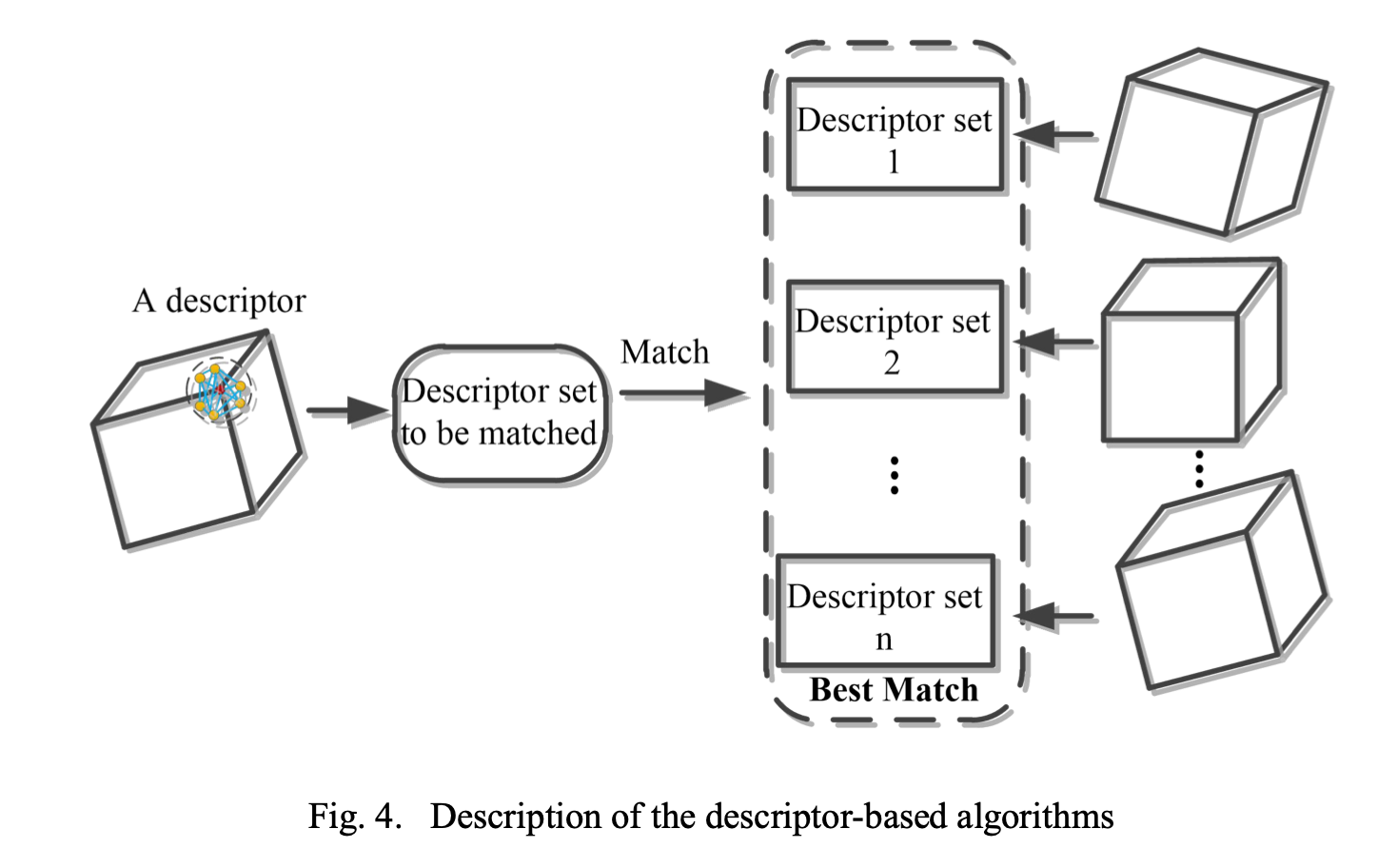
本质也是需要预先生成一堆描述子集合然后逐个进行匹配。
一些经典的方法比如说点特征直方图Point Feature Histogram, PFH有兴趣的读者可以自行阅读
R. B. Rusu, N. Blodow, Z. C. Marton, et al, Aligning Point Cloud Views using Persistent Feature Histograms, Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems, pp. 3384-3391, 2008.
基于特征的算法
同样的我们需要生成一系列特征集合进行模型的训练如下图所示
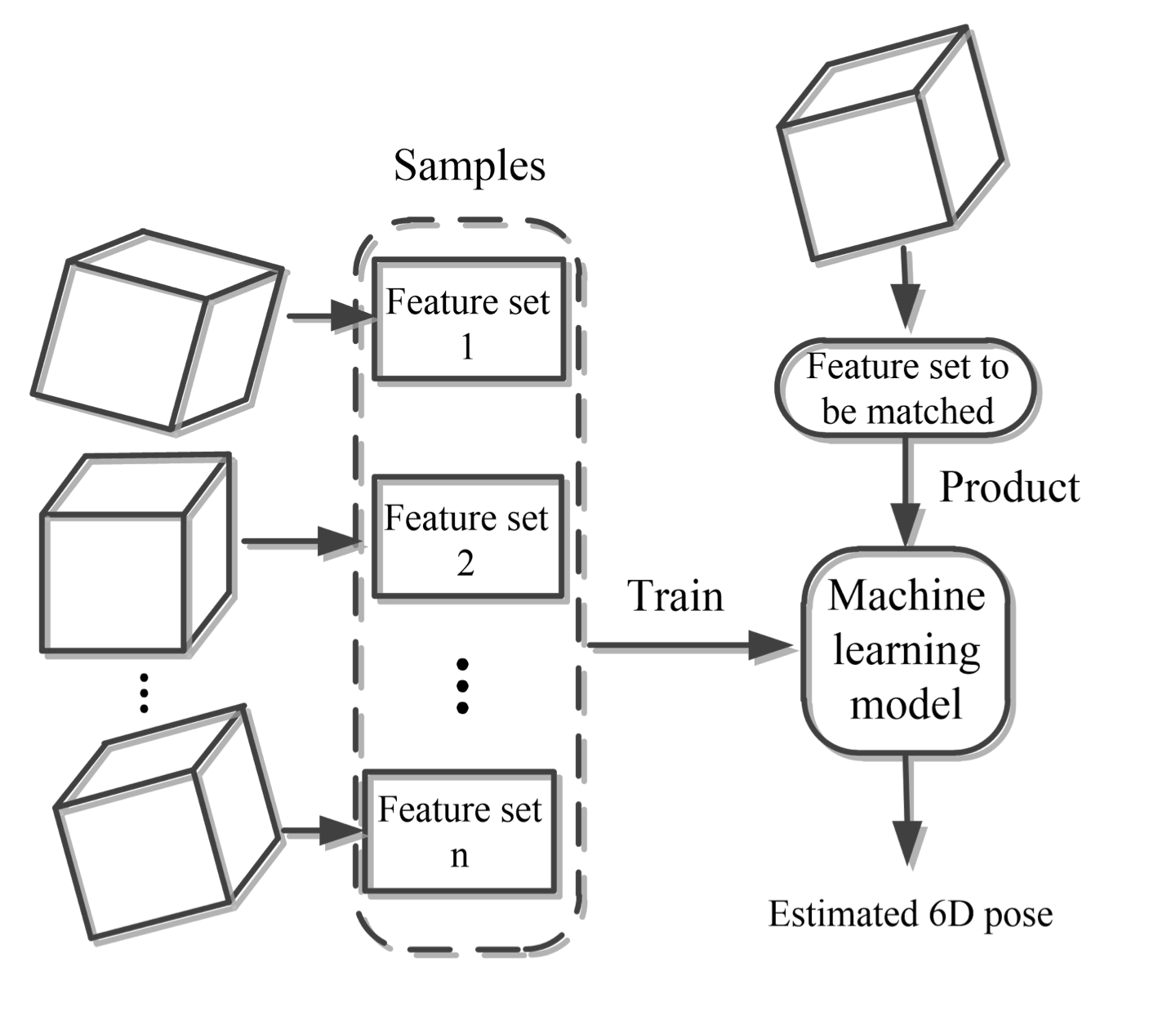
通过一些机器学习的方法比如随机森林等训练一个分类器以特征作为输入输出对6D姿态的估计
- E. Brachmann, A. Krull, F. Michel, et al, Learning 6D Object Pose Estimation Using 3D Object Coordinates, Proceedings of European Conference on Computer Vision, pp. 536-551, 2014.
- M. A. Fischler, R. C. Bolles, Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography, Communications of the ACM, vol. 24, issue 6, pp. 381-395, 1981.
基于深度学习的6D姿态估计
这里我们将所有的基于深度学习的方法分成两类
- 基于RGB图像的方法
- 基于RGB-D图像的方法
RGB-D图像即是在原本的图像通道上加了一个深度通道代表像素点的深度信息
基于RGB图像的深度学习方法
这里给出一些相关的方法的总结表格
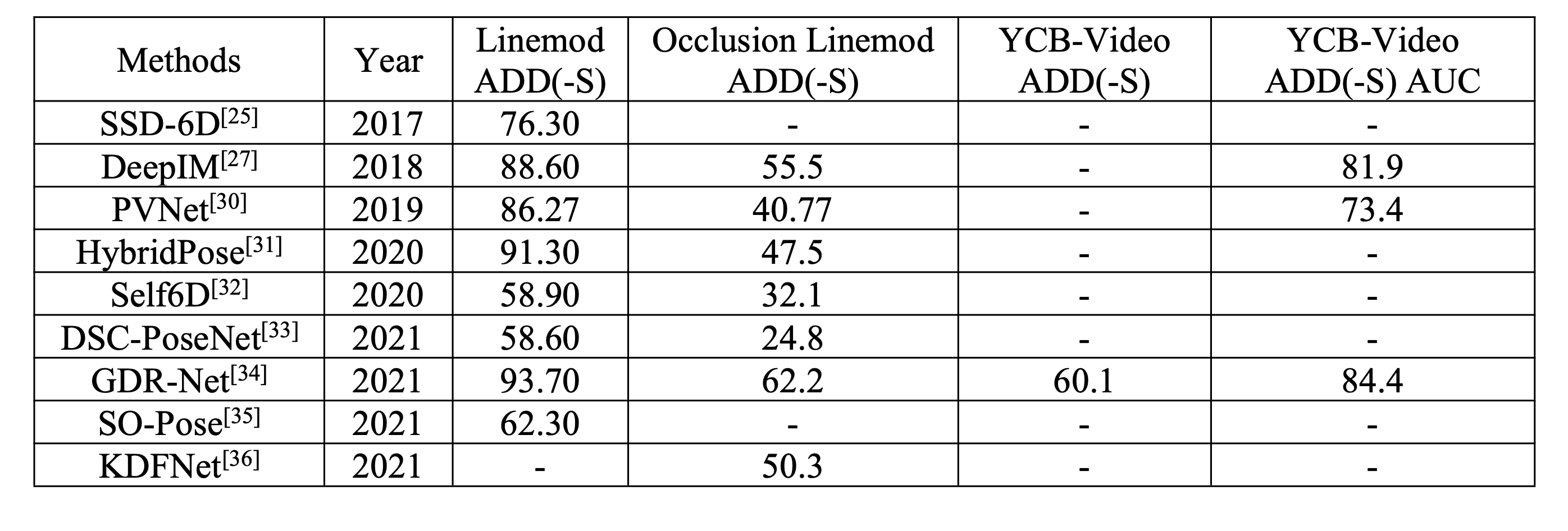
- SSD-6D: Making RGB- Based 3D Detection and 6D Pose Estimation Great Again,
- DeepIM: Deep Iterative Matching for 6D Pose Estimation
- PVNet: Pixel-Wise Voting Network for 6DoF Pose Estimation
- HybridPose: 6D Object Pose Estimation Under Hybrid Representations
- Self6D: Self-supervised Monocular 6D Object Pose Estimation
- Dsc-posenet:Learning6dofobjectpose estimation via dual-scale consistency
- GDR-Net: Geometry- Guided Direct Regression Network for Monocular 6D Object Pose Estimation
- SO-Pose: Exploiting Self-Occlusion for Direct 6D Pose Estimation
- KDFNet: Learning Keypoint Distance Field for 6D Object Pose Estimation
其中ADD(-S) 代表预测点和最近的真实点的距离偏差越小越好。
SSD-6D
该方法是将原来目标检测的SSD范式拓展到了6D目标检测领域使用InceptionV4估计2D的边界框并且对所有的视角和旋转进行打分。
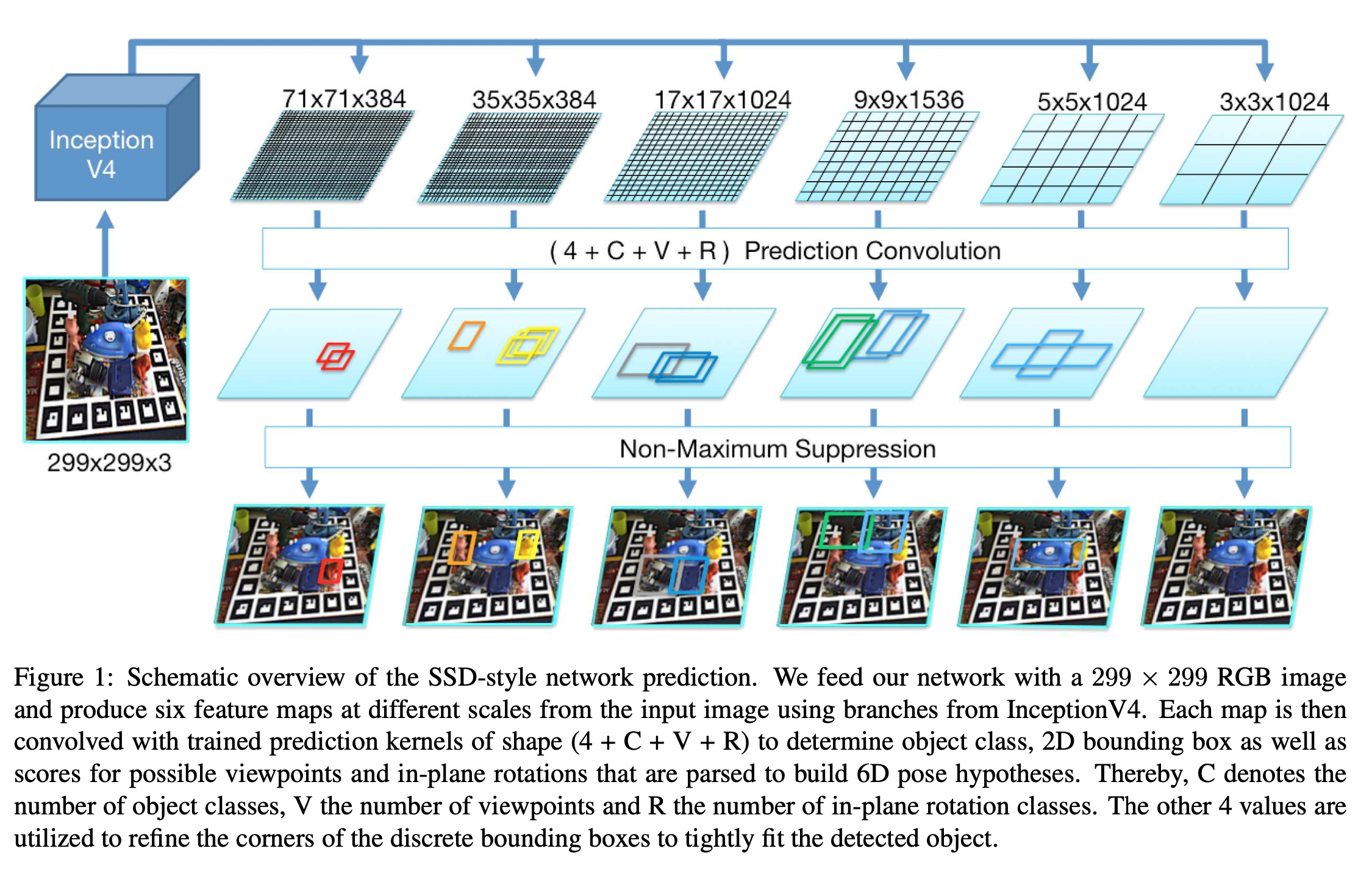
可以看到最后的预测结果由四个部分组成
- 42D边界框坐标
- C代表物体的类别
- V代表物体的视角个数可以理解成物体的角度
- R平面内旋转的类别 (in-plane rotation class)
同时SSD-6D使用ICP来提高精确度优化姿态的结果
在6D姿态识别中ICP是指迭代最近点Iterative Closest Point算法。该算法主要用于将一个点云或三维模型与另一个点云或三维模型对齐或配准。在6D姿态识别中ICP算法可以用来估计目标物体的姿态即将一个模型与目标物体的点云匹配找到最合适的姿态使两个模型之间的误差最小化。通过迭代求解最近点匹配问题ICP算法可以不断优化姿态估计的准确性从而实现6D姿态识别。
Deep-IM
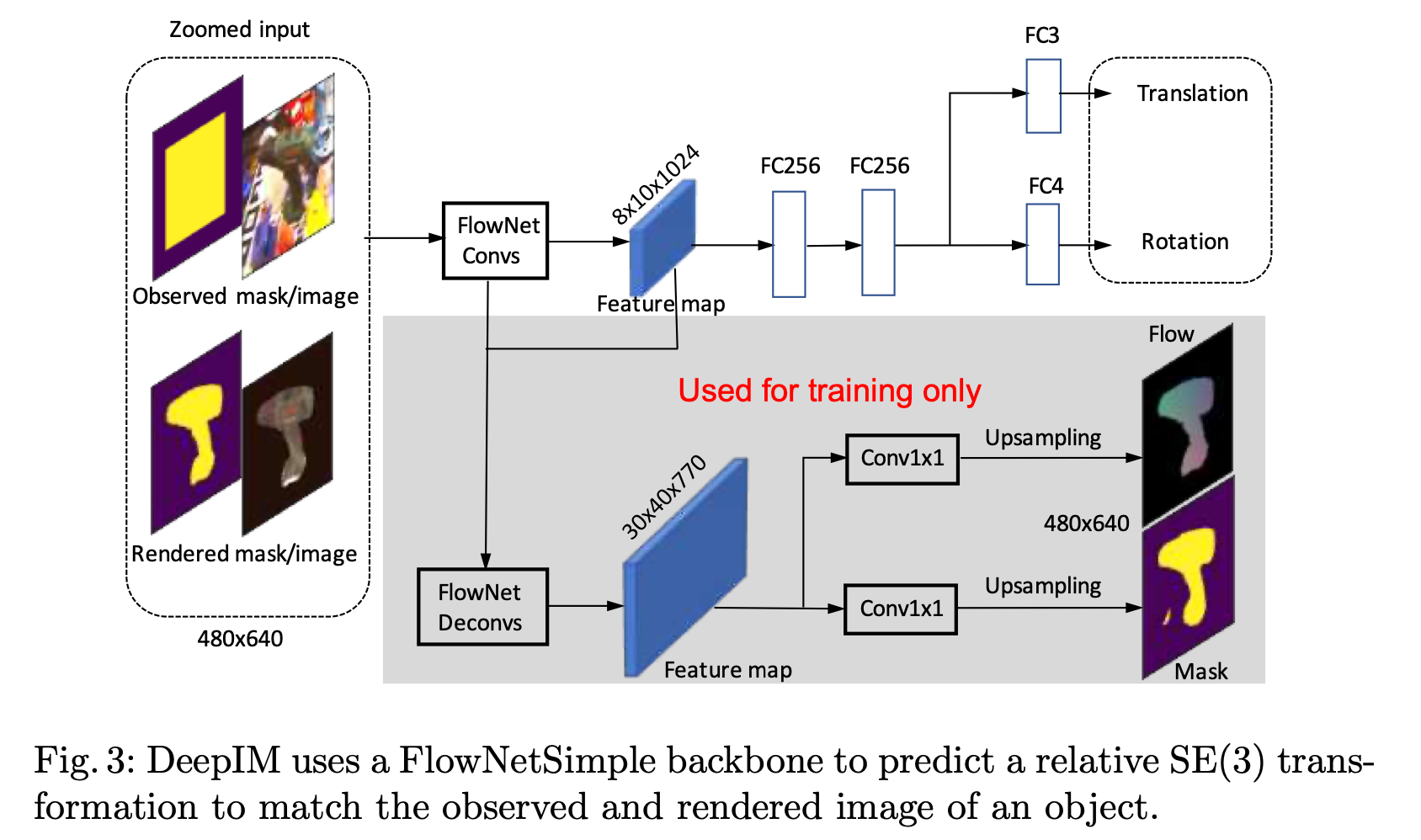
DeepIM使用了一个FlowNetSimple的骨干网络用来预测一个相对的特殊欧式群 SE(3) 的元素
SE(3) 是一个包含所有旋转和平移的集合其中该集合中的元素可以表示成4x4的矩阵
T = ( R v 0 1 ) T = \begin{pmatrix} R&v\\ 0&1 \end{pmatrix} T=(R0v1)
其中 R R R 是一个3x3的旋转矩阵 v v v 是一个平移向量
在训练过程中DeepIM还会有两个额外的分支用来进行Mask和光流估计
FlowNetSimple: A. Dosovitskiy, P. Fischer, E. Ilg, et al, FlowNet: Learning Optical Flow with Convolutional Networks, Proceedings of International Conference on Computer Vision, pp. 2758-2766, 2015.
PV-Net
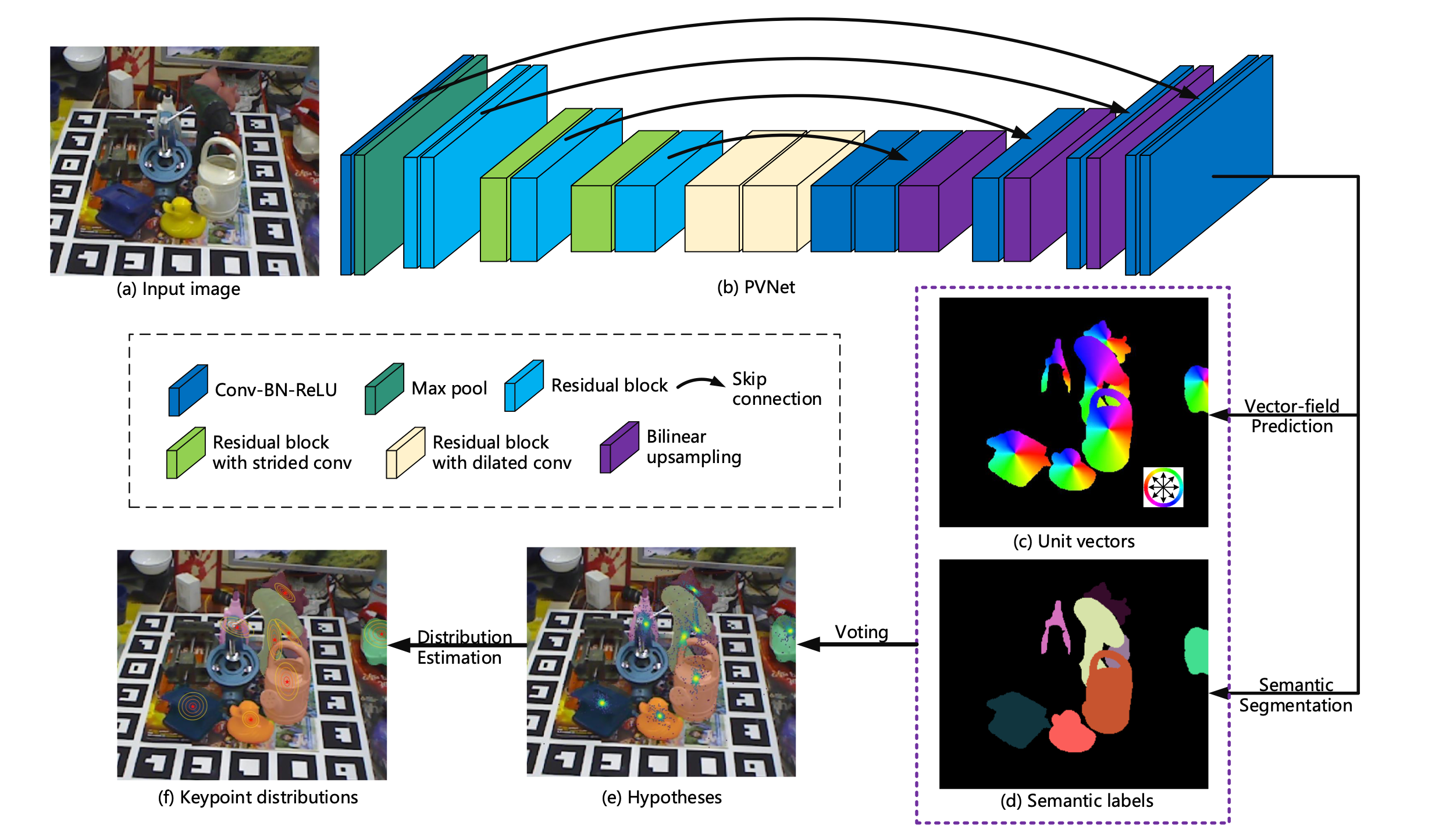
如上图所示PV-Net首先使用一个网络做向量场估计以及语义分割然后投票得到关键点位置的假设最后得到关键点位置的分布
这里PV-Net的骨干网络使用的是ResNet18。
HybridPose
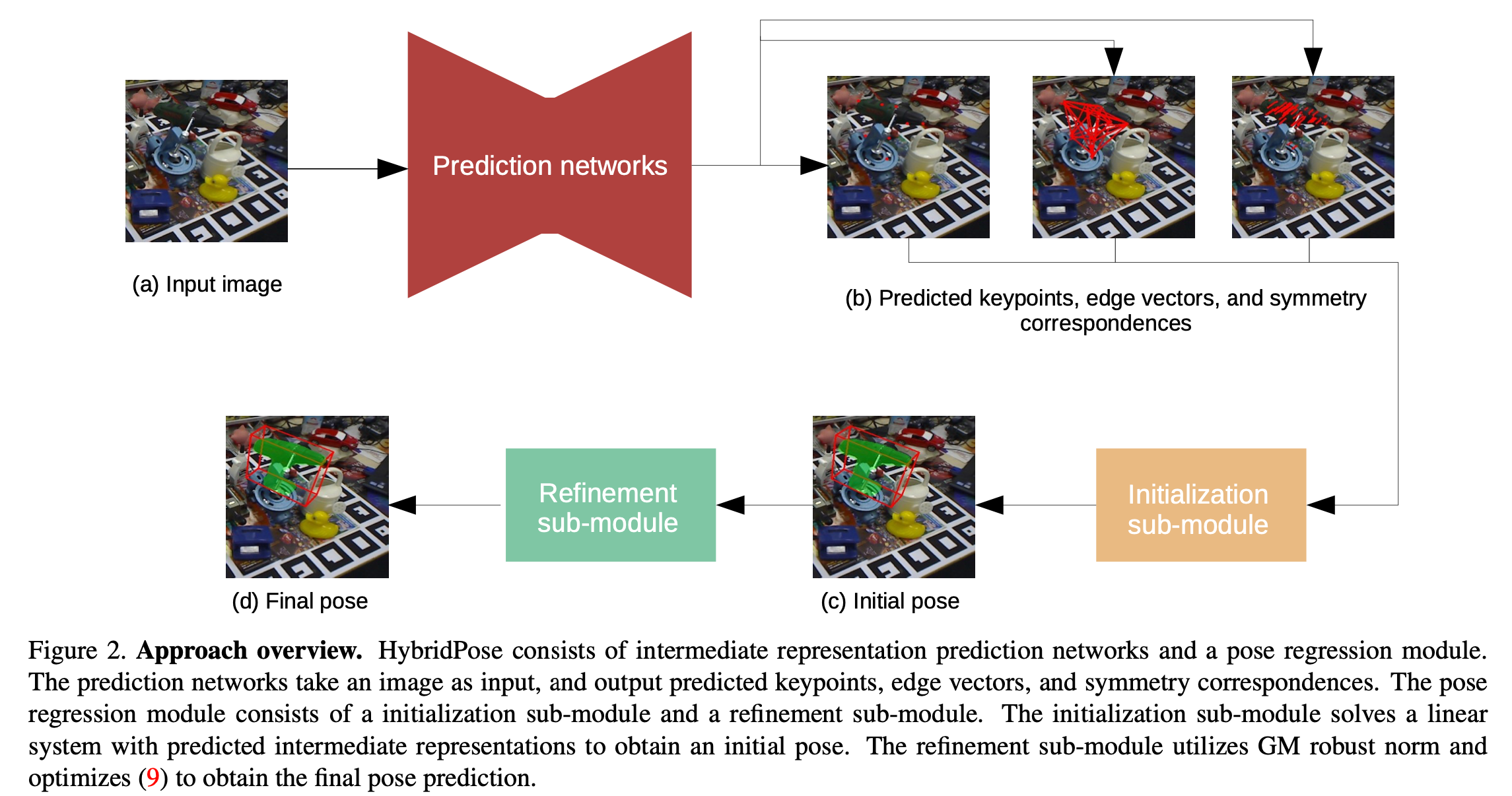
HybridPose方法的特点就是揉合了多种不同的特征关键点、边缘向量和对称相似symmetry correspondences
Self6D
首个将自监督学习引入6D姿态估计中利用神经渲染neural rendering来实现视觉和几何的对齐
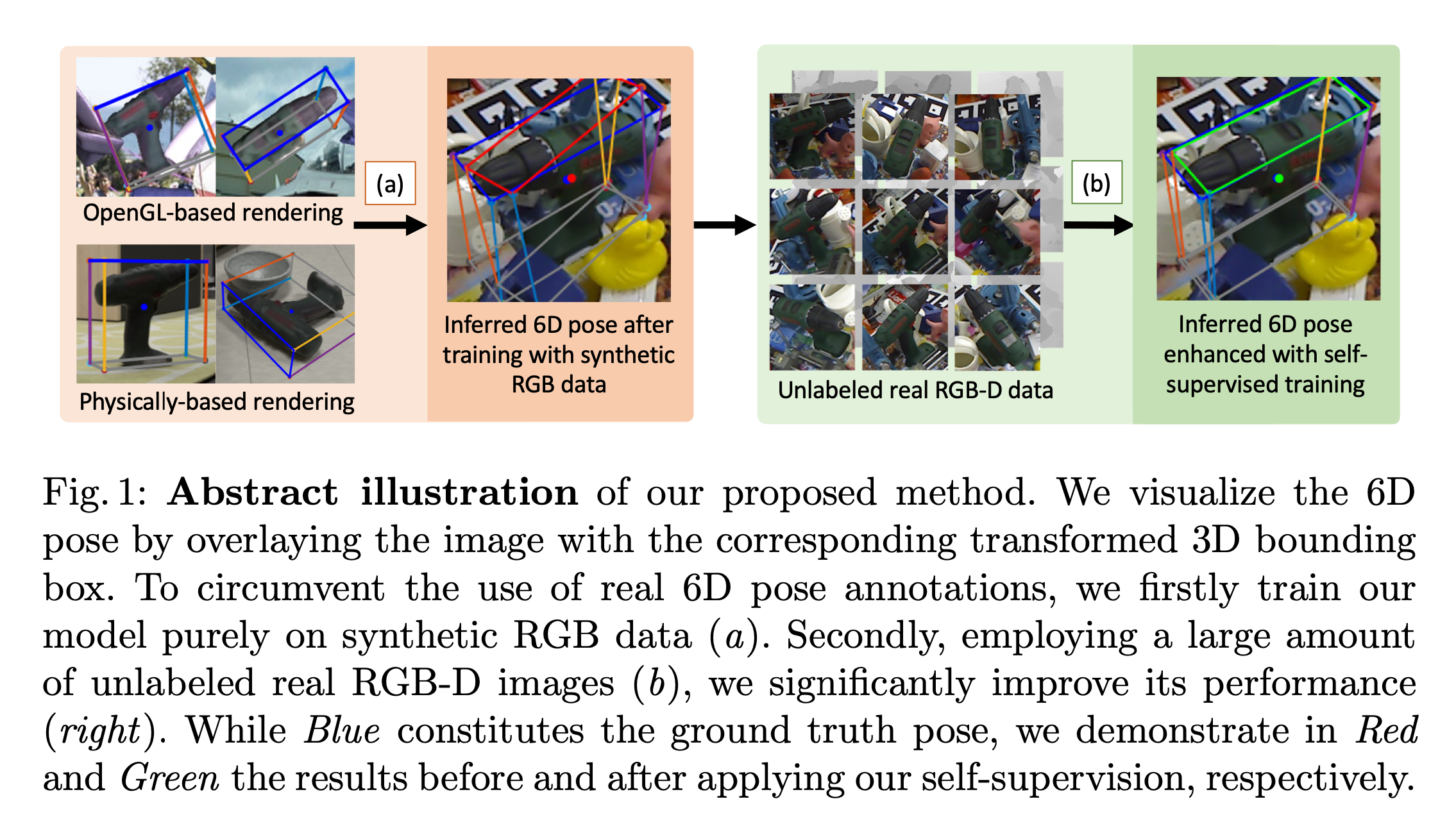
a先使用生成的数据进行模型训练
b基于训练后的模型在大量的RGB-D数据上进行推断
c然后基于这些推断结果再进行训练优化6D姿态检测的结果
DSC-PoseNet
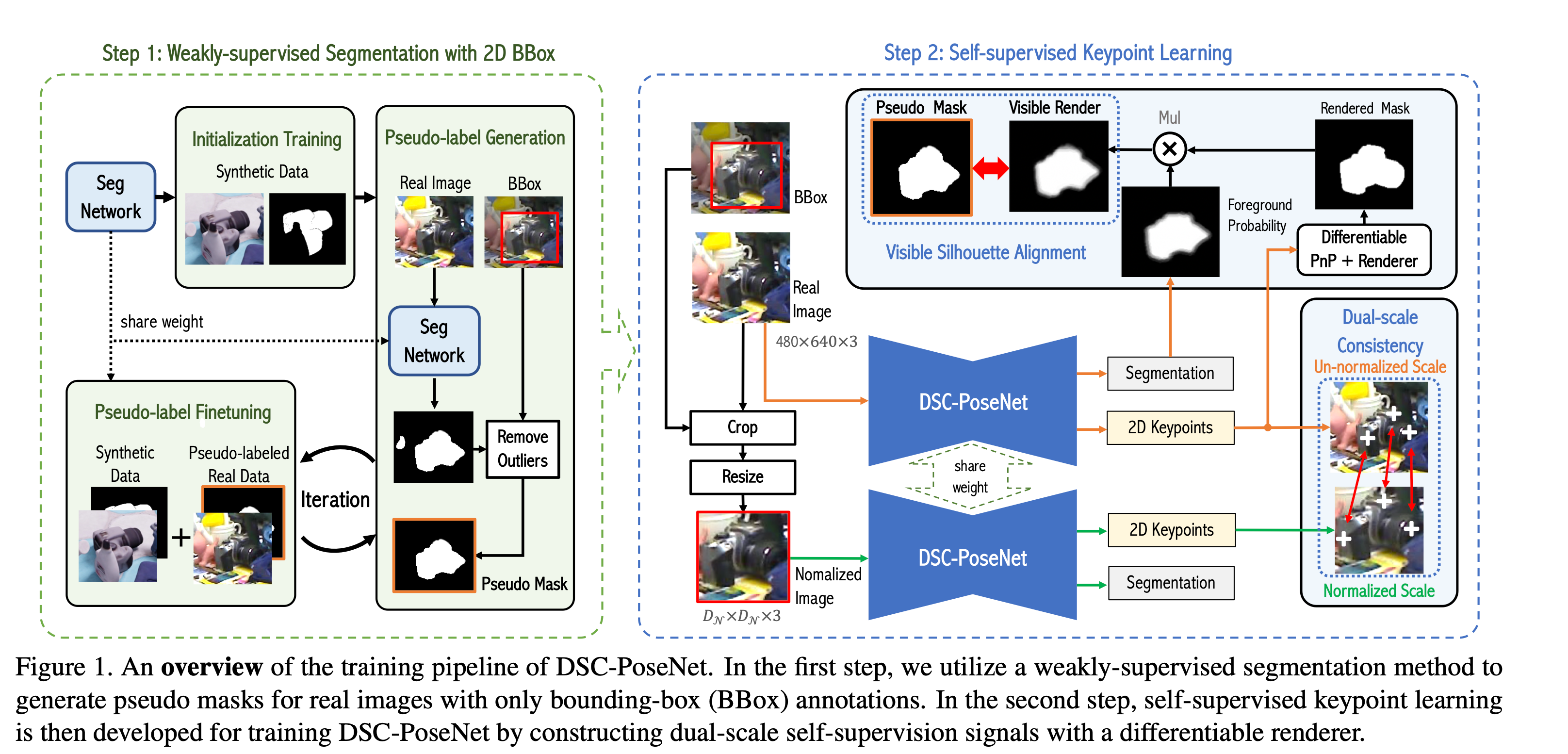
主要分成两个步骤
1. 利用2D边界框进行弱监督的分割
首先使用一个分割网络在生成的数据上进行初始训练。
然后在实际的图像上推断利用2D边界框移除掉一些异常的分割结果反复优化这个分割网络
2. 自监督关键点学习
构造一个双尺度dual-scale的自监督信号来训练DSC-PoseNet
主要有两个部分
- 原始图像经过DSC-PoseNet之后得到2D关键点和分割结果
- 利用2D边界框裁剪和缩放之后经过DSC-PoseNet得到2D关键点和分割结果
利用第一部分的分割结果以及分割网络的结果进行对齐
第一和第二部分得到的关键点进行比对计算出不同尺度下的连续性构造误差
GDR-Net
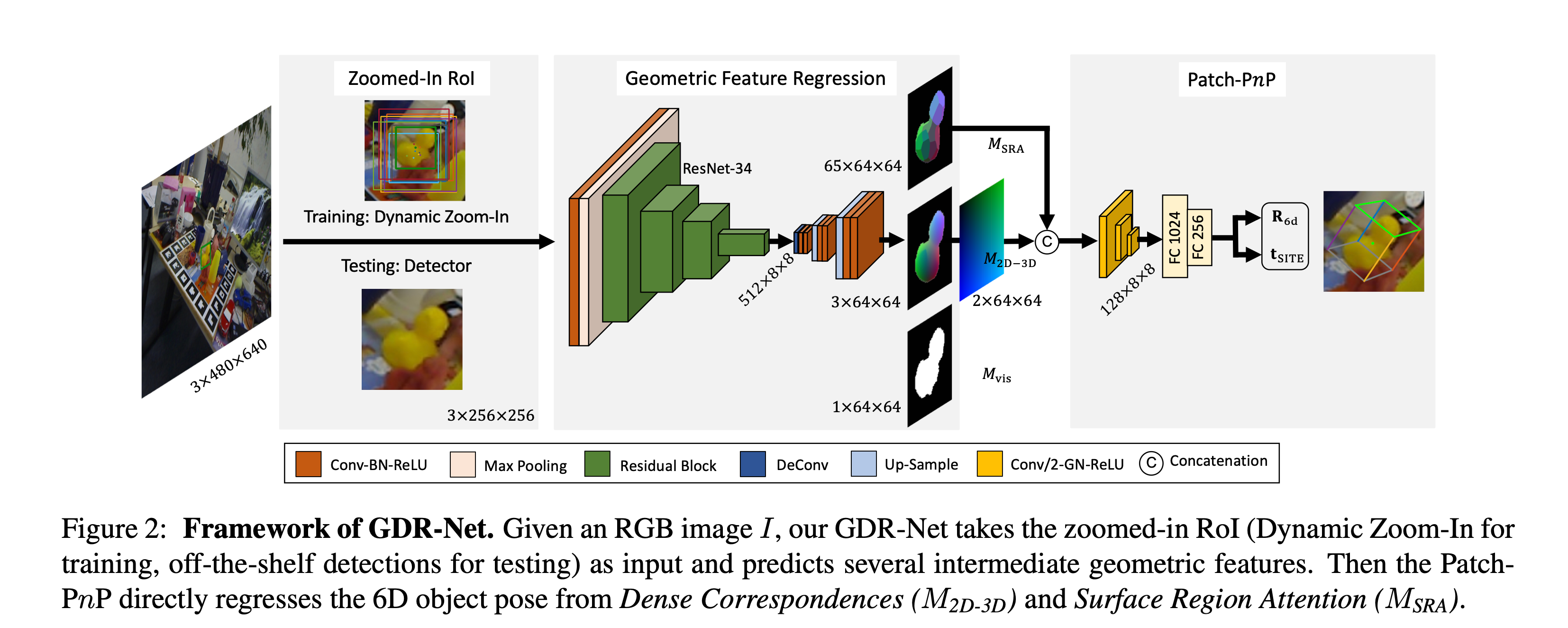
同先前的一些网络输出一样最后输出包含两个部分一个是旋转矩阵一个是平移向量
在训练过程中会使用一个随机放大技巧Dynamic Zoom-In 然后经过网络生成3个中间几何特征intermediate geometry feature分别是
- Dense Correspondences Map:
M
2
D
−
3
D
M_{2D-3D}
M2D−3D
- 其大小是2x64x64本质上就是每个像素2D投影的坐标
- Surface Region Attention Map:
M
S
R
A
M_{SRA}
MSRA
- 对于每一个像素来说输出该点所属于表面区域这里应该是不同的表面区域代表不同的类别
- 可以看到形状是64x65x65意味着一共有64个不同表面区域
- 文章后续探究了不同的表面区域数量对方法的影响有兴趣的可以看一下原文
- Visible Object Mask:
M
v
i
s
M_{vis}
Mvis
- 就是一个遮罩类似语义分割的物体遮罩
SO-Pose
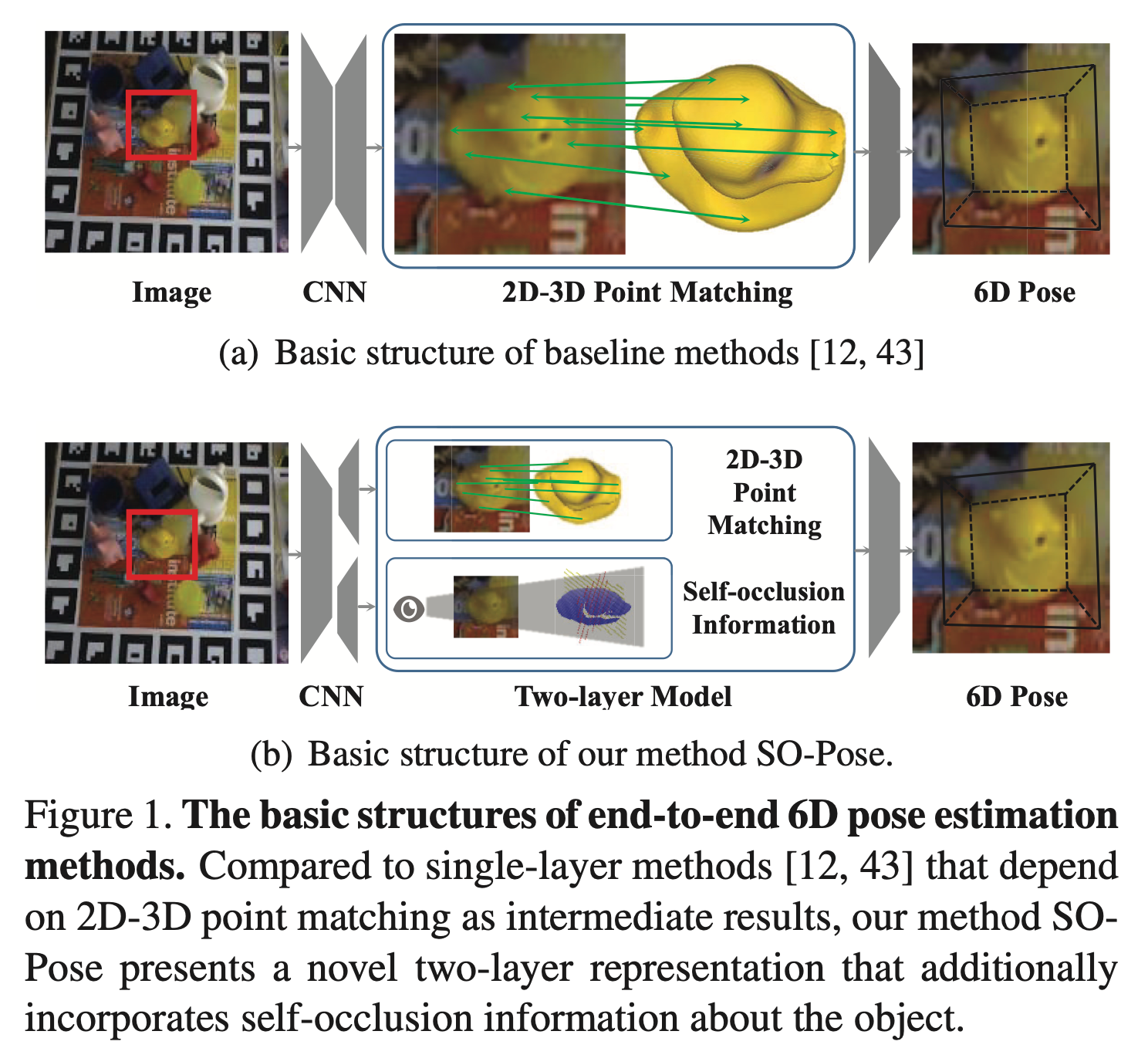
如上图所示该方法的特点就是引入了一个自遮挡信息Self-Occlusion Information进一步增强了准确度
KDF-Net
传统方法通常都是使用像素粒度的投票来确定2D的关键点利用解决PnP问题来求解物体的姿态
不过这种投票方法因为是基于方向的所以难以处理一些比较长、薄的物体
这些长、薄的物体的方向难以被推断出来因此该方法提出了一种关键点距离场 (Keypoint Distance Field)
利用KDF来预测2D的关键点位置
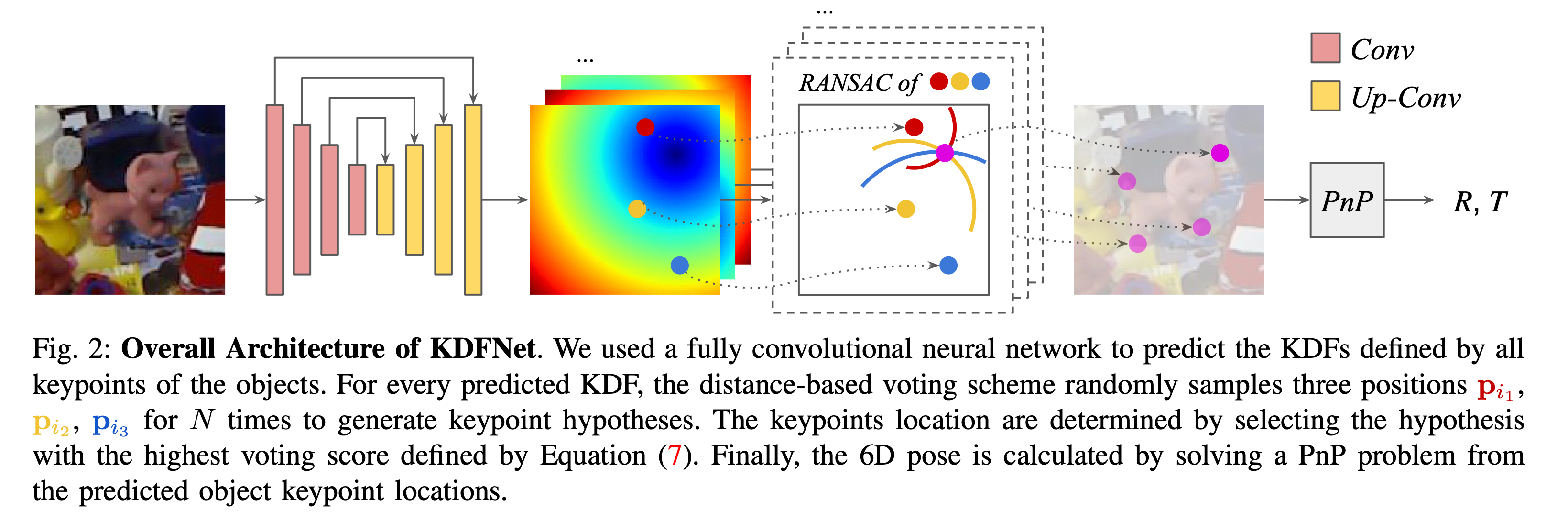
如上图所示首先用一个全卷积网络来预测KDF对于每一个像素应该都有一个KDF然后使用RANSAC方法去随机采样N次
再使用投票来选出关键点最后使用PnP求解
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |